Verhoog de snelheid van controlepunten en verlaag de kosten met nevel
Meer informatie over het verhogen van de controlepuntsnelheid en het verlagen van de kosten voor controlepunten voor grote Azure Machine Learning-trainingsmodellen met behulp van Nebula.
Overzicht
Nenevel is een snelle, eenvoudige, schijfloze, modelbewuste controlepunttool in Azure Container for PyTorch (ACPT). Nebula biedt een eenvoudige, snelle controlepuntoplossing voor gedistribueerde grootschalige modeltrainingstaken met behulp van PyTorch. Door gebruik te maken van de nieuwste technologieën voor gedistribueerde computing, kan Nebula controlepunten verminderen van uren tot seconden- mogelijk 95% tot 99,9% van de tijd besparen. Grootschalige trainingstaken kunnen aanzienlijk profiteren van de prestaties van Nenevel.
Als u Nebula beschikbaar wilt maken voor uw trainingstaken, importeert u het nebulaml Python-pakket in uw script. Nenevel heeft volledige compatibiliteit met verschillende gedistribueerde PyTorch-trainingsstrategieën, waaronder PyTorch Lightning, DeepSpeed en meer. De Nenevel-API biedt een eenvoudige manier om de levenscyclus van controlepunten te bewaken en weer te geven. De API's ondersteunen verschillende modeltypen en zorgen voor consistentie en betrouwbaarheid van controlepunten.
Belangrijk
Het nebulaml pakket is niet beschikbaar in de openbare PyPI Python-pakketindex. Deze is alleen beschikbaar in de door Azure Container for PyTorch (ACPT) samengestelde omgeving in Azure Machine Learning. Om problemen te voorkomen, probeert u niet te installeren nebulaml vanuit PyPI of met behulp van de pip opdracht.
In dit document leert u hoe u Nenevel gebruikt met ACPT in Azure Machine Learning om snel controle uit te voeren op uw modeltrainingstaken. Daarnaast leert u hoe u nenevelcontrolepuntgegevens kunt bekijken en beheren. U leert ook hoe u de modeltrainingstaken van het laatst beschikbare controlepunt hervat als er onderbrekingen, fouten of beëindiging van Azure Machine Learning zijn.
Waarom controlepuntoptimalisatie voor grote modeltrainingen belangrijk is
Naarmate gegevensvolumes toenemen en gegevensindelingen complexer worden, zijn machine learning-modellen ook geavanceerder geworden. Het trainen van deze complexe modellen kan lastig zijn vanwege de limieten voor gpu-geheugencapaciteit en langdurige trainingstijden. Als gevolg hiervan wordt gedistribueerde training vaak gebruikt bij het werken met grote gegevenssets en complexe modellen. Gedistribueerde architecturen kunnen echter onverwachte fouten en knooppuntfouten ervaren, wat steeds problematischer kan worden naarmate het aantal knooppunten in een machine learning-model toeneemt.
Controlepunten kunnen helpen deze problemen te verhelpen door periodiek een momentopname van de volledige modelstatus op een bepaald moment op te slaan. In het geval van een fout kan deze momentopname worden gebruikt om het model op het moment van de momentopname opnieuw te bouwen, zodat de training vanaf dat moment kan worden hervat.
Wanneer grote modeltrainingsbewerkingen fouten of beëindigingen ervaren, kunnen gegevenswetenschappers en onderzoekers het trainingsproces herstellen vanuit een eerder opgeslagen controlepunt. Eventuele voortgang tussen het controlepunt en de beëindiging gaat echter verloren omdat berekeningen opnieuw moeten worden uitgevoerd om niet-opgeslagen tussenliggende resultaten te herstellen. Kortere controlepuntintervallen kunnen helpen dit verlies te verminderen. Het diagram illustreert de tijd die is verspild tussen het trainingsproces van controlepunten en beëindiging:

Het proces voor het opslaan van controlepunten zelf kan echter aanzienlijke overhead genereren. Het opslaan van een controlepunt in TB-grootte kan vaak een knelpunt worden in het trainingsproces, waarbij het gesynchroniseerde controlepunt de training uren blokkeert. Gemiddeld kan controlepuntgerelateerde overhead 12% van de totale trainingstijd in rekening worden gebracht en kan oplopen tot 43% (Maeng et al., 2021).
Om samen te vatten, omvat het beheer van grote modelcontrolepunten zware opslag en overheadkosten voor het herstel van taken. Frequente controlepunten besparen, gecombineerd met hervatting van trainingstaken van de meest recente beschikbare controlepunten, worden een grote uitdaging.
Nevel naar de redding
Om grote gedistribueerde modellen effectief te trainen, is het belangrijk dat u een betrouwbare en efficiënte manier hebt om de voortgang van de training op te slaan en te hervatten, waardoor gegevensverlies en verspilling van resources worden geminimaliseerd. Nebula helpt controlepunten te besparen en GPU-uursvereisten voor grote azure Machine Learning-trainingstaken te verminderen door sneller en eenvoudiger controlepuntbeheer te bieden.
Met Nenevel kunt u het volgende doen:
Verhoog de snelheid van controlepunten tot 1000 keer met een eenvoudige API die asynchroon werkt met uw trainingsproces. Nenevel kan controlepunten van uren tot seconden verminderen- een mogelijke vermindering van 95% tot 99%.
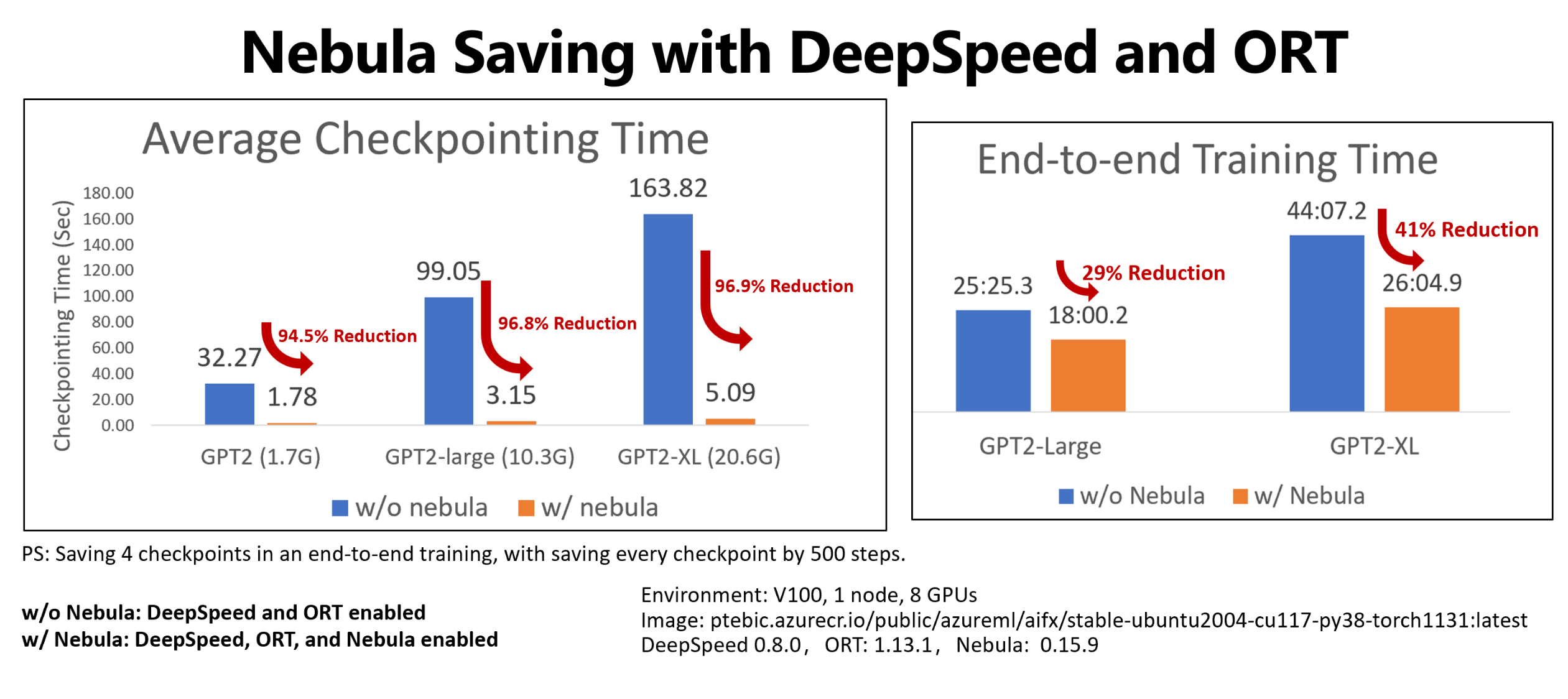
In dit voorbeeld ziet u het controlepunt en de end-to-end trainingstijd voor vier controlepunten voor het opslaan van hugging Face GPT2- en GPT2-Large- en GPT-XL-trainingstaken. Voor de middelgrote Hugging Face GPT2-XL controlepunt bespaart (20,6 GB), heeft Nebula een 96,9% tijdsvermindering bereikt voor één controlepunt.
De toename van de controlepuntsnelheid kan nog steeds toenemen met modelgrootte en GPU-nummers. Als u bijvoorbeeld een controlepunt voor een trainingspunt test op 97 GB op 128 A100 Nvidia GPU's, kan dit van 20 minuten tot 1 seconde verkleinen.
Verminder de end-to-end trainingstijd en rekenkosten voor grote modellen door controlepuntoverhead te minimaliseren en het aantal GPU-uren te verminderen dat wordt verspild aan taakherstel. Nenevel slaat controlepunten asynchroon op en deblokkert het trainingsproces om de end-to-end trainingstijd te verkleinen. Het maakt ook frequenter controlepunten opslaan mogelijk. Op deze manier kunt u uw training hervatten vanaf het laatste controlepunt na een onderbreking en tijd en geld besparen die verspild zijn aan jobherstel- en GPU-trainingsuren.
Volledige compatibiliteit met PyTorch bieden. Nenevel biedt volledige compatibiliteit met PyTorch en biedt volledige integratie met gedistribueerde trainingsframeworks, waaronder DeepSpeed (>=0.7.3) en PyTorch Lightning (>=1.5.0). U kunt deze ook gebruiken met verschillende Azure Machine Learning-rekendoelen, zoals Azure Machine Learning Compute of AKS.
Beheer uw controlepunten eenvoudig met een Python-pakket waarmee u uw controlepunten kunt weergeven, ophalen, opslaan en laden. Om de levenscyclus van controlepunten weer te geven, biedt Nebula ook uitgebreide logboeken over Azure Machine Learning-studio. U kunt ervoor kiezen om uw controlepunten op te slaan op een lokale of externe opslaglocatie
- Azure Blob-opslag
- Azure Data Lake Storage
- NFS
en ze op elk gewenst moment openen met een paar regels code.

Vereisten
- Een Azure-abonnement en een Azure Machine Learning-werkruimte. Zie Werkruimteresources maken voor meer informatie over het maken van werkruimteresources
- Een Azure Machine Learning-rekendoel. Zie Training beheren en berekeningen implementeren voor meer informatie over het maken van rekendoel
- Een trainingsscript dat Gebruikmaakt van PyTorch.
- Door ACPT samengestelde omgeving (Azure Container for PyTorch). Zie Gecureerde omgevingen om de ACPT-installatiekopieën te verkrijgen. Meer informatie over het gebruik van de gecureerde omgeving
Nebula gebruiken
Nenevel biedt een snelle, eenvoudige controlepuntervaring, direct in uw bestaande trainingsscript. De stappen voor het snel starten van Nenevel zijn onder andere:
- ACPT-omgeving gebruiken
- Nenevel initialiseren
- API's aanroepen om controlepunten op te slaan en te laden
ACPT-omgeving gebruiken
Azure Container for PyTorch (ACPT), een gecureerde omgeving voor pyTorch-modeltraining, bevat Nebula als een vooraf geïnstalleerd, afhankelijk Python-pakket. Zie Azure Container for PyTorch (ACPT) om de gecureerde omgeving weer te geven en Deep Learning in te schakelen met Azure Container for PyTorch in Azure Machine Learning voor meer informatie over de ACPT-installatiekopieën.
Nenevel initialiseren
Als u Nebula wilt inschakelen met de ACPT-omgeving, hoeft u alleen uw trainingsscript te wijzigen om het nebulaml pakket te importeren en vervolgens de Nenevel-API's op de juiste plaatsen aan te roepen. U kunt voorkomen dat Azure Machine Learning SDK of CLI wordt gewijzigd. U kunt ook het wijzigen van andere stappen voorkomen om uw grote model te trainen op Azure Machine Learning Platform.
Nenevel moet initialisatie uitvoeren in uw trainingsscript. Geef in de initialisatiefase de variabelen op waarmee de locatie en frequentie van het controlepunt worden bepaald, zoals wordt weergegeven in dit codefragment:
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
Nenevel is geïntegreerd in DeepSpeed en PyTorch Lightning. Als gevolg hiervan wordt initialisatie eenvoudig en eenvoudig. Deze voorbeelden laten zien hoe u Nebula integreert in uw trainingsscripts.
Belangrijk
Voor het opslaan van controlepunten met Nebula is geheugen vereist om controlepunten op te slaan. Zorg ervoor dat uw geheugen groter is dan ten minste drie exemplaren van de controlepunten.
Als het geheugen niet voldoende is om controlepunten vast te houden, wordt u aangeraden een omgevingsvariabele NEBULA_MEMORY_BUFFER_SIZE in te stellen in de opdracht om het gebruik van het geheugen per elk knooppunt te beperken bij het opslaan van controlepunten. Bij het instellen van deze variabele wordt dit geheugen gebruikt als buffer om controlepunten op te slaan. Als het geheugengebruik niet beperkt is, zal Nenevel het geheugen zoveel mogelijk gebruiken om de controlepunten op te slaan.
Als meerdere processen op hetzelfde knooppunt worden uitgevoerd, is het maximale geheugen voor het opslaan van controlepunten de helft van de limiet gedeeld door het aantal processen. Nenevel zal de andere helft gebruiken voor coördinatie met meerdere processen. Als u bijvoorbeeld het geheugengebruik per knooppunt wilt beperken tot 200 MB, kunt u de omgevingsvariabele instellen als export NEBULA_MEMORY_BUFFER_SIZE=200000000 (in bytes, ongeveer 200 MB) in de opdracht. In dit geval gebruikt Nenevel slechts 200 MB geheugen om de controlepunten in elk knooppunt op te slaan. Als er vier processen worden uitgevoerd op hetzelfde knooppunt, gebruikt Nebula 25 MB geheugen per proces om de controlepunten op te slaan.
API's aanroepen om controlepunten op te slaan en te laden
Nenevel biedt API's voor het afhandelen van controlepunten. U kunt deze API's gebruiken in uw trainingsscripts, vergelijkbaar met de PyTorch-API torch.save() . Deze voorbeelden laten zien hoe u Nenevel gebruikt in uw trainingsscripts.
Bekijk de geschiedenis van uw controlepunten
Wanneer uw trainingstaak is voltooid, gaat u naar het Name> Outputs + logs taakvenster. Vouw in het linkerdeelvenster de map Nenevel uit en selecteer checkpointHistories.csv deze om gedetailleerde informatie te bekijken over het opslaan van nenevelcontrolepunten: duur, doorvoer en controlepuntgrootte.

Voorbeelden
In deze voorbeelden ziet u hoe u Nenevel gebruikt met verschillende frameworktypen. U kunt het voorbeeld kiezen dat het beste past bij uw trainingsscript.
Als u volledige Nebula-compatibiliteit met trainingsscripts op basis van PyTorch wilt inschakelen, wijzigt u uw trainingsscript indien nodig.
Importeer eerst het vereiste
nebulamlpakket:# Import the Nebula package for fast-checkpointing import nebulaml as nmAls u Nenevel wilt initialiseren, roept u de
nm.init()functie aan,main()zoals hier wordt weergegeven:# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)Als u controlepunten wilt opslaan, vervangt u de oorspronkelijke
torch.save()instructie om uw controlepunt op te slaan door Nebula. Zorg ervoor dat uw controlepuntexemplaren beginnen met 'global_step', zoals 'global_step500' of 'global_step1000':checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)Notitie
<'CKPT_TAG_NAME'>is de unieke id voor het controlepunt. Een tag is meestal het aantal stappen, het epochnummer of een door de gebruiker gedefinieerde naam. De optionele optionele<'NUM_OF_FILES'>parameter geeft het statusnummer op dat u voor deze tag wilt opslaan.Laad het meest recente geldige controlepunt, zoals hier wordt weergegeven:
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)Aangezien een controlepunt of momentopname veel bestanden kan bevatten, kunt u een of meer bestanden laden op basis van de naam. Met het laatste controlepunt kan de trainingsstatus worden hersteld naar de status die is opgeslagen door het laatste controlepunt.
Andere API's kunnen controlepuntbeheer verwerken
- alle controlepunten weergeven
- meest recente controlepunten ophalen
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)