Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Dit notebook laat zien hoe u logboekgegevens analyseert met behulp van een aangepaste bibliotheek met Apache Spark in HDInsight. De aangepaste bibliotheek die we gebruiken, is een Python-bibliotheek met de naam iislogparser.py.
Vereiste voorwaarden
Een Apache Spark-cluster in HDInsight. Zie Apache Spark-clusters maken in Azure HDInsight voor instructies.
Onbewerkte gegevens opslaan als RDD
In deze sectie gebruiken we het Jupyter Notebook dat is gekoppeld aan een Apache Spark-cluster in HDInsight om taken uit te voeren die uw onbewerkte voorbeeldgegevens verwerken en opslaan als een Hive-tabel. De voorbeeldgegevens zijn een .csv bestand (hvac.csv) dat standaard beschikbaar is voor alle clusters.
Zodra uw gegevens zijn opgeslagen als een Apache Hive-tabel, maken we in de volgende sectie verbinding met de Hive-tabel met behulp van BI-hulpprogramma's zoals Power BI en Tableau.
Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net/jupyter, waarbijCLUSTERNAMEde naam van uw cluster is.Maak een nieuw notitieblok. Selecteer Nieuw en vervolgens PySpark.
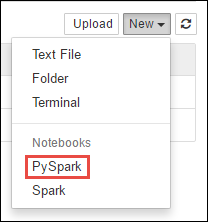 Notebook" border="true":::
Notebook" border="true":::Er wordt een nieuwe notebook gemaakt en geopend met de naam Untitled.pynb. Selecteer de naam van het notitieblok bovenaan en voer een simpele, herkenbare naam in.
Omdat u een notebook hebt gemaakt met behulp van de PySpark-kernel, hoeft u geen contexten expliciet te maken. De Spark- en Hive-contexten worden automatisch voor u gemaakt wanneer u de eerste codecel uitvoert. U kunt beginnen met het importeren van de typen die vereist zijn voor dit scenario. Plak het volgende fragment in een lege cel en druk op Shift+Enter.
from pyspark.sql import Row from pyspark.sql.types import *Maak een RDD met behulp van de voorbeeldlogboekgegevens die al beschikbaar zijn op het cluster. U kunt toegang krijgen tot de gegevens in het standaardopslagaccount dat is gekoppeld aan het cluster op
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log. Voer de volgende code uit:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Haal een voorbeeldlogboekset op om te controleren of de vorige stap is voltooid.
logs.take(5)U zou een uitvoer moeten zien die lijkt op de volgende tekst:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Logboekgegevens analyseren met behulp van een aangepaste Python-bibliotheek
In de bovenstaande uitvoer bevatten de eerste paar regels de headergegevens en elke resterende regel komt overeen met het schema dat in die header wordt beschreven. Het parseren van dergelijke logboeken kan ingewikkeld zijn. We gebruiken dus een aangepaste Python-bibliotheek (iislogparser.py) die het parseren van dergelijke logboeken veel eenvoudiger maakt. Deze bibliotheek is standaard opgenomen in uw Spark-cluster in HDInsight op
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py.Deze bibliotheek bevindt zich echter niet in de
PYTHONPATHbibliotheek, zodat we deze niet kunnen gebruiken met behulp van een importinstructie zoalsimport iislogparser. Als u deze bibliotheek wilt gebruiken, moet u deze distribueren naar alle werkknooppunten. Voer het volgende codefragment uit.sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparserbiedt een functieparse_log_linedie retourneertNoneals een logboekregel een veldnamenrij is en een exemplaar van deLogLineklasse retourneert als er een logboeklijn wordt aangeroepen. Gebruik deLogLineklasse om alleen de logboeklijnen uit de RDD te extraheren:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Haal een aantal geëxtraheerde logboekregels op om te controleren of de stap is voltooid.
