Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Managed Instance voor Apache Cassandra is een volledig beheerde service voor pure opensource Apache Cassandra-clusters. Met de service kunnen configuraties ook worden overschreven, afhankelijk van de specifieke behoeften van elke workload, waardoor maximale flexibiliteit en controle waar nodig mogelijk zijn.
In dit artikel worden de beheerbewerkingen en -functies van de service gedefinieerd. Ook wordt de scheiding van verantwoordelijkheden tussen het ondersteuning voor Azure team en klanten uitgelegd bij het onderhouden van hybride clusters.
Verdichting
Er zijn verschillende soorten compressie. Deze service voert momenteel een kleine compressie uit met behulp van reparatie, zie Onderhoud voor meer informatie. Deze bewerking voert een Merkle boomcompressie uit, wat een speciaal soort compressie is.
Afhankelijk van de compressiestrategie die is ingesteld op de tabel met behulp van CQL, wordt Cassandra bijvoorbeeld
WITH compaction = { 'class' : 'LeveledCompactionStrategy' }automatisch gecomprimeerd wanneer de tabel een specifieke grootte bereikt. U wordt aangeraden zorgvuldig een compressiestrategie voor uw workload te selecteren. Voer geen handmatige compressies uit buiten de strategie.
Toepassing van een patch
Patches op besturingssysteemniveau worden automatisch uitgevoerd met een frequentie van twee weken.
Patches op softwareniveau van Apache Cassandra worden uitgevoerd wanneer beveiligingsproblemen worden geïdentificeerd. De patchfrequentie kan variëren.
Tijdens het patchen worden machines één rek tegelijk opnieuw opgestart. U mag geen afname aan de toepassingszijde ervaren zolang quorum ALL-instelling niet wordt gebruikt en de replicatiefactor 3 of hoger is.
De versie in Apache Cassandra heeft de indeling
X.Y.Z. U kunt de implementatie van primaire (X) en secundaire (Y) versies handmatig beheren met behulp van servicehulpprogramma's. De Cassandra-patches (Z) die mogelijk vereist zijn voor die combinatie van primaire/secundaire versies, worden automatisch uitgevoerd.
Notitie
De service ondersteunt momenteel Cassandra-versies tot 5.0. Als u een Cassandra-versie wilt opgeven wanneer u een cluster implementeert, raadpleegt u de Quickstart van Azure CLI.
Onderhoud
De service voert nodetool repair uit met reaper. Dit hulpprogramma wordt elke week uitgevoerd. Als u uw eigen service gebruikt voor een hybride implementatie, kunt u de reaper uitschakelen.
Statuscontrole van knooppunten bestaat uit:
- Controleer actief het lidmaatschap van elk knooppunt in de Cassandra-ring.
- Problemen met de infrastructuur automatisch detecteren en automitteren, zoals virtuele machine, netwerk, opslag, Linux en ondersteuning van softwarefouten.
- Proactief cpu-, schijf-, quorumverlies en andere problemen met resources bewaken.
- Er worden waar mogelijk mislukte knooppunten automatisch weergegeven en worden knooppunten handmatig weergegeven als reactie op automatisch gegenereerde waarschuwingen.
Ondersteuning
Azure Managed Instance voor Apache Cassandra biedt een SLA voor de beschikbaarheid van datacenters in een beheerd cluster. Als u problemen ondervindt met het gebruik van de service, dient u een ondersteuningsaanvraag in de Azure-portal in.
Onze ondersteuningsvoordelen zijn onder andere:
- Enig aanspreekpunt voor problemen met Cassandra-infrastructuur. U hoeft geen ondersteuningsverzoeken in te dienen bij IaaS-teams, zoals schijfbeheer, rekencapaciteit en netwerken, afzonderlijk.
- Pro-actief advies per e-mail over prestatieknelpunten, schaalgrootte en andere problemen met beperkingen in middelen.
- Ondersteuningsdekking van 24x7, inclusief automatisch gegenereerde incidenten voor ernstige storingsproblemen.
- Ondersteuning voor door de community goedgekeurde patches. Zie Patching.
- Interne ondersteuning voor Java JDK/JVM-engineeringteam.
- Linux-besturingssysteemondersteuning met beveiliging van software supply chain.
Belangrijk
Microsoft onderzoekt en diagnosticeert eventuele problemen die zijn gerapporteerd met behulp van een ondersteuningsaanvraag. Ondersteuning verhelpt of beperkt problemen waar mogelijk. U bent uiteindelijk verantwoordelijk voor elk gebruik op configuratieniveau van Apache Cassandra, waardoor CPU-, schijf- of netwerkproblemen optreden.
Voorbeelden van dergelijke problemen zijn:
- Inefficiënte querybewerkingen.
- Doorvoer die de capaciteit overschrijdt.
- Gegevens opnemen die de opslagcapaciteit overschrijden.
- Onjuiste configuratie-instellingen voor keyspace.
- Slechte strategie voor gegevensmodel of partitiesleutel.
Microsoft kan een ondersteuningsaanvraag onderzoeken en ontdekken dat de oorzaak van het probleem zich op het configuratieniveau van Apache Cassandra bevindt. Een dergelijk probleem komt niet van onderliggende aspecten op platformniveau die Azure onderhoudt. Ondersteuning biedt nog steeds aanbevelingen en richtlijnen voor herstel, of risicobeperking indien mogelijk, voordat ze de aanvraag sluiten.
U wordt aangeraden metrische gegevens in te schakelen en vertrouwd te raken met de integratie van Azure Monitor om veelvoorkomende problemen op toepassings-/configuratieniveau in Apache Cassandra te voorkomen, zoals eerder beschreven.
Waarschuwing
Met Azure Managed Instance voor Apache Cassandra kunt u ook nodetool en sstable opdrachten uitvoeren voor routine DBA-beheer. Zie DBA-opdrachten voor Azure Managed Instance voor Apache Cassandra voor meer informatie.
Sommige van deze opdrachten kunnen het Cassandra-cluster stabiliseren. U moet deze opdrachten zorgvuldig uitvoeren en nadat deze zijn getest in niet-productieomgevingen. Gebruik waar mogelijk eerst een --dry-run optie. Microsoft biedt geen SLA of ondersteuning voor problemen met het uitvoeren van opdrachten die de standaarddatabaseconfiguratie of -tabellen wijzigen.
Back-up en terugzetten
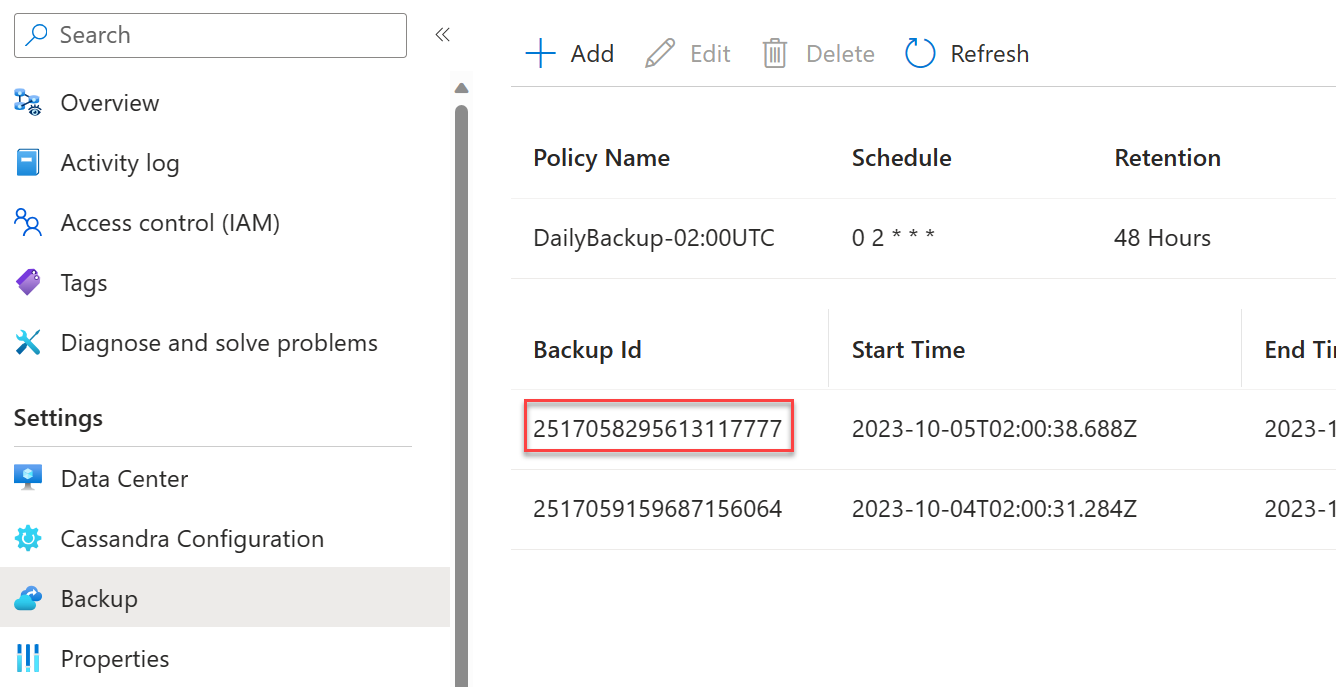
Back-ups van momentopnamen zijn standaard ingeschakeld en worden elke 24 uur gemaakt. Back-ups worden opgeslagen in een intern Azure Blob Storage-account en worden maximaal twee dagen bewaard (48 uur). Er zijn geen kosten verbonden aan de eerste twee back-ups. Er worden extra back-ups in rekening gebracht. Zie prijzen. Als u het back-upinterval of de bewaarperiode wilt wijzigen, kunt u het beleid bewerken in Azure Portal:

Als u wilt herstellen vanuit een bestaande back-up, dient u een ondersteuningsaanvraag in de Azure-portal in. Wanneer u een ondersteuningsaanvraag indient, moet u het volgende doen:
Geef de back-up-id op vanuit de portal voor de back-up die u wilt herstellen. U vindt deze id in Azure Portal:
Laat ons weten of het broncentrum is verwijderd. Dit is belangrijk om het juiste back-upaccount te identificeren waaruit moet worden hersteld.
Als u het hele cluster niet hoeft te herstellen, geeft u de keyspace en tabel op, indien van toepassing, die moet worden hersteld.
Geef aan of u de back-up wilt herstellen in het bestaande cluster of in een nieuw cluster.
Als u wilt herstellen naar een nieuw cluster, moet u eerst het nieuwe cluster maken. Zorg ervoor dat het doelcluster overeenkomt met het broncluster in termen van het aantal datacenters. Controleer of het bijbehorende datacenter hetzelfde aantal knooppunten heeft. U kunt ook bepalen of u de referenties in het nieuwe doelcluster wilt behouden. U kunt ook toestaan dat herstel de gebruikersnaam en het wachtwoord overschrijft met wat oorspronkelijk is aangemaakt.
U kunt ook beslissen of u
system_authkeyspace wilt behouden in het nieuwe doelcluster of toestaan dat de herstelbewerking het overschrijft met gegevens uit de back-up. Desystem_authkeyspace in Cassandra bevat autorisatie- en interne verificatiegegevens, waaronder rollen, rolmachtigingen en wachtwoorden. Het standaardherstelproces overschrijft desystem_authkeyspace.
Notitie
De tijd die nodig is om te reageren op een aanvraag om een back-up te herstellen, is afhankelijk van de ernst van de ondersteuningscase die u opgeeft, de SLA voor reactietijd en de hoeveelheid gegevens die u wilt herstellen. We bieden geen SLA voor tijd om de herstelbewerking te voltooien. Deze waarde is tijd afhankelijk van het volume van de gegevens die worden hersteld.
Waarschuwing
Back-ups zijn bedoeld voor onbedoelde verwijderingsscenario's en zijn niet geografisch redundant. We raden geen back-ups aan voor gebruik als noodherstelstrategie (DR) voor regionale storingen. Om te beschermen tegen storingen in de hele regio, raden we een implementatie van meerdere regio's aan. Voor meer informatie, zie de quickstart voor implementaties in meerdere regio's.
Beveiliging
Azure Managed Instance voor Apache Cassandra biedt veel ingebouwde, expliciete beveiligingscontroles en -functies:
- Versterkte Linux virtuele machine afbeeldingen met een gecontroleerde toeleveringsketen.
- Monitoring van Common Vulnerability & Exposure (CVE) op het niveau van het besturingssysteem.
- Certificaatrotatie voor zowel Apache Cassandra- als Prometheus-software die wordt gehost op de beheerde virtuele machines.
- Actief scannen op beveiligingsproblemen.
- Actieve virusscans.
- Veilige codeerpraktijken.
Zie Beveiliging in Azure Managed Instance voor Apache Cassandra voor meer informatie over beveiligingsfuncties.
Hybride ondersteuning
Wanneer een hybride cluster is geconfigureerd, komen geautomatiseerde reaper-activiteiten die in de service worden uitgevoerd ten goede aan het hele cluster. Dit aspect omvat datacenters die niet door de service worden ingericht. Het is uw verantwoordelijkheid om uw on-premises of extern gehoste datacenter te onderhouden.