Azure Machine Learning-gegevenssets maken op basis van Azure Open Datasets
Let op
Dit artikel verwijst naar CentOS, een Linux-distributie met de EOL-status (End Of Life). Overweeg uw gebruik en planning dienovereenkomstig. Zie de Richtlijnen voor het einde van de levensduur van CentOS voor meer informatie.
In dit artikel leert u hoe u gecureerde verrijkingsgegevens kunt overbrengen naar uw lokale of externe machine learning-experimenten met Azure Machine Learning-gegevenssets en Azure Open Datasets.
Door een Azure Machine Learning-gegevensset te maken, maakt u een verwijzing naar de locatie van de gegevensbron, samen met een kopie van de metagegevens. Omdat gegevenssets lazily worden geëvalueerd en de gegevens op de bestaande locatie blijven staan, kunt u
- Er worden geen extra opslagkosten in rekening gebracht.
- Riskeer niet onbedoeld het wijzigen van uw oorspronkelijke gegevensbronnen.
- Verbeter de prestaties van ml-werkstromen.
Als u wilt weten waar gegevenssets passen in de algemene werkstroom voor gegevenstoegang van Azure Machine Learning, raadpleegt u het artikel Over veilige toegang tot gegevens .
Azure Open Datasets zijn gecureerde openbare gegevenssets die u kunt gebruiken om scenariospecifieke functies toe te voegen om uw voorspellende oplossingen te verrijken en hun nauwkeurigheid te verbeteren. Zie de catalogus Met open gegevenssets voor gegevens uit het openbare domein die u kunnen helpen bij het trainen van machine learning-modellen, zoals:
- weer
- volkstelling
- vakantie
- openbare veiligheid
- locatie
Open Datasets bevinden zich in de cloud op Microsoft Azure en zijn opgenomen in zowel de Azure Machine Learning Python SDK als de Azure Machine Learning-studio.
Vereisten
Voor dit artikel hebt u het volgende nodig:
Een Azure-abonnement. Als u nog geen abonnement hebt, maakt u een gratis account voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
De Azure Machine Learning SDK voor Python is geïnstalleerd, waaronder het
azureml-datasetspakket.- Maak een Azure Machine Learning-rekenproces. Dit is een volledig geconfigureerde en beheerde ontwikkelomgeving met geïntegreerde notebooks en de SDK die al is geïnstalleerd.
OF
- Werk aan uw eigen Python-omgeving en installeer de SDK zelf met deze instructies.
Notitie
Sommige gegevenssetklassen hebben afhankelijkheden van het pakket azureml-dataprep, dat alleen compatibel is met 64-bits Python. Voor Linux-gebruikers worden deze klassen alleen ondersteund op de volgende distributies: Red Hat Enterprise Linux (7, 8), Ubuntu (14.04, 16.04, 18.04), Fedora (27, 28), Debian (8, 9) en CentOS (7).
Gegevenssets maken met de SDK
Als u Azure Machine Learning-gegevenssets wilt maken via Azure Open Datasets-klassen in de Python SDK, moet u ervoor zorgen dat u het pakket hebt geïnstalleerd met pip install azureml-opendatasets. Elke discrete gegevensset wordt vertegenwoordigd door een eigen klasse in de SDK en bepaalde klassen zijn beschikbaar als een Azure Machine Learning TabularDataset- FileDatasetof beide. Raadpleeg de referentiedocumentatie voor een volledige lijst met opendatasets klassen.
U kunt bepaalde opendatasets klassen ophalen als een TabularDataset of FileDataset, waarmee u de bestanden rechtstreeks kunt bewerken en/of downloaden. Andere klassen kunnen alleen een gegevensset ophalen met behulp van de get_tabular_dataset() of get_file_dataset() functies uit de Datasetklasse in de Python SDK.
De volgende code laat zien dat de MNIST-klasse opendatasets een TabularDataset of FileDataset.
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
In dit voorbeeld is de opendatasets diabetesklasse alleen beschikbaar als een TabularDataset, vandaar het gebruik van get_tabular_dataset().
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Gegevenssets registreren
Registreer een Azure Machine Learning-gegevensset bij uw werkruimte, zodat u ze met anderen kunt delen en opnieuw kunt gebruiken in experimenten in uw werkruimte. Wanneer u een Azure Machine Learning-gegevensset registreert die is gemaakt op basis van Open Datasets, worden er geen gegevens onmiddellijk gedownload, maar worden de gegevens later geopend wanneer ze worden aangevraagd (bijvoorbeeld tijdens de training) vanaf een centrale opslaglocatie.
Als u uw gegevenssets wilt registreren bij een werkruimte, gebruikt u de register() methode.
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Gegevenssets maken met de studio
U kunt ook Azure Machine Learning-gegevenssets maken vanuit Azure Open Datasets met de Azure Machine Learning-studio, een geconsolideerde webinterface met machine learning-hulpprogramma's voor het uitvoeren van data science-scenario's voor gegevenswetenschapsbeoefenaars van alle vaardigheidsniveaus.
Notitie
Gegevenssets die zijn gemaakt via Azure Machine Learning-studio worden automatisch geregistreerd bij de werkruimte.
Selecteer in uw werkruimte het tabblad Gegevenssets onder Assets. Selecteer in het vervolgkeuzemenu Gegevensset maken de optie Gegevenssets openen.
Selecteer een gegevensset door de tegel te selecteren. (U kunt filteren met behulp van de zoekbalk.) Selecteer Volgende.
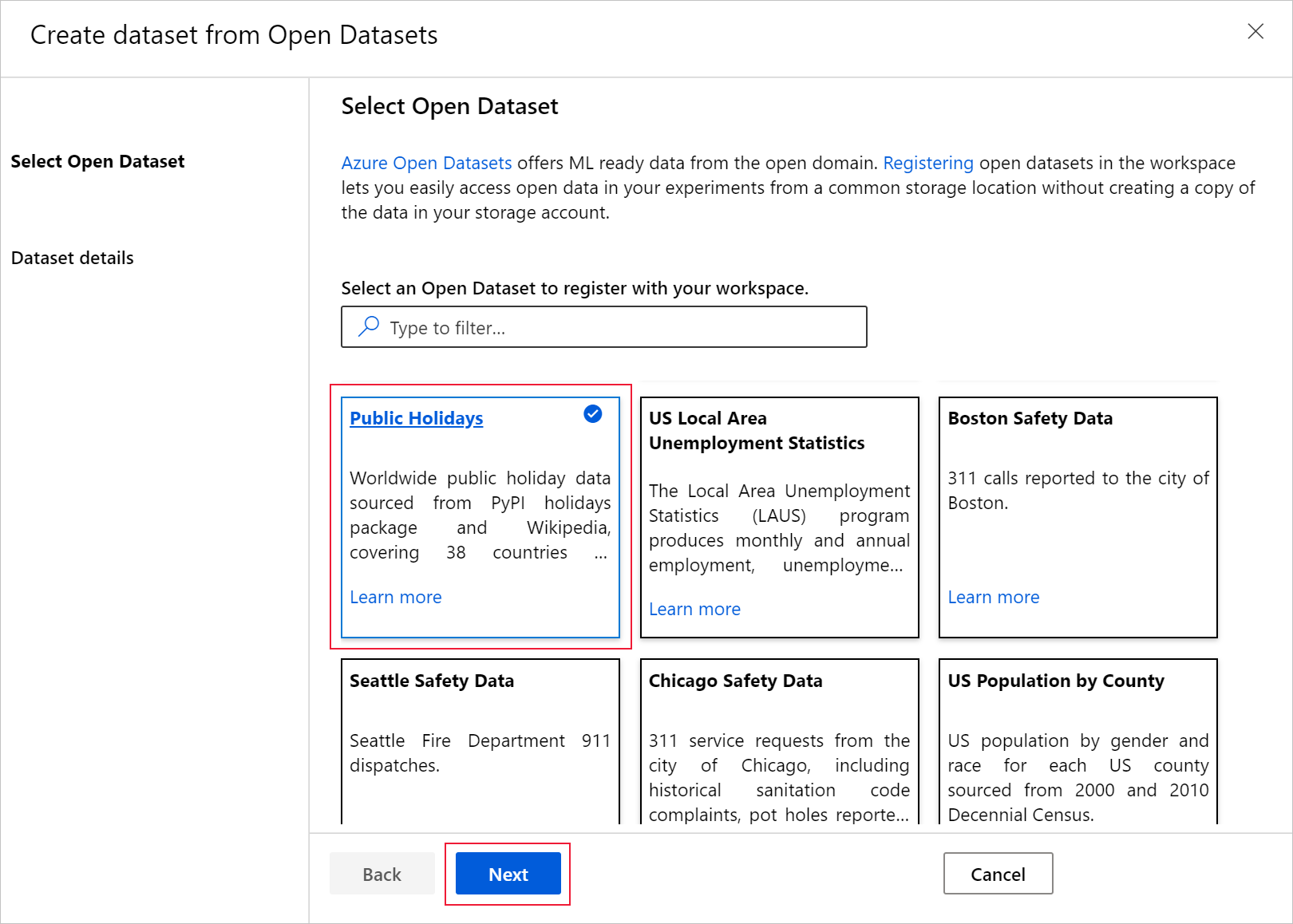
Kies een naam waaronder u de gegevensset wilt registreren en filter eventueel de gegevens met behulp van de beschikbare filters. In dit geval filtert u voor de gegevensset openbare feestdagen de periode op één jaar en de landcode alleen naar de VS. Zie de Azure Open Datasets Catalog voor gegevensdetails, zoals veldbeschrijvingen en datumbereiken. Selecteer Maken.
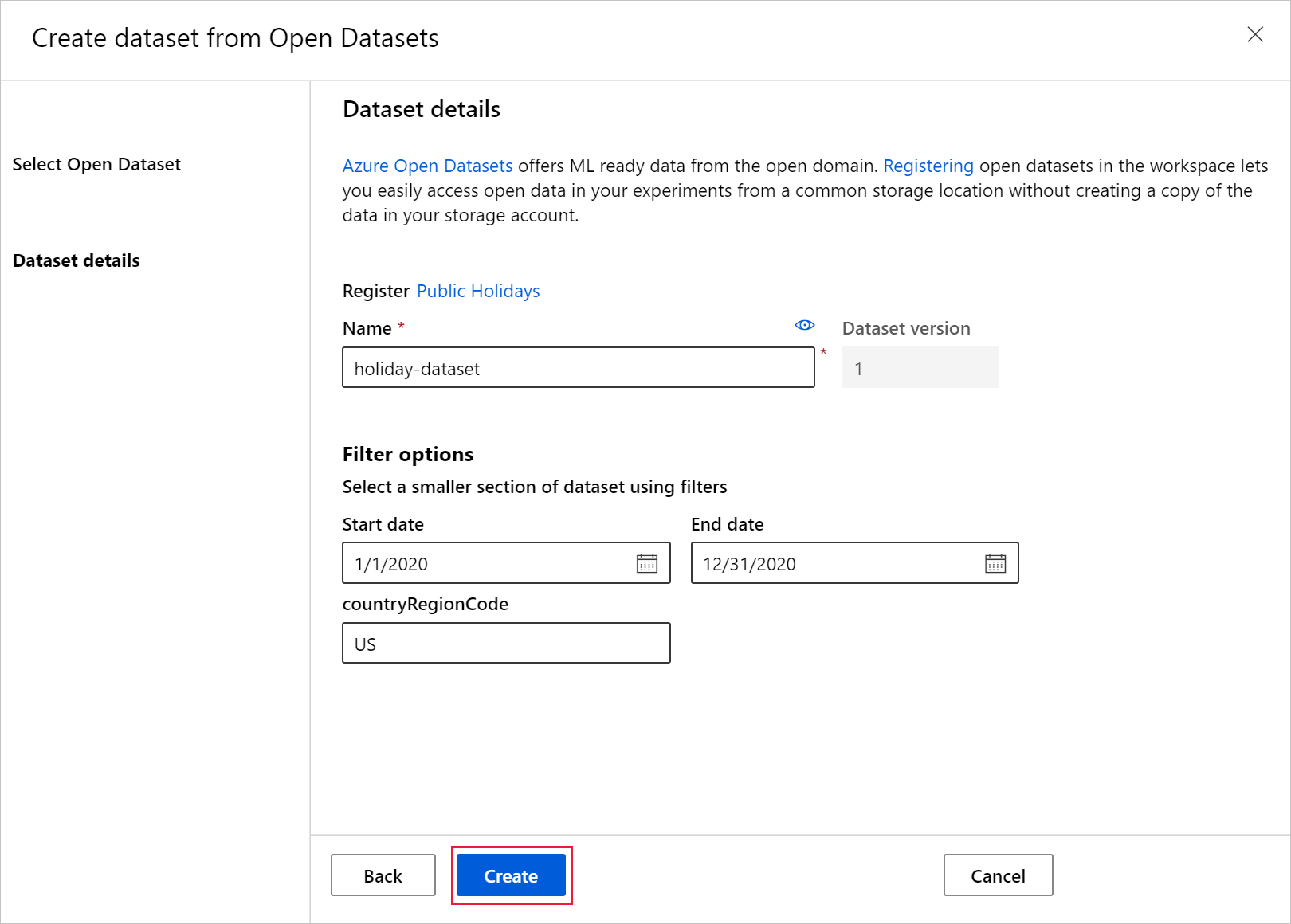
De gegevensset is nu beschikbaar in uw werkruimte onder Gegevenssets. U kunt deze op dezelfde manier gebruiken als andere gegevenssets die u hebt gemaakt.
Toegang tot gegevenssets voor uw experimenten
Gebruik uw gegevenssets in uw machine learning-experimenten voor het trainen van ML-modellen. Meer informatie over het trainen met gegevenssets.
Voorbeeldnotebooks
Zie deze voorbeeldnotitieblokken voor voorbeelden en demonstraties van de functionaliteit open gegevenssets.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor