Gegevensdrift detecteren (preview) op gegevenssets
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
Meer informatie over het bewaken van gegevensdrift en het instellen van waarschuwingen wanneer drift hoog is.
Notitie
Bewaking van Azure Machine Learning-modellen (v2) biedt verbeterde mogelijkheden voor gegevensdrift, samen met aanvullende functies voor het bewaken van signalen en metrische gegevens. Zie Modelbewaking met Azure Machine Learning voor meer informatie over de mogelijkheden van modelbewaking in Azure Machine Learning (v2).
Met azure Machine Learning-gegevenssetmonitors (preview) kunt u het volgende doen:
- Analyseer afwijkingen in uw gegevens om te begrijpen hoe deze in de loop van de tijd verandert.
- Modelgegevens controleren op verschillen tussen training en het leveren van gegevenssets. Begin met het verzamelen van modelgegevens van geïmplementeerde modellen.
- Bewaak nieuwe gegevens voor verschillen tussen een basislijn en doelgegevensset.
- Profielfuncties in gegevens om bij te houden hoe statistische eigenschappen in de loop van de tijd veranderen.
- Stel waarschuwingen in voor gegevensdrift voor vroege waarschuwingen bij potentiële problemen.
- Maak een nieuwe gegevenssetversie wanneer u vaststelt dat de gegevens te veel zijn afgelopen.
Er wordt een Azure Machine Learning-gegevensset gebruikt om de monitor te maken. De gegevensset moet een tijdstempelkolom bevatten.
U kunt metrische gegevensdrift bekijken met de Python SDK of in Azure Machine Learning-studio. Andere metrische gegevens en inzichten zijn beschikbaar via de Azure-toepassing Insights-resource die is gekoppeld aan de Azure Machine Learning-werkruimte.
Belangrijk
Detectie van gegevensdrift voor gegevenssets is momenteel beschikbaar als openbare preview. De preview-versie wordt aangeboden zonder Service Level Agreement en wordt niet aanbevolen voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Vereisten
Als u gegevenssetmonitoren wilt maken en ermee wilt werken, hebt u het volgende nodig:
- Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint. Probeer vandaag nog de gratis of betaalde versie van Azure Machine Learning.
- Een Azure Machine Learning-werkruimte.
- De Azure Machine Learning SDK voor Python is geïnstalleerd, waaronder het pakket azureml-datasets.
- Gestructureerde (tabellaire) gegevens met een tijdstempel die is opgegeven in het bestandspad, de bestandsnaam of de kolom in de gegevens.
Wat is gegevensdrift?
Modelnauwkeurigheid verslechtert in de loop van de tijd, grotendeels vanwege gegevensdrift. Voor machine learning-modellen is gegevensdrift de wijziging in modelinvoergegevens die leiden tot een verslechtering van de modelprestaties. Het bewaken van gegevensdrift helpt bij het detecteren van deze prestatieproblemen van het model.
Oorzaken van gegevensdrift zijn:
- Upstream proceswijzigingen, zoals een sensor die wordt vervangen, waardoor de maateenheden van inches in centimeters worden gewijzigd.
- Problemen met gegevenskwaliteit, zoals een defecte sensor, lezen altijd 0.
- Natuurlijke drift in de gegevens, zoals gemiddelde temperatuurwisseling met de seizoenen.
- Wijzigen in relatie tussen functies of covariate shift.
Azure Machine Learning vereenvoudigt de detectie van driften door één metrische gegevens te berekenen, waardoor de complexiteit van gegevenssets die worden vergeleken, wordt geabstraheerd. Deze gegevenssets hebben mogelijk honderden functies en tienduizenden rijen. Zodra drift is gedetecteerd, zoomt u in welke functies de drift veroorzaken. Vervolgens inspecteert u metrische gegevens op functieniveau om fouten op te sporen en de hoofdoorzaak voor de drift te isoleren.
Met deze top down-benadering kunt u eenvoudig gegevens bewaken in plaats van traditionele op regels gebaseerde technieken. Op regels gebaseerde technieken, zoals toegestaan gegevensbereik of toegestane unieke waarden, kunnen tijdrovend en foutgevoelig zijn.
In Azure Machine Learning gebruikt u gegevenssetmonitors om gegevensdrift te detecteren en te waarschuwen.
Bewaking van gegevenssets
Met een gegevenssetmonitor kunt u het volgende doen:
- Detecteren en waarschuwen voor gegevensdrift op nieuwe gegevens in een gegevensset.
- Analyseer historische gegevens voor drift.
- Profileer nieuwe gegevens in de loop van de tijd.
Het algoritme voor gegevensdrift biedt een algemene meting van wijzigingen in gegevens en geeft aan welke functies verantwoordelijk zijn voor verder onderzoek. Gegevenssetmonitoren produceren veel andere metrische gegevens door nieuwe gegevens in de timeseries gegevensset te profileren.
Aangepaste waarschuwingen kunnen worden ingesteld voor alle metrische gegevens die door de monitor worden gegenereerd via Azure-toepassing Insights. Gegevenssetmonitors kunnen worden gebruikt om snel gegevensproblemen op te vangen en de tijd te verkorten om het probleem op te sporen door waarschijnlijke oorzaken te identificeren.
Conceptueel gezien zijn er drie primaire scenario's voor het instellen van gegevenssetmonitors in Azure Machine Learning.
| Scenario | Beschrijving |
|---|---|
| De dienstgegevens van een model controleren op afwijking van de trainingsgegevens | Resultaten van dit scenario kunnen worden geïnterpreteerd als het bewaken van een proxy voor de nauwkeurigheid van het model, omdat de nauwkeurigheid van het model verslechtert wanneer de servergegevens van de trainingsgegevens afdrijven. |
| Bewaak een tijdreeksgegevensset voor afwijking van een eerdere periode. | Dit scenario is algemener en kan worden gebruikt voor het bewaken van gegevenssets die betrekking hebben op upstream of downstream van het bouwen van modellen. De doelgegevensset moet een tijdstempelkolom hebben. De basislijngegevensset kan elke tabellaire gegevensset zijn met functies die gemeenschappelijk zijn met de doelgegevensset. |
| Voer analyses uit op eerdere gegevens. | Dit scenario kan worden gebruikt om historische gegevens te begrijpen en beslissingen te nemen in instellingen voor gegevenssetmonitors. |
Gegevenssetmonitoren zijn afhankelijk van de volgende Azure-services.
| Azure-service | Beschrijving |
|---|---|
| Gegevensset | Drift maakt gebruik van Machine Learning-gegevenssets om trainingsgegevens op te halen en gegevens te vergelijken voor modeltraining. Het genereren van een profiel van gegevens wordt gebruikt om enkele van de gerapporteerde metrische gegevens te genereren, zoals min, max, afzonderlijke waarden, aantal afzonderlijke waarden. |
| Azure Machine Learning-pijplijn en -berekening | De driftberekeningstaak wordt gehost in een Azure Machine Learning-pijplijn. De taak wordt op aanvraag geactiveerd of volgens planning uitgevoerd op een rekenproces dat is geconfigureerd tijdens het maken van driftmonitors. |
| Application insights | Drift verzendt metrische gegevens naar Application Insights die behoren tot de machine learning-werkruimte. |
| Azure Blob Storage | Drift verzendt metrische gegevens in json-indeling naar Azure Blob Storage. |
Basislijn- en doelgegevenssets
U bewaakt Azure Machine Learning-gegevenssets voor gegevensdrift. Wanneer u een gegevenssetmonitor maakt, verwijst u naar het volgende:
- Basislijngegevensset: meestal de trainingsgegevensset voor een model.
- Doelgegevensset, meestal modelinvoergegevens, wordt in de loop van de tijd vergeleken met uw basislijngegevensset. Deze vergelijking betekent dat uw doelgegevensset een tijdstempelkolom moet hebben opgegeven.
De monitor vergelijkt de basislijn- en doelgegevenssets.
Doelgegevensset maken
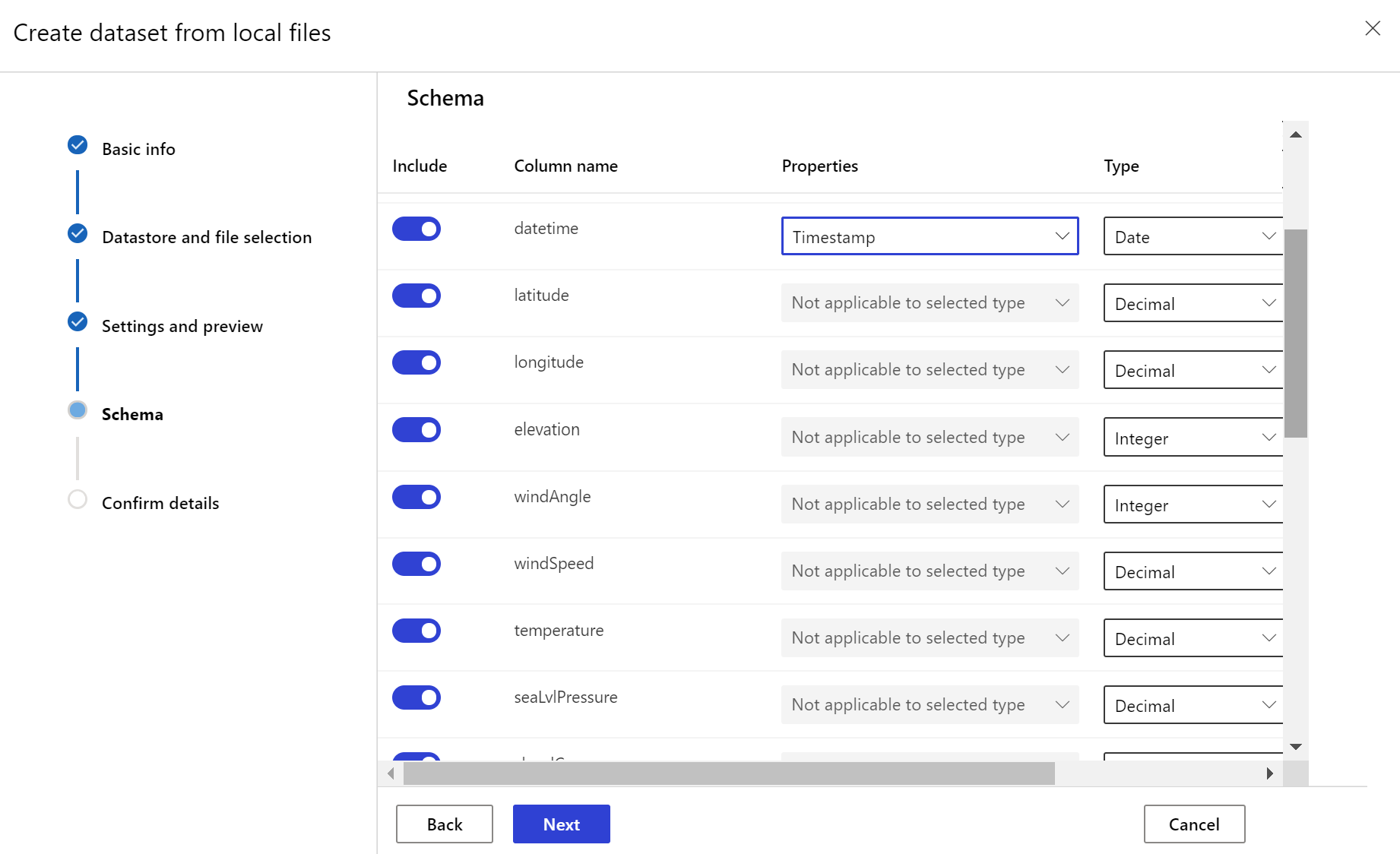
De doelgegevensset heeft de timeseries eigenschappen nodig die erop zijn ingesteld door de tijdstempelkolom op te geven uit een kolom in de gegevens of een virtuele kolom die is afgeleid van het padpatroon van de bestanden. Maak de gegevensset met een tijdstempel via de Python SDK of Azure Machine Learning-studio. Een kolom die een tijdstempel aangeeft, moet worden opgegeven om eigenschappen toe te voegen timeseries aan de gegevensset. Als uw gegevens zijn gepartitioneerd in mapstructuur met tijdsgegevens, zoals {jjjj/MM/dd}, maakt u een virtuele kolom via de padpatrooninstelling en stelt u deze in als de tijdstempel voor partities om de functionaliteit van de tijdreeks-API in te schakelen.
VAN TOEPASSING OP: Python SDK azureml v1
De Dataset klassemethode with_timestamp_columns() definieert de tijdstempelkolom voor de gegevensset.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Tip
Zie het voorbeeldnotebook of de SDK-documentatie voor gegevenssets voor een volledig voorbeeld van het gebruik van de timeseries eigenschappen van gegevenssets.

Gegevenssetmonitor maken
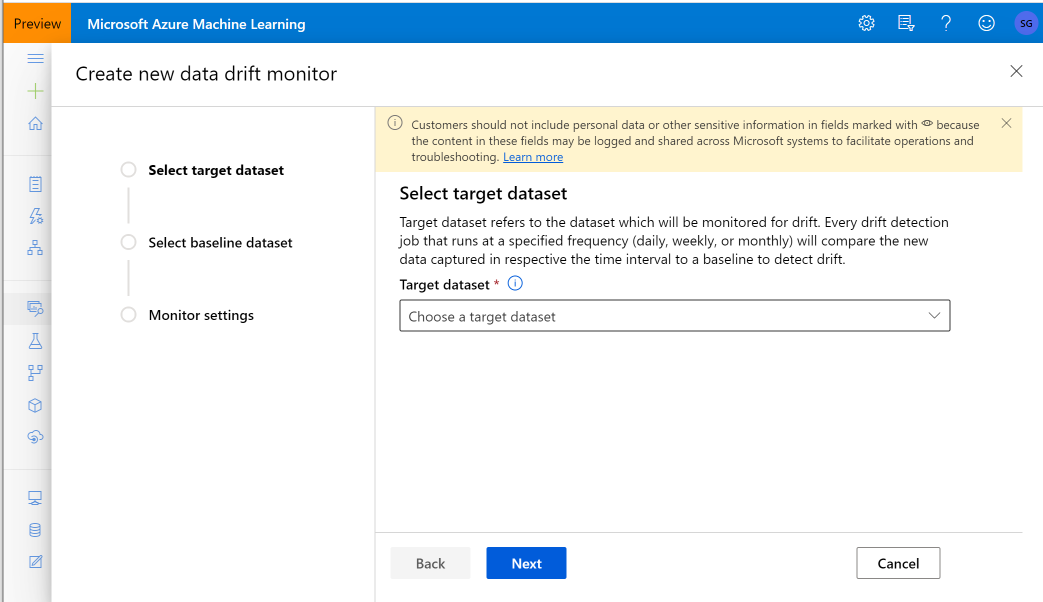
Maak een gegevenssetmonitor om gegevensdrift op een nieuwe gegevensset te detecteren en te waarschuwen. Gebruik de Python SDK of Azure Machine Learning-studio.
Zoals later beschreven, wordt een gegevenssetmonitor uitgevoerd met een ingestelde frequentie (dagelijks, wekelijks, maandelijks). Het analyseert nieuwe gegevens die beschikbaar zijn in de doelgegevensset sinds de laatste uitvoering. In sommige gevallen volstaat een dergelijke analyse van de meest recente gegevens mogelijk niet:
- De nieuwe gegevens uit de upstream-bron zijn vertraagd vanwege een verbroken gegevenspijplijn en deze nieuwe gegevens zijn niet beschikbaar toen de gegevenssetmonitor werd uitgevoerd.
- Een tijdreeksgegevensset had alleen historische gegevens en u wilt driftpatronen in de gegevensset in de loop van de tijd analyseren. Bijvoorbeeld: vergelijk verkeer dat stroomt naar een website, in zowel winter- als zomerseizoenen, om seizoenspatronen te identificeren.
- U bent nog niet eerder in gegevenssetmonitors. U wilt evalueren hoe de functie met uw bestaande gegevens werkt voordat u deze instelt om toekomstige dagen te bewaken. In dergelijke scenario's kunt u een uitvoering op aanvraag indienen, met een specifiek datumbereik voor de doelgegevensset, om te vergelijken met de basislijngegevensset.
Met de functie backfill wordt een backfilltaak uitgevoerd voor een opgegeven begin- en einddatumbereik. Een backfilltaak vult verwachte ontbrekende gegevenspunten in een gegevensset in als een manier om de nauwkeurigheid en volledigheid van de gegevens te waarborgen.
VAN TOEPASSING OP: Python SDK azureml v1
Raadpleeg de python SDK-referentiedocumentatie over gegevensdrift voor volledige details.
In het volgende voorbeeld ziet u hoe u een gegevenssetmonitor maakt met behulp van de Python SDK
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Tip
Zie ons voorbeeldnotebook voor een volledig voorbeeld van het instellen van een timeseries gegevensset en gegevensdriftdetector.
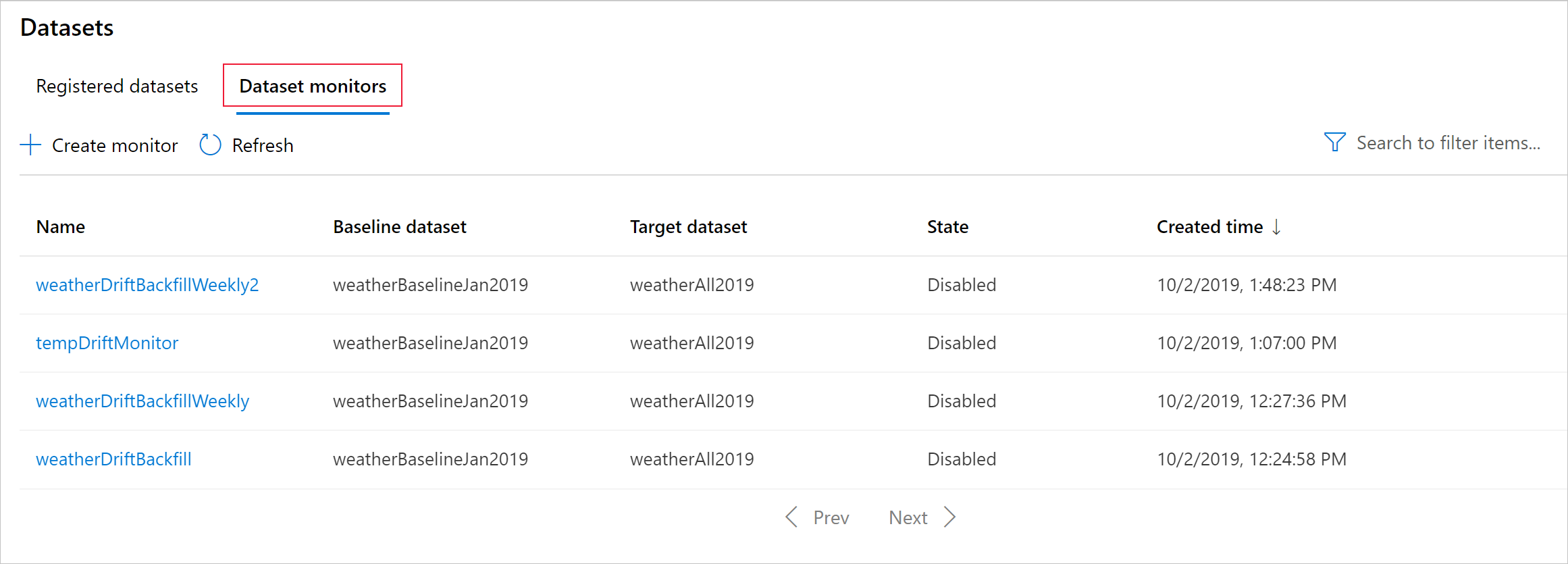
Inzicht in gegevensdriftresultaten
In deze sectie ziet u de resultaten van het bewaken van een gegevensset, te vinden op de pagina Datasets / Dataset monitors in Azure Studio. U kunt de instellingen bijwerken en bestaande gegevens analyseren voor een specifieke periode op deze pagina.
Begin met de inzichten op het hoogste niveau in de omvang van gegevensdrift en een markering van functies die verder moeten worden onderzocht.
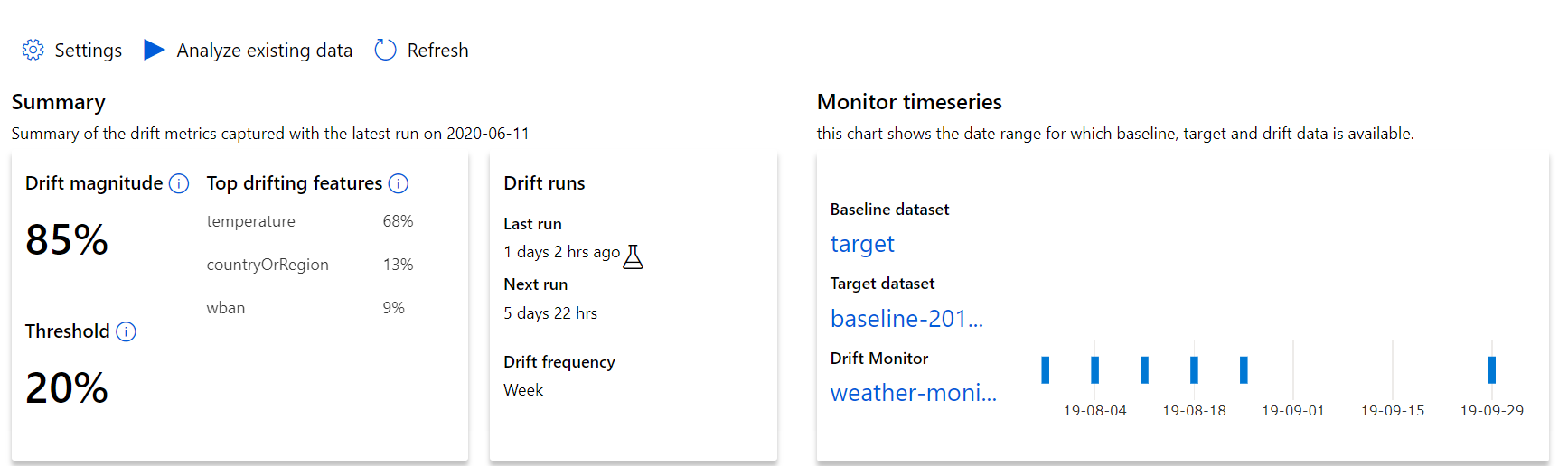
| Metrisch | Beschrijving |
|---|---|
| Grootte van gegevensdrift | Een percentage afwijkingen tussen de basislijn en de doelgegevensset in de loop van de tijd. Dit percentage varieert van 0 tot 100, 0 geeft identieke gegevenssets aan en 100 geeft aan dat het Azure Machine Learning-gegevensdriftmodel de twee gegevenssets volledig kan onderscheiden. Ruis in het exacte percentage dat wordt gemeten, wordt verwacht omdat machine learning-technieken worden gebruikt om deze grootte te genereren. |
| Belangrijkste driftfuncties | Toont de functies van de gegevensset die het meeste hebben gedrift en die daarom het meeste bijdragen aan de metrische waarde Drift Magnitude. Vanwege covariatieverschuiving hoeft de onderliggende verdeling van een functie niet noodzakelijkerwijs te veranderen om relatief hoge functiebelang te hebben. |
| Threshold | Gegevensdriftgrootte buiten de ingestelde drempelwaarde activeert waarschuwingen. Configureer de drempelwaarde in de monitorinstellingen. |
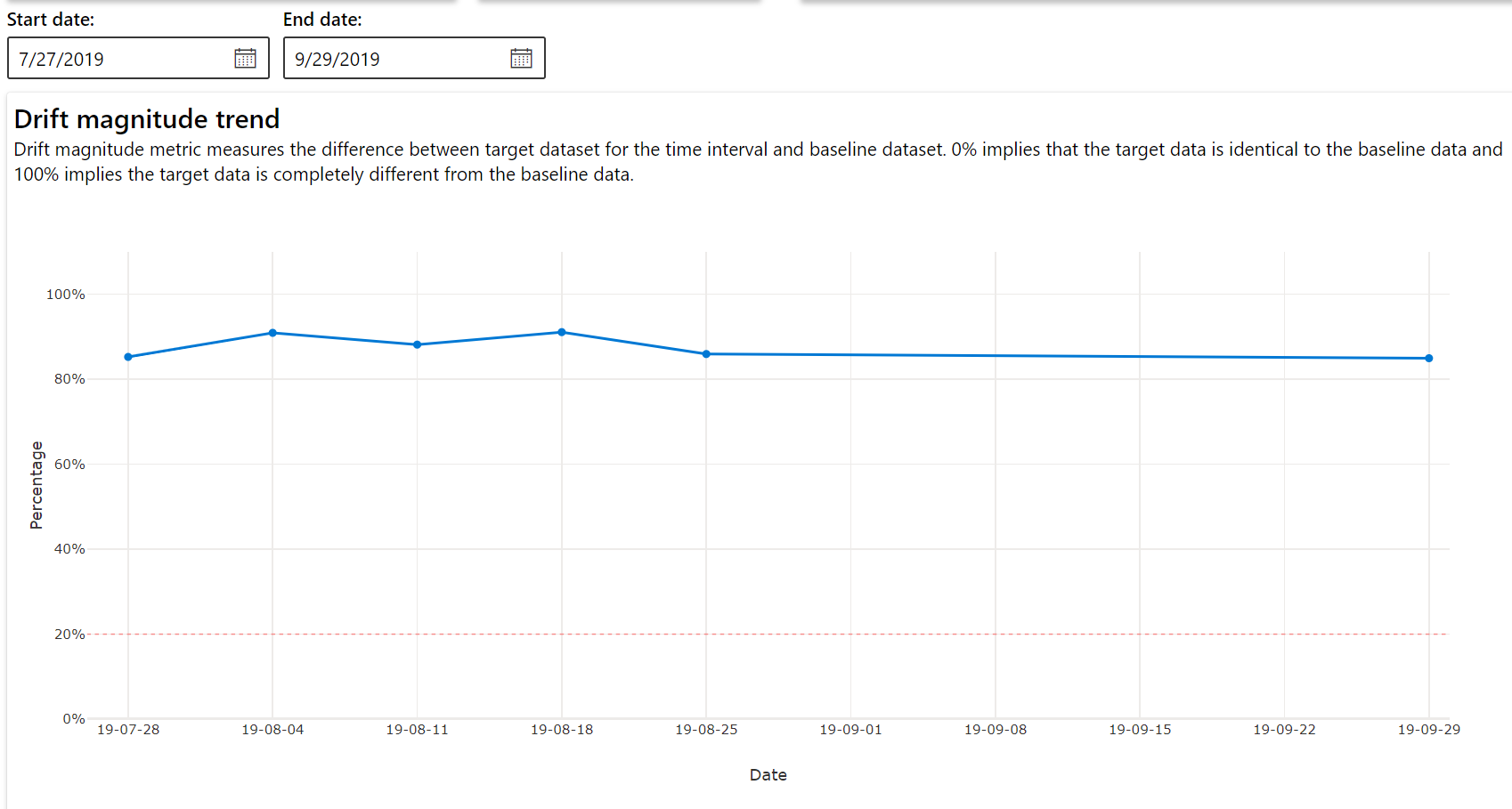
Trend van afwijkingsgrootheid
Bekijk hoe de gegevensset verschilt van de doelgegevensset in de opgegeven periode. Hoe dichter bij 100%, hoe meer de twee gegevenssets verschillen.
Afwijkingsgrootheid per kenmerken
Deze sectie bevat inzichten op functieniveau in de wijziging in de distributie van de geselecteerde functie en andere statistieken in de loop van de tijd.
De doelgegevensset wordt ook geprofileerd in de loop van de tijd. De statistische afstand tussen de basislijnverdeling van elke functie wordt vergeleken met de doelgegevenssets in de loop van de tijd. Conceptueel lijkt dit op de grootte van de gegevensdrift. Deze statistische afstand is echter voor een afzonderlijke functie in plaats van alle functies. Min, max en gemiddelde zijn ook beschikbaar.
Selecteer in de Azure Machine Learning-studio een balk in de grafiek om de details op functieniveau voor die datum weer te geven. Standaard ziet u de distributie van de basislijngegevensset en de meest recente taakverdeling van dezelfde functie.
Deze metrische gegevens kunnen ook worden opgehaald in de Python SDK via de get_metrics() methode voor een DataDriftDetector object.
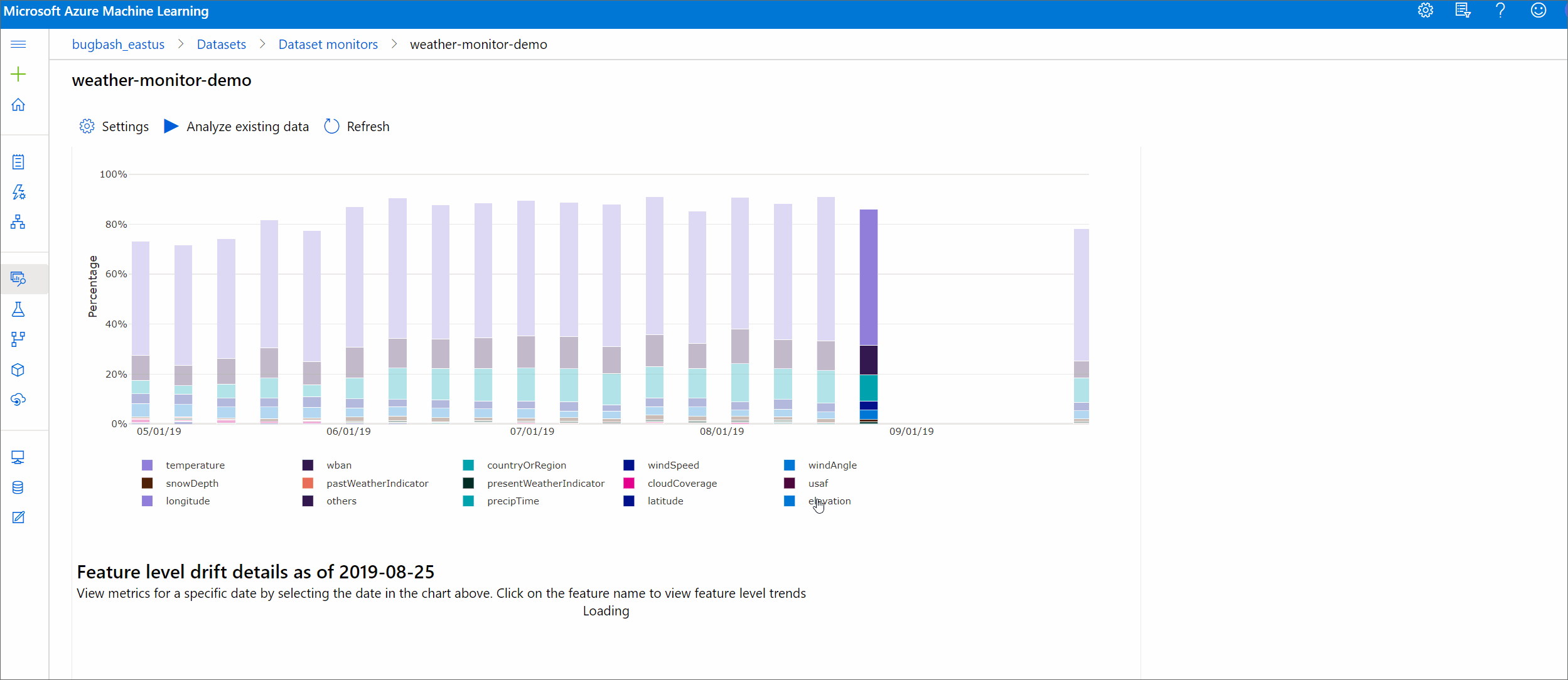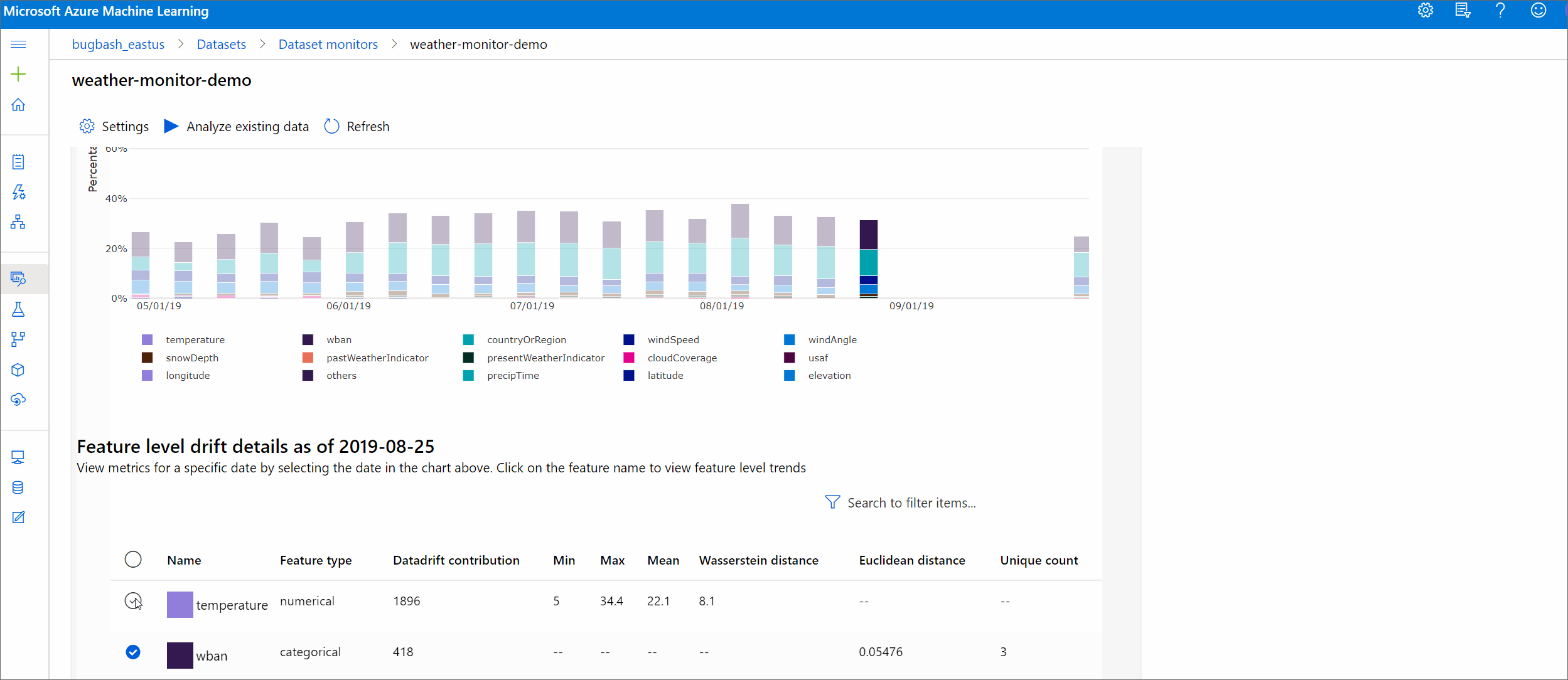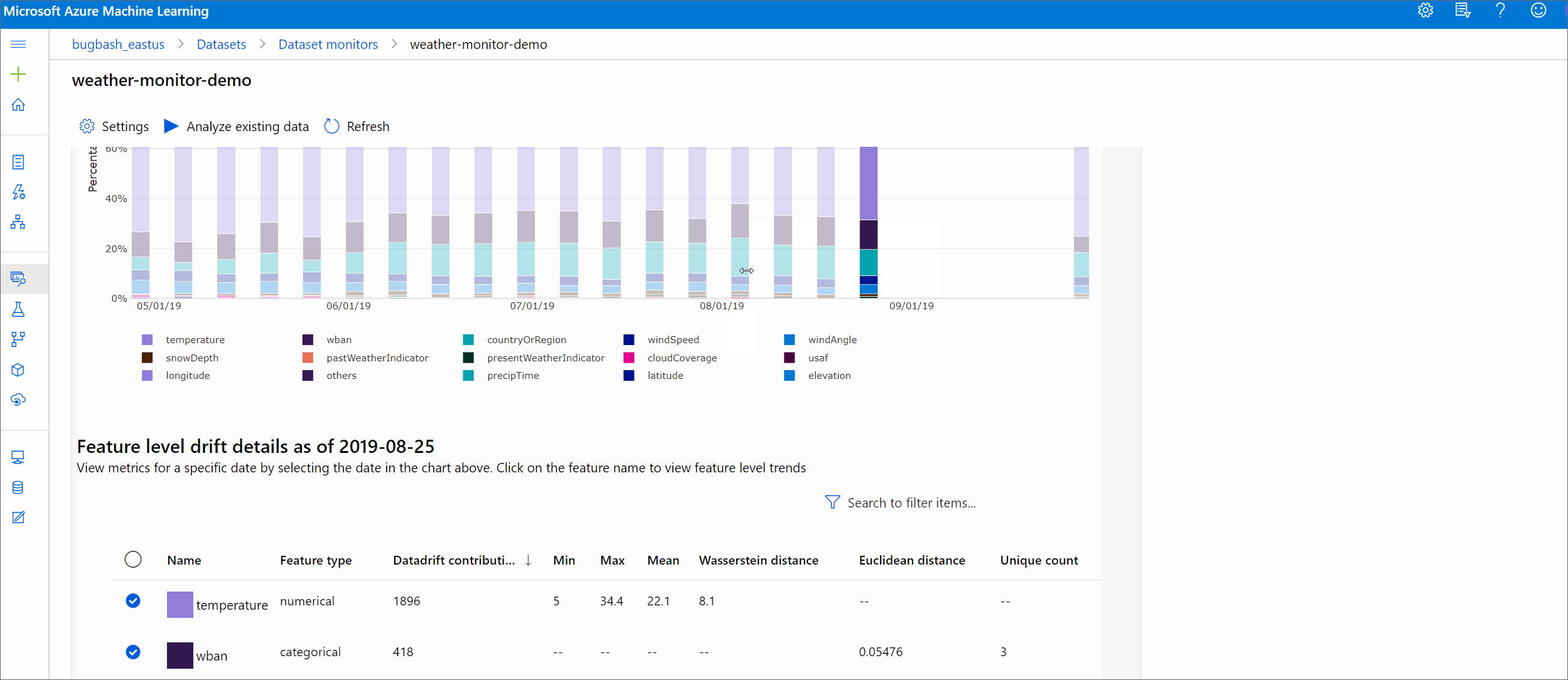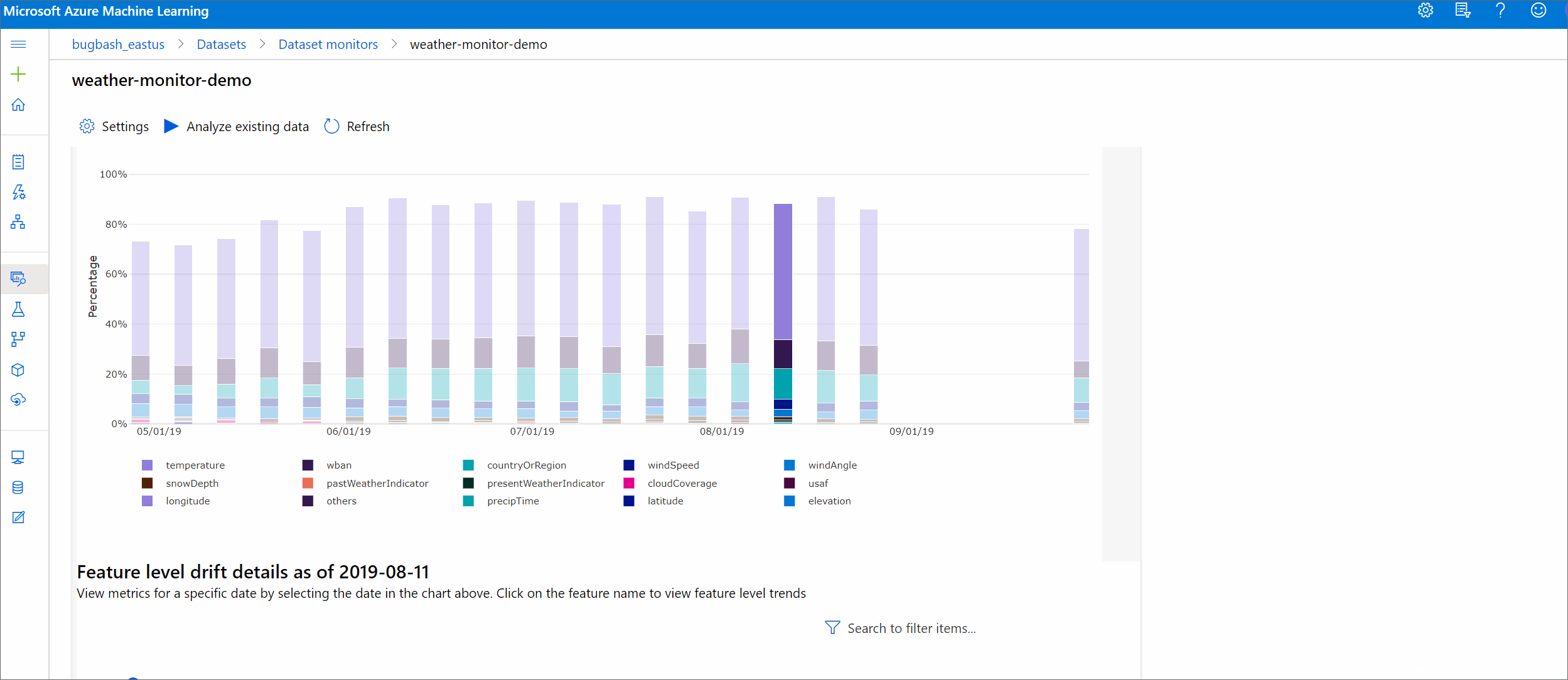
Functiedetails
Schuif tot slot omlaag om details voor elke afzonderlijke functie weer te geven. Gebruik de vervolgkeuzelijsten boven de grafiek om de functie te selecteren en selecteer daarnaast de metrische waarde die u wilt weergeven.
Metrische gegevens in de grafiek zijn afhankelijk van het type functie.
Numerieke functies
Metrisch Beschrijving Wasserstein afstand Minimale hoeveelheid werk om basislijndistributie om te zetten in de doeldistributie. Gemiddelde waarde De gemiddelde waarde van de functie. Minimumwaarde Minimale waarde van de functie. Maximumwaarde Maximumwaarde van de functie. Categorische functies
Metrisch Beschrijving Euclidische afstand Berekend voor categorische kolommen. De euclidische afstand wordt berekend op twee vectoren, gegenereerd op basis van empirische verdeling van dezelfde categorische kolom uit twee gegevenssets. 0 geeft geen verschil aan in de empirische verdelingen. Hoe meer het afwijkt van 0, hoe meer deze kolom is afgelopen. Trends kunnen worden waargenomen vanuit een tijdreekstekening van deze metrische gegevens en kunnen handig zijn bij het ontdekken van een zwevende functie. Unieke waarden Aantal unieke waarden (kardinaliteit) van de functie.
Selecteer in deze grafiek één datum om de functieverdeling tussen het doel en deze datum voor de weergegeven functie te vergelijken. Voor numerieke functies ziet u twee waarschijnlijkheidsverdelingen. Als de functie numeriek is, wordt er een staafdiagram weergegeven.
Metrische gegevens, waarschuwingen en gebeurtenissen
Metrische gegevens kunnen worden opgevraagd in de Azure-toepassing Insights-resource die is gekoppeld aan uw machine learning-werkruimte. U hebt toegang tot alle functies van Application Insights, waaronder het instellen voor aangepaste waarschuwingsregels en actiegroepen om een actie te activeren, zoals een e-mail/sms/push/spraak- of Azure-functie. Raadpleeg de volledige Application Insights-documentatie voor meer informatie.
Om aan de slag te gaan, gaat u naar Azure Portal en selecteert u de overzichtspagina van uw werkruimte. De bijbehorende Application Insights-resource bevindt zich uiterst rechts:

Selecteer Logboeken (Analyse) onder Bewaking in het linkerdeelvenster:
De metrische gegevenssetmonitor worden opgeslagen als customMetrics. U kunt een query schrijven en uitvoeren nadat u een gegevenssetmonitor hebt ingesteld om ze weer te geven:

Nadat u metrische gegevens hebt geïdentificeerd om waarschuwingsregels in te stellen, maakt u een nieuwe waarschuwingsregel:
U kunt een bestaande actiegroep gebruiken of een nieuwe groep maken om de actie te definiëren die moet worden uitgevoerd wanneer aan de ingestelde voorwaarden wordt voldaan:
Probleemoplossing
Beperkingen en bekende problemen voor monitors voor gegevensdrift:
Het tijdsbereik bij het analyseren van historische gegevens is beperkt tot 31 intervallen van de frequentie-instelling van de monitor.
Beperking van 200 functies, tenzij er geen functielijst is opgegeven (alle gebruikte functies).
De rekenkracht moet groot genoeg zijn om de gegevens te verwerken.
Zorg ervoor dat uw gegevensset gegevens bevat binnen de begin- en einddatum voor een bepaalde monitortaak.
Gegevensset bewaakt alleen op gegevenssets die 50 rijen of meer bevatten.
Kolommen of functies in de gegevensset worden geclassificeerd als categorisch of numeriek op basis van de voorwaarden in de volgende tabel. Als de functie niet aan deze voorwaarden voldoet, bijvoorbeeld een kolom van het type tekenreeks met >100 unieke waarden, wordt de functie verwijderd uit ons algoritme voor gegevensdrift, maar wordt deze nog steeds geprofileerd.
Functietype Gegevenstype Conditie Beperkingen Categorische gegevens tekenreeks Het aantal unieke waarden in de functie is kleiner dan 100 en kleiner dan 5% van het aantal rijen. Null wordt beschouwd als een eigen categorie. Numeriek int, float De waarden in de functie zijn van een numeriek gegevenstype en voldoen niet aan de voorwaarde voor een categorische functie. De functie is verwijderd als >15% van de waarden null is. Wanneer u een gegevensdriftmonitor hebt gemaakt, maar geen gegevens kunt zien op de pagina Gegevenssetmonitoren in Azure Machine Learning-studio, kunt u het volgende proberen.
- Controleer of u het juiste datumbereik boven aan de pagina hebt geselecteerd.
- Selecteer op het tabblad Gegevenssetmonitoren de koppeling naar het experiment om de taakstatus te controleren. Deze koppeling bevindt zich uiterst rechts van de tabel.
- Als de taak is voltooid, controleert u de logboeken van het stuurprogramma om te zien hoeveel metrische gegevens zijn gegenereerd of als er waarschuwingsberichten zijn. Zoek stuurprogrammalogboeken op het tabblad Uitvoer en logboeken nadat u een experiment hebt geselecteerd.
Als de SDK-functie
backfill()de verwachte uitvoer niet genereert, kan dit worden veroorzaakt door een verificatieprobleem. Wanneer u de berekening maakt die in deze functie moet worden doorgegeven, gebruikt u dit nietRun.get_context().experiment.workspace.compute_targets. Gebruik in plaats daarvan ServicePrincipalAuthentication , zoals het volgende om de rekenkracht te maken die u doorgeeft aan diebackfill()functie:auth = ServicePrincipalAuthentication( tenant_id=tenant_id, service_principal_id=app_id, service_principal_password=client_secret ) ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx") compute = ws.compute_targets.get("xxx")Vanuit de modelgegevensverzamelaar kan het tot 10 minuten duren voordat gegevens binnenkomen in uw blobopslagaccount. Het duurt echter meestal minder tijd. Wacht 10 minuten in een script of notebook om ervoor te zorgen dat de onderstaande cellen correct worden uitgevoerd.
import time time.sleep(600)
Volgende stappen
- Ga naar de Azure Machine Learning-studio of het Python-notebook om een gegevenssetmonitor in te stellen.
- Zie hoe u gegevensdrift instelt op modellen die zijn geïmplementeerd in Azure Kubernetes Service.
- Stel driftmonitors voor gegevenssets in met Azure Event Grid.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor