Wat is geautomatiseerde machine learning (AutoML)?
VAN TOEPASSING OP: Python SDK azure-ai-ml v2 (actueel)
Python SDK azure-ai-ml v2 (actueel)
Geautomatiseerde machine learning, ook wel geautomatiseerd ML of AutoML genoemd, is het automatiseren van de tijdrovende, iteratieve taken van het ontwikkelen van machine learning-modellen. Hiermee kunnen gegevenswetenschappers, analisten en ontwikkelaars ML-modellen bouwen met hoge schaal, efficiëntie en productiviteit en tegelijkertijd de kwaliteit van het model behouden. Geautomatiseerde ML in Azure Machine Learning is gebaseerd op een doorbraak van de afdeling Microsoft Research.
- Installeer de Azure Machine Learning Python SDK voor ervaren klanten met code. Aan de slag met zelfstudie: Een objectdetectiemodel trainen (preview) met AutoML en Python.
Hoe werkt AutoML?
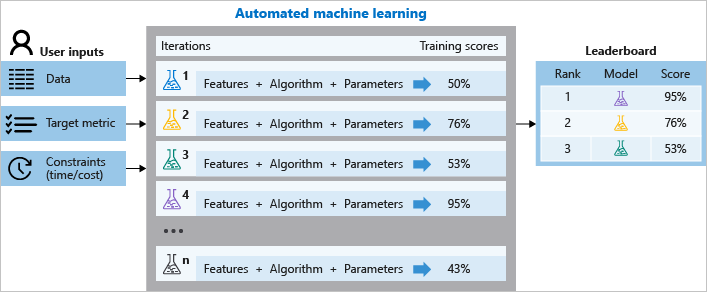
Tijdens de training maakt Azure Machine Learning veel pijplijnen parallel die verschillende algoritmen en parameters voor u proberen. De service doorloopt ML-algoritmen die zijn gekoppeld aan functieselecties, waarbij elke iteratie een model produceert met een trainingsscore. Hoe beter de score voor de metrische gegevens waarvoor u wilt optimaliseren, hoe beter het model wordt beschouwd als 'passend' voor uw gegevens. Deze stopt zodra deze de afsluitcriteria bereikt die in het experiment zijn gedefinieerd.
Met Behulp van Azure Machine Learning kunt u uw geautomatiseerde ML-trainingsexperimenten ontwerpen en uitvoeren met de volgende stappen:
Identificeer het ML-probleem dat moet worden opgelost: classificatie, prognose, regressie, computer vision of NLP.
Kies of u een code-first-ervaring of een no-code studio-webervaring wilt: gebruikers die de voorkeur geven aan een code-first-ervaring, kunnen gebruikmaken van de Azure Machine Learning SDKv2 of de Azure Machine Learning CLIv2. Aan de slag met zelfstudie: Een objectdetectiemodel trainen met AutoML en Python. Gebruikers die liever een beperkte of geen code-ervaring hebben, kunnen de webinterface gebruiken in Azure Machine Learning-studio op https://ml.azure.com. Aan de slag met zelfstudie: Een classificatiemodel maken met geautomatiseerde ML in Azure Machine Learning.
Geef de bron op van de gelabelde trainingsgegevens: U kunt uw gegevens op veel verschillende manieren naar Azure Machine Learning overbrengen.
Configureer de geautomatiseerde machine learning-parameters die bepalen hoeveel iteraties er zijn voor verschillende modellen, hyperparameterinstellingen, geavanceerde preprocessing/featurization en welke metrische gegevens moeten worden bekeken bij het bepalen van het beste model.
Dien de trainingstaak in.
Bekijk de resultaten.
In het volgende diagram ziet u dit proces.
U kunt ook de vastgelegde taakgegevens inspecteren, die metrische gegevens bevatten die tijdens de taak zijn verzameld. De trainingstaak produceert een geserialiseerd Python-object (.pkl bestand) dat het model en de voorverwerking van gegevens bevat.
Hoewel het bouwen van modellen geautomatiseerd is, kunt u ook leren hoe belangrijk of relevante functies zijn voor de gegenereerde modellen.
Wanneer gebruikt u AutoML: classificatie, regressie, prognose, computer vision, & NLP
Pas geautomatiseerde ML toe wanneer u wilt dat Azure Machine Learning een model voor u traint en afstemt met behulp van de doelmetrieken die u opgeeft. Geautomatiseerde ML democratiseert het machine learning-modelontwikkelingsproces en stelt de gebruikers, ongeacht hun expertise op het gebied van gegevenswetenschap, in staat om een end-to-end machine learning-pijplijn te identificeren voor elk probleem.
