Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Apache Spark Streaming biedt verwerking van gegevensstromen in HDInsight Spark-clusters. Met een garantie dat elke invoergebeurtenis exact eenmaal wordt verwerkt, zelfs als er een knooppuntfout optreedt. Een Spark Stream is een langlopende taak die invoergegevens ontvangt van een groot aantal bronnen, waaronder Azure Event Hubs. Ook: Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ ruwe TCP-sockets, of door het monitoren van Apache Hadoop YARN-bestandssystemen. In tegenstelling tot een alleen gebeurtenisgestuurd proces, worden invoergegevens door een Spark Stream in tijdvensters gebatched. Zoals een segment van 2 seconden en transformeert vervolgens elke batch met gegevens met behulp van toewijzings-, reduce-, join- en extract-bewerkingen. De Spark Stream schrijft vervolgens de getransformeerde gegevens naar bestandssysteem, databases, dashboards en de console.
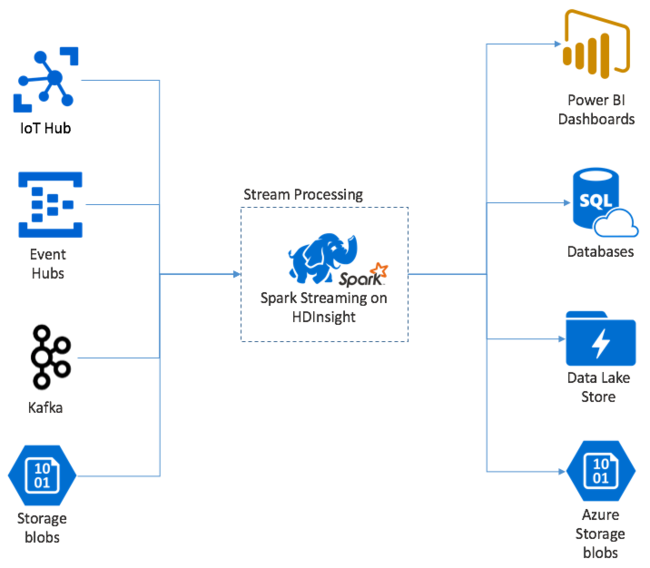
Spark Streaming-toepassingen moeten een fractie van een seconde wachten om elk van de micro-batch gebeurtenissen te verzamelen voordat die batch wordt verzonden voor verwerking. Een gebeurtenisgestuurde toepassing verwerkt daarentegen elke gebeurtenis onmiddellijk. Spark Streaming-latentie duurt doorgaans minder dan een paar seconden. De voordelen van de microbatchbenadering zijn efficiëntere gegevensverwerking en eenvoudigere statistische berekeningen.
Inleiding tot de DStream
Spark Streaming vertegenwoordigt een continue stroom van binnenkomende gegevens met behulp van een discretized stream , een DStream genoemd. Een DStream kan worden gemaakt op basis van invoerbronnen zoals Event Hubs of Kafka. Of door transformaties toe te passen op een andere DStream.
Een DStream biedt een abstractielaag boven op de onbewerkte gebeurtenisgegevens.
Begin met één gebeurtenis, bijvoorbeeld een temperatuurmeting van een aangesloten thermostaat. Wanneer deze gebeurtenis binnenkomt bij uw Spark Streaming-toepassing, wordt de gebeurtenis op een betrouwbare manier opgeslagen, waar deze op meerdere knooppunten wordt gerepliceerd. Deze fouttolerantie zorgt ervoor dat de fout van één knooppunt niet resulteert in het verlies van uw gebeurtenis. De Spark-kern maakt gebruik van een gegevensstructuur die gegevens over meerdere knooppunten in het cluster distribueert. Waar elk knooppunt over het algemeen zijn eigen gegevens in het geheugen onderhoudt voor de beste prestaties. Deze gegevensstructuur wordt een tolerante gedistribueerde gegevensset (RDD) genoemd.
Elke RDD vertegenwoordigt gebeurtenissen die zijn verzameld over een door de gebruiker gedefinieerd tijdsbestek, het batchinterval. Wanneer elk batchinterval is verstreken, wordt er een nieuwe RDD geproduceerd die alle gegevens uit dat interval bevat. De continue set RDD's wordt verzameld in een DStream. Als het batchinterval bijvoorbeeld één seconde lang is, verzendt uw DStream elke seconde een batch met één RDD die alle gegevens bevat die tijdens die seconde zijn opgenomen. Bij het verwerken van de DStream wordt de temperatuurgebeurtenis weergegeven in een van deze batches. Een Spark Streaming-toepassing verwerkt de batches die de gebeurtenissen bevatten en handelt uiteindelijk op de gegevens die zijn opgeslagen in elke RDD.
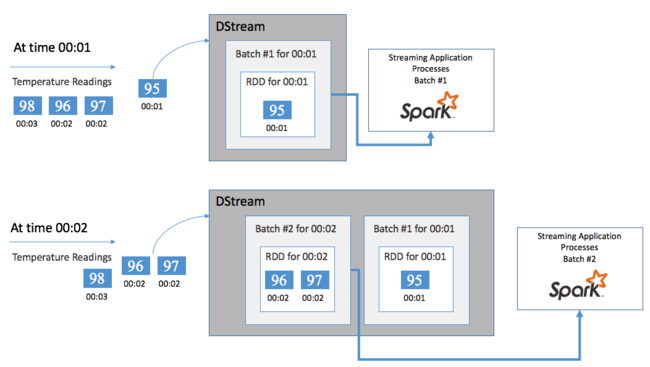
Structuur van een Spark Streaming-toepassing
Een Spark Streaming-toepassing is een langdurige toepassing die gegevens van ingevoerde bronnen ontvangt. Hiermee worden transformaties toegepast om de gegevens te verwerken en worden de gegevens vervolgens naar een of meer bestemmingen gepusht. De structuur van een Spark Streaming-toepassing heeft een statisch onderdeel en een dynamisch onderdeel. Het statische onderdeel definieert waar de gegevens vandaan komen, welke verwerking op de gegevens moet worden uitgevoerd. En waar de resultaten naartoe moeten gaan. Het dynamische onderdeel voert de toepassing voor onbepaalde tijd uit en wacht op een stopsignaal.
De volgende eenvoudige toepassing ontvangt bijvoorbeeld een tekstregel via een TCP-socket en telt het aantal keren dat elk woord wordt weergegeven.
De toepassing definiëren
De definitie van de toepassingslogica heeft vier stappen:
- Maak een StreamingContext.
- Maak een DStream op basis van streamingcontext.
- Transformaties toepassen op de DStream.
- Voer de resultaten uit.
Deze definitie is statisch en er worden geen gegevens verwerkt totdat u de toepassing uitvoert.
Een StreamingContext maken
Maak een StreamingContext vanuit de SparkContext die naar uw cluster verwijst. Wanneer u een StreamingContext maakt, geeft u de grootte van de batch in seconden op, bijvoorbeeld:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Een DStream maken
Maak met het StreamingContext-exemplaar een invoer-DStream voor uw invoerbron. In dit geval kijkt de toepassing naar het uiterlijk van nieuwe bestanden in de standaard bijgevoegde opslag.
val lines = ssc.textFileStream("/uploads/Test/")
Transformaties toepassen
U implementeert de verwerking door transformaties toe te passen op de DStream. Deze toepassing ontvangt één regel tekst tegelijk van het bestand en splitst elke regel in woorden. En gebruikt vervolgens een map-reduce patroon om het aantal keren te tellen dat elk woord voorkomt.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Uitvoerresultaten
Push de transformatieresultaten naar de doelsystemen door uitvoerbewerkingen toe te passen. In dit geval wordt het resultaat van elke uitvoering door de berekening afgedrukt in de console-uitvoer.
wordCounts.print()
De toepassing uitvoeren
Start de streamingtoepassing en voer deze uit totdat er een beëindigingssignaal wordt ontvangen.
ssc.start()
ssc.awaitTermination()
Zie de Apache Spark Streaming-programmeerhandleiding voor meer informatie over de Spark Stream-API.
