Apache Spark MLlib gebruiken om een machine learning-toepassing te bouwen en een gegevensset te analyseren
Meer informatie over het gebruik van Apache Spark MLlib om een machine learning-toepassing te maken. De toepassing voert voorspellende analyses uit voor een geopende gegevensset. Uit de ingebouwde machine learning-bibliotheken van Spark wordt in dit voorbeeld gebruikgemaakt van classificatie via logistieke regressie.
MLlib is een spark-kernbibliotheek die veel hulpprogramma's biedt die nuttig zijn voor machine learning-taken, zoals:
- Classificatie
- Regressie
- Clustering
- Modellen maken
- SVD (Singular Value Decomposition) en PCA (Principal Component Snalysis)
- Hypothesen voor het testen en berekenen van voorbeeldstatistieken
Classificatie en logistieke regressie begrijpen
Classificatie, een populaire machine learning-taak, is het proces waarbij invoergegevens worden gesorteerd in categorieën. Het is de taak van een classificatie-algoritme om erachter te komen hoe u 'labels' toewijst aan invoergegevens die u opgeeft. U kunt bijvoorbeeld een machine learning-algoritme bedenken dat aandeleninformatie als invoer accepteert. Vervolgens verdeelt u het aandeel in twee categorieën: aandelen die u moet verkopen en aandelen die u moet behouden.
Logistieke regressie is het algoritme dat u gebruikt voor classificatie. De logistieke regressie-API van Spark is handig voor binaire classificatie, of voor het classificeren van invoergegevens in één van twee groepen. Zie Wikipedia voor meer informatie over logistieke regressies.
Kortom, het proces van logistieke regressie produceert een logistieke functie. Gebruik de functie om de kans te voorspellen dat een invoervector deel uitmaakt van de ene groep of de andere.
Voorbeeld van voorspellende analyse van gegevens over voedselinspectie
In dit voorbeeld gebruikt u Spark om een voorspellende analyse uit te voeren op voedselinspectiegegevens (Food_Inspections1.csv). Gegevens die zijn verkregen via de gegevensportal city of Chicago. Deze gegevensset bevat informatie over voedselinrichtingsinspecties die zijn uitgevoerd in Chicago. Inclusief informatie over elke vestiging, de gevonden schendingen (indien aanwezig) en de resultaten van de inspectie. Het CSV-gegevensbestand is al beschikbaar in het opslagaccount dat is gekoppeld aan het cluster op /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
In de volgende stappen ontwikkelt u een model om te zien wat er nodig is om een voedselinspectie door te geven of te mislukken.
Een machine learning-app maken in Apache Spark MLlib
Maak een Jupyter-notebook met behulp van de PySpark-kernel. Zie Een Jupyter Notebook-bestand maken voor de instructies.
Importeer de typen die zijn vereist voor deze toepassing. Kopieer en plak de volgende code in een lege cel en druk op Shift+Enter.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Vanwege de PySpark-kernel hoeft u niet expliciet contexten te maken. De Spark- en Hive-contexten worden automatisch gemaakt wanneer u de eerste codecel uitvoert.
Een invoergegevensframe maken
Gebruik de Spark-context om de onbewerkte CSV-gegevens in het geheugen op te halen als ongestructureerde tekst. Gebruik vervolgens de CSV-bibliotheek van Python om elke regel van de gegevens te parseren.
Voer de volgende regels uit om een RDD (Resilient Distributed Dataset) te maken door de invoergegevens te importeren en te parseren.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Voer de volgende code uit om één rij op te halen uit de RDD, zodat u het gegevensschema kunt bekijken:
inspections.take(1)De uitvoer is:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]De uitvoer geeft u een idee van het schema van het invoerbestand. Het omvat de naam van elke vestiging en het type vestiging. Ook het adres, de gegevens van de inspecties en de locatie, onder andere.
Voer de volgende code uit om een dataframe (df) en een tijdelijke tabel (CountResults) te maken met een paar kolommen die nuttig zijn voor de voorspellende analyse.
sqlContextwordt gebruikt om transformaties uit te voeren op gestructureerde gegevens.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')De vier kolommen van belang in het dataframe zijn id, naam, resultaten en schendingen.
Voer de volgende code uit om een klein voorbeeld van de gegevens op te halen:
df.show(5)De uitvoer is:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
De gegevens begrijpen
Laten we beginnen met een idee van wat de gegevensset bevat.
Voer de volgende code uit om de afzonderlijke waarden in de resultatenkolom weer te geven:
df.select('results').distinct().show()De uitvoer is:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Voer de volgende code uit om de distributie van deze resultaten te visualiseren:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsDe
%%sqlmagie gevolgd door-o countResultsdfzorgt ervoor dat de uitvoer van de query lokaal wordt bewaard op de Jupyter-server (meestal het hoofdknooppunt van het cluster). De uitvoer wordt bewaard als een Pandas-dataframe met de opgegeven naam countResultsdf. Zie Kernels die beschikbaar zijn op Jupyter Notebooks met Apache Spark HDInsight-clusters voor meer informatie over de%%sqlmagie en andere magics die beschikbaar zijn met de PySpark-kernel.De uitvoer is:
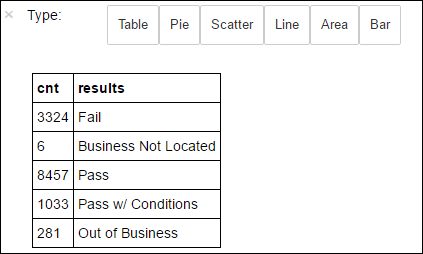
U kunt ook Matplotlib, een bibliotheek die wordt gebruikt om visualisatie van gegevens samen te stellen, gebruiken om een plot te maken. Omdat de plot moet worden gemaakt op basis van het lokaal persistente countResultsdf-gegevensframe , moet het codefragment beginnen met de
%%localmagie. Deze actie zorgt ervoor dat de code lokaal wordt uitgevoerd op de Jupyter-server.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Als u een resultaat van een voedselinspectie wilt voorspellen, moet u een model ontwikkelen op basis van de schendingen. Omdat logistieke regressie een binaire classificatiemethode is, is het zinvol om de resultaatgegevens te groeperen in twee categorieën: Fail en Pass:
Geslaagd
- Geslaagd
- Voorwaarden doorgeven
Mislukt
- Mislukt
Verwijderen
- Bedrijf bevindt zich niet
- Out-of-Business
Gegevens met de andere resultaten ('Business Not Located' of 'Out of Business') zijn niet nuttig en vormen toch een klein percentage van de resultaten.
Voer de volgende code uit om het bestaande dataframe(
df) te converteren naar een nieuw dataframe waarin elke inspectie wordt weergegeven als een paar labelschendingen. In dit geval vertegenwoordigt een label0.0van een fout, een label van1.0een succes en een label met-1.0enkele resultaten naast die twee resultaten.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Voer de volgende code uit om één rij met de gelabelde gegevens weer te geven:
labeledData.take(1)De uitvoer is:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Een logistiek regressiemodel maken op basis van het invoergegevensframe
De laatste taak is het converteren van de gelabelde gegevens. Converteer de gegevens naar een indeling die wordt geanalyseerd door logistieke regressie. De invoer voor een logistiek regressie-algoritme heeft een set labelfunctievectorparen nodig. Waarbij de 'functievector' een vector is van getallen die het invoerpunt vertegenwoordigen. U moet dus de kolom 'schendingen' converteren, die semi-gestructureerd is en veel opmerkingen in vrije tekst bevat. Converteer de kolom naar een matrix met reële getallen die een machine gemakkelijk kan begrijpen.
