AutoML instellen voor het trainen van een tijdreeksprognosemodel met SDK en CLI
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel leert u hoe u AutoML instelt voor tijdreeksprognoses met geautomatiseerde ML van Azure Machine Learning in de Azure Machine Learning Python SDK.
Dit doet u als volgt:
- Gegevens voorbereiden voor training.
- Configureer specifieke tijdreeksparameters in een prognosetaak.
- Training, deductie en modelevaluatie organiseren met behulp van onderdelen en pijplijnen.
Voor een ervaring met weinig code raadpleegt u de zelfstudie: Vraag voorspellen met geautomatiseerde machine learning voor een voorbeeld van een tijdreeksprognose met behulp van geautomatiseerde ML in de Azure Machine Learning-studio.
AutoML maakt gebruik van standaard machine learning-modellen, samen met bekende tijdreeksmodellen om prognoses te maken. Onze benadering bevat historische informatie over de doelvariabele, door de gebruiker verstrekte functies in de invoergegevens en automatisch ontworpen functies. Modelzoekalgoritmen werken vervolgens om een model te vinden met de beste voorspellende nauwkeurigheid. Zie onze artikelen over prognosemethodologie en modelzoekopdrachten voor meer informatie.
Vereisten
Voor dit artikel hebt u het volgende nodig:
Een Azure Machine Learning-werkruimte. Zie Werkruimtebronnen maken om de werkruimte te maken.
De mogelijkheid om AutoML-trainingstaken te starten. Volg de handleiding voor het instellen van AutoML voor meer informatie.
Trainings- en validatiegegevens
Invoergegevens voor AutoML-prognose moeten geldige tijdreeksen bevatten in tabelvorm. Elke variabele moet een eigen overeenkomende kolom in de gegevenstabel hebben. AutoML vereist ten minste twee kolommen: een tijdkolom die de tijdsas en de doelkolom vertegenwoordigt. Dit is de hoeveelheid die moet worden voorspeld. Andere kolommen kunnen fungeren als voorspellers. Zie voor meer informatie hoe AutoML uw gegevens gebruikt.
Belangrijk
Wanneer u een model traint voor het voorspellen van toekomstige waarden, moet u ervoor zorgen dat alle functies die in de training worden gebruikt, kunnen worden gebruikt bij het uitvoeren van voorspellingen voor uw beoogde horizon.
Een functie voor de huidige aandelenkoers kan bijvoorbeeld de nauwkeurigheid van de training enorm verhogen. Als u echter van plan bent om te voorspellen met een lange horizon, kunt u mogelijk niet nauwkeurig toekomstige aandelenwaarden voorspellen die overeenkomen met toekomstige tijdreekspunten en de nauwkeurigheid van het model kan lijden.
Voor AutoML-prognosetaken is vereist dat uw trainingsgegevens worden weergegeven als een MLTable-object . Een MLTable bevat een gegevensbron en stappen voor het laden van de gegevens. Zie de handleiding mlTable voor meer informatie en gebruiksvoorbeelden. Stel dat uw trainingsgegevens zijn opgenomen in een CSV-bestand in een lokale map. ./train_data/timeseries_train.csv
U kunt een MLTable maken met behulp van de Mltable Python SDK , zoals in het volgende voorbeeld:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Met deze code maakt u een nieuw bestand, ./train_data/MLTabledat de bestandsindeling en laadinstructies bevat.
U definieert nu een invoergegevensobject, dat vereist is om een trainingstaak te starten, met behulp van de Azure Machine Learning Python SDK als volgt:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
U geeft validatiegegevens op een vergelijkbare manier op door een MLTable te maken en een invoer voor validatiegegevens op te geven. Als u geen validatiegegevens opgeeft, worden in AutoML automatisch kruisvalidatiesplitsingen gemaakt van uw trainingsgegevens die moeten worden gebruikt voor modelselectie. Zie ons artikel over het voorspellen van modelselectie voor meer informatie. Zie ook de vereisten voor lengte van trainingsgegevens voor meer informatie over hoeveel trainingsgegevens u nodig hebt om een prognosemodel te trainen.
Meer informatie over hoe AutoML kruisvalidatie toepast om te voorkomen dat overpassen wordt toegepast.
Compute en uitvoering van het experiment instellen
AutoML maakt gebruik van Azure Machine Learning Compute, een volledig beheerde rekenresource, om de trainingstaak uit te voeren. In het volgende voorbeeld wordt een rekencluster met de naam cpu-compute gemaakt:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Experiment configureren
U gebruikt de automl-factoryfuncties om prognoses te configureren in de Python SDK. In het volgende voorbeeld ziet u hoe u een prognosetaak maakt door de primaire metrische gegevens in te stellen en limieten in te stellen voor de trainingsuitvoering:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Taakinstellingen voor prognose
Prognosetaken hebben veel instellingen die specifiek zijn voor prognoses. De meest elementaire van deze instellingen zijn de naam van de tijdkolom in de trainingsgegevens en de prognosehorizk.
Gebruik de ForecastingJob-methoden om deze instellingen te configureren:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
De naam van de tijdkolom is een vereiste instelling en u moet in het algemeen de prognosehorizk instellen op basis van uw voorspellingsscenario. Als uw gegevens meerdere tijdreeksen bevatten, kunt u de namen van de kolommen met tijdreeks-id's opgeven. Wanneer deze kolommen zijn gegroepeerd, definieert u de afzonderlijke reeksen. Stel dat u gegevens hebt die bestaan uit uurverkopen uit verschillende winkels en merken. In het volgende voorbeeld ziet u hoe u de tijdreeks-id-kolommen instelt, ervan uitgaande dat de gegevens kolommen bevatten met de naam 'store' en 'merk':
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML probeert automatisch tijdreeks-id-kolommen in uw gegevens te detecteren als er geen kolommen zijn opgegeven.
Andere instellingen zijn optioneel en gecontroleerd in de volgende sectie.
Optionele instellingen voor prognosetaak
Er zijn optionele configuraties beschikbaar voor het voorspellen van taken, zoals het inschakelen van deep learning en het opgeven van een doelaggregatie van rolling windows. Er is een volledige lijst met parameters beschikbaar in de documentatie over prognosereferenties.
Zoekinstellingen voor modellen
Er zijn twee optionele instellingen die de modelruimte bepalen waar AutoML zoekt naar het beste model allowed_training_algorithms en blocked_training_algorithms. Als u de zoekruimte wilt beperken tot een bepaalde set modelklassen, gebruikt u de allowed_training_algorithms parameter zoals in het volgende voorbeeld:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
In dit geval zoekt de prognosetaak alleen naar exponentieel smoothing- en elastic net-modelklassen. Als u een bepaalde set modelklassen uit de zoekruimte wilt verwijderen, gebruikt u de blocked_training_algorithms zoals in het volgende voorbeeld:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
De taak doorzoekt nu alle modelklassen behalve Prophet. Zie de referentiedocumentatie voor trainingseigenschappen voor een lijst met prognosemodelnamen die worden geaccepteerd allowed_training_algorithms in enblocked_training_algorithms. Beide, maar niet beide, van allowed_training_algorithms en blocked_training_algorithms kunnen worden toegepast op een trainingsuitvoering.
Deep Learning inschakelen
AutoML wordt geleverd met een aangepast DNN-model (Deep Neural Network) genaamd TCNForecaster. Dit model is een tijdelijk convolutionele netwerk, of TCN, waarmee algemene methoden voor imaging-taken worden toegepast op tijdreeksmodellering. Dat wil zeggen dat eendimensionale "causale" samenvoegingen de backbone van het netwerk vormen en het model in staat stellen om complexe patronen te leren over lange duur in de trainingsgeschiedenis. Zie ons TCNForecaster-artikel voor meer informatie.
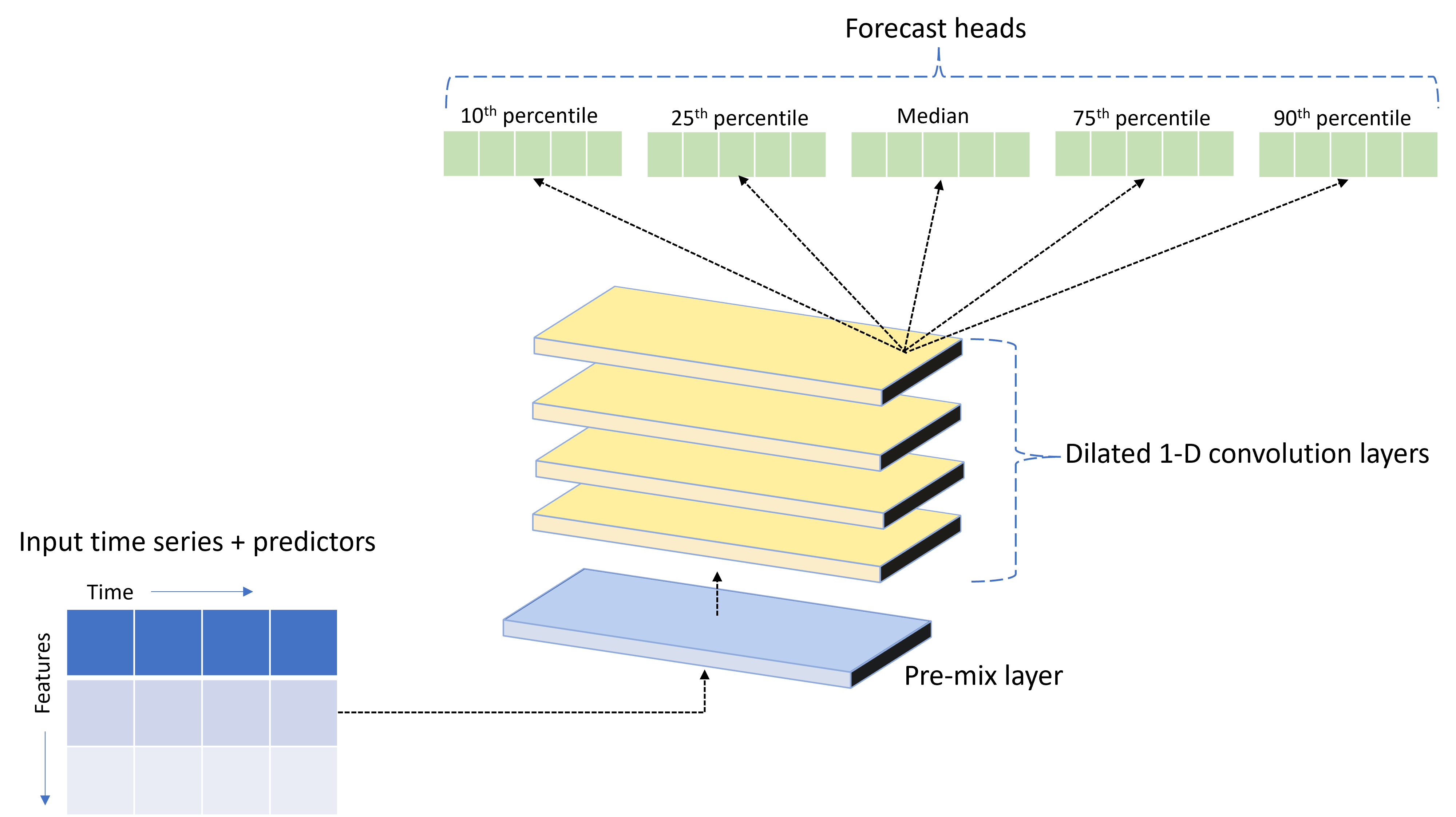
De TCNForecaster bereikt vaak een hogere nauwkeurigheid dan standaard tijdreeksmodellen wanneer er duizenden of meer waarnemingen in de trainingsgeschiedenis zijn. Het duurt echter ook langer om TCNForecaster-modellen te trainen en te vegen vanwege hun hogere capaciteit.
U kunt de TCNForecaster in AutoML inschakelen door de enable_dnn_training vlag in de trainingsconfiguratie als volgt in te stellen:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
TCNForecaster-training is standaard beperkt tot één rekenknooppunt en één GPU, indien beschikbaar, per modelabonnement. Voor scenario's met grote gegevens raden we u aan elke TCNForecaster-proefversie over meerdere kernen/GPU's en knooppunten te distribueren. Zie de sectie met gedistribueerde trainingsartikels voor meer informatie en codevoorbeelden.
Als u DNN wilt inschakelen voor een AutoML-experiment dat is gemaakt in de Azure Machine Learning-studio, raadpleegt u de taaktype-instellingen in de gebruikersinterface van studio.
Notitie
- Wanneer u DNN inschakelt voor experimenten die zijn gemaakt met de SDK, worden de beste modeluitlegen uitgeschakeld.
- DNN-ondersteuning voor prognoses in geautomatiseerde machine learning wordt niet ondersteund voor uitvoeringen die in Databricks zijn geïnitieerd.
- GPU-rekentypen worden aanbevolen wanneer DNN-training is ingeschakeld
Functies voor vertragings- en rollend venster
Recente waarden van het doel zijn vaak van invloed op functies in een prognosemodel. AutoML kan daarom functies voor aggregatie van tijd- en rolling vensters maken om de nauwkeurigheid van het model mogelijk te verbeteren.
Overweeg een scenario voor het voorspellen van energievraag waarbij weergegevens en historische vraag beschikbaar zijn. In de tabel ziet u de resulterende functie-engineering die optreedt wanneer vensteraggregatie gedurende de meest recente drie uur wordt toegepast. Kolommen voor minimum, maximum en som worden gegenereerd in een schuifvenster van drie uur op basis van de gedefinieerde instellingen. Voor de waarneming die bijvoorbeeld geldig is op 8 september 2017 4:00 uur, worden de maximum-, minimum- en somwaarden berekend met behulp van de vraagwaarden voor 8 september 2017 1:00 - 3:00 uur. In dit venster van drie uur worden gegevens voor de resterende rijen ingevuld. Zie het artikel over vertragingsfuncties voor meer informatie en voorbeelden.

U kunt aggregatiefuncties voor vertragings- en rollingvensters voor het doel inschakelen door de grootte van het rolling-venster in te stellen, die in het vorige voorbeeld drie was en de vertragingsorders die u wilt maken. U kunt ook vertragingen inschakelen voor functies met de feature_lags instelling. In het volgende voorbeeld stellen we al deze instellingen auto zo in dat AutoML automatisch instellingen bepaalt door de correlatiestructuur van uw gegevens te analyseren:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Verwerking van korte reeksen
Geautomatiseerde ML beschouwt een tijdreeks in een korte reeks als er onvoldoende gegevenspunten zijn om de train- en validatiefasen van modelontwikkeling uit te voeren. Zie vereisten voor lengte van trainingsgegevens voor meer informatie over lengtevereisten.
AutoML heeft verschillende acties die kunnen worden uitgevoerd voor korte reeksen. Deze acties kunnen worden geconfigureerd met de short_series_handling_config instelling. De standaardwaarde is 'auto'. In de volgende tabel worden de instellingen beschreven:
| Instelling | Beschrijving |
|---|---|
auto |
De standaardwaarde voor het verwerken van korte reeksen. - Als alle reeksen kort zijn, vult u de gegevens in. - Als niet alle reeksen kort zijn, zet u de korte reeks neer. |
pad |
Als short_series_handling_config = pad, dan voegt geautomatiseerde ML willekeurige waarden toe aan elke korte reeks gevonden. Hieronder ziet u de kolomtypen en waarmee ze zijn opgevuld: - Objectkolommen met NaN's - Numerieke kolommen met 0 - Booleaanse/logische kolommen met Onwaar - De doelkolom wordt opgevuld met witte ruis. |
drop |
Als short_series_handling_config = dropgeautomatiseerde ML de korte reeks afneemt en deze niet wordt gebruikt voor training of voorspelling. Voorspellingen voor deze reeks retourneren NaN's. |
None |
Er is geen reeks opgevuld of verwijderd |
In het volgende voorbeeld stellen we de verwerking van korte reeksen in, zodat alle korte reeksen worden opgevuld tot de minimale lengte:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Waarschuwing
Opvulling kan van invloed zijn op de nauwkeurigheid van het resulterende model, omdat we kunstmatige gegevens introduceren om trainingsfouten te voorkomen. Als veel van de reeks kort zijn, ziet u mogelijk ook enige impact in de resultaten van de uitlegbaarheid
Frequentie en doelgegevensaggregatie
Gebruik de opties voor frequentie en gegevensaggregatie om fouten te voorkomen die worden veroorzaakt door onregelmatige gegevens. Uw gegevens zijn onregelmatig als ze geen vaste frequentie in tijd volgen, zoals elk uur of dagelijks. Point-of-sales-gegevens zijn een goed voorbeeld van onregelmatige gegevens. In deze gevallen kan AutoML uw gegevens aggregeren naar een gewenste frequentie en vervolgens een prognosemodel bouwen op basis van de aggregaties.
U moet de frequency en target_aggregate_function instellingen instellen om onregelmatige gegevens te verwerken. De frequentie-instelling accepteert Pandas DateOffset-tekenreeksen als invoer. Ondersteunde waarden voor de aggregatiefunctie zijn:
| Functie | Beschrijving |
|---|---|
sum |
Som van doelwaarden |
mean |
Gemiddelde of gemiddelde van doelwaarden |
min |
Minimumwaarde van een doel |
max |
Maximumwaarde van een doel |
- De doelkolomwaarden worden geaggregeerd volgens de opgegeven bewerking. Meestal is som geschikt voor de meeste scenario's.
- Numerieke predictorkolommen in uw gegevens worden geaggregeerd op som, gemiddelde, minimumwaarde en maximumwaarde. Als gevolg hiervan genereert geautomatiseerde ML nieuwe kolommen met de naam van de aggregatiefunctie en past de geselecteerde statistische bewerking toe.
- Voor categorische predictorkolommen worden de gegevens samengevoegd op modus, de meest prominente categorie in het venster.
- Datum voorspellende kolommen worden geaggregeerd op minimumwaarde, maximumwaarde en modus.
In het volgende voorbeeld wordt de frequentie ingesteld op uur en de aggregatiefunctie om op te sommen:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Aangepaste instellingen voor kruisvalidatie
Er zijn twee aanpasbare instellingen waarmee kruisvalidatie voor prognosetaken wordt beheerd: het aantal vouwen, n_cross_validationsen de stapgrootte die de tijdsverschil tussen vouwen definieert, cv_step_size. Zie de selectie van het prognosemodel voor meer informatie over de betekenis van deze parameters. AutoML stelt standaard beide instellingen automatisch in op basis van kenmerken van uw gegevens, maar geavanceerde gebruikers willen ze mogelijk handmatig instellen. Stel dat u dagelijkse verkoopgegevens hebt en u wilt dat uw validatie-instelling bestaat uit vijf vouwen met een verschuiving van zeven dagen tussen aangrenzende vouwen. In het volgende codevoorbeeld ziet u hoe u deze kunt instellen:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Aangepaste featurization
Met AutoML worden standaard trainingsgegevens aangevuld met ontworpen functies om de nauwkeurigheid van de modellen te vergroten. Zie geautomatiseerde functie-engineering voor meer informatie. Sommige van de voorverwerkingsstappen kunnen worden aangepast met behulp van de featurization-configuratie van de prognosetaak.
Ondersteunde aanpassingen voor prognoses staan in de volgende tabel:
| Aanpassing | Beschrijving | Opties |
|---|---|---|
| Update van kolomdoel | Overschrijf het automatisch gedetecteerde functietype voor de opgegeven kolom. | "Categorisch", "Datum/tijd", "Numeriek" |
| Parameterupdate voor transformatieprogramma | Werk de parameters voor de opgegeven imputer bij. | {"strategy": "constant", "fill_value": <value>}, , {"strategy": "median"}{"strategy": "ffill"} |
Stel dat u een scenario hebt waarin de gegevens prijzen, een vlag 'te koop' en een producttype bevatten. In het volgende voorbeeld ziet u hoe u aangepaste typen en imputers voor deze functies kunt instellen:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Als u de Azure Machine Learning-studio voor uw experiment gebruikt, raadpleegt u hoe u featurization kunt aanpassen in de studio.
Een prognosetaak verzenden
Nadat alle instellingen zijn geconfigureerd, start u de prognosetaak als volgt:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
Zodra de taak is verzonden, richt AutoML rekenresources in, past u featurization en andere voorbereidingsstappen toe op de invoergegevens en begint u vervolgens met het opruimen van voorspellingsmodellen. Zie onze artikelen over prognosemethodologie en modelzoekopdrachten voor meer informatie.
Training, deductie en evaluatie organiseren met onderdelen en pijplijnen
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Uw ML-werkstroom vereist waarschijnlijk meer dan alleen training. Deductie of het ophalen van modelvoorspellingen op nieuwere gegevens en de evaluatie van modelnauwkeurigheid op een testset met bekende doelwaarden zijn andere algemene taken die u in AzureML samen met trainingstaken kunt organiseren. Om deductie- en evaluatietaken te ondersteunen, biedt AzureML onderdelen, die zelfstandige stukjes code zijn die één stap in een AzureML-pijplijn uitvoeren.
In het volgende voorbeeld halen we onderdeelcode op uit een clientregister:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Vervolgens definiëren we een fabrieksfunctie waarmee pijplijnen worden gemaakt die training, deductie en metrische berekeningen organiseren. Zie de sectie trainingsconfiguratie voor meer informatie over trainingsinstellingen.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Nu definiëren we invoer van train- en testgegevens, ervan uitgaande dat ze zijn opgenomen in lokale mappen en ./train_data./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Ten slotte maken we de pijplijn, stellen we de standaard rekenkracht in en verzenden we de taak:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
Zodra de pijplijn is verzonden, voert de pijplijn AutoML-training, rolling evaluatiedeductie en metrische berekening in volgorde uit. U kunt de uitvoering bewaken en inspecteren in de gebruikersinterface van studio. Wanneer de uitvoering is voltooid, kunnen de rolling prognoses en de metrische evaluatiegegevens worden gedownload naar de lokale werkmap:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Vervolgens kunt u de metrische resultaten vinden in ./named-outputs/metrics_results/evaluationResult/metrics.json en de prognoses, in de indeling JSON-regels, in ./named-outputs/rolling_fcst_result/inference_output_file.
Zie het artikel over de evaluatie van het prognosemodel voor meer informatie over rolling evaluatie.
Prognose op schaal: veel modellen
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Met de vele onderdelen van modellen in AutoML kunt u miljoenen modellen parallel trainen en beheren. Zie de sectie met veel modellenartikels voor meer informatie over veel modelconcepten.
Trainingsconfiguratie voor veel modellen
Het trainingsonderdeel voor veel modellen accepteert een YAML-indelingsconfiguratiebestand van de AutoML-trainingsinstellingen. Het onderdeel past deze instellingen toe op elk AutoML-exemplaar dat wordt gestart. Dit YAML-bestand heeft dezelfde specificatie als de prognosetaak plus aanvullende parameters partition_column_names en allow_multi_partitions.
| Parameter | Description |
|---|---|
| partition_column_names | Kolomnamen in de gegevens die, wanneer gegroepeerd, de gegevenspartities definiëren. Het trainingsonderdeel voor veel modellen start een onafhankelijke trainingstaak op elke partitie. |
| allow_multi_partitions | Een optionele vlag waarmee één model per partitie kan worden getraind wanneer elke partitie meer dan één unieke tijdreeks bevat. De standaardwaarde is Onwaar. |
Het volgende voorbeeld bevat een configuratiesjabloon:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
In volgende voorbeelden wordt ervan uitgegaan dat de configuratie wordt opgeslagen op het pad. ./automl_settings_mm.yml
Veel modellenpijplijn
Vervolgens definiëren we een factory-functie waarmee pijplijnen worden gemaakt voor het organiseren van veel modellentraining, deductie en metrische berekeningen. De parameters van deze fabrieksfunctie worden beschreven in de volgende tabel:
| Parameter | Description |
|---|---|
| max_nodes | Aantal rekenknooppunten dat moet worden gebruikt in de trainingstaak |
| max_concurrency_per_node | Het aantal AutoML-processen dat op elk knooppunt moet worden uitgevoerd. Daarom is max_nodes * max_concurrency_per_nodede totale gelijktijdigheid van een groot aantal modellen taken. |
| parallel_step_timeout_in_seconds | Veel time-outs voor modellenonderdelen die in het aantal seconden zijn opgegeven. |
| retrain_failed_models | Vlag om opnieuw trainen voor mislukte modellen in te schakelen. Dit is handig als u eerder veel modellen hebt uitgevoerd, waardoor mislukte AutoML-taken op sommige gegevenspartities zijn uitgevoerd. Wanneer deze vlag is ingeschakeld, starten veel modellen alleen trainingstaken voor eerder mislukte partities. |
| forecast_mode | Deductiemodus voor modelevaluatie. Geldige waarden zijn "recursive" en 'rolling'. Zie het artikel over modelevaluatie voor meer informatie. |
| forecast_step | Stapgrootte voor rolling prognose. Zie het artikel over modelevaluatie voor meer informatie. |
In het volgende voorbeeld ziet u een fabrieksmethode voor het bouwen van veel modellen voor het trainen en evalueren van modellen:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Nu maken we de pijplijn via de fabrieksfunctie, ervan uitgaande dat de trainings- en testgegevens zich in lokale mappen ./data/train bevinden en ./data/test, respectievelijk. Ten slotte stellen we de standaard rekenkracht in en verzenden we de taak zoals in het volgende voorbeeld:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Nadat de taak is voltooid, kunnen de metrische evaluatiegegevens lokaal worden gedownload met behulp van dezelfde procedure als in de pijplijn voor één trainingsuitvoering.
Zie ook de vraagprognoses met veel modellennotitieblok voor een gedetailleerder voorbeeld.
Notitie
De vele modellen trainen en deductieonderdelen partitioneren uw gegevens voorwaardelijk op basis van de partition_column_names instelling, zodat elke partitie zich in een eigen bestand bevindt. Dit proces kan erg traag zijn of mislukken wanneer gegevens erg groot zijn. In dit geval raden we u aan uw gegevens handmatig te partitioneren voordat u veel modellen traint of deductie uitvoert.
Prognose op schaal: hiërarchische tijdreeks
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Met de hiërarchische tijdreeksonderdelen (HTS) in AutoML kunt u een groot aantal modellen trainen op gegevens met hiërarchische structuur. Zie de sectie HTS-artikel voor meer informatie.
HTS-trainingsconfiguratie
Het HTS-trainingsonderdeel accepteert een YAML-indelingsconfiguratiebestand van de AutoML-trainingsinstellingen. Het onderdeel past deze instellingen toe op elk AutoML-exemplaar dat wordt gestart. Dit YAML-bestand heeft dezelfde specificatie als de prognosetaak plus aanvullende parameters met betrekking tot de hiërarchiegegevens:
| Parameter | Description |
|---|---|
| hierarchy_column_names | Een lijst met kolomnamen in de gegevens die de hiërarchische structuur van de gegevens definiëren. De volgorde van de kolommen in deze lijst bepaalt de hiërarchieniveaus; de mate van aggregatie neemt af met de lijstindex. Dat wil gezegd, de laatste kolom in de lijst definieert het leaf-niveau (meest geaggregeerd) van de hiërarchie. |
| hierarchy_training_level | Het hiërarchieniveau dat moet worden gebruikt voor het trainen van prognosemodellen. |
Hieronder ziet u een voorbeeldconfiguratie:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
In volgende voorbeelden wordt ervan uitgegaan dat de configuratie wordt opgeslagen op het pad. ./automl_settings_hts.yml
HTS-pijplijn
Vervolgens definiëren we een factory-functie waarmee pijplijnen worden gemaakt voor het organiseren van HTS-training, deductie en metrische berekeningen. De parameters van deze fabrieksfunctie worden beschreven in de volgende tabel:
| Parameter | Description |
|---|---|
| forecast_level | Het niveau van de hiërarchie voor het ophalen van prognoses voor |
| allocation_method | Toewijzingsmethode die moet worden gebruikt wanneer prognoses worden uitgesplitst. Geldige waarden zijn "proportions_of_historical_average" en "average_historical_proportions". |
| max_nodes | Aantal rekenknooppunten dat moet worden gebruikt in de trainingstaak |
| max_concurrency_per_node | Het aantal AutoML-processen dat op elk knooppunt moet worden uitgevoerd. Daarom is max_nodes * max_concurrency_per_nodede totale gelijktijdigheid van een HTS-taak . |
| parallel_step_timeout_in_seconds | Veel time-outs voor modellenonderdelen die in het aantal seconden zijn opgegeven. |
| forecast_mode | Deductiemodus voor modelevaluatie. Geldige waarden zijn "recursive" en 'rolling'. Zie het artikel over modelevaluatie voor meer informatie. |
| forecast_step | Stapgrootte voor rolling prognose. Zie het artikel over modelevaluatie voor meer informatie. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Nu maken we de pijplijn via de fabrieksfunctie, ervan uitgaande dat de trainings- en testgegevens zich in lokale mappen ./data/train bevinden en ./data/test, respectievelijk. Ten slotte stellen we de standaard rekenkracht in en verzenden we de taak zoals in het volgende voorbeeld:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Nadat de taak is voltooid, kunnen de metrische evaluatiegegevens lokaal worden gedownload met behulp van dezelfde procedure als in de pijplijn voor één trainingsuitvoering.
Zie ook de vraagprognoses met een hiërarchisch tijdreeksnotitieblok voor een gedetailleerder voorbeeld.
Notitie
De HTS-trainings- en deductieonderdelen partitioneren uw gegevens voorwaardelijk volgens de hierarchy_column_names instelling, zodat elke partitie zich in een eigen bestand bevindt. Dit proces kan erg traag zijn of mislukken wanneer gegevens erg groot zijn. In dit geval raden we u aan uw gegevens handmatig te partitioneren voordat u HTS-training of -deductie uitvoert.
Prognose op schaal: gedistribueerde DNN-training
- Als u wilt weten hoe gedistribueerde training werkt voor prognosetaken, raadpleegt u ons artikel over prognose op schaal.
- Zie de sectie met gedistribueerde training voor tabellaire gegevens voor codevoorbeelden.
Voorbeeldnotebooks
Zie de notebooks met prognosevoorbeelden voor gedetailleerde codevoorbeelden van geavanceerde prognoseconfiguratie, waaronder:
- Voorbeelden van prognosepijplijnen voor vraag
- Deep Learning-modellen
- Vakantiedetectie en featurization
- Handmatige configuratie voor vertragings- en rolling windowaggregatiefuncties
Volgende stappen
- Meer informatie over het implementeren van een AutoML-model naar een online-eindpunt.
- Meer informatie over interpreteerbaarheid: modeluitleg in geautomatiseerde machine learning (preview).
- Meer informatie over hoe AutoML voorspellingsmodellen bouwt.
- Meer informatie over prognoses op schaal.
- Meer informatie over het configureren van AutoML voor verschillende prognosescenario's.
- Meer informatie over deductie en evaluatie van prognosemodellen.