Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure AI Zoeken biedt ondersteuning voor het importeren, analyseren en indexeren van gegevens uit meerdere gegevensbronnen in één geconsolideerde zoekindex.
In deze C#-zelfstudie wordt de Azure.Search.Documents-clientbibliotheek in de Azure SDK voor .NET gebruikt om voorbeeldgegevens van hotels te indexeren vanuit een Azure Cosmos DB-exemplaar. Vervolgens voegt u de gegevens samen met hotelgegevens die zijn opgehaald uit Azure Blob Storage-documenten. Het resultaat is een gecombineerde index voor hotelzoekopdrachten met hoteldocumenten, met kamers als complexe gegevenstypen.
In deze handleiding leert u:
- Voorbeeldgegevens uploaden naar gegevensbronnen
- De documentsleutel identificeren
- De index definiëren en maken
- Hotelgegevens uit Azure Cosmos DB indexeren
- Gegevens van hotelkamers samenvoegen vanuit Blob Storage
Overzicht
In deze zelfstudie wordt gebruikgemaakt van Azure.Search.Documents om meerdere indexeerfuncties te maken en uit te voeren. U uploadt voorbeeldgegevens naar twee Azure-gegevensbronnen en configureert een indexeerfunctie die uit beide bronnen wordt opgehaald om één zoekindex te vullen. De twee gegevenssets moeten een gemeenschappelijke waarde hebben om de samenvoeging te ondersteunen. In deze handleiding is dat veld een ID. Zolang er een algemeen veld is ter ondersteuning van de toewijzing, kan een indexeerfunctie gegevens uit verschillende resources samenvoegen: gestructureerde gegevens uit Azure SQL, ongestructureerde gegevens uit Blob Storage of een combinatie van ondersteunde gegevensbronnen in Azure.
Een voltooide versie van de code in deze zelfstudie vindt u in het volgende project:
Vereisten
- Een Azure-account met een actief abonnement. Gratis een account maken
- Een Azure Cosmos DB voor NoSQL-account.
- Een Azure Storage-account.
- Een Azure AI Zoeken-service.
- Visual Studio.
Notitie
U kunt een gratis zoekservice gebruiken voor deze zelfstudie. De gratis laag beperkt u tot drie indexen, drie indexeerfuncties en drie gegevensbronnen. In deze zelfstudie wordt één exemplaar van elk onderdeel gemaakt. Voordat u begint, moet u ervoor zorgen dat u ruimte hebt voor uw service om de nieuwe resources te accepteren.
Services voorbereiden
In deze zelfstudie wordt Gebruikgemaakt van Azure AI Zoeken voor indexering en query's, Azure Cosmos DB voor de eerste gegevensset en Azure Blob Storage voor de tweede gegevensset.
Maak, indien mogelijk, alle services in dezelfde regio en resourcegroep voor nabijheid en beheerbaarheid. In de praktijk kunnen uw services zich in elke regio bevinden.
In dit voorbeeld worden twee kleine gegevenssets gebruikt die zeven fictieve hotels beschrijven. In één set worden de hotels zelf beschreven en geladen in een Azure Cosmos DB-database. De andere set bevat hotelgegevens en wordt geleverd als zeven afzonderlijke JSON-bestanden die moeten worden geüpload naar Azure Blob Storage.
Beginnen met Azure Cosmos DB
Ga naar uw Azure Cosmos DB-account in Azure Portal.
Selecteer Data Explorer in het linkerdeelvenster.
Selecteer Nieuwe container>nieuwe database.
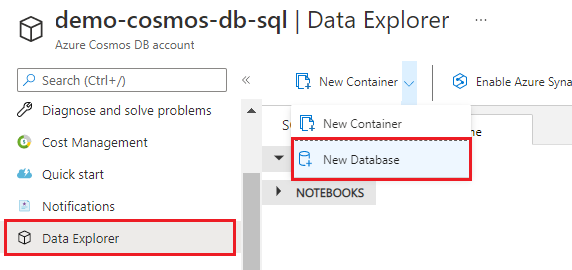
Voer hotel-rooms-db in als naam. Accepteer de standaardwaarden voor de overige instellingen.
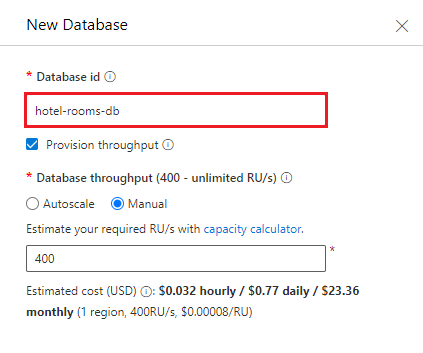
Maak een container die is gericht op de database die u eerder hebt gemaakt. Voer hotels in voor de containernaam en /HotelId voor de partitiesleutel.
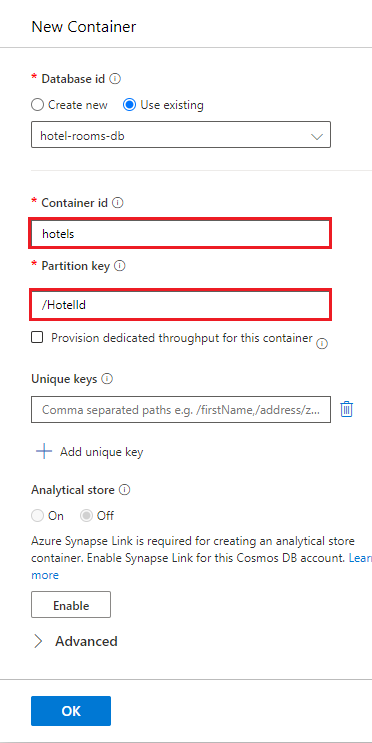
Selecteer hotels>Items, en selecteer Item uploaden op de opdrachtbalk.
Upload het JSON-bestand uit de
cosmosdbmap in multiple-data-sources/v11.
Gebruik de knop Vernieuwen om uw weergave van de items in de verzameling hotels te vernieuwen. Er worden zeven nieuwe databasedocumenten weergegeven.
In het linkerdeelvenster, selecteer Instellingen>Sleutels.
Noteer een verbindingsreeks. U hebt deze waarde nodig voor appsettings.json in een latere stap. Als u de voorgestelde databasenaam hotel-rooms-db niet hebt gebruikt, kopieert u ook de databasenaam.
Azure Blob-opslag
Ga naar uw Azure Storage-account in Azure Portal.
Selecteer in het linkerdeelvenster Gegevensopslagcontainers>.
Maak een blobcontainer met de naam hotel-rooms om de JSON-voorbeeldbestanden voor hotelkamers op te slaan. U kunt het toegangsniveau instellen op elke geldige waarde.
Open de container en selecteer Uploaden op de opdrachtbalk.
Upload de JSON-bestanden uit de map
blobin multiple-data-sources/v11 (zeven in totaal).
Selecteer in het linkerdeelvenster Beveiliging en>.
Noteer de accountnaam en een verbindingsreeks. U hebt beide waarden nodig voor appsettings.json in een latere stap.
Azure AI Zoeken
Het derde onderdeel is Azure AI Zoeken, dat u kunt maken in Azure Portal of een bestaande zoekservice in uw Azure-resources kunt vinden.
Een beheerderssleutel en URL voor Azure AI Zoeken kopiëren
Als u zich wilt verifiëren bij uw zoekservice, hebt u de service-URL en een toegangssleutel nodig. Als u een geldige sleutel hebt, wordt een vertrouwensrelatie vastgesteld per aanvraag tussen de toepassing die de aanvraag verzendt en de service die deze verwerkt.
Ga naar uw zoekservice in Azure Portal.
Selecteer Overzicht in het linkerdeelvenster.
Noteer de URL, die er zoals
https://my-service.search.windows.netuit moet zien.In het linkerdeelvenster, selecteer Instellingen>Sleutels.
