Een verantwoorde AI-inzichten genereren in de gebruikersinterface van Studio
In dit artikel maakt u een verantwoordelijk AI-dashboard en -scorecard (preview) met een ervaring zonder code in de gebruikersinterface van Azure Machine Learning-studio.
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Ga als volgt te werk om toegang te krijgen tot de wizard voor het genereren van dashboards en om een verantwoordelijk AI-dashboard te genereren:
Registreer uw model in Azure Machine Learning, zodat u toegang hebt tot de ervaring zonder code.
Selecteer in het linkerdeelvenster van Azure Machine Learning-studio het tabblad Modellen.
Selecteer het geregistreerde model waarvoor u verantwoorde AI-inzichten wilt maken en selecteer vervolgens het tabblad Details .
Selecteer Een verantwoordelijk AI-dashboard maken (preview).


Zie ondersteunde scenario's en beperkingen voor meer informatie over ondersteunde modeltypen en -beperkingen in het dashboard voor verantwoorde AI.
De wizard biedt een interface voor het invoeren van alle benodigde parameters om uw Responsible AI-dashboard te maken zonder code aan te raken. De ervaring vindt volledig plaats in de gebruikersinterface van Azure Machine Learning-studio. De studio presenteert een begeleide stroom en instructietekst om de verscheidenheid aan keuzes te contexteren over de verantwoordelijke AI-onderdelen waarmee u uw dashboard wilt vullen.
De wizard is onderverdeeld in vijf secties:
- Trainingsgegevenssets
- Gegevensset testen
- Modelleringstaak
- Dashboardonderdelen
- Onderdeelparameters
- Experimentconfiguratie
Uw gegevenssets selecteren
In de eerste twee secties selecteert u de gegevenssets trainen en testen die u hebt gebruikt bij het trainen van uw model om inzichten voor modelopsporing te genereren. Voor onderdelen zoals causale analyse, waarvoor geen model vereist is, gebruikt u de gegevensset trainen om het causale model te trainen om de causale inzichten te genereren.
Notitie
Alleen tabellaire gegevenssetindelingen in ML-tabel worden ondersteund.
Selecteer een gegevensset voor training: Selecteer in de lijst met geregistreerde gegevenssets in de Azure Machine Learning-werkruimte de gegevensset die u wilt gebruiken om verantwoorde AI-inzichten te genereren voor onderdelen, zoals modeluitleg en foutanalyse.
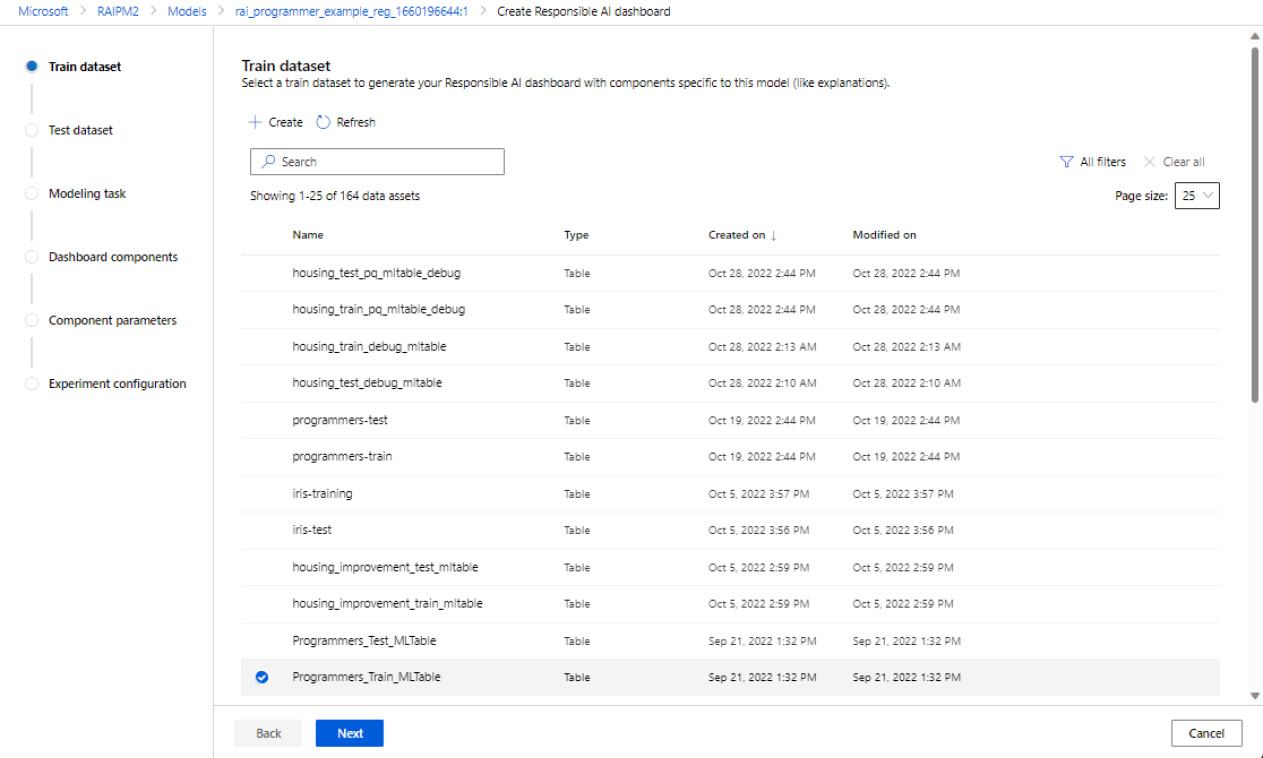
Selecteer een gegevensset voor testen: selecteer in de lijst met geregistreerde gegevenssets de gegevensset die u wilt gebruiken om uw verantwoordelijke AI-dashboardvisualisaties te vullen.

Als de gegevensset trainen of testen die u wilt gebruiken niet wordt vermeld, selecteert u Maken om deze te uploaden.


Uw modelleringstaak selecteren
Nadat u uw gegevenssets hebt gekozen, selecteert u het type modelleringstaak, zoals wordt weergegeven in de volgende afbeelding:

Uw dashboardonderdelen selecteren
Het dashboard Responsible AI biedt twee profielen voor aanbevolen sets hulpprogramma's die u kunt genereren:
Foutopsporing van modellen: foutieve gegevenscohorten in uw Machine Learning-model begrijpen en fouten opsporen met behulp van foutanalyse, contrafactuele wat-als-voorbeelden en modeluitlegbaarheid.
Echte interventies: foutieve gegevenscohorten in uw machine learning-model begrijpen en fouten opsporen met behulp van causale analyse.
Notitie
Classificatie van meerdere klassen biedt geen ondersteuning voor het analyseprofiel voor real-life interventies.

- Selecteer het profiel dat u wilt gebruiken.
- Selecteer Volgende.
Parameters configureren voor dashboardonderdelen
Nadat u een profiel hebt geselecteerd, worden de onderdeelparameters voor het configuratievenster voor modelopsporing voor de bijbehorende onderdelen weergegeven.

Onderdeelparameters voor modelopsporing:
Doelfunctie (vereist): geef de functie op die uw model is getraind om te voorspellen.
Categorische functies: Geef aan welke functies categorisch zijn om ze correct weer te geven als categorische waarden in de gebruikersinterface van het dashboard. Dit veld wordt vooraf geladen op basis van de metagegevens van uw gegevensset.
Foutstructuur en heatmap genereren: In- en uitschakelen om een onderdeel voor foutanalyse te genereren voor uw verantwoordelijke AI-dashboard.
Functies voor heatmap voor fouten: selecteer maximaal twee functies waarvoor u een fout-heatmap wilt genereren.
Geavanceerde configuratie: geef aanvullende parameters op, zoals maximale diepte van foutstructuur, aantal bladeren in foutstructuur en minimum aantal steekproeven in elk leaf-knooppunt.
Counterfactual what-if-voorbeelden genereren: In- en uitschakelen om een contrafactueel what-if-onderdeel te genereren voor uw verantwoordelijke AI-dashboard.
Aantal contrafactuals (vereist): geef het aantal contrafactuele voorbeelden op dat u per gegevenspunt wilt genereren. Er moeten minimaal 10 worden gegenereerd om een staafdiagramweergave in te schakelen van de functies die gemiddeld het meest verstoord waren om de gewenste voorspelling te bereiken.
Bereik van waardevoorspellingen (vereist): geef op voor regressiescenario's het bereik waarin u de voorspellingswaarden wilt opnemen. Voor binaire classificatiescenario's wordt het bereik automatisch ingesteld om contrafactuals te genereren voor de tegenovergestelde klasse van elk gegevenspunt. Voor scenario's met meerdere classificaties gebruikt u de vervolgkeuzelijst om op te geven welke klasse u wilt dat elk gegevenspunt wordt voorspeld als.
Geef op welke functies u wilt verstoren: standaard worden alle functies verstoord. Als u echter alleen specifieke functies wilt verstoren, selecteert u Opgeven welke functies u wilt verstoren voor het genereren van contrafactuele uitleg om een deelvenster weer te geven met een lijst met functies die u wilt selecteren.
Wanneer u Opgeven selecteert in welke functies u wilt verstoren, kunt u het bereik opgeven waarin u turbaties wilt toestaan. Bijvoorbeeld: voor de functie YOE (jaren ervaring) geeft u op dat contrafactuals functiewaarden moeten hebben van slechts 10 tot 21 in plaats van de standaardwaarden van 5 tot 21.

Uitleg genereren: in- en uitschakelen om een modeluitlegonderdeel te genereren voor uw verantwoordelijke AI-dashboard. Er is geen configuratie nodig, omdat een standaard ondoorzichtige box-uitleg wordt gebruikt om functiebelangen te genereren.

Als u ook het real-life interventieprofiel selecteert, ziet u dat in het volgende scherm een causale analyse wordt gegenereerd. Dit helpt u inzicht te krijgen in de causale effecten van functies die u wilt 'behandelen' op een bepaald resultaat dat u wilt optimaliseren.

Componentparameters voor real-life interventies maken gebruik van causale analyse. Ga als volgt te werk:
- Doelfunctie (vereist): kies het resultaat waarvoor de causale effecten moeten worden berekend.
- Behandelfuncties (vereist): kies een of meer functies die u wilt wijzigen ('behandelen') om het doelresultaat te optimaliseren.
- Categorische functies: Geef aan welke functies categorisch zijn om ze correct weer te geven als categorische waarden in de gebruikersinterface van het dashboard. Dit veld wordt vooraf geladen op basis van de metagegevens van uw gegevensset.
- Geavanceerde instellingen: geef aanvullende parameters op voor uw causale analyse, zoals heterogene functies (dat wil weten over causale segmentatie in uw analyse, naast uw behandelingsfuncties) en welk causaal model u wilt gebruiken.
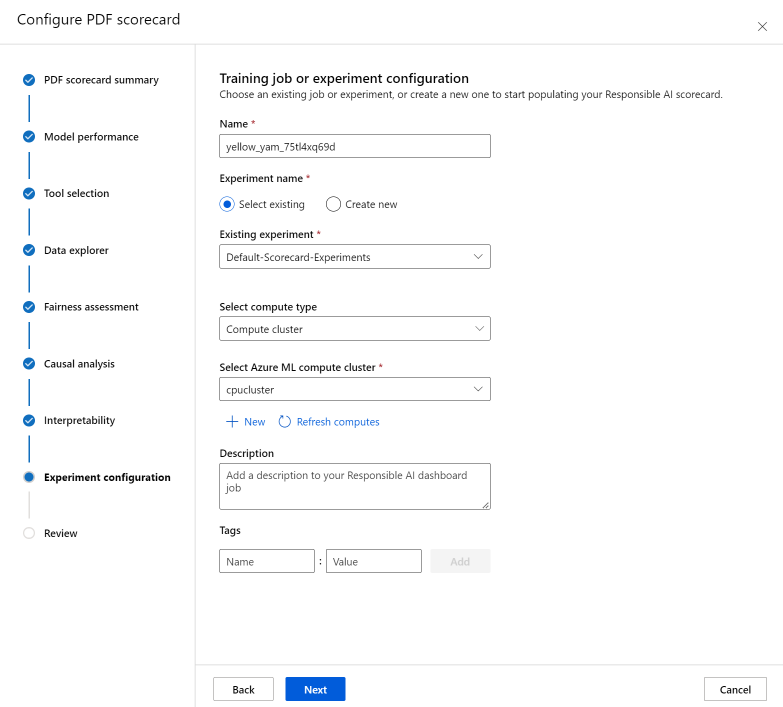
Uw experiment configureren
Ten slotte configureert u uw experiment om een taak te starten om uw verantwoordelijke AI-dashboard te genereren.

