ML-modellen bijhouden met MLflow en Azure Machine Learning
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In dit artikel leert u hoe u MLflow-tracering inschakelt om Azure Machine Learning te verbinden als de back-end van uw MLflow-experimenten.
MLflow is een opensource-bibliotheek voor het beheren van de levenscyclus van uw machine learning-experimenten. MLflow Tracking is een onderdeel van MLflow waarmee metrische gegevens van uw trainingsuitvoering en modelartefacten worden bijgehouden en bijgehouden, ongeacht de omgeving van uw experiment, lokaal op uw computer, op een extern rekendoel, een virtuele machine of een Azure Databricks-cluster.
Zie MLflow en Azure Machine Learning voor alle ondersteunde MLflow- en Azure Machine Learning-functionaliteit, waaronder ondersteuning voor MLflow-projecten (preview) en modelimplementatie.
Tip
Als u experimenten wilt bijhouden die worden uitgevoerd in Azure Databricks of Azure Synapse Analytics, raadpleegt u de speciale artikelen Azure Databricks ML-experimenten bijhouden met MLflow en Azure Machine Learning of Ml-experimenten van Azure Synapse Analytics bijhouden met MLflow en Azure Machine Learning.
Notitie
De informatie in dit document is voornamelijk bedoeld voor gegevenswetenschappers en ontwikkelaars die het modeltrainingsproces willen bewaken. Als u een beheerder bent die geïnteresseerd is in het bewaken van het resourcegebruik en gebeurtenissen van Azure Machine Learning, zoals quota, voltooide trainingstaken of voltooide modelimplementaties, raadpleegt u Bewaking van Azure Machine Learning.
Vereisten
Installeer het
mlflow-pakket.- U kunt de MLflow Skinny gebruiken. Dit is een lichtgewicht MLflow-pakket zonder SQL-opslag, server, gebruikersinterface of gegevenswetenschap-afhankelijkheden. Dit wordt aanbevolen voor gebruikers die voornamelijk de mogelijkheden voor tracering en logboekregistratie nodig hebben zonder de volledige suite met MLflow-functies, inclusief implementaties, te importeren.
Installeer het
azureml-mlflow-pakket.Installeer en stel Azure Machine Learning CLI (v1) in en zorg ervoor dat u de ml-extensie installeert.
Belangrijk
Sommige Azure CLI-opdrachten in dit artikel maken gebruik van de
azure-cli-mlextensie , of v1 voor Azure Machine Learning. Ondersteuning voor de v1-extensie eindigt op 30 september 2025. Tot die datum kunt u de extensie v1 installeren en gebruiken.U wordt aangeraden vóór 30 september 2025 over te stappen op de
mlextensie , of v2. Zie Azure ML CLI-extensie en Python SDK v2 voor meer informatie over de v2-extensie.Azure Machine Learning SDK voor Python installeren en instellen.
Uitvoeringen bijhouden vanaf uw lokale computer of externe berekeningen
Bijhouden met MLflow met Azure Machine Learning stelt u in staat om de vastgelegde metrische gegevens en artefacten die zijn uitgevoerd op uw lokale computer op te slaan in uw Azure Machine Learning-werkruimte.
Traceringsomgeving instellen
Als u een uitvoering wilt bijhouden die niet wordt uitgevoerd op Azure Machine Learning Compute (vanaf nu 'lokale berekening' genoemd), moet u uw lokale berekening verwijzen naar de Azure Machine Learning MLflow Tracking-URI.
Notitie
Wanneer u uitvoert op Azure Compute (Azure Notebooks, Jupyter Notebooks die worden gehost op Azure Compute Instances of Rekenclusters), hoeft u de tracerings-URI niet te configureren. Deze wordt automatisch voor u geconfigureerd.
- De Azure Machine Learning SDK gebruiken
- Een omgevingsvariabele gebruiken
- De MLflow-tracerings-URI bouwen
VAN TOEPASSING OP:Python SDK azureml v1
U kunt de Azure Machine Learning MLflow-tracerings-URI ophalen met behulp van de Azure Machine Learning SDK v1 voor Python. Zorg ervoor dat de bibliotheek azureml-sdk is geïnstalleerd in het cluster dat u gebruikt. In het volgende voorbeeld wordt de unieke MLFLow-tracerings-URI ophaalt die is gekoppeld aan uw werkruimte. Vervolgens wijst de methode set_tracking_uri() de MLflow-tracerings-URI naar die URI.
Het configuratiebestand voor de werkruimte gebruiken:
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())Tip
U kunt het configuratiebestand voor de werkruimte downloaden door:
- Ga naar Azure Machine Learning-studio
- Klik op de rechterbovenhoek van de pagina -> Configuratiebestand downloaden.
