Indexeerfuncties in Azure AI Search
Een indexeerfunctie in Azure AI Search is een crawler waarmee tekstgegevens uit cloudgegevensbronnen worden geëxtraheerd en een zoekindex wordt gevuld met veld-naar-veldtoewijzingen tussen brongegevens en een zoekindex. Deze benadering wordt soms een 'pull-model' genoemd, omdat de zoekservice gegevens ophaalt zonder dat u code hoeft te schrijven waarmee gegevens aan een index worden toegevoegd.
Indexeerfuncties stimuleren ook de uitvoering van vaardigheden en AI-verrijking, waar u vaardigheden kunt configureren voor het integreren van extra verwerking van inhoud en route naar een index. Enkele voorbeelden zijn OCR over afbeeldingsbestanden, vaardigheid voor het splitsen van tekst voor gegevenssegmentering, tekstomzetting voor meerdere talen.
Indexeerfuncties richten zich op ondersteunde gegevensbronnen. Een indexeerfunctieconfiguratie specificeert een gegevensbron (oorsprong) en een zoekindex (doel). Verschillende bronnen, zoals Azure Blob Storage, hebben meer configuratie-eigenschappen die specifiek zijn voor dat inhoudstype.
U kunt indexeerfuncties op aanvraag of volgens een terugkerend schema voor gegevensvernieuwing uitvoeren dat zo vaak als elke vijf minuten wordt uitgevoerd. Frequentere updates vereisen een 'pushmodel' dat tegelijkertijd gegevens bijwerkt in zowel Azure AI Search als uw externe gegevensbron.
Een zoekservice voert één indexeertaak per zoekeenheid uit. Als u gelijktijdige verwerking nodig hebt, moet u ervoor zorgen dat u voldoende replica's hebt. Indexeerfuncties worden niet op de achtergrond uitgevoerd, dus u kunt meer querybeperking detecteren dan normaal als de service onder druk staat.
Indexeerscenario's en gebruiksvoorbeelden
U kunt een indexeerfunctie als enige manier gebruiken voor gegevensopname of in combinatie met andere technieken. De volgende tabel bevat een overzicht van de belangrijkste scenario's.
| Scenario | Strategie |
|---|---|
| Eén gegevensbron | Dit patroon is het eenvoudigst: één gegevensbron is de enige inhoudsprovider voor een zoekindex. De meeste ondersteunde gegevensbronnen bieden een vorm van wijzigingsdetectie, zodat de volgende indexeerfunctie het verschil ophaalt wanneer inhoud wordt toegevoegd of bijgewerkt in de bron. |
| Meerdere gegevensbronnen | Een indexeerfunctiespecificatie kan slechts één gegevensbron hebben, maar de zoekindex zelf kan inhoud van meerdere bronnen accepteren, waarbij elke indexeerfunctie nieuwe inhoud van een andere gegevensprovider brengt. Elke bron kan bijdragen aan het deel van volledige documenten of geselecteerde velden in elk document vullen. Zie Zelfstudie: Indexeren uit meerdere gegevensbronnen voor een beter overzicht van dit scenario. |
| Meerdere indexeerfuncties | Meerdere gegevensbronnen worden doorgaans gekoppeld aan meerdere indexeerfuncties als u runtimeparameters, de planning of veldtoewijzingen moet variëren. Uitschalen tussen regio's van Azure AI Search is een ander scenario. Mogelijk hebt u kopieën van dezelfde zoekindex in verschillende regio's. Als u inhoud van de zoekindex wilt synchroniseren, kunt u meerdere indexeerfuncties ophalen uit dezelfde gegevensbron, waarbij elke indexeerfunctie gericht is op een andere zoekindex in elke regio. Parallelle indexering van zeer grote gegevenssets vereist ook een strategie voor meerdere indexeerfuncties, waarbij elke indexeerfunctie zich richt op een subset van de gegevens. |