logLines.take(2)De uitvoer moet er ongeveer uitzien als de volgende tekst:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]De
LogLineklasse heeft op zijn beurt enkele nuttige methoden, zoalsis_error(), die retourneert of een logboekvermelding een foutcode heeft. Gebruik deze klasse om het aantal fouten in de geëxtraheerde logboekregels te berekenen en alle fouten vervolgens in een ander bestand te registreren.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')De uitvoer moet de status
There are 30 errors and 646 log entrieshebben.U kunt Matplotlib ook gebruiken om een visualisatie van de gegevens te maken. Als u bijvoorbeeld de oorzaak wilt isoleren van aanvragen die lange tijd worden uitgevoerd, wilt u mogelijk de bestanden vinden die de meeste tijd in beslag nemen om gemiddeld te verwerken. Met het onderstaande codefragment worden de top 25 resources opgehaald die de meeste tijd hebben genomen om een oproep te beantwoorden.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])U zou een uitvoer moeten zien zoals de volgende tekst:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]U kunt deze informatie ook presenteren in de vorm van een plot. Als eerste stap voor het maken van een plot maken we eerst een tijdelijke tabel AverageTime. De tabel groepeert de logboeken op tijd om te zien of er op een bepaald moment ongebruikelijke latentiepieken waren.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')Vervolgens kunt u de volgende SQL-query uitvoeren om alle records in de tabel AverageTime op te halen.
%%sql -o averagetime SELECT * FROM AverageTimeDe
%%sqlmagie gevolgd door-o averagetimezorgt ervoor dat de uitvoer van de query lokaal wordt bewaard op de Jupyter-server (meestal het hoofdknooppunt van het cluster). De output wordt bewaard als een Pandas-dataframe met de opgegeven naam averagetime.U zou een uitvoer zoals de volgende afbeelding moeten zien.
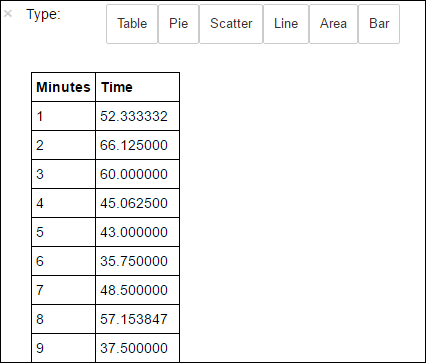 yter sql query output" border="true":::
yter sql query output" border="true":::Zie Parameters die worden ondersteund met de %%sql magic voor meer informatie over de
%%sqlmagie.U kunt nu Matplotlib, een bibliotheek die wordt gebruikt om visualisatie van gegevens samen te stellen, gebruiken om een plot te maken. Omdat de plot moet worden gemaakt op basis van het lokaal persistente dataframe voor gemiddelde tijd , moet het codefragment beginnen met de
%%localmagie. Dit zorgt ervoor dat de code lokaal wordt uitgevoerd op de Jupyter-server.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')U zou een uitvoer moeten zien zoals de volgende afbeelding:
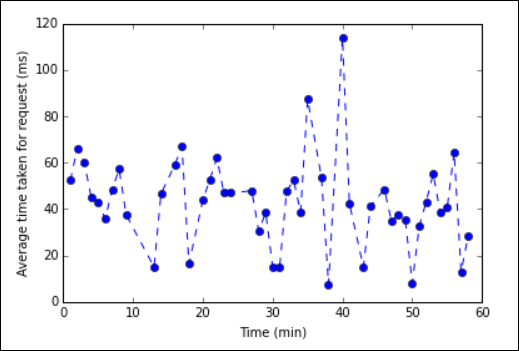 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::Nadat u de toepassing hebt uitgevoerd, moet u het notebook afsluiten om de resources vrij te geven. Selecteer hiervoor Sluiten en stoppen in het menu Bestand van het notebook. Met deze actie wordt het notitieblok uitgeschakeld en gesloten.
Volgende stappen
Bekijk de volgende artikelen: