Logboekweergave & metrische gegevens en logboekbestanden v1
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
Log realtime informatie met behulp van zowel het standaard Python-logboekregistratiepakket als azure Machine Learning Python SDK-specifieke functionaliteit. U kunt logboeken lokaal opslaan en logboeken verzenden naar uw werkruimte in de portal.
Logboeken kunnen u helpen bij het diagnosticeren van fouten en waarschuwingen, of bij het bijhouden van metrische gegevens, zoals parameters en modelprestaties. In dit artikel leert u hoe u logboekregistratie inschakelt in de volgende scenario's:
- Metrische gegevens voor logboekuitvoering
- Interactieve trainingssessies
- Trainingstaken verzenden met behulp van ScriptRunConfig
- Systeemeigen Python-instellingen voor
logging - Logboekregistratie van aanvullende bronnen
Tip
In dit artikel leest u hoe u het modeltrainingsproces kunt bewaken. Als u geïnteresseerd bent in het bewaken van het resourcegebruik en gebeurtenissen van Azure Machine Learning, zoals quota, voltooide trainingsuitvoeringen of voltooide modelimplementaties, raadpleegt u Bewaking van Azure Machine Learning.
Gegevenstypen
U kunt meerdere gegevenstypen vastleggen, waaronder scalaire waarden, lijsten, tabellen, afbeeldingen, directory's en meer. Zie de referentiepagina voor Run-klassen voor meer informatie en Python-codevoorbeelden voor verschillende gegevenstypen.
Metrische gegevens van uitvoering in logboekregistratie
Gebruik de volgende methoden in de API's voor logboekregistratie om de visualisaties van metrische gegevens te beïnvloeden. Let op de servicelimieten voor deze vastgelegde metrische gegevens.
| Vastgelegde waarde | Voorbeeldcode | Opmaak in portal |
|---|---|---|
| Een matrix met numerieke waarden registreren | run.log_list(name='Fibonacci', value=[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]) |
lijndiagram met één variabele |
| Registreer één numerieke waarde met dezelfde metrische naam die herhaaldelijk wordt gebruikt (bijvoorbeeld vanuit een for-lus) | for i in tqdm(range(-10, 10)): run.log(name='Sigmoid', value=1 / (1 + np.exp(-i))) angle = i / 2.0 |
Lijndiagram met één variabele |
| Een rij met 2 numerieke kolommen herhaaldelijk vastleggen | run.log_row(name='Cosine Wave', angle=angle, cos=np.cos(angle)) sines['angle'].append(angle) sines['sine'].append(np.sin(angle)) |
Lijndiagram met twee variabelen |
| Logboektabel met 2 numerieke kolommen | run.log_table(name='Sine Wave', value=sines) |
Lijndiagram met twee variabelen |
| Logboekafbeelding | run.log_image(name='food', path='./breadpudding.jpg', plot=None, description='desert') |
Gebruik deze methode om een afbeeldingsbestand of een matplotlib-plot aan de uitvoering vast te leggen. Deze installatiekopieën zijn zichtbaar en vergelijkbaar in de uitvoeringsrecord |
Logboekregistratie met MLflow
We raden u aan om uw modellen, metrische gegevens en artefacten te registreren met MLflow, omdat het open source is en de lokale modus ondersteunt voor cloudportabiliteit. In de volgende tabel en codevoorbeelden ziet u hoe u MLflow gebruikt om metrische gegevens en artefacten van uw trainingsuitvoeringen te registreren. Meer informatie over de logboekregistratiemethoden en ontwerppatronen van MLflow.
Zorg ervoor dat u de mlflow pip-pakketten en azureml-mlflow installeert in uw werkruimte.
pip install mlflow
pip install azureml-mlflow
Stel de MLflow-tracerings-URI zo in dat deze verwijst naar de back-end van Azure Machine Learning om ervoor te zorgen dat uw metrische gegevens en artefacten worden geregistreerd in uw werkruimte.
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
| Vastgelegde waarde | Voorbeeldcode | Notities |
|---|---|---|
| Een numerieke waarde registreren (int of float) | mlflow.log_metric('my_metric', 1) |
|
| Een booleaanse waarde registreren | mlflow.log_metric('my_metric', 0) |
0 = Waar, 1 = Onwaar |
| Een tekenreeks registreren | mlflow.log_text('foo', 'my_string') |
Geregistreerd als een artefact |
| Numpy-metrische gegevens of PIL-afbeeldingsobjecten in logboeken | mlflow.log_image(img, 'figure.png') |
|
| Logboek matlotlib-plot of afbeeldingsbestand | mlflow.log_figure(fig, "figure.png") |
Metrische uitvoeringsgegevens weergeven via de SDK
U kunt de metrische gegevens van een getraind model weergeven met behulp van run.get_metrics().
from azureml.core import Run
run = Run.get_context()
run.log('metric-name', metric_value)
metrics = run.get_metrics()
# metrics is of type Dict[str, List[float]] mapping metric names
# to a list of the values for that metric in the given run.
metrics.get('metric-name')
# list of metrics in the order they were recorded
U kunt ook toegang krijgen tot uitvoeringsinformatie met behulp van MLflow via de gegevens- en informatie-eigenschappen van het uitvoeringsobject. Zie de documentatie over het object MLflow.entities.Run voor meer informatie.
Nadat de uitvoering is voltooid, kunt u deze ophalen met behulp van de MlFlowClient().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
finished_mlflow_run = MlflowClient().get_run(mlflow_run.info.run_id)
U kunt de metrische gegevens, parameters en tags voor de uitvoering weergeven in het gegevensveld van het uitvoeringsobject.
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
Notitie
De metrische woordenlijst onder mlflow.entities.Run.data.metrics retourneert alleen de laatst vastgelegde waarde voor een bepaalde metrische naam. Als u zich bijvoorbeeld op volgorde 1, dan 2, dan 3 en vervolgens 4 aanmeldt bij een metrische waarde met de naam sample_metric, is alleen 4 aanwezig in de woordenlijst met metrische gegevens voor sample_metric.
Als u alle metrische gegevens wilt laten vastgelegd voor een bepaalde metrische naam, kunt u gebruiken MlFlowClient.get_metric_history().
Metrische uitvoergegevens weergeven in de gebruikersinterface van Studio
U kunt bladeren door voltooide uitvoeringsrecords, inclusief vastgelegde metrische gegevens, in de Azure Machine Learning-studio.
Ga naar het tabblad Experimenten . Als u al uw uitvoeringen in uw werkruimte in experimenten wilt weergeven, selecteert u het tabblad Alle uitvoeringen . U kunt inzoomen op uitvoeringen voor specifieke experimenten door het experimentfilter toe te passen in de bovenste menubalk.
Selecteer voor de afzonderlijke experimentweergave het tabblad Alle experimenten . Op het dashboard voor het uitvoeren van het experiment ziet u bijgehouden metrische gegevens en logboeken voor elke uitvoering.
U kunt ook de uitvoeringslijsttabel bewerken om meerdere uitvoeringen te selecteren en de laatste, minimale of maximale logboekwaarde voor uw uitvoeringen weer te geven. Pas uw grafieken aan om de vastgelegde metrische waarden en aggregaties voor meerdere uitvoeringen te vergelijken. U kunt meerdere metrische gegevens op de y-as van de grafiek uitzetten en de x-as aanpassen om de vastgelegde metrische gegevens te tekenen.
Logboekbestanden voor een uitvoering weergeven en downloaden
Logboekbestanden zijn een essentiële resource voor het opsporen van fouten in de Azure Machine Learning-workloads. Nadat u een trainingstaak hebt verzonden, zoomt u in op een specifieke uitvoering om de logboeken en uitvoer ervan weer te geven:
- Ga naar het tabblad Experimenten .
- Selecteer de runID voor een specifieke uitvoering.
- Selecteer Uitvoer en logboeken bovenaan de pagina.
- Selecteer Alles downloaden om al uw logboeken naar een zip-map te downloaden.
- U kunt ook afzonderlijke logboekbestanden downloaden door het logboekbestand te kiezen en Downloaden te selecteren
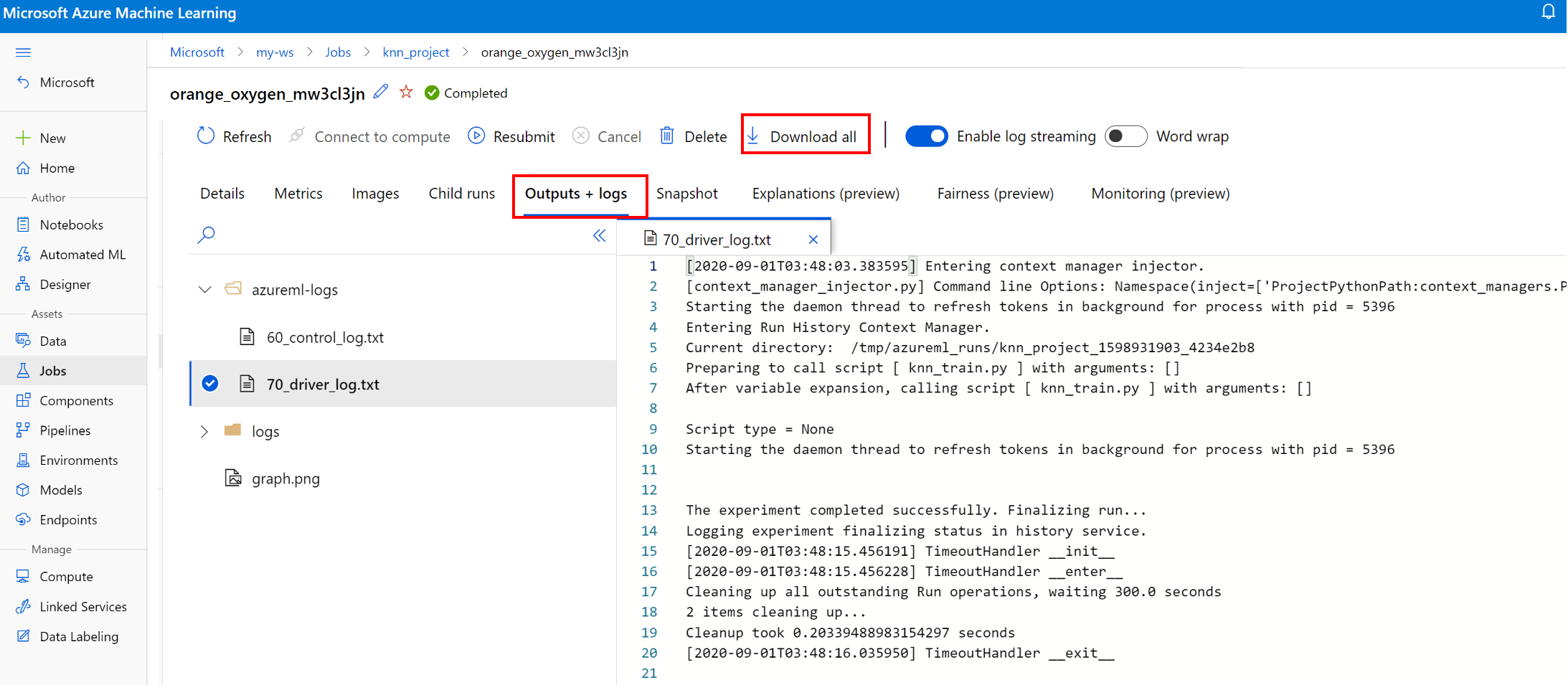
user_logs map
Deze map bevat informatie over de door de gebruiker gegenereerde logboeken. Deze map is standaard geopend en het std_log.txt logboek is geselecteerd. De std_log.txt is waar de logboeken van uw code (bijvoorbeeld afdrukinstructies) worden weergegeven. Dit bestand bevat stdout logboeken en stderr logboeken van uw besturingsscript en trainingsscript, één per proces. In de meeste gevallen controleert u de logboeken hier.
system_logs map
Deze map bevat de logboeken die zijn gegenereerd door Azure Machine Learning en worden standaard gesloten. De logboeken die door het systeem worden gegenereerd, worden gegroepeerd in verschillende mappen, op basis van de fase van de taak in de runtime.
Andere mappen
Voor het trainen van taken op clusters met meerdere berekeningen zijn logboeken aanwezig voor elk knooppunt-IP-adres. De structuur voor elk knooppunt is hetzelfde als taken met één knooppunt. Er is nog een map met logboeken voor algemene uitvoering, stderr- en stdout-logboeken.
Azure Machine Learning registreert gegevens uit verschillende bronnen tijdens de training, zoals AutoML of de Docker-container waarmee de trainingstaak wordt uitgevoerd. Veel van deze logboeken zijn niet gedocumenteerd. Als u problemen ondervindt en contact opneemt met Microsoft Ondersteuning, kunnen ze deze logboeken mogelijk gebruiken tijdens het oplossen van problemen.
Interactieve logboekregistratiesessie
Interactieve logboekregistratiesessies worden doorgaans gebruikt in notebookomgevingen. Met de methode Experiment.start_logging() wordt een interactieve logboekregistratiesessie gestart. Alle metrische gegevens die tijdens de sessie zijn geregistreerd, worden toegevoegd aan het uitvoeringsrecord in het experiment. Met de methode run.complete() worden de sessies beëindigd en de uitvoering als voltooid gemarkeerd.
ScriptRun-logboeken
In dit gedeelte leert u hoe u logboekcode in uitvoeringen toevoegt die zijn gemaakt toen de ScriptRunConfig werd geconfigureerd. Met de klasse ScriptRunConfig-kunt u scripts en omgevingen inkapselen voor herhaalbare uitvoeringen. U kunt deze optie ook gebruiken om een visuele Jupyter Notebook-widget weer te geven voor bewakingsdoeleinden.
In dit voorbeeld wordt een parameteropruiming uitgevoerd op alfawaarden en worden de resultaten vastgelegd met de methode run.log().
Maak een trainingsscript dat de logica voor logboekregistratie bevat,
train.py.# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. from sklearn.datasets import load_diabetes from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from azureml.core.run import Run import os import numpy as np import mylib # sklearn.externals.joblib is removed in 0.23 try: from sklearn.externals import joblib except ImportError: import joblib os.makedirs('./outputs', exist_ok=True) X, y = load_diabetes(return_X_y=True) run = Run.get_context() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) data = {"train": {"X": X_train, "y": y_train}, "test": {"X": X_test, "y": y_test}} # list of numbers from 0.0 to 1.0 with a 0.05 interval alphas = mylib.get_alphas() for alpha in alphas: # Use Ridge algorithm to create a regression model reg = Ridge(alpha=alpha) reg.fit(data["train"]["X"], data["train"]["y"]) preds = reg.predict(data["test"]["X"]) mse = mean_squared_error(preds, data["test"]["y"]) run.log('alpha', alpha) run.log('mse', mse) model_file_name = 'ridge_{0:.2f}.pkl'.format(alpha) # save model in the outputs folder so it automatically get uploaded with open(model_file_name, "wb") as file: joblib.dump(value=reg, filename=os.path.join('./outputs/', model_file_name)) print('alpha is {0:.2f}, and mse is {1:0.2f}'.format(alpha, mse))Verzend het script
train.pyvoor uitvoering in een door de gebruiker beheerde omgeving. De volledige scriptmap wordt verzonden voor training.from azureml.core import ScriptRunConfig src = ScriptRunConfig(source_directory='./scripts', script='train.py', environment=user_managed_env)run = exp.submit(src)Met de parameter
show_outputwordt uitgebreide logboekregistratie ingeschakeld, zodat u zowel details van het trainingsproces als informatie over externe resources of rekendoelen kunt bekijken. Gebruik de volgende code om uitgebreide logboekregistratie in te schakelen wanneer u het experiment verzendt.run = exp.submit(src, show_output=True)U kunt ook dezelfde parameter gebruiken in de functie
wait_for_completionvan de resulterende uitvoering.run.wait_for_completion(show_output=True)
Systeemeigen logboekregistratie van Python
Sommige logboeken in de SDK bevatten mogelijk een foutmelding dat u het logboekregistratieniveau moet instellen op DEBUG (fouten opsporen). Als u het logboekregistratieniveau wilt instellen, voegt u de volgende code toe aan het script.
import logging
logging.basicConfig(level=logging.DEBUG)
Andere bronnen voor logboekregistratie
Met Azure Machine Learning kunnen tijdens de training ook gegevens van andere bronnen worden geregistreerd, zoals geautomatiseerde machine learning-uitvoeringen, of Docker-containers die de taken uitvoeren. Deze logboeken worden niet gedocumenteerd, maar als u problemen ondervindt en contact opneemt met Microsoft-ondersteuning, kunnen ze deze logboeken gebruiken tijdens het oplossen van problemen.
Raadpleeg Hoe kan ik metrische gegevens registreren in de ontwerpfunctie voor informatie over het vastleggen van metrische gegevens in de Azure Machine Learning-ontwerpfunctie
Voorbeeldnotebooks
In de volgende notebooks worden concepten in dit artikel gedemonstreerd:
- how-to-use-azureml/training/train-on-local
- how-to-use-azureml/track-and-monitor-experiments/logging-api
Informatie over het uitvoeren van notebooks vindt u in het artikel Use Jupyter notebooks to explore this service (Jupyter Notebooks gebruiken om deze service te verkennen).
Volgende stappen
Raadpleeg deze artikelen voor meer informatie over het gebruik van Azure Machine Learning:
- Bekijk een voorbeeld van hoe u het beste model registreert en implementeert in de zelfstudie Een afbeeldingsclassificatiemodel trainen met Azure Machine Learning.