De volgende voorbeeldtoepassing is zelfstandig, zodat u deze in een Jupyter Notebook kunt uitvoeren. In dit voorbeeld wordt een gesimuleerde gegevensbron gemaakt in de klasse DummySource die elke vijf seconden de waarde van een teller en de huidige tijd in milliseconden uitvoert. Een nieuw StreamingContext-object heeft een batchinterval van 30 seconden. Telkens wanneer een batch wordt gemaakt, onderzoekt de streamingtoepassing de geproduceerde RDD. Converteert vervolgens de RDD naar een Spark DataFrame en maakt een tijdelijke tabel over het DataFrame.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Wacht ongeveer 30 seconden nadat u de bovenstaande toepassing hebt gestart. Vervolgens kunt u periodiek een query uitvoeren op het DataFrame om de huidige set waarden in de batch weer te geven, bijvoorbeeld met behulp van deze SQL-query:
%%sql
SELECT * FROM demo_numbers
De resulterende uitvoer ziet eruit als de volgende uitvoer:
| waarde | tijd |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Er zijn zes waarden, omdat dummySource elke 5 seconden een waarde maakt en de toepassing elke 30 seconden een batch verzendt.
Schuifvensters
Als u aggregaties wilt uitvoeren voor uw DStream gedurende een bepaalde periode, bijvoorbeeld om een gemiddelde temperatuur te krijgen gedurende de afgelopen twee seconden, gebruikt u de sliding window bewerkingen die zijn opgenomen in Spark Streaming. Een schuifvenster heeft een duur (de lengte van het venster) en het interval waarin de inhoud van het venster wordt geëvalueerd (het schuifinterval).
Schuifvensters kunnen elkaar overlappen. Bijvoorbeeld, je kunt een venster definiëren met een lengte van twee seconden dat elke seconde verschuift. Deze actie betekent dat telkens wanneer u een aggregatieberekening uitvoert, het venster gegevens uit de laatste seconde van het vorige venster bevat. En eventuele nieuwe gegevens in de volgende seconde.
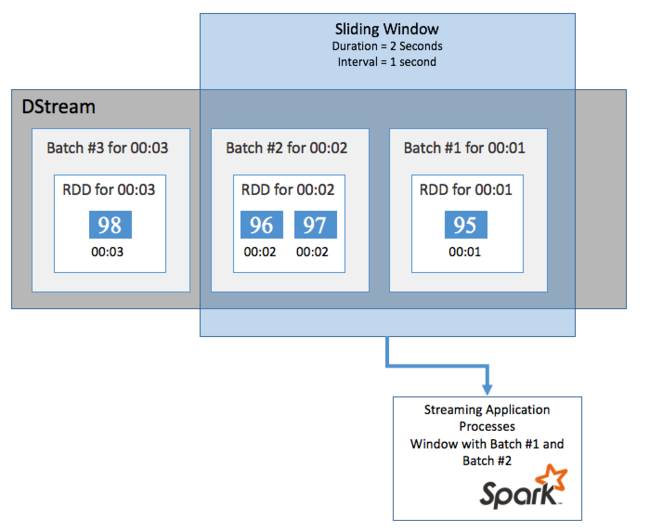
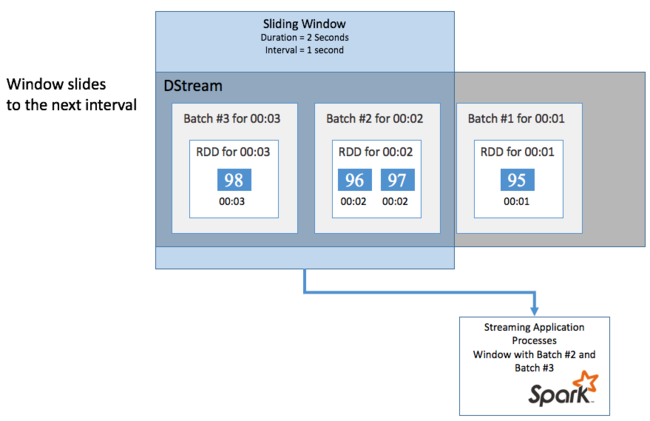
In het volgende voorbeeld wordt de code bijgewerkt die gebruikmaakt van de DummySource, om de batches in een venster te verzamelen met een duur van één minuut en een dia van één minuut.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Na de eerste minuut zijn er 12 vermeldingen: zes vermeldingen uit elk van de twee batches die in het venster zijn verzameld.