Noteer een beheerderssleutel voor volledige rechten op de service. Er zijn twee uitwisselbare beheersleutels die voor bedrijfscontinuïteit worden verstrekt voor het geval u een moet overschakelen. U kunt een van beide sleutels gebruiken voor aanvragen voor het toevoegen, wijzigen en verwijderen van objecten.
Uw omgeving instellen
Open het
AzureSearchMultipleDataSources.slnbestand vanuit meerdere gegevensbronnen/v11 in Visual Studio.Klik in Solution Explorer met de rechtermuisknop op het project en selecteer NuGet-pakketten beheren voor oplossing....
Zoek en installeer de volgende pakketten op het tabblad Bladeren :
Azure.Search.Documents (versie 11.0 of hoger)
Microsoft.Extensions.Configuration
Microsoft.Extensions.Configuration.Json
Bewerk in Solution Explorer het
appsettings.jsonbestand met de verbindingsgegevens die u in de vorige stappen hebt verzameld.{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
Sleutelvelden koppelen
Voor het samenvoegen van inhoud moeten beide gegevensstromen zijn gericht op dezelfde documenten in de zoekindex.
In Azure AI Zoeken identificeert het sleutelveld elk document uniek. Elke zoekindex moet precies één sleutelveld van het type Edm.String bevatten. Het sleutelveld moet aanwezig zijn voor elk document in een gegevensbron dat wordt toegevoegd aan de index. (Dit is zelfs het enige vereiste veld.)
Wanneer u gegevens uit meerdere gegevensbronnen indexeert, moet u ervoor zorgen dat elke binnenkomende rij of elk document een gemeenschappelijke documentsleutel bevat. Hiermee kunt u gegevens uit twee fysiek afzonderlijke brondocumenten samenvoegen in een nieuw zoekdocument in de gecombineerde index.
Het vereist vaak enige planning vooraf om een zinvolle documentsleutel voor uw index te identificeren en ervoor te zorgen dat deze in beide gegevensbronnen aanwezig is. In deze demo is de HotelId sleutel voor elk hotel in Azure Cosmos DB ook aanwezig in de ruimtes JSON-blobs in Blob Storage.
Azure AI Zoeken-indexeerfuncties kunnen veldtoewijzingen gebruiken om de naam van gegevensvelden te wijzigen en zelfs opnieuw op te maken tijdens het indexeringsproces, zodat brongegevens kunnen worden omgeleid naar het juiste indexveld. In Azure Cosmos DB wordt de hotel-id bijvoorbeeld aangeroepen HotelId, maar in de JSON-blobbestanden voor de hotelkamers heeft de hotel-id de naam Id. Het programma verwerkt deze discrepantie door het Id veld van de blobs toe te geven aan het HotelId sleutelveld in de indexeerfunctie.
Notitie
In de meeste gevallen zijn automatisch gegenereerde documentsleutels, zoals de sleutels die standaard door sommige indexeerfuncties zijn gemaakt, geen goede documentsleutels voor gecombineerde indexen. Gebruik in het algemeen een zinvolle, unieke sleutelwaarde die al bestaat in uw gegevensbronnen of kan eenvoudig worden toegevoegd.
De code verkennen
Wanneer de gegevens en configuratie-instellingen zijn ingesteld, moet het voorbeeldprogramma AzureSearchMultipleDataSources.sln gereed zijn om te bouwen en uit te voeren.
Deze eenvoudige C#-/.NET-console-app voert de volgende taken uit:
- Hiermee maakt u een nieuwe index op basis van de gegevensstructuur van de klasse C# Hotel, die ook verwijst naar de klassen Adres en Ruimte.
- Maakt een nieuwe gegevensbron en een indexeerfunctie om Azure Cosmos DB-gegevens toe te wijzen aan indexvelden. Dit zijn beide objecten in Azure AI Zoeken.
- Hiermee wordt de indexeerfunctie uitgevoerd om hotelgegevens uit Azure Cosmos DB te laden.
- Maakt een tweede gegevensbron en een indexeerfunctie om JSON-blobgegevens toe te wijzen aan indexvelden.
- Hiermee wordt de tweede indexeerfunctie uitgevoerd voor het laden van hotelkamergegevens uit Blob Storage.
Neem even de tijd om de code, indexdefinitie en indexeerfunctiedefinitie te bestuderen voordat u het programma uitvoert. De relevante code staat in twee bestanden:
-
Hotel.csbevat het schema dat de index definieert. -
Program.csbevat functies die de Azure AI Zoeken-index, gegevensbronnen en indexeerfuncties maken en de gecombineerde resultaten in de index laden.
Een index maken
In dit voorbeeldprogramma wordt CreateIndexAsync gebruikt om een Azure AI Zoeken-index te definiëren en te maken. Er wordt gebruikgemaakt van de FieldBuilder-klasse om een indexstructuur te genereren op basis van een C#-gegevensmodelklasse.
Het gegevensmodel wordt gedefinieerd door de hotelklasse, die ook verwijzingen bevat naar de adres- en kamerklassen. Met FieldBuilder wordt ingezoomd op meerdere klassedefinities om een complexe gegevensstructuur voor de index te genereren. Tags voor metagegevens worden gebruikt voor het definiëren van de kenmerken van elk veld; er kan bijvoorbeeld worden aangegeven of een veld doorzoekbaar of sorteerbaar is.
Het programma verwijdert een bestaande index van dezelfde naam voordat u het nieuwe maakt, voor het geval u dit voorbeeld meer dan één keer wilt uitvoeren.
In de volgende fragmenten uit het Hotel.cs bestand worden enkele velden weergegeven, gevolgd door een verwijzing naar een andere gegevensmodelklasse, Room[], die op zijn beurt is gedefinieerd in Room.cs het bestand (niet weergegeven).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
In het Program.cs bestand wordt een SearchIndex gedefinieerd met een naam en een veldverzameling die door de FieldBuilder.Build methode wordt gegenereerd en vervolgens als volgt gemaakt:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Een Azure Cosmos DB-gegevensbron en -indexeerfunctie maken
Het hoofdprogramma bevat logica voor het maken van de Azure Cosmos DB-gegevensbron voor de hotelsgegevens.
Eerst voegt deze de naam van de Azure Cosmos DB-database samen met de verbindingsreeks. Vervolgens wordt een SearchIndexerDataSourceConnection-object gedefinieerd.
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
Nadat de gegevensbron is gemaakt, stelt het programma een Azure Cosmos DB-indexeerfunctie in met de naam hotel-rooms-cosmos-indexer.
Het programma werkt alle bestaande indexeerfuncties met dezelfde naam bij, waarbij de bestaande indexeerfunctie wordt overschreven met de inhoud van de vorige code. Het omvat ook het opnieuw instellen en uitvoeren van acties, voor het geval u dit voorbeeld meer dan één keer wilt uitvoeren.
In het volgende voorbeeld wordt een schema voor de indexeerfunctie gedefinieerd, zodat deze eenmaal per dag wordt uitgevoerd. U kunt de planningseigenschap uit deze aanroep verwijderen als u niet wilt dat de indexeerfunctie in de toekomst automatisch opnieuw wordt uitgevoerd.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Dit voorbeeld bevat een eenvoudig try-catch-blok om eventuele fouten te rapporteren die tijdens de uitvoering kunnen optreden.
Nadat de Indexeerfunctie van Azure Cosmos DB is uitgevoerd, bevat de zoekindex een volledige set voorbeeldhoteldocumenten. Het veld Kamers voor elk hotel is echter een lege matrix, omdat de Azure Cosmos DB-gegevensbron ruimtedetails weglaat. Vervolgens haalt het programma gegevens uit Blob Storage om de kamerdata te laden en samen te voegen.
Blob Storage-gegevensbron en -indexeerfunctie maken
Om de details van de ruimte op te halen, stelt het programma eerst een Blob Storage-gegevensbron in om te verwijzen naar een set afzonderlijke JSON-blobbestanden.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
Nadat de gegevensbron is gemaakt, stelt het programma een blob-indexeerfunctie in met de naam hotel-rooms-blob-indexer, zoals hieronder wordt weergegeven.
De JSON-blobs bevatten een sleutelveld met de naam Id in plaats van HotelId. In de code wordt de klasse FieldMapping gebruikt om de indexeerfunctie te laten weten dat de veldwaarde Id moet verwijzen naar de documentsleutel HotelId in de index.
Blob Storage-indexeerfuncties kunnen IndexingParameters gebruiken om een parseermodus op te geven. U moet verschillende parseringsmodi instellen, afhankelijk van of blobs één document of meerdere documenten binnen dezelfde blob vertegenwoordigen. In dit voorbeeld vertegenwoordigt elke blob één JSON-document, dus in de code wordt de parseermodus json gebruikt. Voor meer informatie over het parseren van parameters voor de indexeerfunctie voor JSON-blobs raadpleegt u JSON-blobs indexeren.
In dit voorbeeld wordt een schema voor de indexeerfunctie gedefinieerd, zodat deze eenmaal per dag wordt uitgevoerd. U kunt de planningseigenschap uit deze aanroep verwijderen als u niet wilt dat de indexeerfunctie in de toekomst automatisch opnieuw wordt uitgevoerd.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Omdat de index al is gevuld met hotelgegevens uit de Azure Cosmos DB-database, werkt de blob-indexeerfunctie de bestaande documenten in de index bij en worden de kamergegevens toegevoegd.
Notitie
Als u dezelfde niet-sleutelvelden in beide gegevensbronnen hebt en de gegevens in die velden niet overeenkomen, bevat de index de waarden van de indexeerfunctie die het laatst is uitgevoerd. In ons voorbeeld bevatten beide gegevensbronnen een HotelName veld. Als de gegevens in dit veld om een of andere reden anders zijn, zijn voor documenten met dezelfde sleutelwaarde de HotelName gegevens uit de laatst geïndexeerde gegevensbron de waarde die in de index is opgeslagen.
Zoeken
Nadat u het programma hebt uitgevoerd, kunt u de ingevulde zoekindex verkennen met behulp van Search Explorer in Azure Portal.
Ga naar uw zoekservice in Azure Portal.
Selecteerzoekbeheerindexen> in het linkerdeelvenster.
Selecteer het voorbeeld van hotelkamers in de lijst met indexen.
Voer op het tabblad Search Explorer een query in voor een term zoals
Luxury.U zou ten minste één document in de resultaten moeten zien. Dit document moet een lijst met ruimteobjecten in zijn
Roomsarray bevatten.
Opnieuw instellen en uitvoeren
In de vroege experimentele ontwikkelingsfasen is de meest praktische benadering voor het ontwerpen van iteratie het verwijderen van de objecten uit Azure AI Zoeken en het mogelijk maken van uw code om ze opnieuw te bouwen. Resourcenamen zijn uniek. Na het verwijderen van een object kunt u het opnieuw maken met dezelfde naam.
In de voorbeeldcode wordt gecontroleerd op bestaande objecten, en worden deze verwijderd of bijgewerkt, zodat u het programma opnieuw kunt uitvoeren. U kunt azure Portal ook gebruiken om indexen, indexeerfuncties en gegevensbronnen te verwijderen.
Hulpbronnen opschonen
Wanneer u in uw eigen abonnement werkt, is het aan het einde van een project een goed idee om de resources te verwijderen die u niet meer nodig hebt. Resources die door blijven draaien, kunnen u geld kosten. U kunt resources afzonderlijk verwijderen, maar u kunt ook de resourcegroep verwijderen als u de volledige resourceset wilt verwijderen.
U kunt resources vinden en beheren in de Azure-portal met behulp van de koppeling Alle Resources of Resourcegroepen in het linkerdeelvenster.
Volgende stap
Nu u bekend bent met het opnemen van gegevens uit meerdere bronnen, gaat u dieper in op de configuratie van de indexeerfunctie, te beginnen met Azure Cosmos DB: