Concepten van vaardighedensets in Azure AI Search
Dit artikel is bedoeld voor ontwikkelaars die meer inzicht nodig hebben in de concepten en samenstelling van vaardighedensets en gaan ervan uit dat ze vertrouwd zijn met de concepten op hoog niveau van AI-verrijking.
Een vaardighedenset is een herbruikbare resource in Azure AI Search die is gekoppeld aan een indexeerfunctie. Het bevat een of meer vaardigheden die ingebouwde AI of externe aangepaste verwerking aanroepen voor documenten die zijn opgehaald uit een externe gegevensbron.
In het volgende diagram ziet u de basisgegevensstroom van de uitvoering van vaardighedensets.
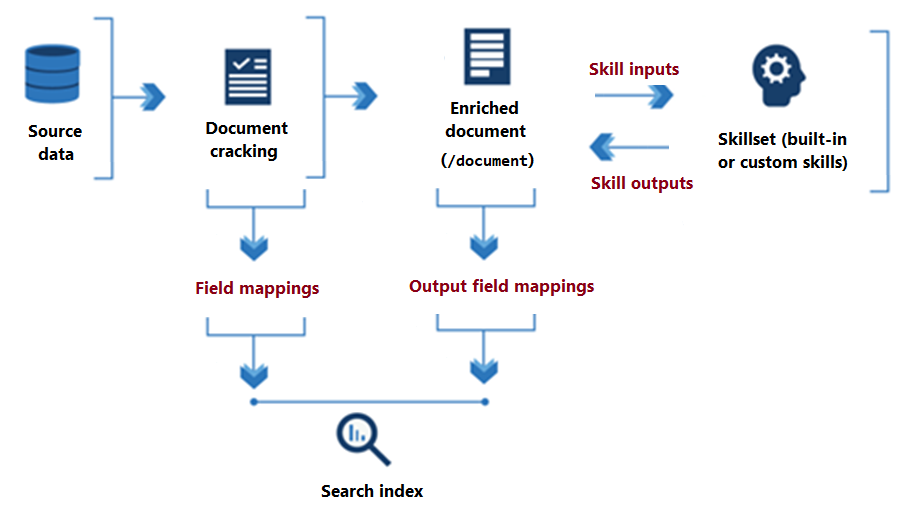
Vanaf het begin van de verwerking van vaardighedensets tot de conclusie, lezen vaardigheden van en schrijven naar een verrijkt document. In eerste instantie is een verrijkt document alleen de onbewerkte inhoud die is geëxtraheerd uit een gegevensbron (geformuleerd als het "/document" hoofdknooppunt). Bij elke uitvoering van vaardigheden krijgt het verrijkte document structuur en inhoud als vaardigheid de uitvoer als knooppunten in de grafiek schrijft.
Nadat de uitvoering van de vaardighedenset is voltooid, vindt de uitvoer van een verrijkt document de weg naar een index via toewijzingen van uitvoervelden. Alle onbewerkte inhoud die u intact wilt overbrengen, van bron naar een index, wordt gedefinieerd via veldtoewijzingen.
Als u verrijking wilt configureren, geeft u instellingen op in een vaardighedenset en indexeerfunctie.
Definitie set vaardigheden
Een vaardighedenset is een matrix van een of meer vaardigheden die een verrijking uitvoeren, zoals het vertalen van tekst of OCR in een afbeeldingsbestand. Vaardigheden kunnen de ingebouwde vaardigheden van Microsoft zijn of aangepaste vaardigheden voor het verwerken van logica die u extern host. Een vaardighedenset produceert verrijkte documenten die worden gebruikt tijdens het indexeren of projecteren naar een kennisarchief.
Vaardigheden hebben een context, invoer en uitvoer:
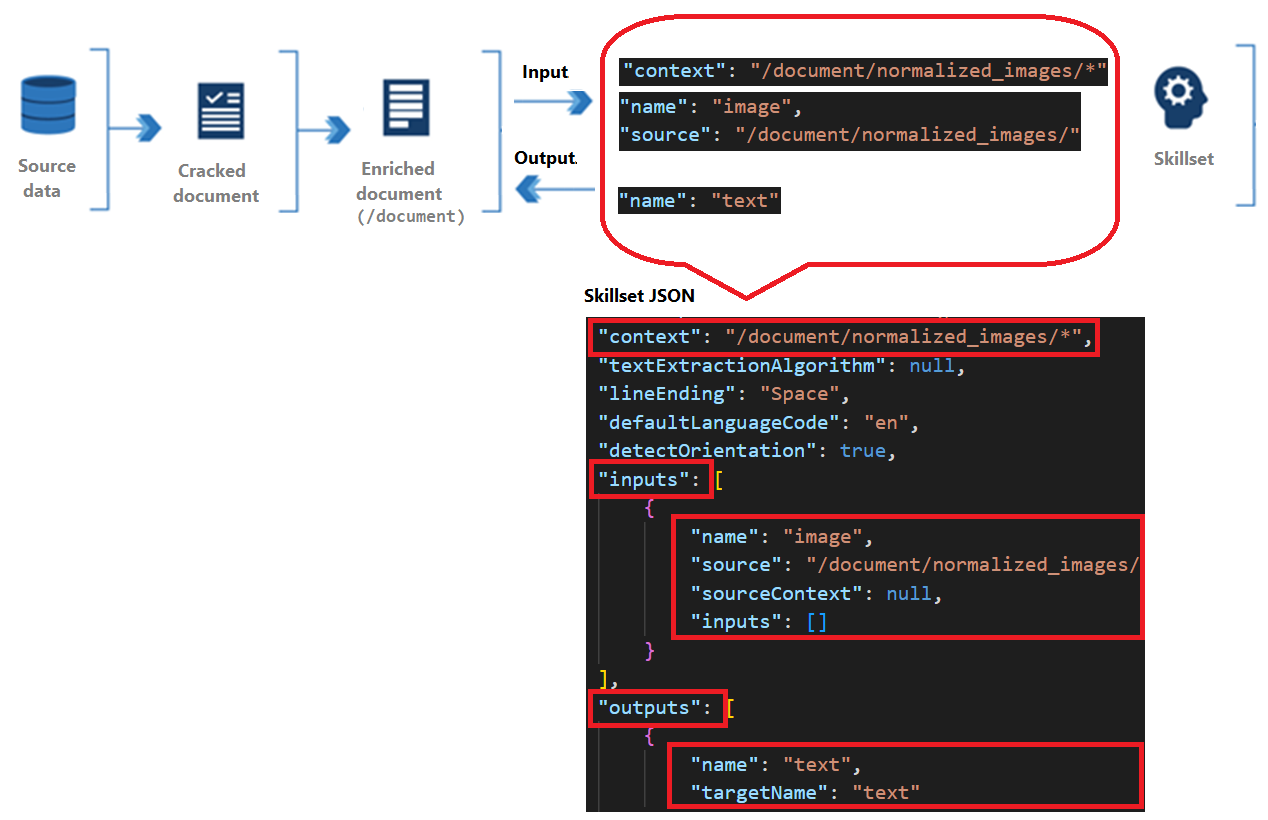
Context verwijst naar het bereik van de bewerking, die één keer per document of eenmaal voor elk item in een verzameling kan zijn.
Invoer is afkomstig van knooppunten in een verrijkt document, waarbij een 'bron' en 'naam' een bepaald knooppunt identificeren.
Uitvoer wordt als een nieuw knooppunt teruggestuurd naar het verrijkte document. Waarden zijn de 'naam' van het knooppunt en de inhoud van het knooppunt. Als een knooppuntnaam wordt gedupliceerd, kunt u een doelnaam instellen voor ondubbelzinnigheid.
Vaardigheidscontext
Elke vaardigheid heeft een context, die het hele document (/document) of een knooppunt lager in de structuur (/document/countries/*) kan zijn. Een context bepaalt:
Het aantal keren dat de vaardigheid wordt uitgevoerd, over één waarde (één keer per veld, per document) of voor contextwaarden van het typeverzameling, waarbij het toevoegen van een
/*vaardigheid resulteert in aanroep, één keer voor elk exemplaar in de verzameling.Uitvoerdeclaratie, of waar in de verrijkingsstructuur de vaardigheidsuitvoer wordt toegevoegd. Uitvoer wordt altijd toegevoegd aan de structuur als onderliggende elementen van het contextknooppunt.
Vorm van de invoer. Voor verzamelingen met meerdere niveaus heeft het instellen van de context op de bovenliggende verzameling invloed op de vorm van de invoer voor de vaardigheid. Als u bijvoorbeeld een verrijkingsstructuur hebt met een lijst met landen/regio's, elk verrijkt met een lijst met staten met een lijst met postcodes, hoe u de context instelt, bepaalt hoe de invoer wordt geïnterpreteerd.
Context Invoer Vorm van invoer Vaardigheid aanroepen /document/countries/*/document/countries/*/states/*/zipcodes/*Een lijst met alle postcodes in het land/de regio Eenmaal per land/regio /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Een lijst met postcodes in de staat Eenmaal per combinatie van land/regio en staat
Vaardigheidsafhankelijkheden
Vaardigheden kunnen onafhankelijk en parallel worden uitgevoerd, of opeenvolgend als u de uitvoer van de ene vaardigheid in een andere vaardigheid invoert. In het volgende voorbeeld ziet u twee ingebouwde vaardigheden die op volgorde worden uitgevoerd:
Vaardigheid #1 is een vaardigheid tekst splitsen die de inhoud van het bronveld 'reviews_text' als invoer accepteert en die inhoud splitst in 'pagina's' van 5000 tekens als uitvoer. Het splitsen van grote tekst in kleinere segmenten kan betere resultaten opleveren voor vaardigheden zoals gevoelsdetectie.
Vaardigheid #2 is een vaardigheid gevoelsdetectie accepteert 'pagina's' als invoer en produceert een nieuw veld met de naam 'Sentiment' als uitvoer dat de resultaten van sentimentanalyse bevat.
U ziet hoe de uitvoer van de eerste vaardigheid ('pagina's') wordt gebruikt in sentimentanalyse, waarbij '/document/reviews_text/pages/*' zowel de context als de invoer is. Zie How to reference enrichments (Verrijkingen verwijzen) voor meer informatie over padformulering.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Verrijkingsstructuur
Een verrijkt document is een tijdelijke, structuurachtige gegevensstructuur die is gemaakt tijdens de uitvoering van de vaardighedenset waarmee alle wijzigingen worden verzameld die zijn geïntroduceerd via vaardigheden. Samen worden verrijkingen weergegeven als een hiërarchie van adresseerbare knooppunten. Knooppunten bevatten ook niet-aangepaste velden die in de exacte bewoordingen van de externe gegevensbron worden doorgegeven.
Er bestaat een verrijkt document voor de duur van de uitvoering van de vaardighedenset, maar kan in de cache worden opgeslagen of naar een kennisarchief worden verzonden.
In eerste instantie is een verrijkt document simpelweg de inhoud die is geëxtraheerd uit een gegevensbron tijdens het kraken van het document, waarbij tekst en afbeeldingen uit de bron worden geëxtraheerd en beschikbaar worden gesteld voor taal- of afbeeldingsanalyse.
De eerste inhoud is metagegevens en het hoofdknooppunt (document/content). Het hoofdknooppunt is meestal een heel document of een genormaliseerde afbeelding die tijdens het kraken van een document uit een gegevensbron wordt geëxtraheerd. De manier waarop deze wordt geformuleerd in een verrijkingsstructuur, varieert voor elk gegevensbrontype. In de volgende tabel ziet u de status van een document dat in de verrijkingspijplijn wordt ingevoerd voor verschillende ondersteunde gegevensbronnen:
| Gegevensbron\parseermodus | Standaardinstelling | JSON, JSON-lijnen en CSV |
|---|---|---|
| Blob Storage | /document/inhoud /document/normalized_images/* ... |
/document/{key1} /document/{key2} ... |
| Azure SQL | /document/{column1} /document/{column2} ... |
N.v.t. |
| Azure Cosmos DB | /document/{key1} /document/{key2} ... |
N.v.t. |
Wanneer vaardigheden worden uitgevoerd, wordt uitvoer toegevoegd aan de verrijkingsstructuur als nieuwe knooppunten. Als de uitvoering van vaardigheden het hele document heeft, worden knooppunten toegevoegd op het eerste niveau onder de hoofdmap.
Knooppunten kunnen worden gebruikt als invoer voor downstreamvaardigheden. Vaardigheden die bijvoorbeeld inhoud maken, zoals vertaalde tekenreeksen, kunnen invoer worden voor vaardigheden die entiteiten herkennen of sleuteltermen extraheren.
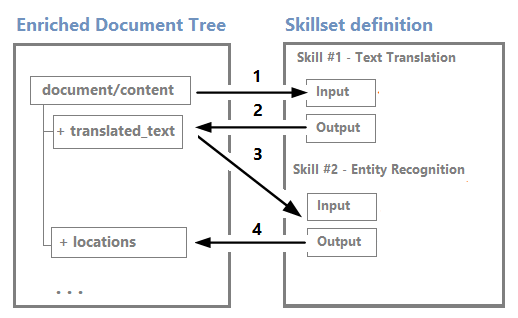
Hoewel u een verrijkingsstructuur kunt visualiseren en ermee kunt werken via de visuele editor voor foutopsporingssessies, is dit meestal een interne structuur.
Verrijkingen kunnen onveranderbaar zijn: na het maken kunnen knooppunten niet worden bewerkt. Naarmate uw vaardighedensets complexer worden, moet uw verrijkingsstructuur, maar niet alle knooppunten in de verrijkingsstructuur deze naar de index of het kennisarchief brengen.
U kunt selectief een subset van de verrijkingsuitvoer behouden, zodat u alleen behoudt wat u van plan bent te gebruiken. De uitvoerveldtoewijzingen in de definitie van de indexeerfunctie bepalen welke inhoud daadwerkelijk wordt opgenomen in de zoekindex. Als u een kennisarchief maakt, kunt u uitvoer toewijzen aan shapes die zijn toegewezen aan projecties.
Notitie
Met de indeling van de verrijkingsstructuur kan de verrijkingspijplijn metagegevens koppelen aan zelfs primitieve gegevenstypen. De metagegevens zijn geen geldig JSON-object, maar kunnen worden geprojecteerd in een geldige JSON-indeling in projectiedefinities in een kennisarchief. Zie Shaper-vaardigheid voor meer informatie.
Definitie van de indexeerfunctie
Een indexeerfunctie heeft eigenschappen en parameters die worden gebruikt om de uitvoering van de indexeerfunctie te configureren. Onder deze eigenschappen zijn toewijzingen waarmee het gegevenspad wordt ingesteld op velden in een zoekindex.

Er zijn twee sets toewijzingen:
"fieldMappings" wijst een bronveld toe aan een zoekveld.
'outputFieldMappings' wijst een knooppunt in een verrijkt document toe aan een zoekveld.
De eigenschap sourceFieldName geeft een veld in uw gegevensbron of een knooppunt in een verrijkingsstructuur op. De eigenschap targetFieldName geeft het zoekveld op in een index die de inhoud ontvangt.
Voorbeeld van verrijking
In dit voorbeeld wordt uitgelegd hoe een verrijkingsstructuur zich ontwikkelt door het uitvoeren van vaardigheden met behulp van conceptuele diagrammen.
In dit voorbeeld ziet u ook:
- Hoe de context en invoer van een vaardigheid werken om te bepalen hoe vaak een vaardigheid wordt uitgevoerd
- Welke vorm van de invoer is gebaseerd op de context
In dit voorbeeld bevatten bronvelden uit een CSV-bestand klantbeoordelingen over hotels ('reviews_text') en classificaties ('reviews_rating'). De indexeerfunctie voegt metagegevensvelden toe uit Blob Storage en vaardigheden voegen vertaalde tekst, gevoelsscores en sleuteltermdetectie toe.
In het voorbeeld van hotelbeoordelingen vertegenwoordigt een 'document' in het verrijkingsproces één hotelbeoordeling.
Tip
U kunt een zoekindex en kennisarchief maken voor deze gegevens in Azure Portal of REST API's. U kunt ook Foutopsporingssessies gebruiken voor inzicht in de samenstelling van vaardighedensets, afhankelijkheden en effecten op een verrijkingsstructuur . Afbeeldingen in dit artikel worden opgehaald uit foutopsporingssessies.
Conceptueel ziet de eerste verrijkingsstructuur er als volgt uit:

Het hoofdknooppunt voor alle verrijkingen is "/document". Wanneer u met blobindexeerfuncties werkt, heeft het "/document" knooppunt onderliggende knooppunten van "/document/content" en "/document/normalized_images". Wanneer de gegevens CSV zijn, zoals in dit voorbeeld, worden de kolomnamen toegewezen aan knooppunten eronder "/document".
Vaardigheid 1: Vaardigheid splitsen
Wanneer broninhoud bestaat uit grote stukken tekst, is het handig om deze op te splitsen in kleinere onderdelen voor een grotere nauwkeurigheid van taal-, sentiment- en sleuteltermdetectie. Er zijn twee korrels beschikbaar: pagina's en zinnen. Een pagina bestaat uit ongeveer 5000 tekens.
Een vaardigheid voor het splitsen van tekst is doorgaans eerst in een vaardighedenset.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
Met de vaardigheidscontext van "/document/reviews_text", wordt de splitsvaardigheid eenmaal uitgevoerd voor de reviews_text. De uitvoer van de vaardigheid is een lijst waarin de reviews_text segmenten van 5000 tekens zijn onderverdeeld. De uitvoer van de splitsvaardigheid heet pages en wordt toegevoegd aan de verrijkingsstructuur. Met targetName de functie kunt u de naam van een vaardigheidsuitvoer wijzigen voordat u deze toevoegt aan de verrijkingsstructuur.
De verrijkingsstructuur heeft nu een nieuw knooppunt in de context van de vaardigheid. Dit knooppunt is beschikbaar voor elke vaardigheid, projectie of uitvoerveldtoewijzing.

Voor toegang tot een van de verrijkingen die door een vaardigheid aan een knooppunt zijn toegevoegd, is het volledige pad voor de verrijking nodig. Als u bijvoorbeeld de tekst van het pages knooppunt wilt gebruiken als invoer voor een andere vaardigheid, moet u deze opgeven als "/document/reviews_text/pages/*". Zie Referentieverrijkingen voor meer informatie over paden.
Vaardigheid 2 Taaldetectie
Hotelbeoordelingsdocumenten bevatten feedback van klanten, uitgedrukt in meerdere talen. De vaardigheid taaldetectie bepaalt welke taal wordt gebruikt. Het resultaat wordt vervolgens doorgegeven aan sleuteltermextractie en gevoelsdetectie (niet weergegeven), waarbij rekening wordt gehouden met taal bij het detecteren van sentiment en woordgroepen.
Hoewel de vaardigheid voor taaldetectie de derde vaardigheid (vaardigheid #3) is die is gedefinieerd in de vaardighedenset, is dit de volgende vaardigheid die moet worden uitgevoerd. Er zijn geen invoer nodig, zodat deze parallel met de vorige vaardigheid wordt uitgevoerd. Net als de gesplitste vaardigheid die eraan voorafging, wordt de vaardigheid voor taaldetectie ook één keer aangeroepen voor elk document. De verrijkingsstructuur heeft nu een nieuw knooppunt voor taal.

Vaardigheden #3 en #4 (sentimentanalyse en detectie van sleuteltermen)
Feedback van klanten weerspiegelt een reeks positieve en negatieve ervaringen. De vaardigheid voor sentimentanalyse analyseert de feedback en wijst een score toe aan een continuum negatief aan positieve getallen of neutraal als het gevoel niet is bepaald. Parallel aan sentimentanalyse identificeert en extraheert sleuteltermdetectie woorden en korte zinnen die gevolgschade lijken.
Gezien de context van /document/reviews_text/pages/*worden zowel sentimentanalyse als sleuteltermvaardigheden eenmaal aangeroepen voor elk van de items in de pages verzameling. De uitvoer van de vaardigheid is een knooppunt onder het bijbehorende pagina-element.
U moet nu de rest van de vaardigheden in de vaardighedenset kunnen bekijken en visualiseren hoe de structuur van verrijkingen blijft groeien met de uitvoering van elke vaardigheid. Sommige vaardigheden, zoals de samenvoegvaardigheid en de shaper-vaardigheid, maken ook nieuwe knooppunten, maar gebruiken alleen gegevens van bestaande knooppunten en maken geen nieuwe verrijkingen.

De kleuren van de verbindingslijnen in de bovenstaande structuur geven aan dat de verrijkingen zijn gemaakt door verschillende vaardigheden en dat de knooppunten afzonderlijk moeten worden aangepakt en geen deel uitmaken van het object dat wordt geretourneerd bij het selecteren van het bovenliggende knooppunt.
Vaardigheid 5 Shaper-vaardigheid
Als uitvoer een kennisarchief bevat, voegt u een Shaper-vaardigheid toe als laatste stap. De shaper-vaardigheid maakt gegevensshapes van knooppunten in een verrijkingsstructuur. U kunt bijvoorbeeld meerdere knooppunten samenvoegen in één shape. U kunt deze shape vervolgens projecteren als een tabel (knooppunten worden de kolommen in een tabel), waarbij de shape op naam wordt doorgegeven aan een tabelprojectie.
De Shaper-vaardigheid is eenvoudig om mee te werken, omdat deze zich richt op het vormgeven onder één vaardigheid. U kunt er ook voor kiezen om inline vorm te geven binnen afzonderlijke projecties. De Shaper-vaardigheid voegt geen verrijkingsstructuur toe of trekt deze niet af, zodat deze niet wordt gevisualiseerd. In plaats daarvan kunt u een Shaper-vaardigheid beschouwen als de middelen waarmee u de verrijkingsstructuur die u al hebt herstructureren. Conceptueel gezien is dit vergelijkbaar met het maken van weergaven uit tabellen in een database.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Volgende stappen
Met een inleiding en voorbeeld achter u kunt u proberen uw eerste vaardighedenset te maken met behulp van ingebouwde vaardigheden.