| waarde | tijd |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
De schuivende vensterfuncties die beschikbaar zijn in de Spark Streaming-API zijn onder andere venster, countByWindow, reduceByWindow en countByValueAndWindow. Zie Transformaties in DStreams voor meer informatie over deze functies.
Controlepunten maken
Voor het leveren van tolerantie en fouttolerantie is Spark Streaming afhankelijk van controlepunten om ervoor te zorgen dat stroomverwerking ononderbroken kan worden voortgezet, zelfs als er knooppuntfouten optreden. Spark maakt controlepunten voor duurzame opslag (Azure Storage of Data Lake Storage). Deze controlepunten slaan metagegevens van streamingtoepassingen op, zoals de configuratie en de bewerkingen die door de toepassing zijn gedefinieerd. Ook alle batches die in de wachtrij zijn geplaatst, maar nog niet zijn verwerkt. Soms omvatten de controlepunten ook het opslaan van de gegevens in de RDD's, zodat Spark de datatoestand sneller kan herbouwen op basis van wat aanwezig is in de RDD's die het beheert.
Spark Streaming-toepassingen implementeren
Doorgaans bouwt u een Spark Streaming-toepassing lokaal in een JAR-bestand. Implementeer het vervolgens in Spark in HDInsight door het JAR-bestand te kopiëren naar de standaard gekoppelde opslag. U kunt uw toepassing starten met de LIVY REST API's die beschikbaar zijn in uw cluster met behulp van een POST-bewerking. De hoofdtekst van de POST bevat een JSON-document dat het pad naar uw JAR biedt. En de naam van de klasse waarvan de hoofdmethode de streamingtoepassing definieert en uitvoert, en eventueel de resourcevereisten van de taak (zoals het aantal uitvoerders, geheugen en kernen). Daarnaast zijn alle configuratie-instellingen vereist die uw toepassingscode vereist.
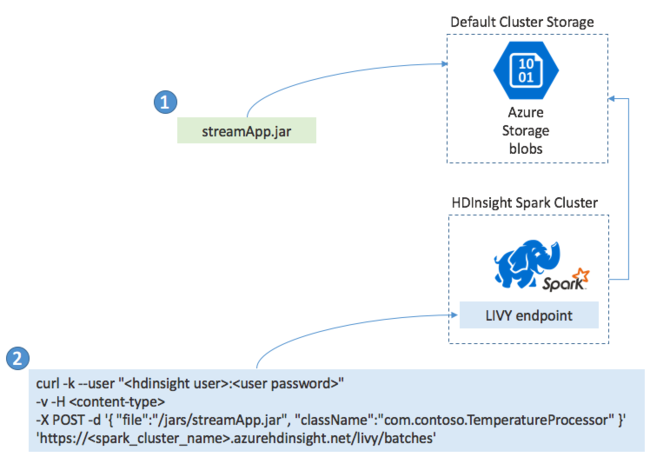
De status van alle toepassingen kan ook worden gecontroleerd met een GET-aanvraag voor een LIVY-eindpunt. Ten slotte kunt u een actieve toepassing beëindigen door een DELETE-aanvraag uit te geven voor het LIVY-eindpunt. Zie Externe taken met Apache LIVY voor meer informatie over de LIVY-API