ML-professionals en -ontwikkelaars in verschillende branches kunnen geautomatiseerde ML gebruiken om:
- ML-oplossingen implementeren zonder uitgebreide programmeerkennis
- Tijd en resources besparen
- Best practices voor data science toepassen
- Flexibele probleemoplossing bieden
Classificatie
Classificatie is een type leren onder supervisie waarin modellen leren trainingsgegevens te gebruiken en die leerresultaten toe te passen op nieuwe gegevens. Azure Machine Learning biedt specifieke featurizations voor deze taken, zoals tekst-featurizers van Deep Neural Network voor classificatie. Zie Data featurization voor meer informatie over de opties voor featurisatie. U vindt ook de lijst met algoritmen die door AutoML worden ondersteund op Ondersteunde algoritmen.
Het belangrijkste doel van classificatiemodellen is om te voorspellen in welke categorieën nieuwe gegevens vallen op basis van het leren van de trainingsgegevens. Veelvoorkomende classificatievoorbeelden zijn fraudedetectie, handschriftherkenning en objectdetectie.
Bekijk een voorbeeld van classificatie en geautomatiseerde machine learning in dit Python-notebook: Bank Marketing.
Regressie
Net als bij classificatie zijn regressietaken ook een algemene leertaak onder supervisie. Azure Machine Learning biedt functionaliteit die specifiek is voor regressieproblemen. Meer informatie over featurization-opties. U vindt ook de lijst met algoritmen die door AutoML worden ondersteund op Ondersteunde algoritmen.
Afgezien van classificatie waarbij voorspelde uitvoerwaarden categorisch zijn, voorspellen regressiemodellen numerieke uitvoerwaarden op basis van onafhankelijke voorspellers. In regressie is het doel om te helpen de relatie tot stand te brengen tussen deze onafhankelijke voorspellingsvariabelen door te schatten hoe één variabele de andere beïnvloedt. Het model kan bijvoorbeeld de prijs van auto's voorspellen op basis van functies zoals benzinekilometers en veiligheidsclassificatie.
Bekijk een voorbeeld van regressie en geautomatiseerde machine learning voor voorspellingen in deze Python-notebooks: Hardwareprestaties.
Prognoses met tijdreeksen
Het maken van prognoses maakt integraal onderdeel uit van elk bedrijf, of het nu gaat om omzet-, voorraad-, verkoop- of klantvraagprognoses. U kunt geautomatiseerde ML gebruiken om technieken en methoden van aanpak met elkaar te combineren om een aanbeveling voor een hoogwaardige tijdreeksprognose te krijgen. U vindt de lijst met algoritmen die door AutoML worden ondersteund op Ondersteunde algoritmen.
Een geautomatiseerd tijdreeksexperiment wordt behandeld als een multivariate regressieprobleem. Waarden uit de afgelopen tijdreeks worden 'pivoted' om meer dimensies voor de regressor te worden, samen met andere voorspellingen. Deze benadering, in tegenstelling tot klassieke tijdreeksmethoden, heeft een voordeel van het natuurlijk opnemen van meerdere contextuele variabelen en hun relatie met elkaar tijdens de training. Geautomatiseerde ML leert één, maar vaak intern vertakt model voor alle items in de gegevensset en voorspellingshorizmen. Er zijn dus meer gegevens beschikbaar voor het schatten van modelparameters en het wordt mogelijk om de reeksen te generaliseren.
Geavanceerde configuratie voor prognose omvat:
- Vakantiedetectie en featurization
- Tijdreeks en DNN-cursisten (Auto-ARIMA, Prophet, ForecastTCN)
- Veel modellen ondersteunen via groepering
- Kruisvalidatie van rolling-origin
- Configureerbare vertragingen
- Functies voor aggregatie van doorlopende vensters
Bekijk een voorbeeld van prognose en geautomatiseerde machine learning in dit Python-notebook: Energievraag.
Computer Vision
Met ondersteuning voor Computer Vision-taken kunt u eenvoudig modellen genereren die zijn getraind op afbeeldingsgegevens voor scenario's zoals afbeeldingsclassificatie en objectdetectie.
Met deze mogelijkheid kunt u het volgende doen:
- Naadloos integreren met de mogelijkheid voor gegevenslabels van Azure Machine Learning.
- Gebruik gelabelde gegevens voor het genereren van afbeeldingsmodellen.
- Optimaliseer de modelprestaties door het modelalgoritmen op te geven en de hyperparameters af te stemmen.
- Download of implementeer het resulterende model als een webservice in Azure Machine Learning.
- Operationeel op schaal, waarbij gebruik wordt gemaakt van de mogelijkheden van Azure Machine Learning MLOps en ML Pipelines .
Het ontwerpen van AutoML-modellen voor vision-taken wordt ondersteund via de Azure Machine Learning Python SDK. De resulterende experimententaken, modellen en uitvoer kunnen worden geopend vanuit de gebruikersinterface van Azure Machine Learning-studio.
