Online-eindpuntimplementatie voor realtime deductie
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel worden online-eindpunten beschreven voor realtime deductie in Azure Machine Learning. Deductie is het proces van het toepassen van nieuwe invoergegevens op een machine learning-model om uitvoer te genereren. Met Azure Machine Learning kunt u realtime deductie uitvoeren op gegevens met behulp van modellen die zijn geïmplementeerd op online-eindpunten. Hoewel deze uitvoer doorgaans voorspellingen worden genoemd, kunt u deductie gebruiken om uitvoer te genereren voor andere machine learning-taken, zoals classificatie en clustering.
Online-eindpunten
Online-eindpunten implementeren modellen op een webserver die voorspellingen onder het HTTP-protocol kan retourneren. Online-eindpunten kunnen modellen operationeel maken voor realtime deductie in synchrone aanvragen met lage latentie en worden het beste gebruikt wanneer:
- U hebt vereisten voor lage latentie.
- Uw model kan de aanvraag in relatief korte tijd beantwoorden.
- De invoer van uw model past bij de HTTP-nettolading van de aanvraag.
- U moet het aantal aanvragen omhoog schalen.
Als u een eindpunt wilt definiëren, moet u het volgende opgeven:
- Eindpuntnaam. Deze naam moet uniek zijn in de Azure-regio. Zie Azure Machine Learning Online-eindpunten en batcheindpunten voor andere naamgevingsvereisten.
- Verificatiemodus. U kunt kiezen uit verificatiemodus op basis van sleutels, verificatiemodus op basis van Azure Machine Learning-tokens of verificatie op basis van Microsoft Entra-tokens voor het eindpunt. Zie Clients verifiëren voor online-eindpunten voor meer informatie over verificatie.
Beheerde online-eindpunten
Beheerde online-eindpunten implementeren uw machine learning-modellen op een handige, kant-en-klare manier en zijn de aanbevolen manier om online-eindpunten van Azure Machine Learning te gebruiken. Beheerde online-eindpunten werken met krachtige CPU- en GPU-machines in Azure op een schaalbare, volledig beheerde manier.
Om u vrij te maken van de overhead van het instellen en beheren van de onderliggende infrastructuur, zorgen deze eindpunten ook voor het leveren, schalen, beveiligen en bewaken van uw modellen. Zie Het eindpunt definiëren voor meer informatie over het definiëren van beheerde online-eindpunten.
Beheerde online-eindpunten versus Azure Container Instances of Azure Kubernetes Service (AKS) v1
Beheerde online-eindpunten zijn de aanbevolen manier om online-eindpunten te gebruiken in Azure Machine Learning. In de volgende tabel ziet u belangrijke kenmerken van beheerde online-eindpunten vergeleken met Azure Container Instances en Azure Kubernetes Service (AKS) v1-oplossingen.
| Kenmerken | Beheerde online-eindpunten (v2) | Container Instances of AKS (v1) |
|---|---|---|
| Netwerkbeveiliging/isolatie | Eenvoudig inkomend/uitgaand besturingselement met snelle wisselknop | Virtueel netwerk wordt niet ondersteund of vereist complexe handmatige configuratie |
| Beheerde service | • Volledig beheerde compute-inrichting/schaalaanpassing • Netwerkconfiguratie voor preventie van gegevensexfiltratie • Upgrade van hostbesturingssysteem, gecontroleerde implementatie van in-place updates |
• Schaalaanpassing is beperkt • Gebruiker moet netwerkconfiguratie of upgrade beheren |
| Eindpunt/implementatieconcept | Onderscheid tussen eindpunt en implementatie maakt complexe scenario's mogelijk, zoals een veilige implementatie van modellen | Geen concept van eindpunt |
| Diagnose en controle | • Lokaal foutopsporingspunt mogelijk met Docker en Visual Studio Code • Geavanceerde analyse van metrische gegevens en logboeken met grafiek/query om te vergelijken tussen implementaties • Uitsplitsing van kosten naar implementatieniveau |
Geen eenvoudige lokale foutopsporing |
| Schaalbaarheid | Elastisch en automatisch schalen (niet gebonden aan de standaardclustergrootte) | • Container Instances is niet schaalbaar • AKS v1 biedt alleen ondersteuning voor in-clusterschaal en vereist schaalbaarheidsconfiguratie |
| Gereedheid voor bedrijven | Private Link, door de klant beheerde sleutels, Microsoft Entra ID, quotumbeheer, factureringsintegratie, SLA (Service Level Agreement) | Niet ondersteund |
| Geavanceerde ML-functies | • Gegevensverzameling modelleren • Modelbewaking • Champion-challenger model, veilige implementatie, verkeersspiegeling • Verantwoorde AI-uitbreidbaarheid |
Niet ondersteund |
Beheerde online-eindpunten versus Kubernetes Online-eindpunten
Als u Liever Kubernetes gebruikt om uw modellen te implementeren en eindpunten te leveren en u vertrouwd bent met het beheren van de vereisten voor de infrastructuur, kunt u Online-eindpunten van Kubernetes gebruiken. Met deze eindpunten kunt u modellen implementeren en online-eindpunten leveren met CPU's of GPU's in uw volledig geconfigureerde en beheerde Kubernetes-cluster .
Beheerde online-eindpunten kunnen u helpen uw implementatieproces te stroomlijnen en de volgende voordelen te bieden ten opzichte van Kubernetes online-eindpunten:
Automatisch infrastructuurbeheer
- Hiermee wordt het rekenproces en het model gehost. U hoeft alleen het type en de schaalinstellingen voor de virtuele machine (VM) op te geven.
- Hiermee worden de onderliggende installatiekopie van het hostbesturingssystemen bijgewerkt en gepatcht.
- Voert knooppuntherstel uit als er een systeemfout optreedt.
Bewaking en logboeken
- Mogelijkheid om de beschikbaarheid, prestaties en SLA van modellen te bewaken met behulp van systeemeigen integratie met Azure Monitor.
- Eenvoudig foutopsporingsimplementaties met behulp van logboeken en systeemeigen integratie met Log Analytics.
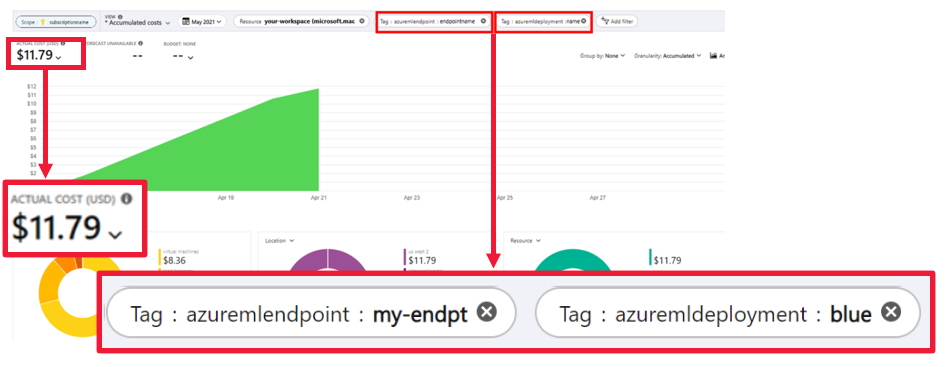
Met de weergave Kostenanalyse kunt u kosten bewaken op eindpunt- en implementatieniveau.
Notitie
Beheerde online-eindpunten zijn gebaseerd op Azure Machine Learning Compute. Wanneer u een beheerd online-eindpunt gebruikt, betaalt u voor de reken- en netwerkkosten. Er is geen toeslag. Zie de Azure-prijscalculator voor meer informatie over prijzen.
Als u een virtueel Azure Machine Learning-netwerk gebruikt om uitgaand verkeer van het beheerde online-eindpunt te beveiligen, worden kosten in rekening gebracht voor de privékoppeling van Azure en de FQDN-regels (Fully Qualified Domain Name) die door het beheerde virtuele netwerk worden gebruikt. Zie Prijzen voor beheerd virtueel netwerk voor meer informatie.


In de volgende tabel ziet u de belangrijkste verschillen tussen beheerde online-eindpunten en Kubernetes Online-eindpunten.
| Beheerde online-eindpunten | Kubernetes Online-eindpunten (AKS v2) | |
|---|---|---|
| Aanbevolen gebruikers | Gebruikers die een implementatie van een beheerd model en een verbeterde MLOps-ervaring willen | Gebruikers die de voorkeur geven aan Kubernetes en zelf infrastructuurvereisten kunnen beheren |
| Knooppuntinrichting | Beheerde compute-inrichting, update, verwijdering | Verantwoordelijkheid van gebruikers |
| Knooppuntonderhoud | Updates van installatiekopieën van beheerde hostbesturingssystemen en beveiligingsmaatregelen | Verantwoordelijkheid van gebruikers |
| Grootte van cluster (schalen) | Beheerde handmatige en automatische schaalaanpassing ter ondersteuning van aanvullende inrichting van knooppunten | Handmatige en automatische schaalaanpassing, waarbij ondersteuning wordt geboden voor het schalen van het aantal replica's binnen vaste clustergrenzen |
| Rekentype | Beheerd door de service | Door de klant beheerd Kubernetes-cluster |
| Beheerde identiteit | Ondersteund | Ondersteund |
| Virtueel netwerk | Ondersteund via beheerd netwerkisolatie | Verantwoordelijkheid van gebruikers |
| Out-of-box bewaking en logboekregistratie | Met Azure Monitor en Log Analytics mogelijk gemaakt, inclusief belangrijke metrische gegevens en logboektabellen voor eindpunten en implementaties | Verantwoordelijkheid van gebruikers |
| Logboekregistratie met Application Insights (verouderd) | Ondersteund | Ondersteund |
| Kostenweergave | Gedetailleerd op eindpunt-/implementatieniveau | Clusterniveau |
| Kosten toegepast op | Virtuele machines (VM's) die zijn toegewezen aan de implementatie | VM's die zijn toegewezen aan het cluster |
| Gespiegeld verkeer | Ondersteund | Niet ondersteund |
| Implementatie zonder code | Ondersteunt MLflow- en Triton-modellen | Ondersteunt MLflow- en Triton-modellen |
Online implementaties
Een implementatie is een set resources en berekeningen die nodig zijn om het model te hosten dat de deductie uitvoert. Eén eindpunt kan meerdere implementaties met verschillende configuraties bevatten. Deze installatie helpt bij het loskoppelen van de interface die door het eindpunt wordt gepresenteerd, van de implementatiedetails die aanwezig zijn in de implementatie. Een online-eindpunt heeft een routeringsmechanisme waarmee aanvragen naar specifieke implementaties in het eindpunt kunnen worden omgeleid.
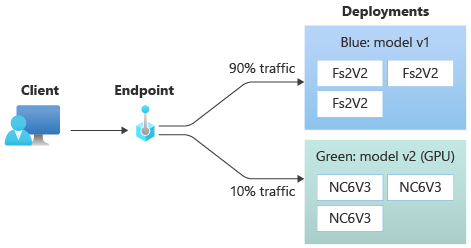
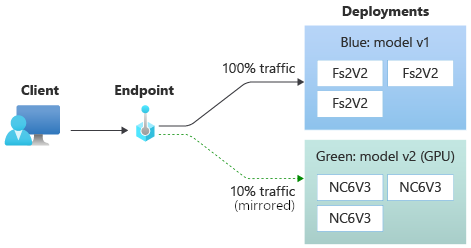
In het volgende diagram ziet u een online-eindpunt met twee implementaties, blauw en groen. De blauwe implementatie maakt gebruik van VM's met een CPU-SKU en voert versie 1 van een model uit. De groene implementatie maakt gebruik van VM's met een GPU-SKU en voert versie 2 van het model uit. Het eindpunt is geconfigureerd om 90% van het binnenkomende verkeer naar de blauwe implementatie te routeren, terwijl de groene implementatie de resterende 10% ontvangt.
Als u een model wilt implementeren, moet u het volgende hebben:
Modelbestanden of de naam en versie van een model dat al in uw werkruimte is geregistreerd.
Scorescriptcode waarmee het model wordt uitgevoerd op een bepaalde invoeraanvraag.
Het scorescript ontvangt gegevens die zijn verzonden naar een geïmplementeerde webservice en geeft deze door aan het model. Het script voert vervolgens het model uit en retourneert de reactie op de client. Het scorescript is specifiek voor uw model en moet inzicht hebben in de gegevens die het model als invoer verwacht en als uitvoer retourneert.
Een omgeving om uw model uit te voeren. De omgeving kan een Docker-installatiekopieën zijn met Conda-afhankelijkheden of een Dockerfile.
Instellingen voor het opgeven van het exemplaartype en de schaalcapaciteit.
Zie Een machine learning-model implementeren met behulp van een online-eindpunt voor meer informatie over het implementeren van online-eindpunten met behulp van de Azure CLI, Python SDK, Azure Machine Learning-studio of een ARM-sjabloon.
Belangrijkste kenmerken van een implementatie
In de volgende tabel worden de belangrijkste kenmerken van een implementatie beschreven:
| Kenmerk | Beschrijving |
|---|---|
| Naam | De naam van de implementatie. |
| Naam Eeindpunt | De naam van het eindpunt voor het maken van de implementatie onder. |
| Modelleren | Het model dat moet worden gebruikt voor de implementatie. Deze waarde kan een verwijzing zijn naar een bestaand versiemodel in de werkruimte of een inline modelspecificatie. Zie Model opgeven om te implementeren voor gebruik in online-eindpunten voor meer informatie over het bijhouden en opgeven van het pad naar uw model. |
| Codepad | Het pad naar de map in de lokale ontwikkelomgeving die alle Python-broncode bevat voor het scoren van het model. U kunt geneste mappen en pakketten gebruiken. |
| Scorescript | Het relatieve pad naar het scorebestand in de broncodemap. Deze Python-code moet een init() functie en een run() functie hebben. De init() functie wordt aangeroepen nadat het model is gemaakt of bijgewerkt, bijvoorbeeld om het model in het geheugen op te cachen. De run() functie wordt aangeroepen bij elke aanroep van het eindpunt om de werkelijke score en voorspelling uit te voeren. |
| Omgeving | De omgeving voor het hosten van het model en de code. Deze waarde kan een verwijzing zijn naar een bestaande versieomgeving in de werkruimte of een inline-omgevingsspecificatie. |
| Type instantie | De VM-grootte die moet worden gebruikt voor de implementatie. Zie de lijst met beheerde online-eindpunten voor SKU's voor de lijst met ondersteunde grootten. |
| Aantal exemplaren | Het aantal exemplaren dat moet worden gebruikt voor de implementatie. Baseer de waarde op de workload die u verwacht. Stel voor hoge beschikbaarheid de waarde in op ten minste 3. Het systeem reserveert een extra 20% voor het uitvoeren van upgrades. Zie VM-quotumtoewijzing voor implementaties voor meer informatie. |
Notities voor online-implementaties
De implementatie kan op elk gewenst moment verwijzen naar het model en de containerinstallatiekopieën die zijn gedefinieerd in de omgeving , bijvoorbeeld wanneer de implementatie-exemplaren beveiligingspatches of andere herstelbewerkingen ondergaan. Als u een geregistreerd model of containerinstallatiekopieën in Azure Container Registry gebruikt voor implementatie en later het model of de containerinstallatiekopieën verwijdert, kunnen de implementaties die afhankelijk zijn van deze assets mislukken bij het opnieuw instellen. Als u het model of de containerinstallatiekopieën verwijdert, moet u de afhankelijke implementaties opnieuw maken of bijwerken met een alternatief model of containerinstallatiekopieën.
Het containerregister waarnaar de omgeving verwijst, kan alleen privé zijn als de eindpuntidentiteit toegang heeft via Microsoft Entra-verificatie en op rollen gebaseerd toegangsbeheer (RBAC) van Azure. Om dezelfde reden worden andere privé-Docker-registers dan Container Registry niet ondersteund.
Microsoft patcht regelmatig de basisinstallatiekopieën op bekende beveiligingsproblemen. U moet uw eindpunt opnieuw implementeren om de patch-installatiekopie te gebruiken. Als u uw eigen installatiekopieën opgeeft, bent u verantwoordelijk voor het bijwerken ervan. Zie Installatiekopieën patchen voor meer informatie.
VM-quotumtoewijzing voor implementatie
Voor beheerde online-eindpunten reserveert Azure Machine Learning 20% van uw rekenresources voor het uitvoeren van upgrades op sommige VM-SKU's. Als u een bepaald aantal exemplaren voor deze VM-SKU's in een implementatie aanvraagt, moet u een quotum hebben dat ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU beschikbaar is om te voorkomen dat er een fout optreedt. Als u bijvoorbeeld 10 exemplaren van een Standard_DS3_v2 VM aanvraagt (die wordt geleverd met vier kernen) in een implementatie, moet u een quotum hebben voor 48 kernen (12 instances * 4 cores) beschikbaar. Dit extra quotum is gereserveerd voor door het systeem geïnitieerde bewerkingen, zoals upgrades van het besturingssysteem en vm-herstel, en er worden geen kosten in rekening gebracht, tenzij dergelijke bewerkingen worden uitgevoerd.
Er zijn bepaalde VM-SKU's die zijn uitgesloten van extra quotumreservering. Als u de volledige lijst wilt bekijken, raadpleegt u de SKU-lijst met beheerde online-eindpunten. Zie Uw gebruiks- en quotaverhogingen weergeven in Azure Portal om uw gebruik en quota te bekijken. Als u de kosten voor het uitvoeren van een beheerd online-eindpunt wilt bekijken, raadpleegt u De kosten voor een beheerd online-eindpunt weergeven.
Gedeelde quotumgroep
Azure Machine Learning biedt een gedeelde quotumgroep van waaruit gebruikers in verschillende regio's toegang hebben tot het quotum voor het uitvoeren van tests gedurende een beperkte tijd, afhankelijk van de beschikbaarheid. Wanneer u de studio gebruikt voor het implementeren van Llama-2, Phi, Nemotron, Mistral, Dolly en Deci-DeciLM-modellen uit de modelcatalogus naar een beheerd online-eindpunt, kunt u met Azure Machine Learning gedurende korte tijd toegang krijgen tot de gedeelde quotumpool, zodat u tests kunt uitvoeren. Zie het gedeelde quotum van Azure Machine Learning voor meer informatie over de gedeelde quotumgroep.
Als u Llama-2-modellen, Phi, Nemotron, Mistral, Dolly en Deci-DeciLM-modellen uit de modelcatalogus wilt implementeren met behulp van het gedeelde quotum, moet u een Enterprise Overeenkomst abonnement hebben. Zie Basismodellen implementeren met behulp van de studio voor meer informatie over het gebruik van het gedeelde quotum voor online-eindpuntimplementatie.
Implementatie voor coders en niet-coderingen
Azure Machine Learning ondersteunt modelimplementatie naar online-eindpunten voor coders en niet-coderingen door opties te bieden voor implementatie zonder code, implementatie met weinig code en BYOC-implementatie (Bring Your Own Container).
- Implementatie zonder code biedt kant-en-klare deductie voor algemene frameworks zoals scikit-learn, TensorFlow, PyTorch en Open Neural Network Exchange (ONNX) via MLflow en Triton.
- Met implementatie met weinig code kunt u minimale code bieden, samen met uw machine learning-model voor implementatie.
- Met BYOC-implementatie kunt u vrijwel alle containers meenemen om uw online-eindpunt uit te voeren. U kunt alle functies van het Azure Machine Learning-platform gebruiken, zoals automatisch schalen, GitOps, foutopsporing en veilige implementatie om uw MLOps-pijplijnen te beheren.
In de volgende tabel worden belangrijke aspecten van de online implementatieopties gemarkeerd:
| Geen code | Weinig code | BYOC | |
|---|---|---|---|
| Samenvatting | Maakt gebruik van kant-en-klare deductie voor populaire frameworks zoals scikit-learn, TensorFlow, PyTorch en ONNX, via MLflow en Triton. Zie MLflow-modellen implementeren naar online-eindpunten voor meer informatie. | Maakt gebruik van beveiligde, openbaar gepubliceerde gecureerde installatiekopieën voor populaire frameworks, met updates om de twee weken om beveiligingsproblemen op te lossen. U geeft scorescripts en/of Python-afhankelijkheden op. Zie Azure Machine Learning Gecureerde omgevingen voor meer informatie. | U geeft uw volledige stack op via Azure Machine Learning-ondersteuning voor aangepaste installatiekopieën. Zie Een aangepaste container gebruiken om een model te implementeren op een online-eindpunt voor meer informatie. |
| Aangepaste basisinstallatiekopieën | Geen. Gecureerde omgevingen bieden de basisinstallatiekopieën voor eenvoudige implementatie. | U kunt een gecureerde afbeelding of uw aangepaste afbeelding gebruiken. | Breng een toegankelijke locatie voor containerinstallatiekopieën, zoals docker.io, Container Registry of Microsoft-artefactregister, of een Dockerfile die u kunt bouwen/pushen met Container Registry voor uw container. |
| Aangepaste afhankelijkheden | Geen. Gecureerde omgevingen bieden afhankelijkheden voor eenvoudige implementatie. | Breng de Azure Machine Learning-omgeving waarin het model wordt uitgevoerd, ofwel een Docker-installatiekopieën met Conda-afhankelijkheden of een dockerfile. | Aangepaste afhankelijkheden worden opgenomen in de containerinstallatiekopieën. |
| Aangepaste code | Geen. Het scorescript wordt automatisch gegenereerd voor eenvoudige implementatie. | Breng uw scorescript. | Het scorescript wordt opgenomen in de containerinstallatiekopieën. |
Notitie
AutoML-uitvoeringen maken automatisch een scorescript en afhankelijkheden voor gebruikers. Voor implementatie zonder code kunt u elk AutoML-model implementeren zonder dat u andere code hoeft te ontwerpen. Voor implementatie met weinig code kunt u automatisch gegenereerde scripts aanpassen aan uw bedrijfsbehoeften. Zie Een AutoML-model implementeren op een online-eindpunt voor meer informatie over het implementeren met AutoML-modellen.
Foutopsporing voor online-eindpunten
Voer uw eindpunt indien mogelijk lokaal uit om uw code en configuratie te valideren en fouten op te sporen voordat u implementeert in Azure. Azure CLI en Python SDK ondersteunen lokale eindpunten en implementaties, terwijl Azure Machine Learning-studio en ARM-sjablonen geen ondersteuning bieden voor lokale eindpunten of implementaties.
Azure Machine Learning biedt de volgende manieren om lokaal fouten in online-eindpunten op te sporen en met behulp van containerlogboeken:
- Lokale foutopsporing met HTTP-server voor Azure Machine Learning-deductie
- Lokale foutopsporing met lokaal eindpunt
- Lokale foutopsporing met lokaal eindpunt en Visual Studio Code
- Foutopsporing met containerlogboeken
Lokale foutopsporing met HTTP-server voor Azure Machine Learning-deductie
U kunt lokaal fouten opsporen in uw scorescript met behulp van de HTTP-server van Deductie van Azure Machine Learning. De HTTP-server is een Python-pakket dat uw scorefunctie beschikbaar maakt als een HTTP-eindpunt en de Flask-servercode en afhankelijkheden verpakt in één pakket.
Azure Machine Learning bevat een HTTP-server in de vooraf gemaakte Docker-installatiekopieën voor deductie die wordt gebruikt voor het implementeren van een model. Door alleen het pakket te gebruiken, kunt u het model lokaal implementeren voor productie en kunt u ook eenvoudig uw scorescript voor invoer valideren in een lokale ontwikkelomgeving. Als er een probleem is met het scorescript, retourneert de server een fout en de locatie waar de fout is opgetreden. U kunt Visual Studio Code ook gebruiken om fouten op te sporen met de AZURE Machine Learning-deductie-HTTP-server.
Tip
U kunt het Python-pakket azure Machine Learning-deductie http-server gebruiken om lokaal fouten in uw scorescript op te sporen zonder Docker Engine. Foutopsporing met de deductieserver helpt u bij het opsporen van fouten in het scorescript voordat u implementeert op lokale eindpunten, zodat u fouten kunt opsporen zonder dat dit wordt beïnvloed door de configuraties van de implementatiecontainer.
Zie Voor meer informatie over foutopsporing met de HTTP-server foutopsporingsscript met Http-server voor deductie van Azure Machine Learning.
Lokale foutopsporing met lokaal eindpunt
Voor lokale foutopsporing hebt u een model nodig dat is geïmplementeerd in een lokale Docker-omgeving. U kunt deze lokale implementatie gebruiken voor het testen en opsporen van fouten voordat de implementatie in de cloud wordt uitgevoerd.
Als u lokaal wilt implementeren, moet de Docker Engine zijn geïnstalleerd en uitgevoerd. Azure Machine Learning maakt vervolgens een lokale Docker-installatiekopieën om de onlineinstallatiekopieën na te bootsen. Azure Machine Learning bouwt en voert implementaties voor u lokaal uit en slaat de installatiekopieën in de cache op voor snelle iteraties.
Tip
Als Docker Engine niet start wanneer de computer wordt gestart, kunt u problemen met Docker Engine oplossen. U kunt hulpprogramma's aan de clientzijde, zoals Docker Desktop , gebruiken om fouten op te sporen in wat er in de container gebeurt.
Lokale foutopsporing omvat doorgaans de volgende stappen:
- Controleer eerst of de lokale implementatie is geslaagd.
- Roep vervolgens het lokale eindpunt aan voor deductie.
- Controleer ten slotte de uitvoerlogboeken voor de
invokebewerking.
Lokale eindpunten hebben de volgende beperkingen:
Geen ondersteuning voor verkeersregels, verificatie of testinstellingen.
Ondersteuning voor slechts één implementatie per eindpunt.
Ondersteuning voor lokale modelbestanden en omgevingen met alleen lokaal Conda-bestand.
Als u geregistreerde modellen wilt testen, moet u ze eerst downloaden met behulp van CLI of SDK en vervolgens in de implementatiedefinitie gebruiken
pathom naar de bovenliggende map te verwijzen.Als u geregistreerde omgevingen wilt testen, controleert u de context van de omgeving in Azure Machine Learning-studio en bereidt u een lokaal Conda-bestand voor dat u wilt gebruiken.
Zie Lokaal implementeren en fouten opsporen met behulp van een lokaal eindpunt voor meer informatie over lokale foutopsporing.
Lokale foutopsporing met lokaal eindpunt en Visual Studio Code (preview)
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Net als bij lokale foutopsporing moet de Docker Engine zijn geïnstalleerd en uitgevoerd en vervolgens een model implementeren in de lokale Docker-omgeving. Zodra u een lokale implementatie hebt, gebruiken lokale Azure Machine Learning-eindpunten Docker- en Visual Studio Code-ontwikkelcontainers (dev-containers) om een lokale foutopsporingsomgeving te bouwen en te configureren.
Met dev-containers kunt u Visual Studio Code-functies gebruiken, zoals interactieve foutopsporing vanuit een Docker-container. Zie Debug online eindpunten lokaal in Visual Studio Code voor meer informatie over interactief foutopsporing van online-eindpunten in Visual Studio Code.
Foutopsporing met containerlogboeken
U kunt geen directe toegang krijgen tot een virtuele machine waarop een model wordt geïmplementeerd, maar u kunt logboeken ophalen uit de volgende containers die op de VIRTUELE machine worden uitgevoerd:
- Het consolelogboek van de deductieserver bevat de uitvoer van functies voor afdrukken/logboekregistratie van uw scorescript score.py code.
- Initialisatielogboeken voor opslag bevatten informatie over of code- en modelgegevens zijn gedownload naar de container. De container wordt uitgevoerd voordat de container van de deductieserver wordt uitgevoerd.
Zie Containerlogboeken ophalen voor meer informatie over foutopsporing met containerlogboeken.
Verkeersroutering en spiegeling naar onlineimplementaties
Eén online-eindpunt kan meerdere implementaties hebben. Wanneer het eindpunt binnenkomende verkeersaanvragen ontvangt, kan het percentage verkeer naar elke implementatie routeren, zoals in de systeemeigen blauw/groene implementatiestrategie. Het eindpunt kan ook verkeer van de ene implementatie naar de andere spiegelen of kopiëren, ook wel verkeer spiegelen of schaduwen genoemd.
Verkeersroutering voor blauw/groen implementatie
Blauw/groen-implementatie is een implementatiestrategie waarmee u een nieuwe groene implementatie kunt implementeren voor een kleine subset van gebruikers of aanvragen voordat u deze volledig uitrolt. Het eindpunt kan taakverdeling implementeren om bepaalde percentages van het verkeer toe te wijzen aan elke implementatie, waarbij de totale toewijzing voor alle implementaties 100% bedraagt.
Tip
Een aanvraag kan de geconfigureerde verkeerstaakverdeling omzeilen door een HTTP-header van azureml-model-deployment. Stel de headerwaarde in op de naam van de implementatie waarnaar u de aanvraag wilt routeren.
In de volgende afbeelding ziet u instellingen in Azure Machine Learning-studio voor het toewijzen van verkeer tussen een blauwe en groene implementatie.
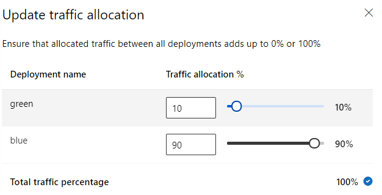
De voorgaande verkeerstoewijzing routeert 10% van het verkeer naar de groene implementatie en 90% van het verkeer naar de blauwe implementatie, zoals wordt weergegeven in de volgende afbeelding.
Verkeer spiegelen naar online-implementaties
Het eindpunt kan ook verkeer van de ene implementatie naar de andere spiegelen of kopiëren. U kunt verkeerspiegeling, ook wel schaduwtests genoemd, gebruiken als u een nieuwe implementatie met productieverkeer wilt testen zonder dat dit van invloed is op de resultaten die klanten ontvangen van bestaande implementaties.
U kunt bijvoorbeeld een blauw/groene implementatie implementeren waarbij 100% van het verkeer wordt gerouteerd naar blauw en 10% wordt gespiegeld aan de groene implementatie. De resultaten van het gespiegelde verkeer naar de groene implementatie worden niet geretourneerd naar de clients, maar de metrische gegevens en logboeken worden vastgelegd.
Zie Veilige implementatie van nieuwe implementaties uitvoeren voor realtime deductie voor meer informatie over het gebruik van verkeersspiegeling.
Meer mogelijkheden voor online-eindpunten
In de volgende secties worden andere mogelijkheden van online-eindpunten van Azure Machine Learning beschreven.
Verificatie en versleuteling
- Verificatie: Sleutel- en Azure Machine Learning-tokens
- Beheerde identiteit: Door de gebruiker toegewezen en het systeem toegewezen
- Ssl (Secure Socket Layer) standaard voor eindpuntoproep
Automatisch schalen
Automatisch schalen wordt uitgevoerd met de juiste hoeveelheid resources om de belasting van uw toepassing te verwerken. Beheerde eindpunten ondersteunen automatisch schalen via integratie met de functie voor automatische schaalaanpassing van Azure Monitor. U kunt schaalaanpassing op basis van metrische gegevens configureren, zoals CPU-gebruik >van 70%, schaalaanpassing op basis van een planning, zoals piekregels voor bedrijfuren of beide.

Zie Online-eindpunten automatisch schalen in Azure Machine Learning voor meer informatie.
Beheerde netwerkisolatie
Wanneer u een machine learning-model implementeert op een beheerd online-eindpunt, kunt u de communicatie met het online-eindpunt beveiligen met behulp van privé-eindpunten. U kunt de beveiliging voor binnenkomende scoreaanvragen en uitgaande communicatie afzonderlijk configureren.
Inkomende communicatie maakt gebruik van het privé-eindpunt van de Azure Machine Learning-werkruimte, terwijl uitgaande communicatie privé-eindpunten gebruikt die zijn gemaakt voor het beheerde virtuele netwerk van de werkruimte. Zie Netwerkisolatie met beheerde online-eindpunten voor meer informatie.
Online-eindpunten en -implementaties bewaken
Azure Machine Learning-eindpunten kunnen worden geïntegreerd met Azure Monitor. Met Azure Monitor-integratie kunt u metrische gegevens weergeven in grafieken, waarschuwingen configureren, querylogboektabellen en Application Insights gebruiken om gebeurtenissen uit gebruikerscontainers te analyseren. Zie Online-eindpunten bewaken voor meer informatie.
Geheime injectie in online implementaties (preview)
Geheime injectie voor een online-implementatie omvat het ophalen van geheimen, zoals API-sleutels uit geheime archieven en het injecteren ervan in de gebruikerscontainer die in de implementatie wordt uitgevoerd. Als u een beveiligd geheimverbruik wilt bieden voor de deductieserver waarop uw scorescript of de deductiestack in uw BYOC-implementatie wordt uitgevoerd, kunt u omgevingsvariabelen gebruiken om toegang te krijgen tot geheimen.
U kunt geheimen zelf injecteren met behulp van beheerde identiteiten of u kunt de functie voor geheime injectie gebruiken. Zie Geheime injectie in online-eindpunten (preview)voor meer informatie.
Gerelateerde inhoud
- Een machine learning-model implementeren en beoordelen met behulp van een online-eindpunt
- Batch-eindpunten
- Uw beheerde online-eindpunten beveiligen met netwerkisolatie
- Modellen implementeren met REST
- Online eindpunten bewaken
- Kosten weergeven voor een online-eindpunt dat door Azure Machine Learning wordt beheerd
- Quota en limieten voor resources beheren en verhogen met Azure Machine Learning