Modellen, onderdelen en omgevingen delen in werkruimten met registers
Met het Azure Machine Learning-register kunt u samenwerken tussen werkruimten binnen uw organisatie. Met behulp van registers kunt u modellen, onderdelen en omgevingen delen.
Er zijn twee scenario's waarin u dezelfde set modellen, onderdelen en omgevingen in meerdere werkruimten wilt gebruiken:
- MLOps voor meerdere werkruimten: u traint een model in een
devwerkruimte en moet dit implementeren intestenprodwerkruimten. In dit geval wilt u end-to-end herkomst hebben tussen eindpunten waarop het model wordt geïmplementeerd intestofprodwerkruimten en de trainingstaak, metrische gegevens, code, gegevens en omgeving die is gebruikt om het model in dedevwerkruimte te trainen. - Modellen en pijplijnen delen en hergebruiken in verschillende teams: delen en hergebruiken verbeteren samenwerking en productiviteit. In dit scenario wilt u mogelijk een getraind model en de bijbehorende onderdelen en omgevingen publiceren die worden gebruikt om het te trainen naar een centrale catalogus. Van daaruit kunnen collega's van andere teams de assets zoeken en hergebruiken die u in hun eigen experimenten hebt gedeeld.
In dit artikel leert u het volgende:
- Maak een omgeving en onderdeel in het register.
- Gebruik het onderdeel uit het register om een modeltrainingstaak in een werkruimte te verzenden.
- Registreer het getrainde model in het register.
- Implementeer het model van het register naar een online-eindpunt in de werkruimte en dien vervolgens een deductieaanvraag in.
Vereisten
Voordat u de stappen in dit artikel volgt, moet u ervoor zorgen dat u over de volgende vereisten beschikt:
- Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
Een Azure Machine Learning-register voor het delen van modellen, onderdelen en omgevingen. Als u een register wilt maken, raadpleegt u Meer informatie over het maken van een register.
Een Azure Machine Learning-werkruimte. Als u er nog geen hebt, gebruikt u de stappen in de quickstart: artikel Werkruimtebronnen maken om er een te maken.
Belangrijk
De Azure-regio (locatie) waar u uw werkruimte maakt, moet in de lijst met ondersteunde regio's voor het Azure Machine Learning-register staan
De Azure CLI en de
mlextensie of de Azure Machine Learning Python SDK v2:Zie De CLI (v2) installeren, instellen en gebruiken om de Azure CLI en extensie te installeren.
Belangrijk
In de CLI-voorbeelden in dit artikel wordt ervan uitgegaan dat u de Bash-shell (of compatibele) shell gebruikt. Bijvoorbeeld vanuit een Linux-systeem of Windows-subsysteem voor Linux.
In de voorbeelden wordt ook ervan uitgegaan dat u standaardwaarden voor de Azure CLI hebt geconfigureerd, zodat u de parameters voor uw abonnement, werkruimte, resourcegroep of locatie niet hoeft op te geven. Gebruik de volgende opdrachten om standaardinstellingen in te stellen. Vervang de volgende parameters door de waarden voor uw configuratie:
- Vervang
<subscription>door de id van uw Azure-abonnement. - Vervang door
<workspace>de naam van uw Azure Machine Learning-werkruimte. - Vervang door
<resource-group>de Azure-resourcegroep die uw werkruimte bevat. - Vervang door
<location>de Azure-regio die uw werkruimte bevat.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>U kunt zien wat de huidige standaardwaarden zijn met behulp van de
az configure -lopdracht.- Vervang
Opslagplaats met kloonvoorbeelden
De codevoorbeelden in dit artikel zijn gebaseerd op het nyc_taxi_data_regression voorbeeld in de opslagplaats met voorbeelden. Als u deze bestanden in uw ontwikkelomgeving wilt gebruiken, gebruikt u de volgende opdrachten om de opslagplaats te klonen en mappen te wijzigen in het voorbeeld:
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
Voor het CLI-voorbeeld wijzigt u mappen cli/jobs/pipelines-with-components/nyc_taxi_data_regression in uw lokale kloon van de voorbeeldenopslagplaats.
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
SDK-verbinding maken
Tip
Deze stap is alleen nodig wanneer u de Python SDK gebruikt.
Maak een clientverbinding met zowel de Azure Machine Learning-werkruimte als het register:
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
Omgeving maken in register
Omgevingen definiëren de Docker-container en Python-afhankelijkheden die zijn vereist voor het uitvoeren van trainingstaken of het implementeren van modellen. Zie de volgende artikelen voor meer informatie over omgevingen:
Tip
Dezelfde CLI-opdracht az ml environment create kan worden gebruikt voor het maken van omgevingen in een werkruimte of register. Als u de opdracht uitvoert met --workspace-name de opdracht, wordt de omgeving in een werkruimte gemaakt terwijl u de opdracht uitvoert met --registry-name het maken van de omgeving in het register.
We maken een omgeving die gebruikmaakt van de python:3.8 docker-installatiekopie en python-pakketten installeert die nodig zijn om een trainingstaak uit te voeren met behulp van het SciKit Learn-framework. Als u de voorbeeldenopslagplaats hebt gekloond en zich in de map cli/jobs/pipelines-with-components/nyc_taxi_data_regressionbevindt, moet u het omgevingsdefinitiebestand env_train.yml kunnen zien dat verwijst naar het docker-bestand env_train/Dockerfile. Hieronder env_train.yml ziet u het volgende voor uw referentie:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1
build:
path: ./env_train
Maak de omgeving als az ml environment create volgt
az ml environment create --file env_train.yml --registry-name <registry-name>
Als er een foutbericht wordt weergegeven dat er al een omgeving met deze naam en versie in het register bestaat, kunt u het version veld bewerken in env_train.yml of een andere versie opgeven in de CLI waarmee de versiewaarde wordt overschreven.env_train.yml
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
Tip
version=$(date +%s) werkt alleen in Linux. Vervang $version door een willekeurig getal als dit niet werkt.
Noteer de name en version omgeving uit de uitvoer van de az ml environment create opdracht en gebruik deze als volgt met az ml environment show opdrachten. U hebt de name en version in de volgende sectie nodig wanneer u een onderdeel in het register maakt.
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
Tip
Als u een andere omgevingsnaam of -versie hebt gebruikt, vervangt u de --name parameters --version dienovereenkomstig.
U kunt ook az ml environment list --registry-name <registry-name> alle omgevingen in het register weergeven.
U kunt door alle omgevingen in de Azure Machine Learning-studio bladeren. Zorg ervoor dat u naar de algemene gebruikersinterface navigeert en zoekt naar de vermelding Registers .

Een onderdeel maken in het register
Onderdelen zijn herbruikbare bouwstenen van Machine Learning-pijplijnen in Azure Machine Learning. U kunt de code, opdracht, omgeving, invoerinterface en uitvoerinterface van een afzonderlijke pijplijnstap in een onderdeel verpakken. Vervolgens kunt u het onderdeel opnieuw gebruiken in meerdere pijplijnen zonder dat u zich zorgen hoeft te maken over het overzetten van afhankelijkheden en code telkens wanneer u een andere pijplijn schrijft.
Als u een onderdeel in een werkruimte maakt, kunt u het onderdeel in elke pijplijntaak in die werkruimte gebruiken. Als u een onderdeel in een register maakt, kunt u het onderdeel in elke pijplijn in elke werkruimte binnen uw organisatie gebruiken. Het maken van onderdelen in een register is een uitstekende manier om modulaire herbruikbare hulpprogramma's of gedeelde trainingstaken te bouwen die kunnen worden gebruikt voor experimenten door verschillende teams binnen uw organisatie.
Zie de volgende artikelen voor meer informatie over onderdelen:
Onderdelen gebruiken in pijplijnen (SDK)
Belangrijk
Register biedt alleen ondersteuning voor benoemde assets (gegevens/model/component/omgeving). Als u naar een asset in een register wilt verwijzen, moet u deze eerst in het register maken. Met name voor het geval van een pijplijnonderdeel, moet u eerst het onderdeel of de omgeving in het register maken als u een verwijzingsonderdeel of omgeving in het pijplijnonderdeel wilt maken.
Zorg ervoor dat u zich in de map cli/jobs/pipelines-with-components/nyc_taxi_data_regressionbevindt. U vindt het onderdeeldefinitiebestand train.yml dat een Scikit Learn-trainingsscript train_src/train.py en de gecureerde omgeving AzureML-sklearn-0.24-ubuntu18.04-py37-cpuverpakt. We gebruiken de Scikit Learn-omgeving die in een pervious stap is gemaakt in plaats van de gecureerde omgeving. U kunt het veld in de train.yml scikit Learn-omgeving bewerkenenvironment. Het resulterende onderdeeldefinitiebestand train.yml is vergelijkbaar met het volgende voorbeeld:
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1`
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
Als u een andere naam of versie hebt gebruikt, ziet des te algemenere weergave er als volgt uit: environment: azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>, zorg er dus voor dat u de <registry-name>, <sklearn-environment-name> en <sklearn-environment-version> dienovereenkomstig vervangt. Vervolgens voert u de az ml component create opdracht uit om het onderdeel als volgt te maken.
az ml component create --file train.yml --registry-name <registry-name>
Tip
Dezelfde CLI-opdracht az ml component create kan worden gebruikt voor het maken van onderdelen in een werkruimte of register. Als u de opdracht met --workspace-name de opdracht uitvoert, wordt het onderdeel in een werkruimte gemaakt terwijl u de opdracht uitvoert met --registry-name het maken van het onderdeel in het register.
Als u de train.ymlomgevingsnaam liever niet bewerkt, kunt u de omgevingsnaam op de CLI als volgt overschrijven:
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
# or if you used a different name or version, replace `<sklearn-environment-name>` and `<sklearn-environment-version>` accordingly
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>
Tip
Als u een foutbericht krijgt dat de naam van het onderdeel al in het register bestaat, kunt u de versie bewerken in train.yml of de versie op de CLI overschrijven met een willekeurige versie.
Noteer de name en version van het onderdeel uit de uitvoer van de az ml component create opdracht en gebruik deze als volgt met az ml component show opdrachten. U hebt de name en version in de volgende sectie nodig wanneer u een trainingstaak in de werkruimte maakt.
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
U kunt ook az ml component list --registry-name <registry-name> alle onderdelen in het register weergeven.
U kunt door alle onderdelen in de Azure Machine Learning-studio bladeren. Zorg ervoor dat u naar de algemene gebruikersinterface navigeert en zoekt naar de vermelding Registers .

Een pijplijntaak uitvoeren in een werkruimte met behulp van een onderdeel uit het register
Wanneer u een pijplijntaak uitvoert die gebruikmaakt van een onderdeel uit een register, zijn de rekenresources en trainingsgegevens lokaal voor de werkruimte. Zie de volgende artikelen voor meer informatie over het uitvoeren van taken:
- Taken uitvoeren (CLI)
- Taken uitvoeren (SDK)
- Pijplijntaken met onderdelen (CLI)
- Pijplijntaken met onderdelen (SDK)
We voeren een pijplijntaak uit met het Trainingsonderdeel Scikit Learn dat in de vorige sectie is gemaakt om een model te trainen. Controleer of u zich in de map cli/jobs/pipelines-with-components/nyc_taxi_data_regressionbevindt. De trainingsgegevensset bevindt zich in de data_transformed map. Bewerk de component sectie onder de train_job sectie van het single-job-pipeline.yml bestand om te verwijzen naar het trainingsonderdeel dat in de vorige sectie is gemaakt. Hieronder ziet u het resultaat single-job-pipeline.yml .
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
Het belangrijkste aspect is dat deze pijplijn wordt uitgevoerd in een werkruimte met behulp van een onderdeel dat zich niet in de specifieke werkruimte bevindt. Het onderdeel bevindt zich in een register dat kan worden gebruikt met elke werkruimte in uw organisatie. U kunt deze trainingstaak uitvoeren in elke werkruimte waartoe u toegang hebt zonder dat u zich zorgen hoeft te maken over het beschikbaar maken van de trainingscode en omgeving in die werkruimte.
Waarschuwing
- Voordat u de pijplijntaak uitvoert, controleert u of de werkruimte waarin u de taak uitvoert zich in een Azure-regio bevindt die wordt ondersteund door het register waarin u het onderdeel hebt gemaakt.
- Controleer of de werkruimte een rekencluster heeft met de naam
cpu-clusterof bewerk hetcomputeveld onderjobs.train_job.computemet de naam van uw berekening.
Voer de pijplijntaak uit met de az ml job create opdracht.
az ml job create --file single-job-pipeline.yml
Tip
Als u de standaardwerkruimte en resourcegroep niet hebt geconfigureerd, zoals wordt uitgelegd in de sectie Vereisten, moet u de --workspace-name en --resource-group parameters opgeven voor de az ml job create werking.
U kunt ook het bewerken single-job-pipeline.yml overslaan en de naam van het onderdeel overschrijven die in train_job de CLI wordt gebruikt.
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
Aangezien het onderdeel dat in de trainingstaak wordt gebruikt, wordt gedeeld via een register, kunt u de taak verzenden naar elke werkruimte waartoe u toegang hebt in uw organisatie, zelfs in verschillende abonnementen. Als u bijvoorbeeld de trainingstaak in deze drie werkruimten uitvoert dev-workspacetest-workspace prod-workspace, is het net zo eenvoudig als het uitvoeren van drie az ml job create opdrachten.
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
Selecteer in Azure Machine Learning-studio de eindpuntkoppeling in de taakuitvoer om de taak weer te geven. Hier kunt u metrische trainingsgegevens analyseren, controleren of de taak het onderdeel en de omgeving uit het register gebruikt en het getrainde model controleren. Noteer de name taak uit de uitvoer of zoek dezelfde informatie uit het taakoverzicht in Azure Machine Learning-studio. U hebt deze informatie nodig om het getrainde model te downloaden in de volgende sectie over het maken van modellen in het register.

Een model maken in het register
In deze sectie leert u hoe u modellen maakt in een register. Bekijk beheermodellen voor meer informatie over modelbeheer in Azure Machine Learning. We bekijken twee verschillende manieren om een model in een register te maken. Eerst is het afkomstig van lokale bestanden. Ten tweede is het kopiëren van een model dat in de werkruimte is geregistreerd in een register.
In beide opties maakt u een model met de MLflow-indeling, waarmee u dit model kunt implementeren voor deductie zonder dat u deductiecode hoeft te schrijven.
Een model in het register maken op basis van lokale bestanden
Download het model, dat beschikbaar is als uitvoer van het train_job model door de naam van de taak uit de vorige sectie te vervangen <job-name> . Het model samen met MLflow-metagegevensbestanden moet beschikbaar zijn in de ./artifacts/model/.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
Tip
Als u de standaardwerkruimte en resourcegroep niet hebt geconfigureerd, zoals wordt uitgelegd in de sectie Vereisten, moet u de --workspace-name en --resource-group parameters opgeven voor de az ml model create werking.
Waarschuwing
De uitvoer wordt az ml job list doorgegeven aan sed. Dit werkt alleen in Linux-shells. Als u windows gebruikt, voert az ml job list --parent-job-name <job-name> --query [0].name u eventuele aanhalingstekens uit die u ziet in de naam van de traintaak.
Als u het model niet kunt downloaden, kunt u het MLflow-voorbeeldmodel vinden dat is getraind door de trainingstaak in de vorige sectie in cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/ de map.
Maak het model in het register:
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
Tip
- Gebruik een willekeurig getal voor de
versionparameter als er een fout optreedt dat de modelnaam en -versie bestaan. - Dezelfde CLI-opdracht
az ml model createkan worden gebruikt om modellen te maken in een werkruimte of register. Als u de opdracht uitvoert met--workspace-namede opdracht, wordt het model in een werkruimte gemaakt terwijl u de opdracht uitvoert met--registry-namehet maken van het model in het register.
Een model delen van werkruimte naar register
In deze werkstroom maakt u eerst het model in de werkruimte en deelt u het vervolgens met het register. Deze werkstroom is handig als u het model in de werkruimte wilt testen voordat u het deelt. Implementeer deze bijvoorbeeld op eindpunten, probeer deductie uit met enkele testgegevens en kopieer het model vervolgens naar een register als alles er goed uitziet. Deze werkstroom kan ook handig zijn wanneer u een reeks modellen ontwikkelt met behulp van verschillende technieken, frameworks of parameters en slechts een van deze modellen als productiekandidaat wilt promoveren naar het register.
Zorg ervoor dat u de naam van de pijplijntaak uit de vorige sectie hebt en vervang deze in de opdracht om de onderstaande naam van de trainingstaak op te halen. Vervolgens registreert u het model vanuit de uitvoer van de trainingstaak in de werkruimte. Let op hoe de --path parameter verwijst naar de uitvoeruitvoer train_job met de azureml://jobs/$train_job_name/outputs/artifacts/paths/model syntaxis.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
Tip
- Gebruik een willekeurig getal voor de
versionparameter als er een fout optreedt dat de modelnaam en -versie bestaan.' - Als u de standaardwerkruimte en resourcegroep niet hebt geconfigureerd, zoals wordt uitgelegd in de sectie Vereisten, moet u de
--workspace-nameen--resource-groupparameters opgeven voor deaz ml model createwerking.
Noteer de modelnaam en versie. U kunt controleren of het model is geregistreerd in de werkruimte door ernaar te bladeren in de gebruikersinterface van Studio of door de opdracht te gebruiken az ml model show --name nyc-taxi-model --version $model_version .
Vervolgens deelt u het model van de werkruimte naar het register.
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
Tip
- Zorg ervoor dat u de juiste modelnaam en -versie gebruikt als u deze in de
az ml model createopdracht hebt gewijzigd. - De bovenstaande opdracht heeft twee optionele parameters '--share-with-name' en '--share-with-version'. Als dit niet is opgegeven, heeft het nieuwe model dezelfde naam en versie als het model dat wordt gedeeld.
Noteer de
nameenversionvan het model uit de uitvoer van deaz ml model createopdracht en gebruik deze als volgt metaz ml model showopdrachten. U hebt denameenversionin de volgende sectie nodig wanneer u het model implementeert op een online-eindpunt voor deductie.
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
U kunt ook az ml model list --registry-name <registry-name> alle modellen in het register weergeven of door alle onderdelen in de gebruikersinterface van Azure Machine Learning-studio bladeren. Zorg ervoor dat u naar de algemene gebruikersinterface navigeert en zoek naar de hub Registers.
In de volgende schermopname ziet u een model in een register in Azure Machine Learning-studio. Als u een model hebt gemaakt op basis van de taakuitvoer en het model vervolgens hebt gekopieerd van de werkruimte naar het register, ziet u dat het model een koppeling heeft naar de taak die het model heeft getraind. U kunt deze koppeling gebruiken om naar de trainingstaak te navigeren om de code, omgeving en gegevens te controleren die worden gebruikt om het model te trainen.
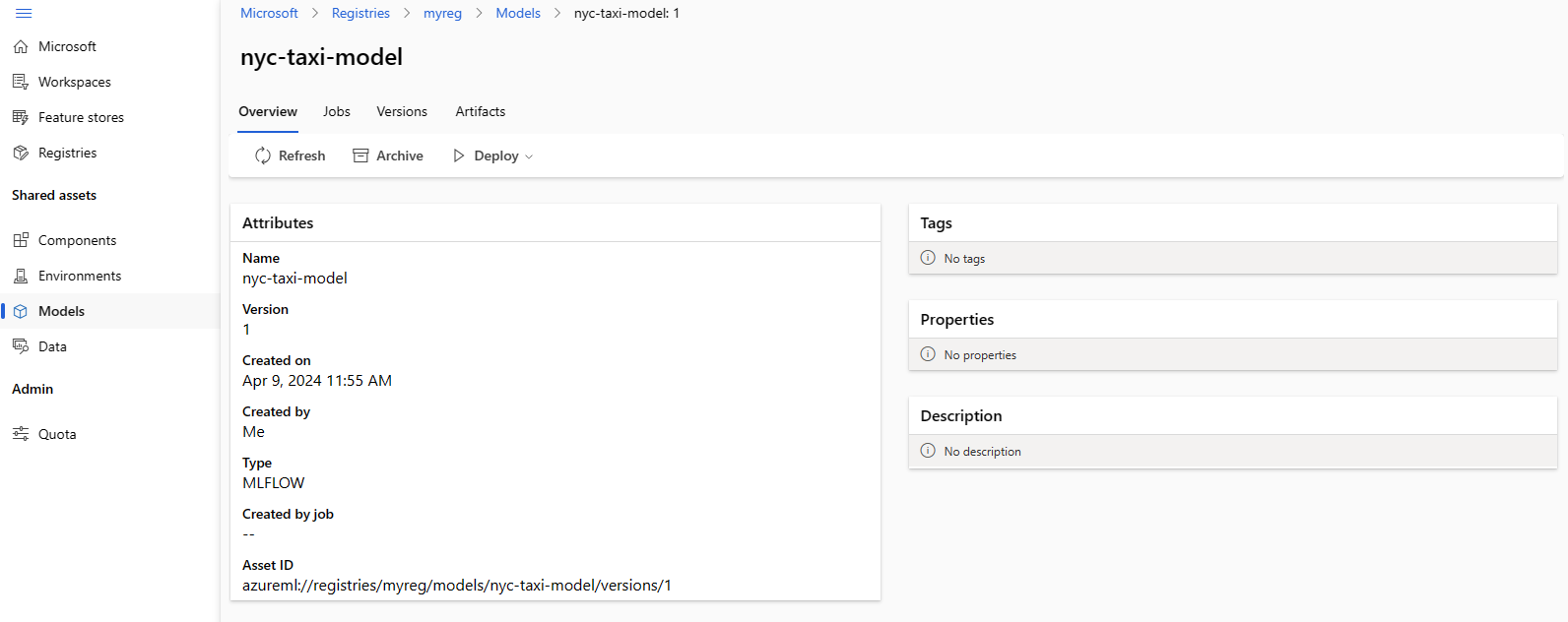
Model implementeren van register naar online-eindpunt in werkruimte
In de laatste sectie implementeert u een model van het register naar een online-eindpunt in een werkruimte. U kunt ervoor kiezen om elke werkruimte te implementeren waartoe u toegang hebt in uw organisatie, mits de locatie van de werkruimte een van de locaties is die door het register worden ondersteund. Deze mogelijkheid is handig als u een model in een dev werkruimte hebt getraind en nu het model moet implementeren naar test of prod werkruimte, terwijl de herkomstinformatie rond de code, omgeving en gegevens die worden gebruikt om het model te trainen, behouden blijft.
Met online-eindpunten kunt u modellen implementeren en deductieaanvragen verzenden via de REST API's. Zie Een machine learning-model implementeren en beoordelen met behulp van een online-eindpunt voor meer informatie.
Maak een online-eindpunt.
az ml online-endpoint create --name reg-ep-1234
Werk de model: regel deploy.yml bij die beschikbaar is in de cli/jobs/pipelines-with-components/nyc_taxi_data_regression map om te verwijzen naar de modelnaam en versie uit de pervious step. Maak een onlineimplementatie naar het online-eindpunt. Hieronder deploy.yml wordt ter referentie weergegeven.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS2_v2
instance_count: 1
Maak de onlineimplementatie. Het duurt enkele minuten om de implementatie te voltooien.
az ml online-deployment create --file deploy.yml --all-traffic
Haal de score-URI op en dien een voorbeeldscoreaanvraag in. Voorbeeldgegevens voor de scoreaanvraag zijn beschikbaar in de scoring-data.json cli/jobs/pipelines-with-components/nyc_taxi_data_regression map.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
Tip
curlde opdracht werkt alleen in Linux.- Als u de standaardwerkruimte en resourcegroep niet hebt geconfigureerd, zoals wordt uitgelegd in de sectie Vereisten, moet u de
--workspace-nameen--resource-groupparameters opgeven voor deaz ml online-endpointenaz ml online-deploymentopdrachten om te kunnen werken.
Resources opschonen
Als u de implementatie niet gaat gebruiken, moet u deze verwijderen om de kosten te verlagen. In het volgende voorbeeld worden het eindpunt en alle onderliggende implementaties verwijderd:
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor