Gegevensopname met Azure Data Factory
In dit artikel vindt u informatie over de beschikbare opties voor het bouwen van een pijplijn voor gegevensopname met Azure Data Factory. Deze Azure Data Factory-pijplijn wordt gebruikt om gegevens op te nemen voor gebruik met Azure Machine Learning. Met Data Factory kunt u eenvoudig ETL-gegevens (extraheren, transformeren en laden). Zodra de gegevens zijn getransformeerd en geladen in de opslag, kunnen ze worden gebruikt om uw machine learning-modellen te trainen in Azure Machine Learning.
Eenvoudige gegevenstransformatie kan worden verwerkt met systeemeigen Data Factory-activiteiten en instrumenten zoals gegevensstroom. Als het gaat om complexere scenario's, kunnen de gegevens worden verwerkt met een aantal aangepaste code. Bijvoorbeeld Python- of R-code.
Gegevensopnamepijplijnen van Azure Data Factory vergelijken
Er zijn verschillende algemene technieken voor het gebruik van Data Factory om gegevens tijdens opname te transformeren. Elke techniek heeft voor- en nadelen die helpen bepalen of deze geschikt is voor een specifieke use case:
| Techniek | Voordelen | Nadelen |
|---|---|---|
| Data Factory + Azure Functions | Alleen goed voor korte verwerking | |
| Data Factory + aangepast onderdeel | ||
| Data Factory + Azure Databricks-notebook |
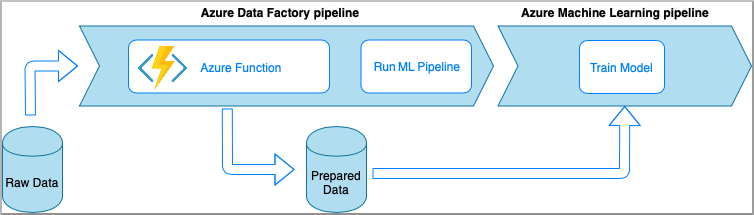
Azure Data Factory met Azure Functions
Met Azure Functions kunt u kleine stukjes code (functies) uitvoeren zonder dat u zich zorgen hoeft te maken over de toepassingsinfrastructuur. In deze optie worden de gegevens verwerkt met aangepaste Python-code die is verpakt in een Azure-functie.
De functie wordt aangeroepen met de Azure Data Factory Azure Function-activiteit. Deze aanpak is een goede optie voor lichtgewicht gegevenstransformaties.
- Voordelen:
- De gegevens worden verwerkt op een serverloze berekening met een relatief lage latentie
- Data Factory-pijplijn kan een Durable Azure-functie aanroepen die een geavanceerde gegevenstransformatiestroom kan implementeren
- De details van de gegevenstransformatie worden weggeabstraheerd door de Azure-functie die kan worden hergebruikt en aangeroepen vanaf andere locaties
- Nadelen:
- De Azure Functions moet worden gemaakt voor gebruik met ADF
- Azure Functions is alleen geschikt voor kortlopende gegevensverwerking
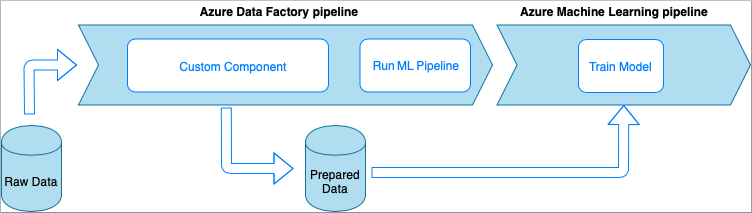
Azure Data Factory met aangepaste onderdeelactiviteit
In deze optie worden de gegevens verwerkt met aangepaste Python-code die is verpakt in een uitvoerbaar bestand. Deze wordt aangeroepen met een aangepaste Azure Data Factory-onderdeelactiviteit. Deze benadering is beter geschikt voor grote gegevens dan de vorige techniek.
- Voordelen:
- De gegevens worden verwerkt in azure Batch-pool , die grootschalige parallelle en high-performance computing biedt
- Kan worden gebruikt om zware algoritmen uit te voeren en aanzienlijke hoeveelheden gegevens te verwerken
- Nadelen:
- Azure Batch-pool moet worden gemaakt voor gebruik met Data Factory
- Over engineering met betrekking tot het verpakken van Python-code in een uitvoerbaar bestand. Complexiteit van het verwerken van afhankelijkheden en invoer-/uitvoerparameters
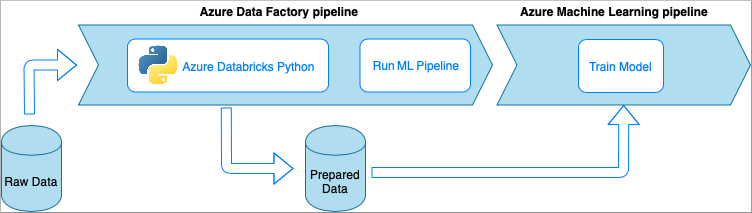
Azure Data Factory met Azure Databricks Python-notebook
Azure Databricks is een op Apache Spark gebaseerd analyseplatform in de Microsoft-cloud.
In deze techniek wordt de gegevenstransformatie uitgevoerd door een Python-notebook, uitgevoerd op een Azure Databricks-cluster. Dit is waarschijnlijk de meest voorkomende benadering die gebruikmaakt van de volledige kracht van een Azure Databricks-service. Het is ontworpen voor gedistribueerde gegevensverwerking op schaal.
- Voordelen:
- De gegevens worden getransformeerd op de krachtigste Azure-service voor gegevensverwerking, waarvan een back-up wordt gemaakt door de Apache Spark-omgeving
- Systeemeigen ondersteuning van Python, samen met data science-frameworks en -bibliotheken, waaronder TensorFlow, PyTorch en scikit-learn
- U hoeft de Python-code niet te verpakken in functies of uitvoerbare modules. De code werkt zoals is.
- Nadelen:
- De Azure Databricks-infrastructuur moet worden gemaakt voordat deze wordt gebruikt met Data Factory
- Kan duur zijn, afhankelijk van de Configuratie van Azure Databricks
- Het maken van rekenclusters vanuit de 'koude' modus duurt enige tijd waardoor de oplossing een hoge latentie krijgt
Gegevens gebruiken in Azure Machine Learning
De Data Factory-pijplijn slaat de voorbereide gegevens op in uw cloudopslag (zoals Azure Blob of Azure Data Lake).
Gebruik uw voorbereide gegevens in Azure Machine Learning door,
- Een Azure Machine Learning-pijplijn aanroepen vanuit uw Data Factory-pijplijn.
OF - Een Azure Machine Learning-gegevensarchief maken.
Azure Machine Learning-pijplijn aanroepen vanuit Data Factory
Deze methode wordt aanbevolen voor MLOps-werkstromen (Machine Learning Operations). Als u geen Azure Machine Learning-pijplijn wilt instellen, raadpleegt u Gegevens rechtstreeks uit de opslag lezen.
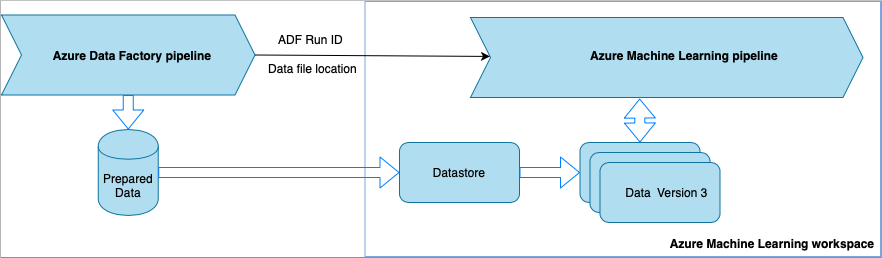
Telkens wanneer de Data Factory-pijplijn wordt uitgevoerd,
- De gegevens worden opgeslagen op een andere locatie in de opslag.
- Als u de locatie wilt doorgeven aan Azure Machine Learning, roept de Data Factory-pijplijn een Azure Machine Learning-pijplijn aan. Bij het aanroepen van de ML-pijplijn worden de gegevenslocatie en taak-id verzonden als parameters.
- De ML-pijplijn kan vervolgens een Azure Machine Learning-gegevensarchief en -gegevensset maken met de gegevenslocatie. Meer informatie vindt u in Azure Machine Learning-pijplijnen uitvoeren in Data Factory.
Fooi
Gegevenssets ondersteunen versiebeheer, zodat de ML-pijplijn een nieuwe versie van de gegevensset kan registreren die verwijst naar de meest recente gegevens uit de ADF-pijplijn.
Zodra de gegevens toegankelijk zijn via een gegevensarchief of gegevensset, kunt u deze gebruiken om een ML-model te trainen. Het trainingsproces maakt mogelijk deel uit van dezelfde ML-pijplijn die wordt aangeroepen vanuit ADF. Of het kan een afzonderlijk proces zijn, zoals experimenten in een Jupyter-notebook.
Omdat gegevenssets versiebeheer ondersteunen en elke taak uit de pijplijn een nieuwe versie maakt, is het eenvoudig te begrijpen welke versie van de gegevens is gebruikt om een model te trainen.
Gegevens rechtstreeks vanuit de opslag lezen
Als u geen ML-pijplijn wilt maken, hebt u rechtstreeks toegang tot de gegevens vanuit het opslagaccount waarin uw voorbereide gegevens worden opgeslagen met een Azure Machine Learning-gegevensarchief en -gegevensset.
De volgende Python-code laat zien hoe u een gegevensarchief maakt dat verbinding maakt met Azure DataLake Generation 2-opslag. Meer informatie over gegevensarchieven en waar u machtigingen voor de service-principal kunt vinden.
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
Maak vervolgens een gegevensset om te verwijzen naar de bestanden die u wilt gebruiken in uw machine learning-taak.
Met de volgende code wordt een TabularDataset gemaakt op basis van een CSV-bestand. prepared-data.csv Meer informatie over typen gegevenssets en geaccepteerde bestandsindelingen.
VAN TOEPASSING OP: Python SDK azureml v1
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
Gebruik hier prepared_dataset om te verwijzen naar uw voorbereide gegevens, zoals in uw trainingsscripts. Meer informatie over het trainen van modellen met gegevenssets in Azure Machine Learning.