Ga als volgt te werk in het deelvenster Trainingstaak of Experimentconfiguratie :
- Naam: Geef uw dashboard een unieke naam, zodat u deze kunt onderscheiden wanneer u de lijst met dashboards voor een bepaald model bekijkt.
- Experimentnaam: selecteer een bestaand experiment waarin u de taak wilt uitvoeren of maak een nieuw experiment.
- Bestaand experiment: Selecteer een bestaand experiment in de vervolgkeuzelijst.
- Selecteer het rekentype: geef op welk rekentype u wilt gebruiken om uw taak uit te voeren.
- Selecteer compute: Selecteer in de vervolgkeuzelijst de berekening die u wilt gebruiken. Als er geen bestaande rekenresources zijn, selecteert u het plusteken (+), maakt u een nieuwe rekenresource en vernieuwt u de lijst.
- Beschrijving: Voeg een langere beschrijving toe van uw verantwoordelijke AI-dashboard.
- Tags: Voeg tags toe aan dit verantwoordelijke AI-dashboard.
Nadat u klaar bent met het configureren van uw experiment, selecteert u Maken om te beginnen met het genereren van uw verantwoordelijke AI-dashboard. U wordt omgeleid naar de experimentpagina om de voortgang van uw taak bij te houden met een koppeling naar het resulterende Responsible AI-dashboard vanaf de taakpagina wanneer deze is voltooid.
Als u wilt weten hoe u uw verantwoordelijke AI-dashboard kunt bekijken en gebruiken, gebruikt u het dashboard voor verantwoorde AI in Azure Machine Learning-studio.
Verantwoordelijke AI-scorecard genereren (preview)
Zodra u een dashboard hebt gemaakt, kunt u een gebruikersinterface zonder code gebruiken in Azure Machine Learning-studio om een verantwoordelijke AI-scorecard aan te passen en te genereren. Hiermee kunt u belangrijke inzichten delen voor een verantwoorde implementatie van uw model, zoals billijkheid en functiebelang, met niet-technische en technische belanghebbenden. Net als bij het maken van een dashboard kunt u de volgende stappen gebruiken om toegang te krijgen tot de wizard scorecardgeneratie:
- Navigeer naar het tabblad Modellen in de linkernavigatiebalk in Azure Machine Learning-studio.
- Selecteer het geregistreerde model waarvoor u een scorecard wilt maken en selecteer het tabblad Verantwoorde AI .
- Selecteer in het bovenste deelvenster Verantwoorde AI-inzichten maken (preview) en genereer vervolgens een nieuwe PDF-scorecard.
Met de wizard kunt u uw PDF-scorecard aanpassen zonder dat u code hoeft aan te raken. De ervaring vindt volledig plaats in de Azure Machine Learning-studio om de verscheidenheid aan keuzes van de gebruikersinterface te contextualiseren met een begeleide stroom en instructietekst om u te helpen bij het kiezen van de onderdelen waarmee u uw scorecard wilt vullen. De wizard is onderverdeeld in zeven stappen, met een achtste stap (fairness assessment) die alleen wordt weergegeven voor modellen met categorische functies:
- SAMENVATTING VAN PDF-scorecard
- Modelprestaties
- Selectie van gereedschap
- Gegevensanalyse (voorheen Data Explorer genoemd)
- Causale analyse
- Interpreteerbaarheid
- Experimentconfiguratie
- Beoordeling van redelijkheid (alleen als categorische functies bestaan)
Uw scorecard configureren
Voer eerst een beschrijvende titel in voor uw scorecard. U kunt ook een optionele beschrijving invoeren over de functionaliteit van het model, gegevens waarop het is getraind en geëvalueerd, architectuurtype en meer.
