Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
HDInsight Spark-clusters bevatten Apache Zeppelin-notebooks . Gebruik de notebooks om Apache Spark-taken uit te voeren. In dit artikel leert u hoe u het Zeppelin-notebook gebruikt in een HDInsight-cluster.
Vereisten
- Een Apache Spark-cluster in HDInsight. Zie Apache Spark-clusters maken in Azure HDInsight voor instructies.
- Het URI-schema voor de primaire opslag voor uw clusters. Het schema is
wasb://voor Azure Blob Storage,abfs://voor Azure Data Lake Storage Gen2 ofadl://voor Azure Data Lake Storage Gen1. Als beveiligde overdracht is ingeschakeld voor Blob Storage, zou de URI zijnwasbs://. Zie Veilige overdracht in Azure Storage vereisen voor meer informatie.
Een Apache Zeppelin-notebook starten
Selecteer in het overzicht van het Spark-cluster de optie Zeppelin-notebook in clusterdashboards. Voer de beheerdersreferenties voor het cluster in.
Notitie
U kunt ook de Zeppelin Notebook voor uw cluster bereiken door de volgende URL in uw browser te openen. Vervang CLUSTERNAME door de naam van uw cluster.
https://CLUSTERNAME.azurehdinsight.net/zeppelinMaak een nieuwe notebook. Navigeer vanuit het koptekstvenster naar Notitieblok>Nieuwe notitie maken.
Voer een naam in voor het notitieblok en selecteer Notitie maken.
Zorg ervoor dat de koptekst van het notitieblok een verbonden status weergeeft. Het wordt aangeduid met een groene stip in de rechterbovenhoek.
Laad voorbeeldgegevens in een tijdelijke tabel. Wanneer u een Spark-cluster maakt in HDInsight, wordt het voorbeeldgegevensbestand
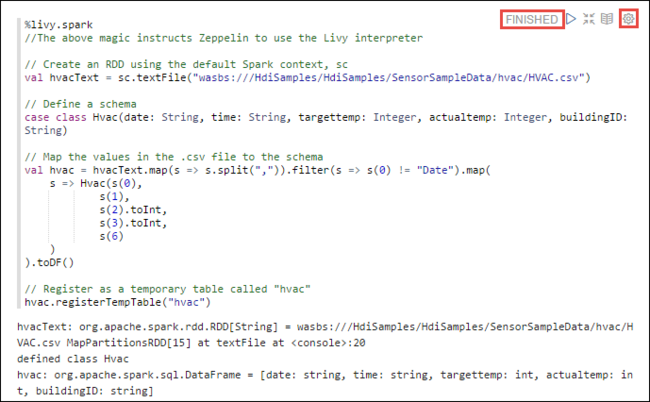
hvac.csvgekopieerd naar het bijbehorende opslagaccount onder\HdiSamples\SensorSampleData\hvac.Plak in de lege alinea die standaard is gemaakt in het nieuwe notitieblok het volgende fragment.
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Druk op Shift+Enter of selecteer de knop Afspelen voor de alinea om het fragment uit te voeren. De status in de rechterhoek van de alinea moet gaan van GEREED, IN BEHANDELING, LOPEND tot VOLTOOID. De uitvoer wordt onder aan dezelfde alinea weergegeven. De schermopname ziet er als volgt uit:
U kunt ook een titel opgeven voor elke alinea. Selecteer in de rechterhoek van de alinea het pictogram Instellingen (tandwiel) en selecteer vervolgens Titel weergeven.
Notitie
%spark2-interpreter wordt niet ondersteund in Zeppelin-notebooks in alle HDInsight-versies en %sh-interpreter wordt niet ondersteund vanaf HDInsight 4.0 en hoger.
U kunt nu Spark SQL-instructies uitvoeren in de
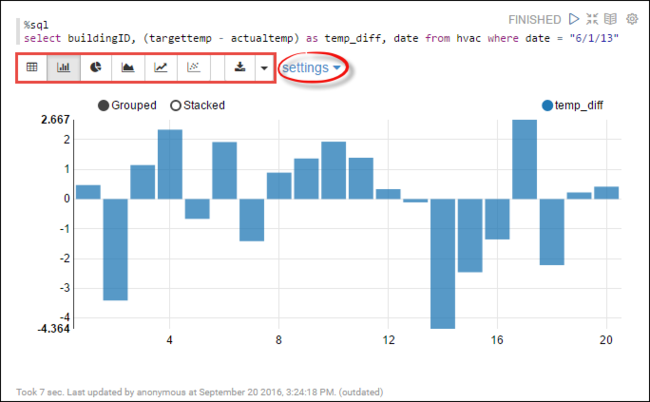
hvactabel. Plak de volgende query in een nieuwe alinea. De query haalt de gebouw-id op. Ook het verschil tussen het doel en de werkelijke temperaturen voor elk gebouw op een bepaalde datum. Druk op Shift+Enter.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"De instructie %sql aan het begin geeft aan dat het notebook de Livy Scala-interpreter moet gebruiken.
Selecteer het pictogram Staafdiagram om de weergave te wijzigen. instellingen worden weergegeven nadat u staafdiagram hebt geselecteerd, zodat u sleutels en waarden kunt kiezen. In de volgende schermopname ziet u de uitvoer.
U kunt ook Spark SQL-instructies uitvoeren met behulp van variabelen in de query. Het volgende codefragment laat zien hoe u een variabele definieert,
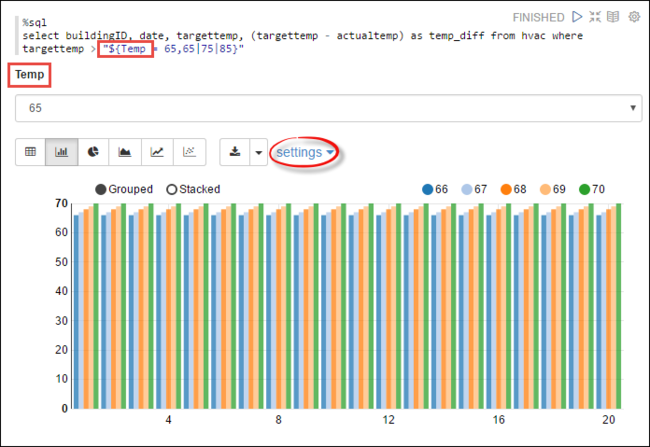
Tempin de query met de mogelijke waarden waarmee u een query wilt uitvoeren. Wanneer u de query voor het eerst uitvoert, wordt er automatisch een vervolgkeuzelijst ingevuld met de waarden die u voor de variabele hebt opgegeven.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Plak dit fragment in een nieuwe alinea en druk op Shift+Enter. Selecteer vervolgens 65 in de dropdownlijst Temp.
Selecteer het pictogram Staafdiagram om de weergave te wijzigen. Selecteer vervolgens instellingen en breng de volgende wijzigingen aan.
Groepen: Voeg targettemp toe.
Waarden: 1. Datum verwijderen. 2. Voeg temp_diff toe. 3. Wijzig de aggregator van SUM in AVG.
In de volgende schermopname ziet u de uitvoer.
Hoe kan ik externe pakketten gebruiken met het notebook?
Zeppelin-notebook in een Apache Spark-cluster op HDInsight kan gebruikmaken van externe pakketten die door de community zijn bijgedragen en niet zijn opgenomen in het cluster. Zoek in de Maven-opslagplaats naar de volledige lijst met beschikbare pakketten. U kunt ook een lijst met beschikbare pakketten ophalen uit andere bronnen. Er is bijvoorbeeld een volledige lijst met door de community bijgedragen pakketten beschikbaar op Spark-pakketten.
In dit artikel ziet u hoe u het spark-CSV-pakket gebruikt met de Jupyter Notebook.
Open interpreterinstellingen. Selecteer in de rechterbovenhoek de aangemelde gebruikersnaam en selecteer vervolgens Interpreter.
Schuif naar livy2 en selecteer bewerken.
Ga naar de sleutel
livy.spark.jars.packagesen stel de waarde in de notatiegroup:id:versionin. Dus als u het spark-CSV-pakket wilt gebruiken, moet u de waarde van de sleutel instellen opcom.databricks:spark-csv_2.10:1.4.0.
Selecteer Opslaan en klik vervolgens op OK om de Livy-interpreter opnieuw op te starten.
Als u wilt weten hoe u de waarde van de ingevoerde sleutel bereikt, gaat u als volgt te werk.
a. Zoek het pakket in de Maven-opslagplaats. Voor dit artikel hebben we spark-csv gebruikt.
b. Verzamel in de opslagplaats de waarden voor GroupId, ArtifactId en Version.
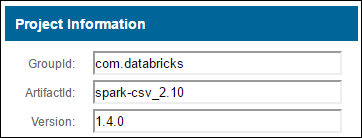
c. Voeg de drie waarden samen, gescheiden door een dubbele punt (:).
com.databricks:spark-csv_2.10:1.4.0
Waar worden de Zeppelin-notitieblokken opgeslagen?
De Zeppelin-notebooks zijn opgeslagen op de cluster-hoofdknooppunten. Dus als u het cluster verwijdert, worden de notebooks ook verwijderd. Als u uw notebooks wilt behouden voor later gebruik op andere clusters, moet u deze exporteren nadat u de taken hebt uitgevoerd. Als u een notitieblok wilt exporteren, selecteert u als volgt het pictogram Exporteren , zoals wordt weergegeven in de afbeelding.
Met deze actie wordt het notitieblok opgeslagen als een JSON-bestand op uw downloadlocatie.
Notitie
In HDI 4.0 is het pad naar de zeppelin-notebookdirectory,
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Bijvoorbeeld /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Gezien het feit dat HDI 5.0 en dit pad verschillend zijn
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Bijvoorbeeld /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
De opgeslagen bestandsnaam verschilt in HDI 5.0. Het wordt opgeslagen als
<notebook_name>_<sessionid>.zplnBijvoorbeeld testzeppelin_2JJK53XQA.zpln
In HDI 4.0 wordt de bestandsnaam note.json opgeslagen onder de session_id directory.