Een standaardmethode voor machine learning voor het verwerken van natuurlijke taal is om elk afzonderlijk woord een index toe te wijzen. Geef vervolgens een vector door aan het machine learning-algoritme. De waarde van elke index bevat de relatieve frequentie van dat woord in de tekenreeks.
MLlib biedt een eenvoudige manier om deze bewerking uit te voeren. Eerst 'tokenize' elke schendingentekenreeks om de afzonderlijke woorden in elke tekenreeks op te halen. Gebruik vervolgens een HashingTF om elke set tokens te converteren naar een functievector die vervolgens kan worden doorgegeven aan het logistieke regressie-algoritme om een model te maken. U voert al deze stappen op volgorde uit met behulp van een pijplijn.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Het model evalueren met behulp van een andere gegevensset
U kunt het model gebruiken dat u eerder hebt gemaakt om te voorspellen wat de resultaten van nieuwe inspecties zijn. De voorspellingen zijn gebaseerd op de schendingen die zijn waargenomen. U hebt dit model getraind op de gegevensset Food_Inspections1.csv. U kunt een tweede gegevensset, Food_Inspections2.csv, gebruiken om de sterkte van dit model op de nieuwe gegevens te evalueren . Deze tweede gegevensset (Food_Inspections2.csv) bevindt zich in de standaardopslagcontainer die is gekoppeld aan het cluster.
Voer de volgende code uit om een nieuw dataframe te maken, voorspellingenDf die de voorspelling bevat die door het model wordt gegenereerd. Het fragment maakt ook een tijdelijke tabel met de naam Voorspellingen op basis van het gegevensframe.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsAls het goed is, ziet u een uitvoer zoals de volgende tekst:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Bekijk een van de voorspellingen. Voer dit fragment uit:
predictionsDf.take(1)Er is een voorspelling voor de eerste vermelding in de testgegevensset.
De
model.transform()methode past dezelfde transformatie toe op nieuwe gegevens met hetzelfde schema en komt tot een voorspelling van hoe de gegevens moeten worden geclassificeerd. U kunt enkele statistieken uitvoeren om een beeld te krijgen van hoe de voorspellingen waren:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")De uitvoer ziet eruit als de volgende tekst:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateHet gebruik van logistieke regressie met Spark geeft u een model van de relatie tussen beschrijvingen van schendingen in het Engels. En of een bepaald bedrijf een voedselinspectie zou passeren of mislukken.
Een visuele weergave van de voorspelling maken
U kunt nu een definitieve visualisatie maken om u te helpen de testresultaten te beoordelen.
U begint met het extraheren van de verschillende voorspellingen en resultaten uit de tijdelijke tabel Voorspellingen die u eerder hebt gemaakt. De volgende query's scheiden de uitvoer als true_positive, false_positive, true_negative en false_negative. In de onderstaande query's schakelt u visualisatie uit met behulp van
-qen slaat u ook de uitvoer (met behulp van)-oop als dataframes die vervolgens kunnen worden gebruikt met de%%localmagie.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Gebruik ten slotte het volgende codefragment om de plot te genereren met matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')U moet de volgende uitvoer zien:
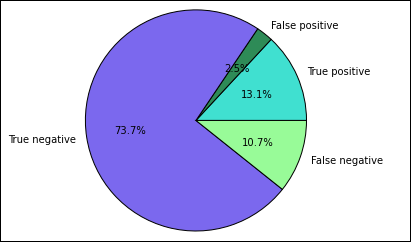
In dit diagram verwijst een positief resultaat naar de mislukte voedselinspectie, terwijl een negatief resultaat verwijst naar een geslaagde inspectie.
Het notitieblok afsluiten
Nadat u de toepassing hebt uitgevoerd, moet u het notebook afsluiten om de resources vrij te geven. Selecteer hiervoor Sluiten en stoppen in het menu Bestand van het notebook. Met deze actie wordt het notebook afgesloten en gesloten.