| Inhoudstransformatie | Indexeerfuncties stimuleren de uitvoering van vaardigheden en AI-verrijking. Inhoudstransformaties worden gedefinieerd in een vaardighedenset die u aan de indexeerfunctie koppelt. U kunt vaardigheden gebruiken om gegevenssegmentering en vectorisatie op te nemen. |
U moet van plan zijn om één indexeerfunctie te maken voor elke combinatie van doelindexen en gegevensbronnen. U kunt meerdere indexeerfuncties hebben die in dezelfde index worden geschreven en u kunt dezelfde gegevensbron voor meerdere indexeerfuncties opnieuw gebruiken. Een indexeerfunctie kan echter slechts één gegevensbron tegelijk verbruiken en kan slechts naar één index schrijven. Zoals in de volgende afbeelding wordt geïllustreerd, biedt één gegevensbron invoer aan één indexeerfunctie, die vervolgens één index vult:

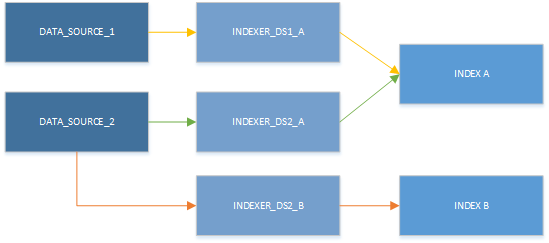
Hoewel u slechts één indexeerfunctie tegelijk kunt gebruiken, kunnen resources in verschillende combinaties worden gebruikt. Het belangrijkste voordeel van de volgende afbeelding is dat een gegevensbron kan worden gekoppeld aan meer dan één indexeerfunctie en dat meerdere indexeerfuncties naar dezelfde index kunnen schrijven.
Ondersteunde gegevensbronnen
Indexeerfuncties verkennen gegevensarchieven in Azure en buiten Azure.
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Azure-tabelopslag
- Azure SQL Managed Instance
- SQL Server op virtuele machines in Azure
- Azure Files (in preview)
- Azure MySQL (in preview)
- SharePoint in Microsoft 365 (in preview)
- Azure Cosmos DB voor MongoDB (in preview)
- Azure Cosmos DB voor Apache Gremlin (in preview)
Azure Cosmos DB voor Cassandra wordt niet ondersteund.
Indexeerfuncties accepteren platgemaakte rijsets, zoals een tabel of weergave, of items in een container of map. In de meeste gevallen wordt er één zoekdocument per rij, record of item gemaakt.
Indexeerfuncties voor externe gegevensbronnen kunnen worden gemaakt met behulp van standaardinternetverbindingen (openbaar) of versleutelde privéverbindingen wanneer u een gedeelde privékoppeling gebruikt. U kunt ook verbindingen instellen om te verifiëren met behulp van een beheerde identiteit. Zie Indexeertoegang tot inhoud die wordt beveiligd door de netwerkbeveiligingsfuncties van Azure en maak verbinding met een gegevensbron met behulp van een beheerde identiteit voor meer informatie over beveiligde verbindingen.
Fasen van indexering
Wanneer de index in eerste instantie leeg is, leest een indexeerfunctie alle gegevens in de tabel of container. Bij volgende uitvoeringen kan de indexeerfunctie meestal alleen de gegevens detecteren en ophalen die zijn gewijzigd. Voor blobgegevens is wijzigingsdetectie automatisch. Voor andere gegevensbronnen, zoals Azure SQL of Azure Cosmos DB, moet wijzigingsdetectie zijn ingeschakeld.
Voor elk document dat het ontvangt, implementeert of coördineert een indexeerfunctie meerdere stappen, van het ophalen van documenten tot een definitieve "handoff" zoekmachine voor indexering. Desgewenst bepaalt een indexeerfunctie ook de uitvoering en uitvoer van de vaardighedenset, ervan uitgaande dat er een vaardighedenset is gedefinieerd.

Fase 1: Document kraken
Document kraken is het proces van het openen van bestanden en het extraheren van inhoud. Inhoud op basis van tekst kan worden geëxtraheerd uit bestanden in een service, rijen in een tabel of items in een container of verzameling. Als u een vaardighedenset en afbeeldingsvaardigheden toevoegt, kan document kraken ook afbeeldingen extraheren en in de wachtrij plaatsen voor afbeeldingsverwerking.
Afhankelijk van de gegevensbron probeert de indexeerfunctie verschillende bewerkingen uit om mogelijk indexeerbare inhoud te extraheren:
Wanneer het document een bestand is met ingesloten afbeeldingen, zoals een PDF, extraheert de indexeerfunctie tekst, afbeeldingen en metagegevens. Indexeerfuncties kunnen bestanden openen vanuit Azure Blob Storage, Azure Data Lake Storage Gen2 en SharePoint.
Wanneer het document een record is in Azure SQL, haalt de indexeerfunctie niet-binaire inhoud op uit elk veld in elke record.
Wanneer het document een record is in Azure Cosmos DB, haalt de indexeerfunctie niet-binaire inhoud op uit velden en subvelden uit het Azure Cosmos DB-document.
Fase 2: Veldtoewijzingen
Een indexeerfunctie extraheert tekst uit een bronveld en verzendt deze naar een doelveld in een index of kennisarchief. Wanneer veldnamen en gegevenstypen samenvallen, is het pad duidelijk. Mogelijk wilt u echter verschillende namen of typen in de uitvoer. In dat geval moet u de indexeerfunctie laten weten hoe u het veld kunt toewijzen.
Als u veldtoewijzingen wilt opgeven, voert u de bron- en doelvelden in de definitie van de indexeerfunctie in.
Veldtoewijzing vindt plaats na het kraken van documenten, maar vóór transformaties, wanneer de indexeerfunctie uit de brondocumenten leest. Wanneer u een veldtoewijzing definieert, wordt de waarde van het bronveld verzonden naar het doelveld zonder wijzigingen.
Fase 3: Uitvoering van vaardighedenset
De uitvoering van een vaardighedenset is een optionele stap die ingebouwde of aangepaste AI-verwerking aanroept. Vaardighedensets kunnen optische tekenherkenning (OCR) of andere vormen van afbeeldingsanalyse toevoegen als de inhoud binair is. Vaardighedensets kunnen ook natuurlijke taalverwerking toevoegen. U kunt bijvoorbeeld tekstomzetting of sleuteltermextractie toevoegen.
Wat de transformatie ook is, de uitvoering van vaardighedensets is waar verrijking plaatsvindt. Als een indexeerfunctie een pijplijn is, kunt u een vaardighedenset beschouwen als een 'pijplijn binnen de pijplijn'.
Fase 4: Toewijzingen van uitvoervelden
Als u een vaardighedenset opneemt, moet u uitvoerveldtoewijzingen opgeven in de definitie van de indexeerfunctie. De uitvoer van een vaardighedenset wordt intern gemanifesteerd als een structuurstructuur die wordt aangeduid als een verrijkt document. Met uitvoerveldtoewijzingen kunt u selecteren welke onderdelen van deze structuur moeten worden toegewezen aan velden in uw index.
Ondanks de gelijkenis in namen, bouwen uitvoerveldtoewijzingen en veldtoewijzingen koppelingen van verschillende bronnen. Veldtoewijzingen koppelen de inhoud van het bronveld aan een doelveld in een zoekindex. Uitvoerveldtoewijzingen koppelen de inhoud van een intern verrijkt document (vaardigheidsuitvoer) aan doelvelden in de index. In tegenstelling tot veldtoewijzingen, die als optioneel worden beschouwd, is een uitvoerveldtoewijzing vereist voor alle getransformeerde inhoud die zich in de index moet bevinden.
In de volgende afbeelding ziet u een voorbeeld van een foutopsporingssessie voor indexeerfuncties van de indexeerfasen: document kraken, veldtoewijzingen, uitvoering van vaardighedensets en uitvoerveldtoewijzingen.

Basiswerkstroom
Indexeerfuncties kunnen functies bieden die uniek voor de gegevensbron zijn. In dit opzicht variëren bepaalde aspecten van de configuratie van de indexeerfunctie of de gegevensbron al naar gelang het type indexeerfunctie. Alle indexeerfuncties hebben echter dezelfde basissamenstelling en voor alle indexeerfuncties gelden dezelfde vereisten. Hieronder vindt u de stappen die voor alle indexeerfuncties gemeenschappelijk zijn.
Stap 1: een gegevensbron maken
Indexeerfuncties vereisen een gegevensbronobject dat een verbindingsreeks en mogelijk referenties biedt. Gegevensbronnen zijn onafhankelijke objecten. Meerdere indexeerfuncties kunnen hetzelfde gegevensbronobject gebruiken om meer dan één index tegelijk te laden.
U kunt een gegevensbron maken met behulp van een van deze methoden:
- Selecteer in Azure Portal op het tabblad Gegevensbronnen van uw zoekservicepagina's de optie Gegevensbron toevoegen om de definitie van de gegevensbron op te geven.
- Met behulp van Azure Portal voert de wizard Gegevens importeren een gegevensbron uit.
- Roep met behulp van de REST API's gegevensbron maken aan.
- Met behulp van de Azure SDK voor .NET roept u de klasse SearchIndexerDataSourceConnection aan
Stap 2: een index maken
Een indexeerfunctie automatiseert bepaalde taken met betrekking tot de opname van gegevens, maar het maken van een index behoort hier niet toe. Als vereiste moet u een vooraf gedefinieerde index hebben die overeenkomende doelvelden bevat voor bronvelden in uw externe gegevensbron. Velden moeten overeenkomen op naam en gegevenstype. Zo niet, dan kunt u veldtoewijzingen definiëren om de koppeling tot stand te brengen.
Zie Een index maken voor meer informatie.
Stap 3: de indexeerfunctie maken en uitvoeren (of plannen)
Een indexeerfunctiedefinitie bestaat uit eigenschappen die de indexeerfunctie uniek identificeren, opgeven welke gegevensbron en index moeten worden gebruikt, en andere configuratieopties bieden die invloed hebben op het gedrag van de uitvoeringstijd, waaronder of de indexeerfunctie op aanvraag of volgens een schema wordt uitgevoerd.
Fouten of waarschuwingen over gegevenstoegang of validatie van vaardighedensets treden op tijdens de uitvoering van de indexeerfunctie. Totdat de uitvoering van de indexeerfunctie wordt gestart, zijn afhankelijke objecten, zoals gegevensbronnen, indexen en vaardighedensets passief voor de zoekservice.
Zie Een indexeerfunctie maken voor meer informatie
Nadat de eerste indexeerfunctie is uitgevoerd, kunt u deze op aanvraag opnieuw uitvoeren of een planning instellen.
U kunt de status van de indexeerfunctie controleren in de portal of via de Status-API van De indexeerfunctie ophalen. U moet ook query's uitvoeren op de index om te controleren of het resultaat is wat u verwacht.
Indexeerfuncties hebben geen toegewezen verwerkingsbronnen. Op basis hiervan kan de status van indexeerfuncties worden weergegeven als niet-actief voordat ze worden uitgevoerd (afhankelijk van andere taken in de wachtrij) en de uitvoeringstijden zijn mogelijk niet voorspelbaar. Andere factoren definiëren ook de prestaties van de indexeerfunctie, zoals documentgrootte, documentcomplexiteit, afbeeldingsanalyse.
Volgende stappen
Nu u kennis hebt gemaakt met indexeerfuncties, is een volgende stap het controleren van de eigenschappen en parameters van de indexeerfunctie, planning en bewaking van indexeerfuncties. U kunt ook terugkeren naar de lijst met ondersteunde gegevensbronnen voor meer informatie over een specifieke bron.