Eindpunten voor deductie in productie
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Nadat u machine learning-modellen of pijplijnen hebt getraind of u modellen hebt gevonden uit de modelcatalogus die aan uw behoeften voldoet, moet u ze implementeren in productie, zodat anderen ze kunnen gebruiken voor deductie. Deductie is het proces van het toepassen van nieuwe invoergegevens op een machine learning-model of pijplijn om uitvoer te genereren. Hoewel deze uitvoer doorgaans 'voorspellingen' wordt genoemd, kan deductie worden gebruikt om uitvoer te genereren voor andere machine learning-taken, zoals classificatie en clustering. In Azure Machine Learning voert u deductie uit met behulp van eindpunten.
Eindpunten en implementaties
Een eindpunt is een stabiele en duurzame URL die kan worden gebruikt om een model aan te vragen of aan te roepen. U geeft de vereiste invoer op voor het eindpunt en haalt de uitvoer terug. Met Azure Machine Learning kunt u serverloze API-eindpunten, online-eindpunten en batcheindpunten implementeren. Een eindpunt biedt:
- een stabiele en duurzame URL (zoals endpoint-name.region.inference.ml.azure.com),
- een verificatiemechanisme en
- een autorisatiemechanisme.
Een implementatie is een set resources en berekeningen die nodig zijn voor het hosten van het model of onderdeel dat de werkelijke deductie uitvoert. Een eindpunt bevat een implementatie en voor online- en batcheindpunten kan één eindpunt verschillende implementaties bevatten. De implementaties kunnen onafhankelijke assets hosten en verschillende resources verbruiken op basis van de behoeften van de assets. Bovendien heeft een eindpunt een routeringsmechanisme waarmee aanvragen naar een van de implementaties kunnen worden omgeleid.
Aan de ene kant verbruiken sommige typen eindpunten in Azure Machine Learning toegewezen resources voor hun implementaties. Als u deze eindpunten wilt uitvoeren, moet u een rekenquotum hebben voor uw Azure-abonnement. Aan de andere kant ondersteunen bepaalde modellen een serverloze implementatie, zodat ze geen quotum uit uw abonnement kunnen gebruiken. Voor serverloze implementatie wordt u gefactureerd op basis van gebruik.
Intuïtie
Stel dat u aan een toepassing werkt die het type en de kleur van een auto voorspelt op basis van de foto. Voor deze toepassing maakt een gebruiker met bepaalde referenties een HTTP-aanvraag naar een URL en geeft een afbeelding van een auto als onderdeel van de aanvraag. Als resultaat krijgt de gebruiker een antwoord met het type en de kleur van de auto als tekenreekswaarden. In dit scenario fungeert de URL als eindpunt.
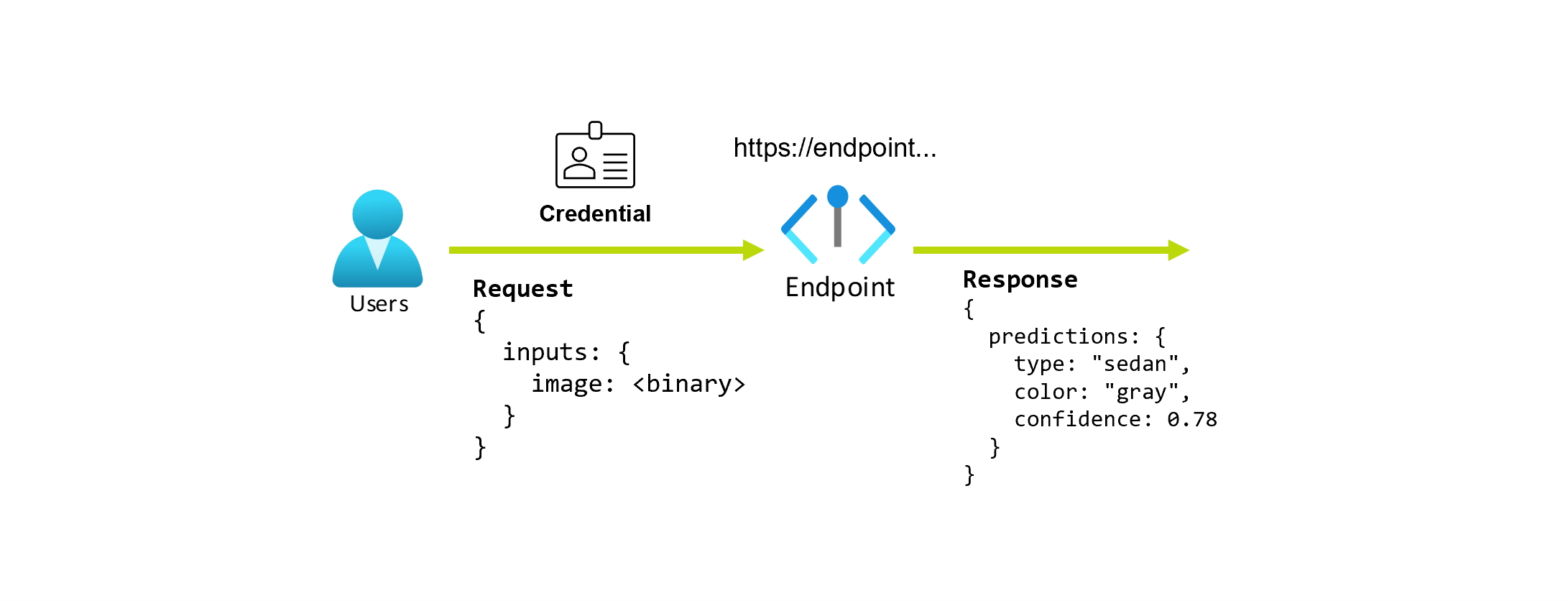
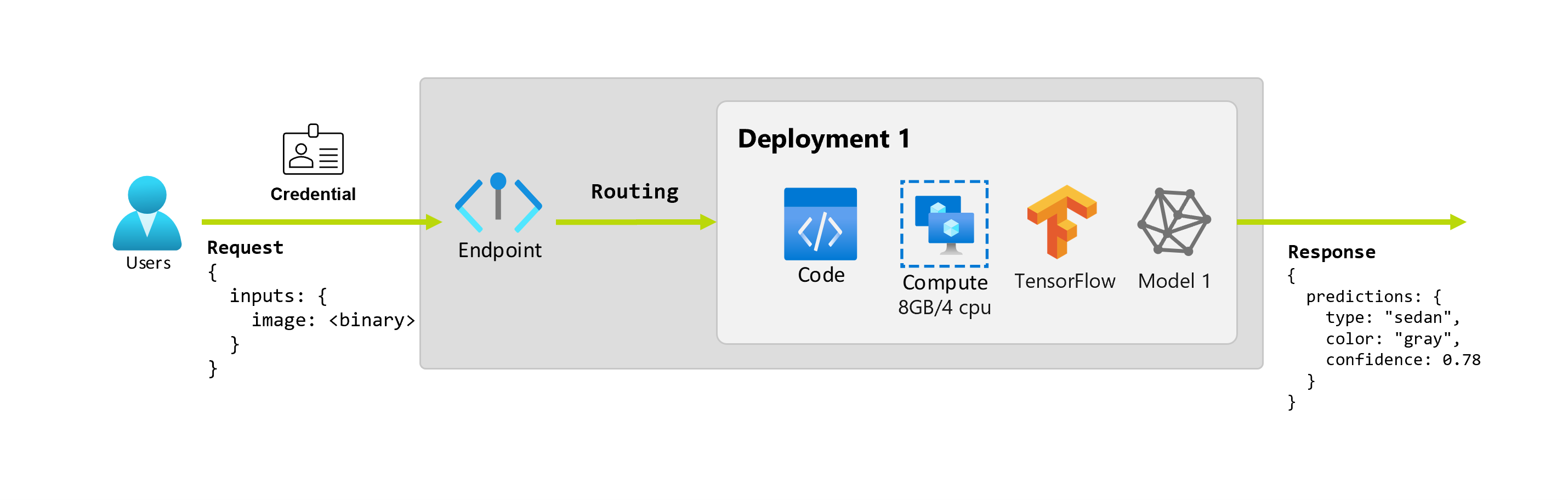
Stel dat een data scientist, Alice, werkt aan de implementatie van de toepassing. Alice weet veel over TensorFlow en besluit het model te implementeren met behulp van een Keras-sequentiële classificatie met een RestNet-architectuur van de TensorFlow Hub. Na het testen van het model is Alice tevreden met de resultaten en besluit het model te gebruiken om het probleem met de autovoorspelling op te lossen. Het model is groot en vereist 8 GB geheugen met vier kernen om uit te voeren. In dit scenario vormen het model van Alice en de resources, zoals de code en de berekening, die nodig zijn om het model uit te voeren, een implementatie onder het eindpunt.
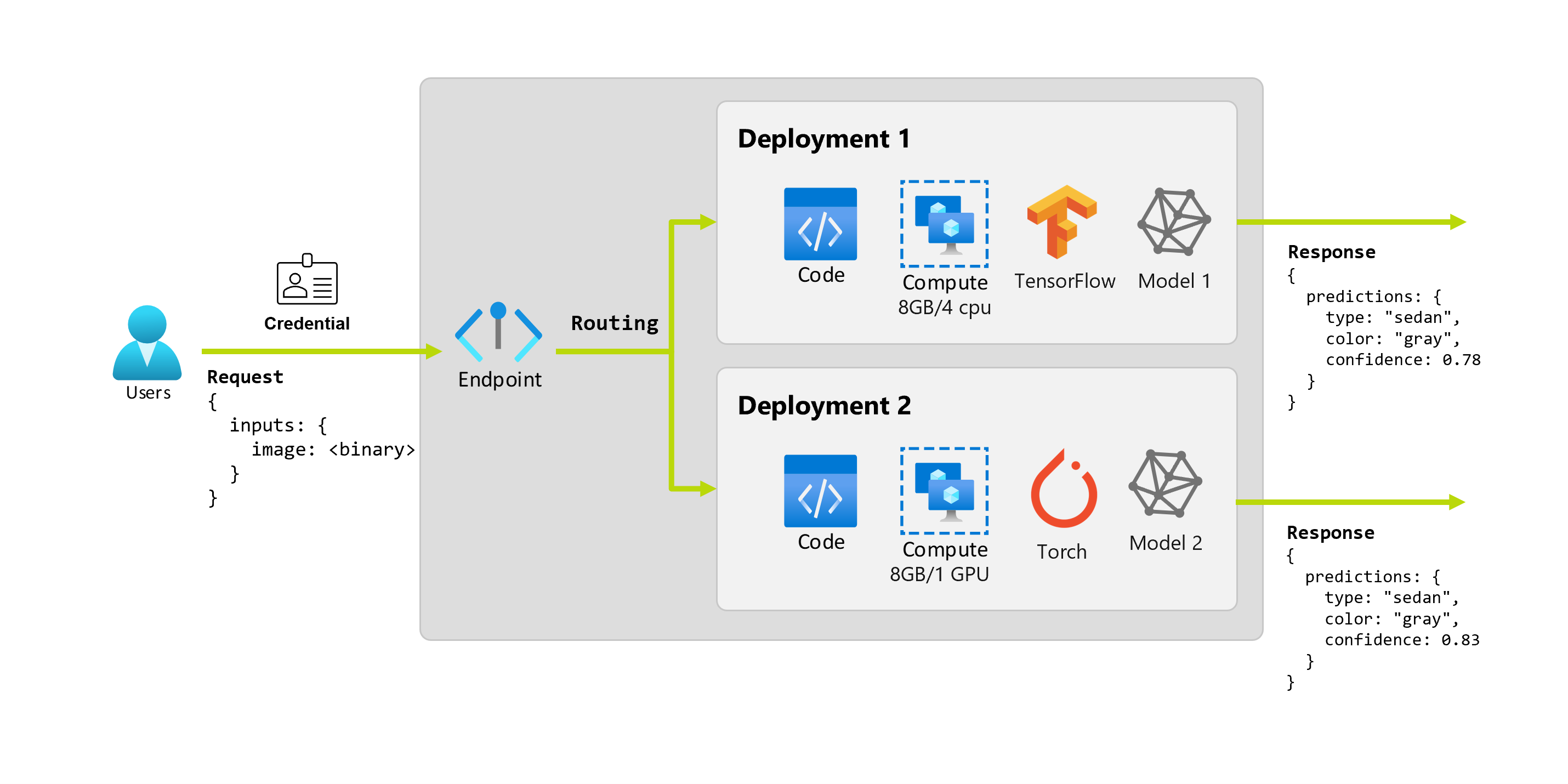
Stel dat de organisatie na een paar maanden ontdekt dat de toepassing slecht presteert op afbeeldingen met minder dan ideale verlichtingsomstandigheden. Bob, een andere data scientist, weet veel over technieken voor gegevensvergroting die een model helpen om robuustheid op te bouwen op die factor. Bob voelt zich echter comfortabeler met behulp van Torch om het model te implementeren en traint een nieuw model met Torch. Bob wil dit model geleidelijk in productie proberen totdat de organisatie klaar is om het oude model buiten gebruik te stellen. Het nieuwe model toont ook betere prestaties wanneer het wordt geïmplementeerd op GPU, dus de implementatie moet een GPU bevatten. In dit scenario vormen het model en de resources van Bob, zoals de code en de berekening, die nodig zijn om het model uit te voeren, een andere implementatie onder hetzelfde eindpunt.
Eindpunten: serverloze API, online en batch
Met Azure Machine Learning kunt u serverloze API-eindpunten, online-eindpunten en batcheindpunten implementeren.
Serverloze API-eindpunten en online-eindpunten zijn ontworpen voor realtime deductie. Wanneer u het eindpunt aanroept, worden de resultaten geretourneerd in het antwoord van het eindpunt. Serverloze API-eindpunten verbruiken geen quotum van uw abonnement; In plaats daarvan worden ze gefactureerd met betalen per gebruik-facturering.
Batch-eindpunten zijn ontworpen voor langdurige batchdeductie. Wanneer u een batch-eindpunt aanroept, genereert u een batchtaak waarmee het werkelijke werk wordt uitgevoerd.
Wanneer serverloze API, online en batch-eindpunten worden gebruikt
Serverloze API-eindpunten:
Gebruik serverloze API-eindpunten om grote basismodellen te gebruiken voor realtime deductie buiten de plank of voor het verfijnen van dergelijke modellen. Niet alle modellen zijn beschikbaar voor implementatie naar serverloze API-eindpunten. We raden u aan deze implementatiemodus te gebruiken wanneer:
- Uw model is een fundamenteel model of een verfijnde versie van een basismodel dat beschikbaar is voor serverloze API-implementaties.
- U kunt profiteren van een quotumloze implementatie.
- U hoeft de deductiestack die wordt gebruikt voor het uitvoeren van het model niet aan te passen.
Online-eindpunten:
Gebruik online-eindpunten om modellen operationeel te maken voor realtime deductie in synchrone aanvragen met lage latentie. U wordt aangeraden deze te gebruiken wanneer:
- Uw model is een fundamenteel model of een verfijnde versie van een basismodel, maar wordt niet ondersteund in serverloze API-eindpunten.
- U hebt vereisten voor lage latentie.
- Uw model kan de aanvraag in relatief korte tijd beantwoorden.
- De invoer van uw model past bij de HTTP-nettolading van de aanvraag.
- U moet omhoog schalen in termen van het aantal aanvragen.
Batch-eindpunten:
Gebruik batcheindpunten om modellen of pijplijnen operationeel te maken voor langlopende asynchrone deductie. U wordt aangeraden deze te gebruiken wanneer:
- U hebt dure modellen of pijplijnen waarvoor langere tijd nodig is om uit te voeren.
- U wilt machine learning-pijplijnen operationeel maken en onderdelen opnieuw gebruiken.
- U moet deductie uitvoeren op grote hoeveelheden gegevens die in meerdere bestanden worden gedistribueerd.
- U hebt geen vereisten voor lage latentie.
- De invoer van uw model wordt opgeslagen in een opslagaccount of in een Azure Machine Learning-gegevensasset.
- U kunt profiteren van parallelle uitvoering.
Vergelijking van serverloze API-, online- en batcheindpunten
Alle serverloze API's, online en batch-eindpunten zijn gebaseerd op het idee van eindpunten. U kunt daarom eenvoudig overstappen van het ene naar het andere eindpunt. Online- en batcheindpunten kunnen ook meerdere implementaties voor hetzelfde eindpunt beheren.
Eindpunten
In de volgende tabel ziet u een overzicht van de verschillende functies die beschikbaar zijn voor serverloze API's, online en batcheindpunten op eindpuntniveau.
| Functie | Serverloze API-eindpunten | Online-eindpunten | Batch-eindpunten |
|---|---|---|---|
| Stabiele aanroep-URL | Ja | Ja | Ja |
| Ondersteuning voor meerdere implementaties | Nr. | Ja | Ja |
| Routering van implementatie | Geen | Verkeer splitsen | Overschakelen naar de standaardinstelling |
| Verkeer spiegelen voor veilige implementatie | Nr. | Ja | Nr. |
| Ondersteuning voor Swagger | Ja | Ja | Nr. |
| Verificatie | Sleutel | Sleutel en Microsoft Entra-id (preview) | Microsoft Entra ID |
| Ondersteuning voor privénetwerk (verouderd) | Nr. | Ja | Ja |
| Beheerde netwerkisolatie | Ja | Ja | Ja (zie vereiste aanvullende configuratie) |
| Door klant beheerde sleutels | N.v.t. | Ja | Ja |
| Kostenbasis | Per eindpunt, per minuut1 | Geen | Geen |
1Een kleine fractie wordt in rekening gebracht voor serverloze API-eindpunten per minuut. Zie de sectie implementaties voor de kosten die betrekking hebben op verbruik, die per token worden gefactureerd.
Installaties
In de volgende tabel ziet u een overzicht van de verschillende functies die beschikbaar zijn voor serverloze API's, online en batcheindpunten op implementatieniveau. Deze concepten zijn van toepassing op elke implementatie onder het eindpunt (voor online- en batcheindpunten) en zijn van toepassing op serverloze API-eindpunten (waarbij het concept van implementatie is ingebouwd in het eindpunt).
| Functie | Serverloze API-eindpunten | Online-eindpunten | Batch-eindpunten |
|---|---|---|---|
| Implementatietypen | Modellen | Modellen | Modellen en pijplijnonderdelen |
| MLflow-modelimplementatie | Nee, alleen specifieke modellen in de catalogus | Ja | Ja |
| Aangepaste modelimplementatie | Nee, alleen specifieke modellen in de catalogus | Ja, met scorescript | Ja, met scorescript |
| Modelpakketimplementatie 2 | Ingebouwd | Ja (preview) | Nee |
| Deductieserver 3 | Azure AI-modelinferentie-API | - Azure Machine Learning-deductieserver -Triton - Aangepast (met BYOC) |
Batchdeductie |
| Verbruikte rekenresource | Geen (serverloos) | Exemplaren of gedetailleerde resources | Clusterexemplaren |
| Rekentype | Geen (serverloos) | Beheerde rekenkracht en Kubernetes | Beheerde rekenkracht en Kubernetes |
| Berekening met lage prioriteit | N.v.t. | Nr. | Ja |
| Rekenkracht schalen naar nul | Ingebouwd | Nr. | Ja |
| Berekening automatisch schalen4 | Ingebouwd | Ja, op basis van resourcegebruik | Ja, op basis van het aantal taken |
| Beheer van overcapaciteit | Beperking | Beperking | Queuing |
| Kostenbasis5 | Per token | Per implementatie: rekeninstanties die worden uitgevoerd | Per taak: rekenproces dat in de taak is verbruikt (beperkt tot het maximum aantal exemplaren van het cluster) |
| Lokale tests van implementaties | Nr. | Ja | Nr. |
2 Voor het implementeren van MLflow-modellen op eindpunten zonder uitgaande internetverbinding of particuliere netwerken moet het model eerst worden verpakt.
3 Deductieserver verwijst naar de ondersteunende technologie die aanvragen accepteert, verwerkt en reacties maakt. De deductieserver bepaalt ook de indeling van de invoer en de verwachte uitvoer.
4 Automatisch schalen is de mogelijkheid om de toegewezen resources van de implementatie dynamisch omhoog of omlaag te schalen op basis van de belasting. Online- en batchimplementaties gebruiken verschillende strategieën voor automatisch schalen. Terwijl onlineimplementaties omhoog en omlaag worden geschaald op basis van het resourcegebruik (zoals CPU, geheugen, aanvragen, enzovoort), worden batcheindpunten omhoog of omlaag geschaald op basis van het aantal gemaakte taken.
5 Zowel online- als batchimplementaties brengen kosten in rekening door de verbruikte resources. In online-implementaties worden resources ingericht tijdens de implementatie. Bij batchimplementatie worden resources niet verbruikt tijdens de implementatie, maar op het moment dat de taak wordt uitgevoerd. Daarom zijn er geen kosten verbonden aan de batchimplementatie zelf. Op dezelfde manier verbruiken taken in de wachtrij ook geen resources.
Ontwikkelaarsinterfaces
Eindpunten zijn ontworpen om organisaties te helpen bij het operationeel maken van workloads op productieniveau in Azure Machine Learning. Eindpunten zijn robuuste en schaalbare resources en bieden de beste mogelijkheden voor het implementeren van MLOps-werkstromen.
U kunt batch- en online-eindpunten maken en beheren met verschillende ontwikkelhulpprogramma's:
- De Azure CLI en de Python SDK
- Azure Resource Manager/REST API
- Azure Machine Learning-studio webportal
- Azure Portal (IT/admin)
- Ondersteuning voor CI/CD MLOps-pijplijnen met behulp van de Azure CLI-interface & REST/ARM-interfaces