Bijvoorbeeld /2JMC9BZ8X/note.json
HDI Zeppelin slaat het notebook altijd op in het pad
/usr/hdp/<version>/zeppelin/notebook/op de lokale schijf van hn0.Als u wilt dat het notebook beschikbaar is, zelfs nadat het cluster is verwijderd, kunt u proberen om Azure File Storage (met behulp van het SMB-protocol) te gebruiken en deze te koppelen aan het lokale pad. Zie SMB Azure-bestandsshare koppelen in Linux voor meer informatie
Nadat u deze hebt gekoppeld, kunt u de zeppelin-configuratie zeppelin.notebook.dir wijzigen in het gekoppelde pad in de Ambari-gebruikersinterface.
- De SMB-bestandsshare als GitNotebookRepo-opslag wordt niet aanbevolen voor zeppelin versie 0.10.1
Gebruiken Shiro voor het configureren van toegang tot Zeppelin-interpreters in ESP-clusters (Enterprise Security Package)
Zoals hierboven vermeld, wordt de %sh interpreter niet ondersteund vanaf HDInsight 4.0.
%sh Aangezien de interpreter bovendien potentiële beveiligingsproblemen introduceert, zoals toegangssleuteltabs met behulp van shell-opdrachten, is deze ook verwijderd uit HDInsight 3.6 ESP-clusters. Dit betekent dat %sh interpreter niet beschikbaar is wanneer u standaard op Nieuwe notitie maken of in de gebruikersinterface van de interpreter klikt.
Bevoegde domeingebruikers kunnen het Shiro.ini bestand gebruiken om de toegang tot de interpretergebruikersinterface te beheren. Alleen deze gebruikers kunnen nieuwe %sh interpreters maken en machtigingen instellen voor elke nieuwe %sh interpreter. Gebruik de volgende stappen om de toegang te beheren met behulp van het shiro.ini bestand:
Definieer een nieuwe rol met behulp van een bestaande domeinnaam. In het volgende voorbeeld
adminGroupNameis dit een groep bevoegde gebruikers in Microsoft Entra ID. Gebruik geen speciale tekens of spaties in de groepsnaam. De tekens na=geven de machtigingen voor deze rol.*betekent dat de groep volledige machtigingen heeft.[roles] adminGroupName = *Voeg de nieuwe rol toe voor toegang tot Zeppelin-interpreters. In het volgende voorbeeld krijgen alle gebruikers in
adminGroupNametoegang tot Zeppelin-interpreters en kunnen ze nieuwe interpreters aanmaken. U kunt meerdere rollen tussen de haakjes plaatsenroles[], gescheiden door komma's. Gebruikers met de benodigde machtigingen hebben vervolgens toegang tot Zeppelin-interpreters.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Voorbeeld shiro.ini voor meerdere domeingroepen:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy-sessiebeheer
Met de eerste codealinea in uw Zeppelin-notebook maakt u een nieuwe Livy-sessie in uw cluster. Deze sessie wordt gedeeld in alle Zeppelin-notebooks die u later maakt. Als de Livy-sessie om welke reden dan ook wordt beëindigd, kunnen taken niet worden uitgevoerd vanuit het Zeppelin-notebook.
In dat geval moet u de volgende stappen uitvoeren voordat u taken vanuit een Zeppelin-notebook kunt uitvoeren.
Start de Livy-interpreter opnieuw vanuit het Zeppelin-notitieblok. Hiervoor opent u de interpreterinstellingen door de aangemelde gebruikersnaam in de rechterbovenhoek te selecteren en vervolgens Interpreter te selecteren.
Schuif naar Livy2 en selecteer opnieuw opstarten.
Voer een codecel uit vanuit een bestaand Zeppelin-notebook. Met deze code maakt u een nieuwe Livy-sessie in het HDInsight-cluster.
Algemene informatie
Service valideren
Als u de service vanuit Ambari wilt valideren, gaat u naar https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary de locatie waar CLUSTERNAME de naam van uw cluster is.
Gebruik SSH op het hoofdknooppunt om de service vanaf een opdrachtregel te valideren. Schakel gebruikers over naar zeppelin met behulp van de opdracht sudo su zeppelin. Statusopdrachten:
| Opdracht | Beschrijving |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Service status. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Serviceversie. |
ps -aux | grep zeppelin |
Pid identificeren. |
Locaties van logbestanden
| Dienst | Pad |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Serverlogboeken | /var/log/zeppelin |
Configuratie-interpreter, Shirosite.xml, log4j |
/usr/hdp/current/zeppelin-server/conf of /etc/zeppelin/conf |
| PID-map | /var/run/zeppelin |
Logboekregistratie voor foutopsporing inschakelen
Navigeer naar
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summaryde locatie waar CLUSTERNAME de naam van uw cluster is.Navigeer naar CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content.
Wijzigen
log4j.appender.dailyfile.Threshold = INFOinlog4j.appender.dailyfile.Threshold = DEBUG.Toevoegen
log4j.logger.org.apache.zeppelin.realm=DEBUG.Sla wijzigingen op en start de service opnieuw op.