Meer informatie over het instellen van AutoML-training voor Computer Vision-modellen.
 Afbeelding van: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Afbeelding van: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Geautomatiseerde ML voor afbeeldingen ondersteunt de volgende Computer Vision-taken:
| Taak | Beschrijving |
|---|---|
| Afbeeldingsclassificatie met meerdere klassen | Taken waarbij een afbeelding wordt geclassificeerd met slechts één label uit een reeks klassen, bijvoorbeeld elke afbeelding wordt geclassificeerd als een afbeelding van een 'kat' of een 'hond' of een 'eend'. |
| Afbeeldingsclassificatie met meerdere labels | Taken waarbij een afbeelding een of meer labels van een set labels kan hebben, kan een afbeelding bijvoorbeeld worden gelabeld met zowel 'kat' als 'hond'. |
| Objectdetectie | Taken voor het identificeren van objecten in een afbeelding en het vinden van elk object met een begrenzingsvak, bijvoorbeeld alle honden en katten in een afbeelding zoeken en een begrenzingsvak rond elk object tekenen. |
| Instantiesegmentatie | Taken voor het identificeren van objecten in een afbeelding op pixelniveau, het tekenen van een veelhoek rond elk object in de afbeelding. |
Verwerking van natuurlijke taal: NLP
Met ondersteuning voor NLP-taken (Natural Language Processing) in geautomatiseerde ML kunt u eenvoudig modellen genereren die zijn getraind op tekstgegevens voor tekstclassificatie en scenario's voor benoemde entiteitsherkenning. Het ontwerpen van geautomatiseerde DOOR ML getrainde NLP-modellen wordt ondersteund via de Azure Machine Learning Python SDK. De resulterende experimententaken, modellen en uitvoer kunnen worden geopend vanuit de gebruikersinterface van Azure Machine Learning-studio.
De NLP-functie ondersteunt:
- End-to-end deep neural network NLP training met de nieuwste vooraf getrainde BERT-modellen
- Naadloze integratie met Azure Machine Learning-gegevenslabels
- Gelabelde gegevens gebruiken voor het genereren van NLP-modellen
- Meertalige ondersteuning met 104 talen
- Gedistribueerde training met Horovod
Meer informatie over het instellen van AutoML-training voor NLP-modellen.
Trainings-, validatie- en testgegevens
Met geautomatiseerde ML geeft u de trainingsgegevens op voor het trainen van ML-modellen en kunt u opgeven welk type modelvalidatie moet worden uitgevoerd. Geautomatiseerde ML voert modelvalidatie uit als onderdeel van de training. Geautomatiseerde ML maakt gebruik van validatiegegevens om modelhypparameters af te stemmen op basis van het toegepaste algoritme om de combinatie te vinden die het beste past bij de trainingsgegevens. Dezelfde validatiegegevens worden echter gebruikt voor elke iteratie van afstemming, waardoor modelevaluatievooroordelen worden geïntroduceerd, omdat het model de validatiegegevens blijft verbeteren en aanpassen.
Om te bevestigen dat dergelijke vooroordelen niet worden toegepast op het uiteindelijke aanbevolen model, ondersteunt geautomatiseerde ML het gebruik van testgegevens om het uiteindelijke model te evalueren dat geautomatiseerde ML aan het einde van uw experiment aanbeveelt. Wanneer u testgegevens opgeeft als onderdeel van de configuratie van uw AutoML-experiment, wordt dit aanbevolen model standaard getest aan het einde van uw experiment (preview).
Belangrijk
Het testen van uw modellen met een testgegevensset om gegenereerde modellen te evalueren, is een preview-functie. Deze mogelijkheid is een experimentele preview-functie en kan op elk gewenst moment worden gewijzigd.
Meer informatie over het configureren van AutoML-experimenten voor het gebruik van testgegevens (preview) met de SDK of met de Azure Machine Learning-studio.
Functie-engineering
Functie-engineering is het proces van het gebruik van domeinkennis van de gegevens om functies te maken die ML-algoritmen helpen beter te leren. In Azure Machine Learning worden schaal- en normalisatietechnieken toegepast om functie-engineering te vergemakkelijken. Gezamenlijk worden deze technieken en functie-engineering aangeduid als featurization.
Voor geautomatiseerde machine learning-experimenten wordt featurization automatisch toegepast, maar kan deze ook worden aangepast op basis van uw gegevens. Meer informatie over welke featurization is opgenomen (SDK v1) en hoe AutoML helpt bij het voorkomen van overfitting en onevenwichtige gegevens in uw modellen.
Notitie
Geautomatiseerde machine learning-featurisatiestappen (bijvoorbeeld functienormalisatie, verwerking van ontbrekende gegevens en het converteren van tekst naar numeriek) worden onderdeel van het onderliggende model. Wanneer u het model voor voorspellingen gebruikt, worden dezelfde featurization-stappen die tijdens de training worden toegepast, automatisch toegepast op uw invoergegevens.