- Sla het bestand
config.jsonop in dezelfde map waar u aan werkt.
Met behulp van de abonnements-id, de naam van de resourcegroep en de naam van de werkruimte:
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
Naam van experiment instellen
Alle MLflow-uitvoeringen worden geregistreerd in het actieve experiment. Uitvoeringen worden standaard geregistreerd bij een experiment met de naam Default dat automatisch voor u wordt gemaakt. Als u het experiment wilt configureren waaraan u wilt werken, gebruikt u de opdracht MLflow mlflow.set_experiment().
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
Tip
Wanneer u taken verzendt met de Azure Machine Learning SDK, kunt u de naam van het experiment instellen met behulp van de eigenschap experiment_name wanneer u deze verzendt. U hoeft deze niet te configureren in uw trainingsscript.
Trainingsuitvoering starten
Nadat u de naam van het MLflow-experiment hebt ingesteld, kunt u de trainingsuitvoering starten met start_run(). log_metric() Gebruik vervolgens om de MLflow-logboekregistratie-API te activeren en begin met het registreren van de metrische gegevens van de trainingsuitvoering.
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
Zie Metrische gegevens vastleggen en weergeven voor meer informatie over het vastleggen van metrische gegevens, parameters en artefacten in een uitvoering met behulp van MLflow.
Uitvoeringen bijhouden die worden uitgevoerd in Azure Machine Learning
VAN TOEPASSING OP:Python SDK azureml v1
Met externe uitvoeringen (taken) kunt u uw modellen op een robuustere en terugkerende manier trainen. Ze kunnen ook gebruikmaken van krachtigere berekeningen, zoals Machine Learning Compute-clusters. Zie Compute-doelen gebruiken voor modeltraining voor meer informatie over verschillende rekenopties.
Bij het verzenden van uitvoeringen configureert Azure Machine Learning MLflow automatisch voor gebruik met de werkruimte waarin de uitvoering wordt uitgevoerd. Dit betekent dat u de MLflow-tracerings-URI niet hoeft te configureren. Bovendien worden experimenten automatisch benoemd op basis van de details van het indienen van het experiment.
Belangrijk
Wanneer u trainingstaken naar Azure Machine Learning verzendt, hoeft u de MLflow-tracerings-URI niet te configureren in uw trainingslogica, omdat deze al voor u is geconfigureerd. U hoeft de naam van het experiment ook niet te configureren in uw trainingsroutine.
Een trainingsroutine maken
Maak eerst een src submap en maak een bestand met uw trainingscode in een train.py bestand in de src submap. Al uw trainingscode gaat naar de submap van src, met inbegrip van train.py.
De trainingscode is afkomstig uit dit MLflow-voorbeeld in de Azure Machine Learning-voorbeeldopslagplaats.
Kopieer deze code naar het bestand:
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
Het experiment configureren
U moet Python gebruiken om het experiment naar Azure Machine Learning te verzenden. Configureer in een notebook of Python-bestand de omgeving voor reken- en trainingsuitvoering met de Environment klasse .
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
Maak vervolgens met ScriptRunConfig uw externe berekening als rekendoel.
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
Met deze configuratie van reken- en trainingsuitvoering gebruikt u de Experiment.submit() methode om een uitvoering te verzenden. Met deze methode wordt automatisch de MLflow-tracerings-URI ingesteld en wordt de logboekregistratie van MLflow naar uw werkruimte verplaatst.
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
Metrische gegevens en artefacten weergeven in uw werkruimte
De metrische gegevens en artefacten van MLflow-logboekregistratie worden bijgehouden in uw werkruimte. Als u ze op elk gewenst moment wilt bekijken, gaat u naar uw werkruimte en zoekt u het experiment op naam in uw werkruimte in Azure Machine Learning-studio. Of voer de onderstaande code uit.
Metrische uitvoeringswaarde ophalen met behulp van MLflow get_run().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
Als u de artefacten van een uitvoering wilt weergeven, kunt u MlFlowClient.list_artifacts() gebruiken
client.list_artifacts(run_id)
Als u een artefact wilt downloaden naar de huidige map, kunt u MLFlowClient.download_artifacts() gebruiken
client.download_artifacts(run_id, "helloworld.txt", ".")
Voor meer informatie over het ophalen van informatie uit experimenten en uitvoeringen in Azure Machine Learning met behulp van MLflow bekijkt u experimenten en uitvoeringen beheren met MLflow.
Vergelijken en query's uitvoeren
Vergelijk en bevraag alle MLflow-uitvoeringen in uw Azure Machine Learning-werkruimte met de volgende code. Meer informatie over het uitvoeren van query's met MLflow.
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
Automatische logboekregistratie
Met Azure Machine Learning en MLFlow kunnen gebruikers automatisch metrische gegevens, modelparameters en modelartefacten registreren bij het trainen van een model. Er worden diverse populaire machine learning-bibliotheken ondersteund.
Als u automatische logboekregistratie wilt inschakelen, voegt u de volgende code in vóór uw trainingscode:
mlflow.autolog()
Meer informatie over Automatische logboekregistratie met MLflow.
Modellen beheren
Registreer en volg uw modellen met het Azure Machine Learning-modelregister, dat ondersteuning biedt voor het MLflow-modelregister. Azure Machine Learning-modellen zijn afgestemd op het MLflow-modelschema, zodat u deze modellen eenvoudig kunt exporteren en importeren in verschillende werkstromen. De MLflow-gerelateerde metagegevens, zoals de uitvoerings-id, worden ook bijgehouden met het geregistreerde model voor traceerbaarheid. Gebruikers kunnen trainingsuitvoeringen indienen, modellen registreren en implementeren die zijn geproduceerd op basis van MLflow-uitvoeringen.
Zie MLflow-modellen implementeren en registreren als u uw model dat gereed is voor productie in één stap wilt implementeren en registreren.
Voer de volgende stappen uit om een model van een uitvoering te registreren en weer te geven:
Zodra een uitvoering is voltooid, roept u de
register_model()methode aan.# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")Bekijk het geregistreerde model in uw werkruimte met Azure Machine Learning-studio.
In het volgende voorbeeld heeft het geregistreerde model
my-modelMLflow-traceringsmetagegevens gelabeld.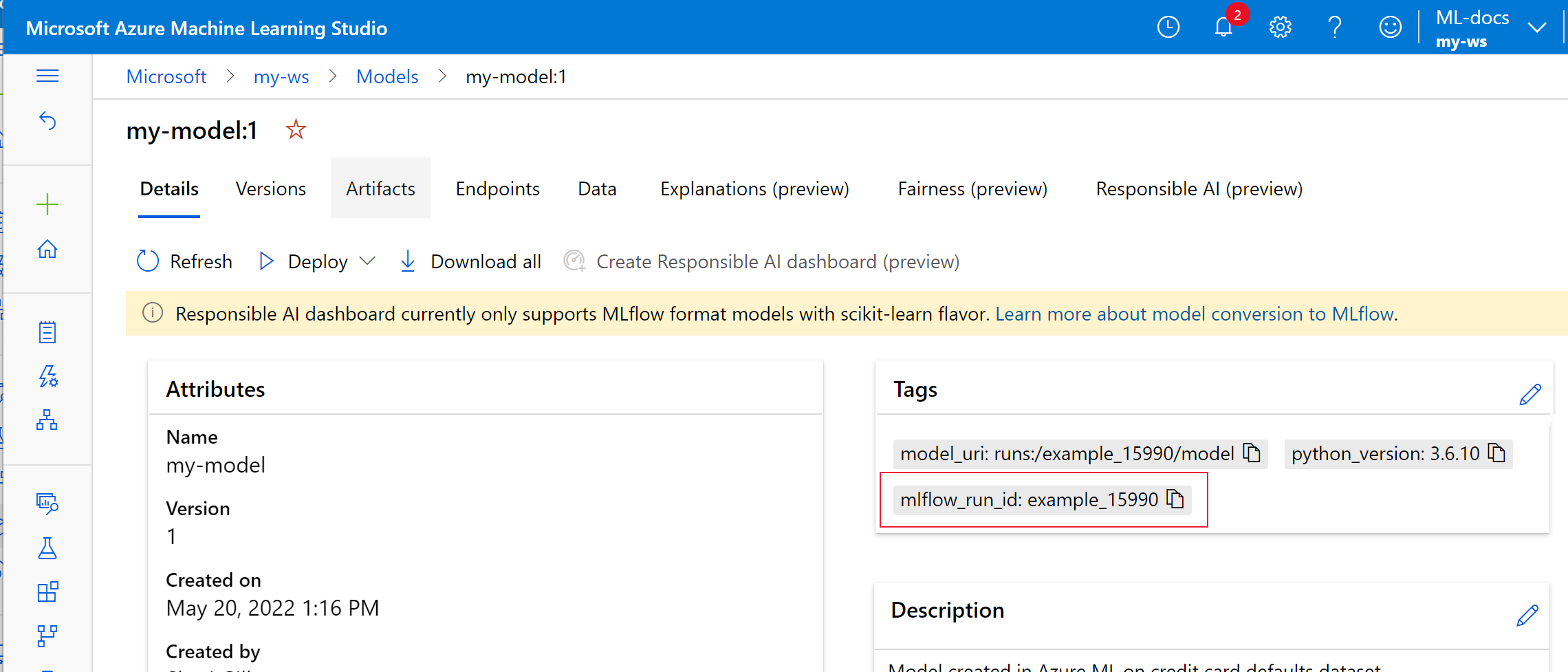
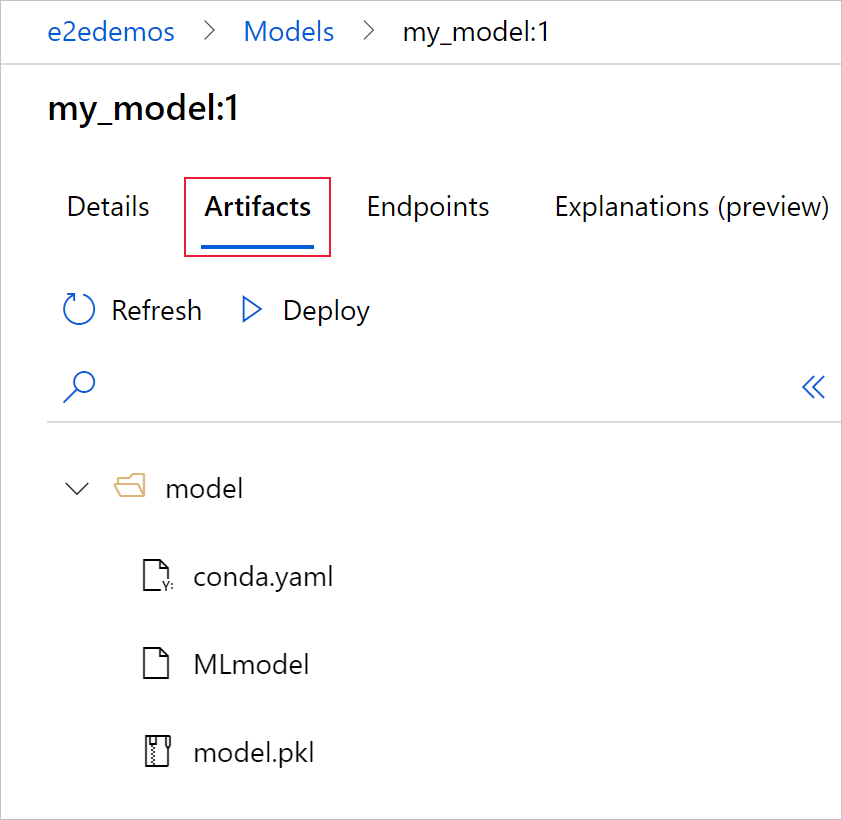
Selecteer het tabblad Artefacten om alle modelbestanden weer te geven die zijn uitgelijnd met het MLflow-modelschema (conda.yaml, MLmodel, model.pkl).
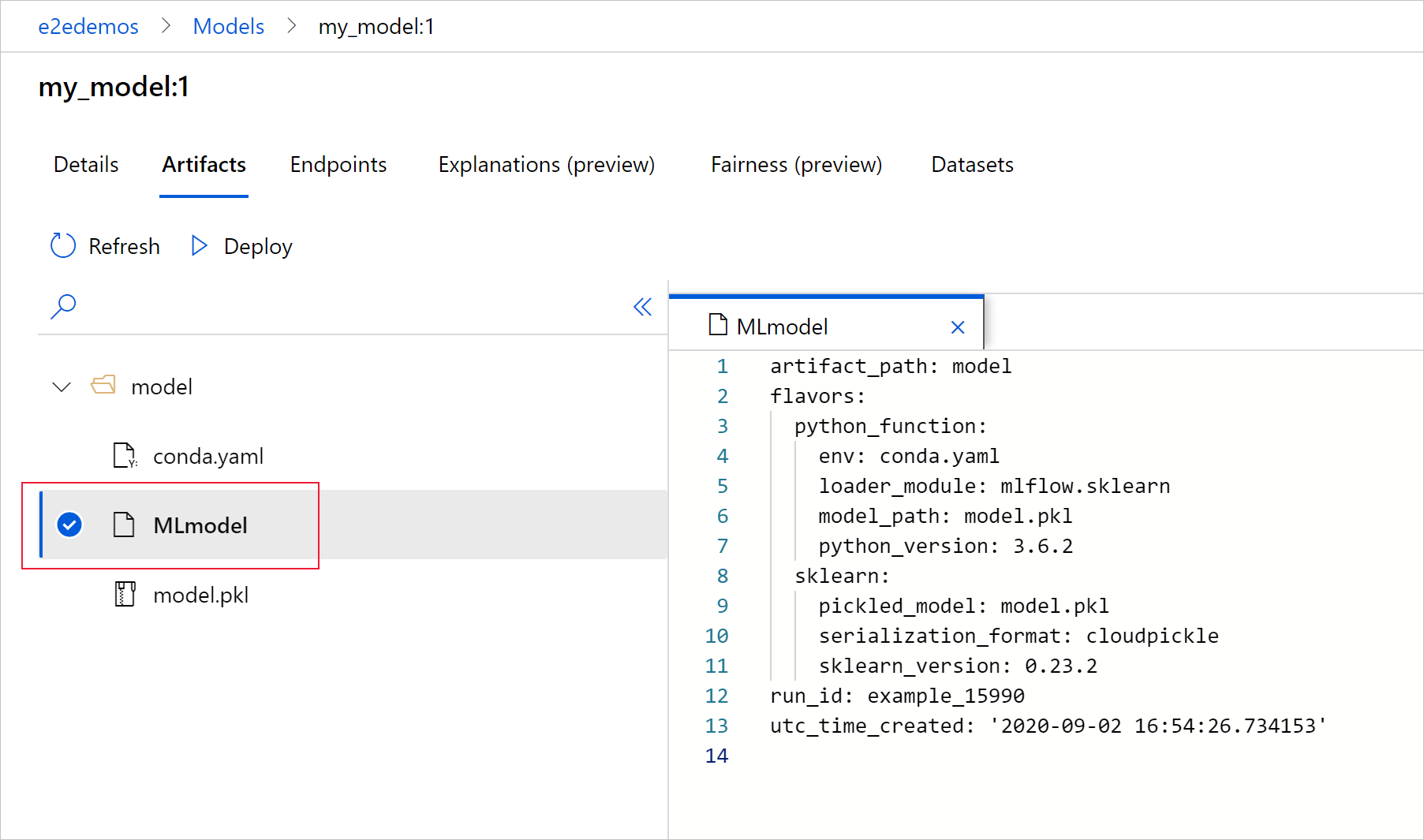
Selecteer MLmodel om het MLmodel-bestand te zien dat door de uitvoering is gegenereerd.
Resources opschonen
Als u niet van plan bent om de vastgelegde metrische gegevens en artefacten in uw werkruimte te gebruiken, is de mogelijkheid om ze afzonderlijk te verwijderen momenteel niet beschikbaar. Verwijder in plaats daarvan de resourcegroep met het opslagaccount en de werkruimte, zodat er geen kosten in rekening worden gebracht:
Selecteer Resourcegroepen links in Azure Portal.
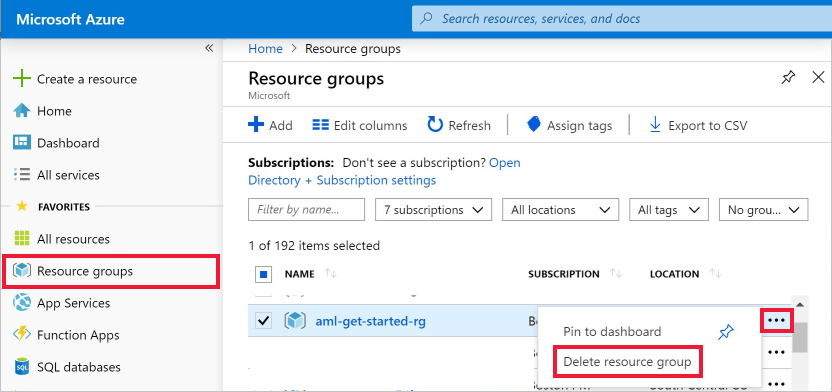
Selecteer de resourcegroep die u eerder hebt gemaakt uit de lijst.
Selecteer Resourcegroep verwijderen.
Voer de naam van de resourcegroup in. Selecteer vervolgens Verwijderen.
Voorbeeldnotebooks
De MLflow met Azure Machine Learning-notebooks laten de concepten in dit artikel zien en uitbreiden. Zie ook de door de community gestuurde opslagplaats , AzureML-Examples.
Volgende stappen
- Modellen implementeren met MLflow.
- Bewaak uw productiemodellen op gegevensdrift.
- Azure Databricks-uitvoeringen bijhouden met MLflow.
- Beheer uw modellen.