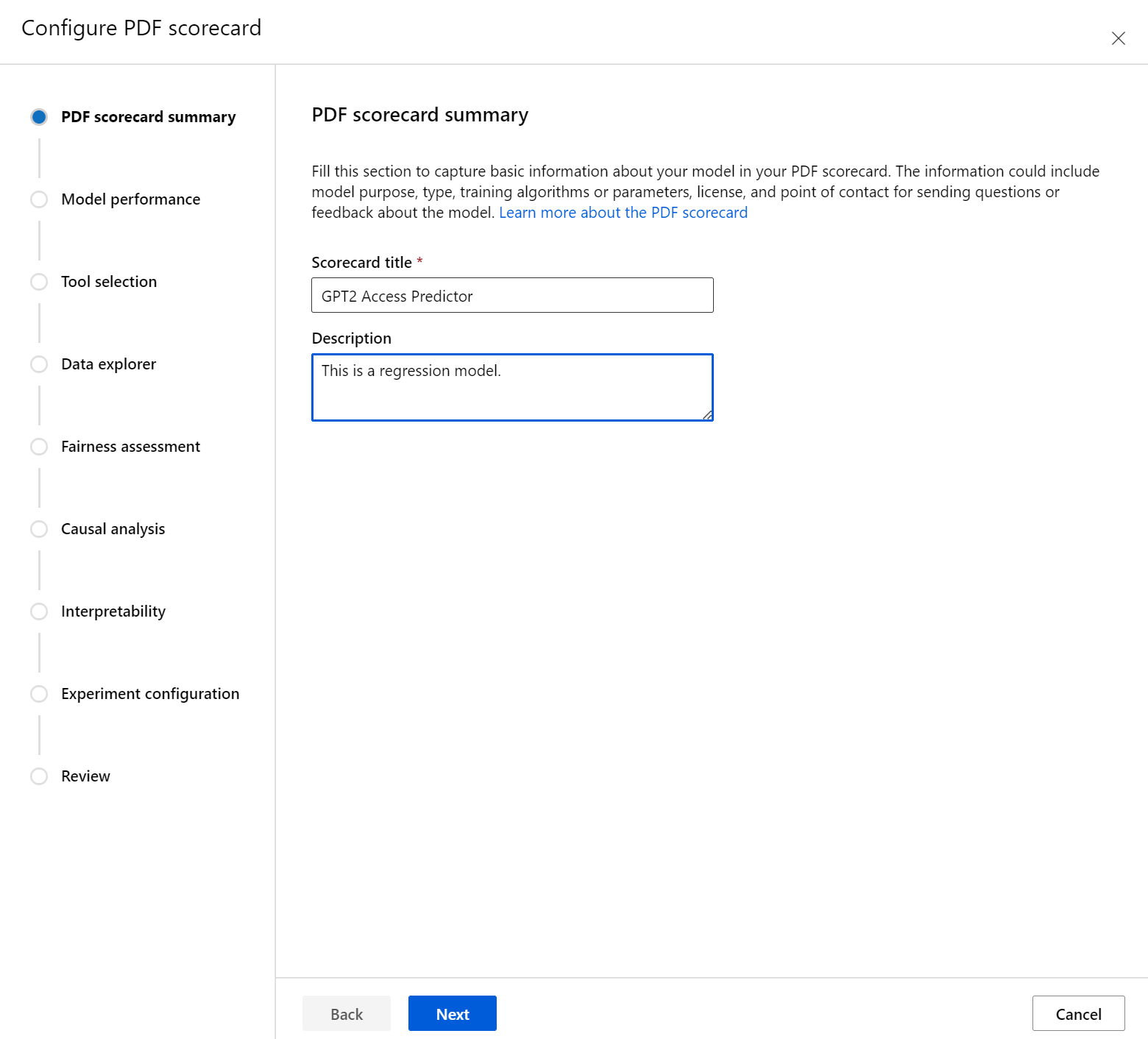
In de sectie Modelprestaties kunt u opnemen in uw scorecard industriestandaard modelevaluatiegegevens, terwijl u de gewenste doelwaarden voor de geselecteerde metrische gegevens kunt instellen. Selecteer de gewenste metrische prestatiegegevens (maximaal drie) en doelwaarden met behulp van de vervolgkeuzelijsten.
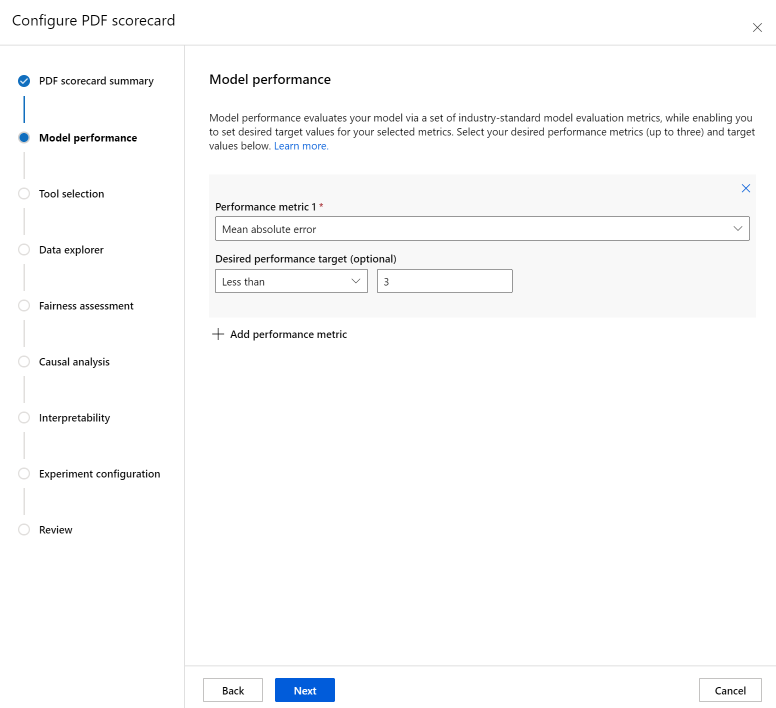
Met de selectiestap Hulpprogramma kunt u kiezen welke volgende onderdelen u wilt opnemen in uw scorecard. Schakel Opnemen in scorecard in om alle onderdelen op te nemen of schakel elk onderdeel afzonderlijk in of uit. Selecteer het infopictogram ('i' in een cirkel) naast de onderdelen voor meer informatie.

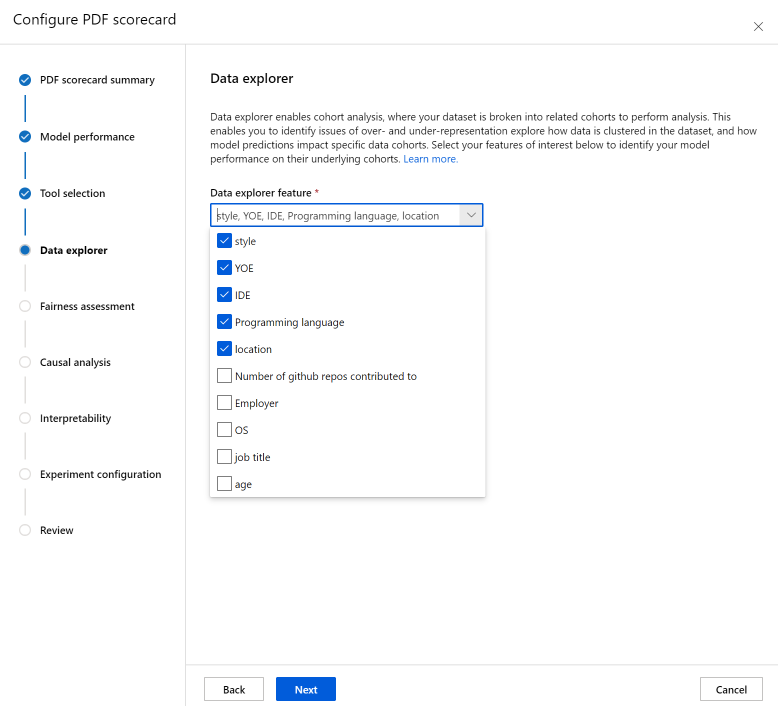
De sectie Gegevensanalyse (voorheen Data Explorer genoemd) maakt cohortanalyse mogelijk. Hier kunt u problemen van over- en onderweergave onderzoeken hoe gegevens worden geclusterd in de gegevensset en hoe modelvoorspellingen van invloed zijn op specifieke gegevenscohorten. Gebruik selectievakjes in de vervolgkeuzelijst om hieronder de gewenste functies te selecteren om de prestaties van uw model te identificeren voor hun onderliggende cohorten.
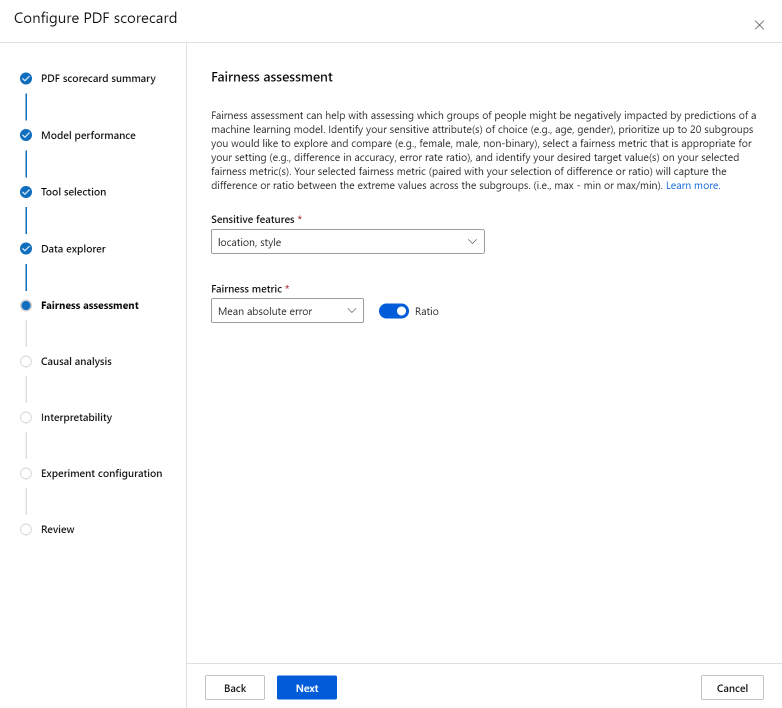
De sectie Fairness-evaluatie kan helpen bij het beoordelen van welke groepen personen een negatieve invloed kunnen hebben op voorspellingen van een machine learning-model. Er zijn twee velden in deze sectie.
Gevoelige functies: identificeer uw gevoelige kenmerken (bijvoorbeeld leeftijd, geslacht) door maximaal 20 subgroepen te prioriteren die u wilt verkennen en vergelijken.
Metrische waarde voor redelijkheid: selecteer een metrische waarde voor redelijkheid die geschikt is voor uw instelling (bijvoorbeeld het verschil in nauwkeurigheid, de verhouding tussen foutpercentages) en identificeer de gewenste doelwaarde(s) op de geselecteerde metrische gegevens voor redelijkheid. De geselecteerde metrische waarde voor redelijkheid (gekoppeld aan uw selectie van verschil of verhouding via de wisselknop) legt het verschil of de verhouding tussen de extreme waarden in de subgroepen vast. (max - min of max/min).
Notitie
De fairness-evaluatie is momenteel alleen beschikbaar voor categorische gevoelige kenmerken, zoals geslacht.
De sectie Causale analyse beantwoordt echte 'wat als'-vragen over hoe veranderingen van behandelingen van invloed zijn op een werkelijk resultaat. Als het causale onderdeel wordt geactiveerd in het dashboard voor verantwoorde AI waarvoor u een scorecard genereert, is er geen configuratie meer nodig.

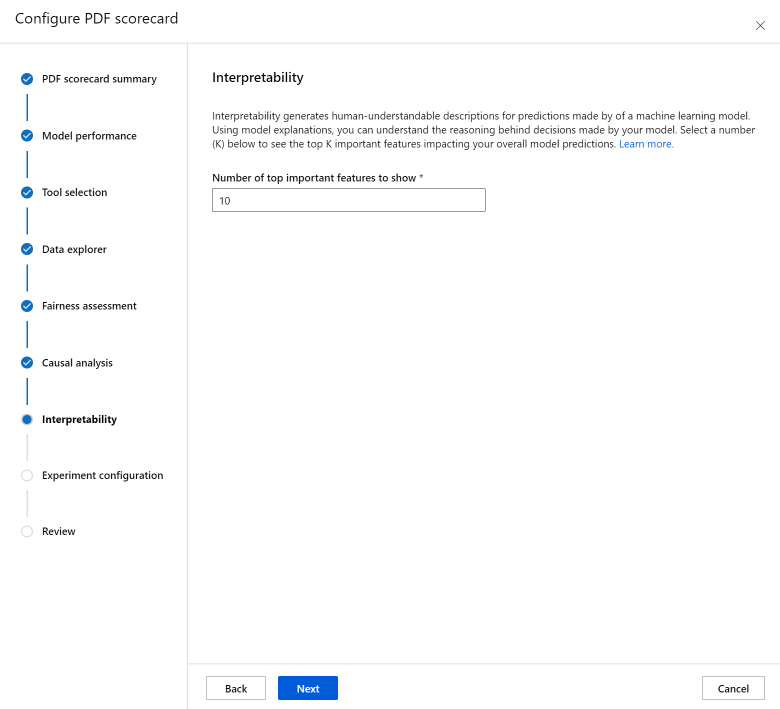
De sectie Interpretabiliteit genereert begrijpelijke beschrijvingen voor voorspellingen die zijn gemaakt door uw machine learning-model. Met modeluitleg kunt u de redenering achter beslissingen van uw model begrijpen. Selecteer hieronder een getal (K) om de belangrijkste K-functies te zien die van invloed zijn op uw algemene modelvoorspellingen. De standaardwaarde voor K is 10.
Ten slotte configureert u uw experiment om een taak te starten om uw scorecard te genereren. Deze configuraties zijn hetzelfde als de configuraties voor uw verantwoordelijke AI-dashboard.
Controleer ten slotte uw configuraties en selecteer Maken om uw taak te starten.

U wordt omgeleid naar de experimentpagina om de voortgang van uw taak bij te houden nadat u deze hebt gestart. Zie Responsible AI scorecard (preview) gebruiken voor meer informatie over het weergeven en gebruiken van uw verantwoordelijke AI-scorecard.









Volgende stappen
- Nadat u uw verantwoordelijke AI-dashboard hebt gegenereerd, bekijkt u hoe u het dashboard opent en gebruikt in Azure Machine Learning-studio.
- Meer informatie over de concepten en technieken achter het verantwoordelijke AI-dashboard.
- Meer informatie over het op verantwoorde wijze verzamelen van gegevens.
- Meer informatie over het gebruik van het verantwoordelijke AI-dashboard en scorecard voor het opsporen van fouten in gegevens en modellen en het informeren van betere besluitvorming in dit blogbericht van de techcommunity.
- Meer informatie over hoe het verantwoordelijke AI-dashboard en scorecard werden gebruikt door de UK National Health Service (NHS) in een echt klantverhaal.
- Verken de functies van het dashboard Voor verantwoorde AI via deze interactieve AI Lab-webdemo.