Featurization aanpassen
Er zijn ook aanvullende techniektechnieken beschikbaar, zoals codering en transformaties.
Schakel deze instelling in met:
Azure Machine Learning-studio: inschakelen Automatische featurisatie in de sectie Aanvullende configuratie weergeven met deze stappen.
Python SDK: geef featurization op in uw AutoML-taakobject . Meer informatie over het inschakelen van featurization.
Ensemblemodellen
Geautomatiseerde machine learning ondersteunt ensemblemodellen, die standaard zijn ingeschakeld. Ensemble learning verbetert machine learning-resultaten en voorspellende prestaties door meerdere modellen te combineren in plaats van één model te gebruiken. De ensemble-iteraties worden weergegeven als de laatste iteraties van uw taak. Geautomatiseerde machine learning maakt gebruik van stem- en stacking ensemblemethoden voor het combineren van modellen:
- Stem: Voorspelt op basis van het gewogen gemiddelde van voorspelde klassenkansen (voor classificatietaken) of voorspelde regressiedoelen (voor regressietaken).
- Stapelen: combineert heterogene modellen en traint een metamodel op basis van de uitvoer van de afzonderlijke modellen. De huidige standaardmetamodellen zijn LogisticRegression voor classificatietaken en ElasticNet voor regressie-/prognosetaken.
Het caruana ensembleselectie-algoritme met gesorteerde ensemble-initialisatie wordt gebruikt om te bepalen welke modellen binnen het ensemble moeten worden gebruikt. Op hoog niveau initialiseert dit algoritme het ensemble met maximaal vijf modellen met de beste individuele scores en controleert of deze modellen binnen 5% van de beste score liggen om een slecht eerste ensemble te voorkomen. Vervolgens wordt voor elke ensemble-iteratie een nieuw model toegevoegd aan het bestaande ensemble en wordt de resulterende score berekend. Als een nieuw model de bestaande ensemblescore heeft verbeterd, wordt het ensemble bijgewerkt met het nieuwe model.
Zie het AutoML-pakket voor het wijzigen van standaard-ensembleinstellingen in geautomatiseerde machine learning.
AutoML & ONNX
Met Azure Machine Learning kunt u geautomatiseerde ML gebruiken om een Python-model te bouwen en te laten converteren naar de ONNX-indeling. Zodra de modellen de ONNX-indeling hebben, kunnen ze worden uitgevoerd op verschillende platforms en apparaten. Meer informatie over het versnellen van ML-modellen met ONNX.
Bekijk hoe u kunt converteren naar ONNX-indeling in dit Jupyter-notebookvoorbeeld. Meer informatie over welke algoritmen worden ondersteund in ONNX.
De ONNX-runtime biedt ook ondersteuning voor C#, zodat u het model dat automatisch is gebouwd in uw C#-apps kunt gebruiken zonder dat u hoeft te worden hersteld of een van de netwerklatenties die REST-eindpunten introduceren. Meer informatie over het gebruik van een AutoML ONNX-model in een .NET-toepassing met ML.NET en het deducteren van ONNX-modellen met de ONNX Runtime C#-API.
Volgende stappen
Er zijn meerdere resources waarmee u aan de slag kunt met AutoML.
Zelfstudies/ procedures
Zelfstudies zijn end-to-end inleidende voorbeelden van AutoML-scenario's.
Voor een eerste ervaring met code volgt u zelfstudie: Een objectdetectiemodel trainen met AutoML en Python
Zie Zelfstudie: Een classificatiemodel trainen zonder code in Azure Machine Learning-studio voor een ervaring met weinig of geen code.
Artikelen met procedures bieden meer informatie over welke functionaliteit geautomatiseerde ML biedt. Voorbeeld:
De instellingen voor automatische trainingsexperimenten configureren
Meer informatie over het trainen van Computer Vision-modellen met Python.
Meer informatie over het weergeven van de gegenereerde code op basis van uw geautomatiseerde ML-modellen (SDK v1).
Voorbeelden van Jupyter-notebooks
Bekijk gedetailleerde codevoorbeelden en gebruiksvoorbeelden in de GitHub notebookopslagplaats voor geautomatiseerde machine learning voorbeelden.
Naslaginformagtie over de Python-SDK
Verdiep uw expertise op het gebied van SDK-ontwerppatronen en klassespecificaties met behulp van de referentiedocumentatie voor De AutoML-taakklasse.
Notitie
Geautomatiseerde machine learning-mogelijkheden zijn ook beschikbaar in andere Microsoft-oplossingen, zoals ML.NET, HDInsight, Power BI en SQL Server.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor