Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure AI Search ondersteunt twee basismethoden voor het importeren van gegevens in een zoekindex: uw gegevens programmatisch naar de index pushen of uw gegevens ophalen door een indexeerfunctie naar een ondersteunde gegevensbron te verwijzen.
In deze handleiding wordt uitgelegd hoe u efficiënt gegevens indexeert met behulp van het pushmodel door verzoeken in batchverwerking te verwerken en een exponentiële uitstelstrategie te hanteren. U kunt de voorbeeldtoepassing downloaden en uitvoeren. In deze zelfstudie worden ook de belangrijkste aspecten van de toepassing uitgelegd en welke factoren u moet overwegen bij het indexeren van gegevens.
In deze zelfstudie gebruikt u C# en de bibliotheek Azure.Search.Documents van de Azure SDK voor .NET om:
- Een index maken
- Verschillende batchgrootten testen om de meest efficiënte grootte te bepalen
- Batches asynchroon indexeren
- Meerdere threads gebruiken om de indexeringssnelheden te verhogen
- Een exponentieel terugval-herprobeerstrategie gebruiken om mislukte documenten opnieuw te proberen.
Vereiste voorwaarden
- Een Azure-account met een actief abonnement. Gratis een account maken
- Visual Studio.
Bestanden downloaden
De broncode voor deze zelfstudie bevindt zich in de map optimize-data-indexing/v11 in de GitHub-opslagplaats azure-Samples/azure-search-dotnet-scale .
Belangrijke overwegingen
De volgende factoren zijn van invloed op indexeringssnelheden. Zie Grote gegevenssets indexeren voor meer informatie.
- Prijscategorie en aantal partities/replica's: Het toevoegen van partities of het upgraden van uw laag verhoogt de indexeringssnelheden.
- Complexiteit van indexschema: door velden en veldeigenschappen toe te voegen, worden de indexeringssnelheden verlaagd. Kleinere indexen zijn sneller te indexeren.
- Batchgrootte: De optimale batchgrootte varieert op basis van uw indexschema en gegevensset.
- Aantal threads/werkrollen: een enkele thread profiteert niet optimaal van indexeringssnelheden.
- Strategie voor opnieuw proberen: Een strategie voor exponentieel uitstel is een best practice voor optimale indexering.
- Snelheid van netwerkgegevensoverdracht: gegevensoverdrachtsnelheden kunnen een beperkende factor zijn. Indexeer gegevens vanuit uw Azure-omgeving om de gegevensoverdrachtsnelheden te verhogen.
Een zoekservice maken
Voor deze zelfstudie is een Azure AI Search-service vereist die u kunt maken in Azure Portal. U kunt ook een bestaande service vinden in uw huidige abonnement. Als u indexeringssnelheden nauwkeurig wilt testen en optimaliseren, raden we u aan dezelfde prijscategorie te gebruiken die u in productie wilt gebruiken.
Een beheerderssleutel en URL voor Azure AI Search ophalen
In deze zelfstudie wordt gebruikgemaakt van verificatie op basis van sleutels. Kopieer een beheer-API-sleutel om in het appsettings.json bestand te plakken.
Ga naar uw zoekservice in Azure Portal.
Selecteer in het linkerdeelvenster Overzicht en kopieer het eindpunt. Deze moet de volgende indeling hebben:
https://my-service.search.windows.netSelecteer inhet linkerdeelvenster> en kopieer een beheerderssleutel voor volledige rechten op de service. Er zijn twee uitwisselbare beheersleutels die voor bedrijfscontinuïteit worden verstrekt voor het geval u een moet overschakelen. U kunt één van beide sleutels gebruiken om objecten toe te voegen, wijzigen of verwijderen.
Uw omgeving instellen
Open het
OptimizeDataIndexing.sln-bestand in Visual Studio.Bewerk in Solution Explorer het
appsettings.jsonbestand met de verbindingsgegevens die u in de vorige stap hebt verzameld.{ "SearchServiceUri": "https://{service-name}.search.windows.net", "SearchServiceAdminApiKey": "", "SearchIndexName": "optimize-indexing" }
De code verkennen
Nadat u de update appsettings.jsonhebt uitgevoerd, moet het voorbeeldprogramma OptimizeDataIndexing.sln gereed zijn om te bouwen en uit te voeren.
Deze code is afgeleid van de sectie C# van quickstart: Zoeken in volledige tekst, die gedetailleerde informatie biedt over de basisbeginselen van het werken met de .NET SDK.
Deze eenvoudige C#-/.NET-console-app voert de volgende taken uit:
- Hiermee maakt u een nieuwe index op basis van de gegevensstructuur van de C#
Hotel-klasse (die ook verwijst naar deAddressklasse) - Test verschillende batchgrootten om de meest efficiënte grootte te bepalen
- Indexeert gegevens asynchroon
- Meerdere threads gebruiken om de indexeringssnelheden te verhogen
- Gebruik een exponentiële backoff-herhalingsstrategie om mislukte taken opnieuw te proberen
Neem even de tijd om de code en de indexdefinities voor dit voorbeeld te bestuderen voordat u het programma uitvoert. De relevante code bevindt zich in verschillende bestanden:
-
Hotel.csenAddress.cshet schema bevatten dat de index definieert -
DataGenerator.csbevat een eenvoudige klasse om het eenvoudig te maken grote hoeveelheden hotelgegevens te maken -
ExponentialBackoff.csbevat code voor het optimaliseren van het indexeringsproces, zoals beschreven in dit artikel -
Program.csbevat functies die de Azure AI Search-index maken en verwijderen, batches met gegevens indexeren en verschillende batchgrootten testen
De index maken
In dit voorbeeldprogramma wordt de Azure SDK voor .NET gebruikt om een Azure AI Search-index te definiëren en te maken. Het maakt gebruik van de FieldBuilder klasse om een indexstructuur te genereren op basis van een C#-gegevensmodelklasse.
Het gegevensmodel wordt gedefinieerd door de Hotel klasse, die ook verwijzingen naar de Address klasse bevat.
FieldBuilder zoomt in op meerdere klassedefinities om een complexe gegevensstructuur voor de index te genereren. Tags voor metagegevens worden gebruikt voor het definiëren van de kenmerken van elk veld; er kan bijvoorbeeld worden aangegeven of een veld doorzoekbaar of sorteerbaar is.
De volgende codefragmenten uit het Hotel.cs bestand geven één veld en een verwijzing naar een andere gegevensmodelklasse op.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
In het Program.cs bestand wordt de index gedefinieerd met een naam en een veldverzameling die door de FieldBuilder.Build(typeof(Hotel)) methode wordt gegenereerd en vervolgens als volgt gemaakt:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Gegevens genereren
Een eenvoudige klasse wordt geïmplementeerd in het DataGenerator.cs bestand om gegevens te genereren voor testen. Het doel van deze klasse is om eenvoudig een groot aantal documenten te genereren met een unieke id voor indexering.
Voer de volgende code uit om een lijst met 100.000 hotels met unieke id's op te halen:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Er zijn twee grootten hotels beschikbaar voor tests in dit voorbeeld: klein en groot.
Het schema van uw index is van invloed op indexeringssnelheden. Nadat u deze zelfstudie hebt voltooid, kunt u deze klasse converteren om gegevens te genereren die het beste overeenkomen met het beoogde indexschema.
Batchgrootten testen
Als u één of meerdere documenten in een index wilt laden, ondersteunt Azure AI Search de volgende API's:
Het indexeren van documenten in batches verbetert de indexeringsprestaties aanzienlijk. Deze batches kunnen maximaal 1000 documenten of maximaal 16 MB per batch zijn.
Het vaststellen van de optimale batchgrootte voor uw gegevens is een belangrijk onderdeel van voor het optimaliseren van de indexeringssnelheid. De twee primaire factoren die van invloed zijn op de optimale batchgrootte zijn:
- Het schema van uw index
- De grootte van uw gegevens
Omdat de optimale batchgrootte afhankelijk is van uw index en uw gegevens, kunt u het beste verschillende batchgrootten testen om te bepalen welke resultaten de snelste indexeringssnelheden voor uw scenario opleveren.
De volgende functie demonstreert een eenvoudige benadering voor het testen van batchgrootten.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Omdat niet alle documenten dezelfde grootte hebben (hoewel ze zich in dit voorbeeld bevinden), schatten we de grootte van de gegevens die we naar de zoekservice verzenden. U kunt dit doen met behulp van de volgende functie die het object eerst converteert naar JSON en vervolgens de grootte ervan in bytes bepaalt. Met deze techniek kunnen we bepalen welke batchgrootten het meest efficiënt zijn in termen van MB/s-indexeringssnelheden.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
De functie vereist een SearchClient plus het aantal pogingen dat u wilt testen voor elke batchgrootte. Omdat er mogelijk variabiliteit is in indexeringstijden voor elke batch, kunt u elke batch drie keer proberen om de resultaten statistisch significanter te maken.
await TestBatchSizesAsync(searchClient, numTries: 3);
Wanneer u de functie uitvoert, ziet u een uitvoer in uw console die vergelijkbaar is met het volgende voorbeeld:
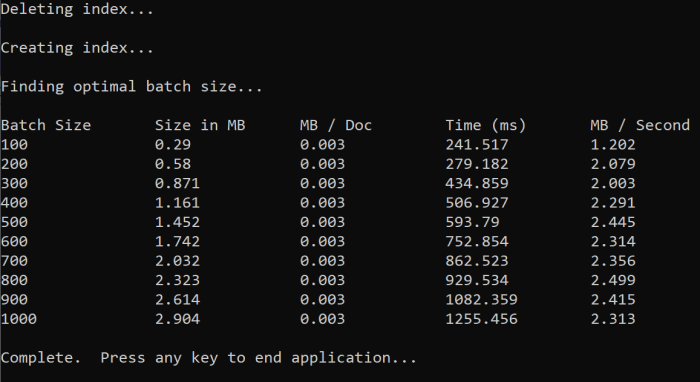
Bepaal welke batchgrootte het efficiëntst is en gebruik die batchgrootte in de volgende stap van deze zelfstudie. Mogelijk ziet u een plateau in MB/s in verschillende batchgrootten.
De gegevens indexeren
Nu u de batchgrootte hebt geïdentificeerd die u wilt gebruiken, is de volgende stap het indexeren van de gegevens. Om gegevens efficiënt te indexeren, biedt dit voorbeeld:
- Gebruikt meerdere threads/werkrollen
- Implementeert een strategie voor exponentieel uitstel voor opnieuw proberen
Verwijder opmerkingen 41 tot en met 49 en voer het programma opnieuw uit. Tijdens deze uitvoering genereert en verzendt het voorbeeld batches documenten, tot 100.000 als u de code uitvoert zonder de parameters te wijzigen.
Meerdere threads/werkrollen gebruiken
Als u wilt profiteren van de indexeringssnelheden van Azure AI Search, gebruikt u meerdere threads om aanvragen voor batchindexering gelijktijdig naar de service te verzenden.
Verschillende van de belangrijkste overwegingen kunnen van invloed zijn op het optimale aantal threads. U kunt dit voorbeeld wijzigen en testen met verschillende threadtellingen om het optimale aantal threads voor uw scenario te bepalen. Zolang er echter meerdere threads gelijktijdig worden uitgevoerd, moet u kunnen profiteren van de meeste efficiëntieverbeteringen.
Wanneer u de aanvragen voor de zoekservice opvoert, kunt u HTTP-statuscodes tegenkomen die aangeven dat de aanvraag niet volledig is geslaagd. Twee veelvoorkomende HTTP-statuscodes die zich tijdens het indexeren kunnen voordoen, zijn:
- 503 Service niet beschikbaar: deze fout betekent dat het systeem zwaar wordt belast en uw aanvraag op dit moment niet kan worden verwerkt.
- 207 Multi-Status: Deze fout betekent dat sommige documenten zijn geslaagd, maar ten minste één is mislukt.
Het implementeren van een exponentiële backoff-herhaalstrategie
Als er een fout optreedt, moet u aanvragen opnieuw proberen met behulp van een strategie voor exponentieel uitstel.
De .NET SDK van Azure AI Search probeert automatisch 503's en andere mislukte aanvragen opnieuw, maar u moet uw eigen logica implementeren om 207s opnieuw te proberen. Opensource-hulpprogramma's zoals Polly kunnen handig zijn in een strategie voor opnieuw proberen.
In dit voorbeeld implementeren we onze eigen strategie voor exponentieel uitstel van nieuwe pogingen. We beginnen met het definiëren van enkele variabelen, waaronder de maxRetryAttempts en de eerste delay voor een mislukte aanvraag.
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
De resultaten van de indexeringsbewerking worden opgeslagen in de variabele IndexDocumentResult result. Met deze variabele kunt u controleren of documenten in de batch zijn mislukt, zoals wordt weergegeven in het volgende voorbeeld. Als er een gedeeltelijke fout optreedt, wordt er een nieuwe batch gemaakt op basis van de id van de mislukte documenten.
RequestFailedException uitzonderingen moeten ook worden opgevangen, omdat ze aangeven dat de aanvraag volledig is mislukt en opnieuw wordt geprobeerd.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Vanaf hier wrapt u de exponentiële terugvalcode in een functie, zodat deze gemakkelijk kan worden aangeroepen.
Er wordt vervolgens een andere functie gemaakt om de actieve threads te beheren. Om het eenvoudig te maken, is deze functie hier niet opgenomen, maar is deze te vinden in ExponentialBackoff.cs. U kunt de functie aanroepen met behulp van de volgende opdracht, waarbij de gegevens zijn die hotels we willen uploaden, 1000 de batchgrootte is en 8 het aantal gelijktijdige threads is.
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Wanneer u de functie uitvoert, ziet u een uitvoer die vergelijkbaar is met het volgende voorbeeld:
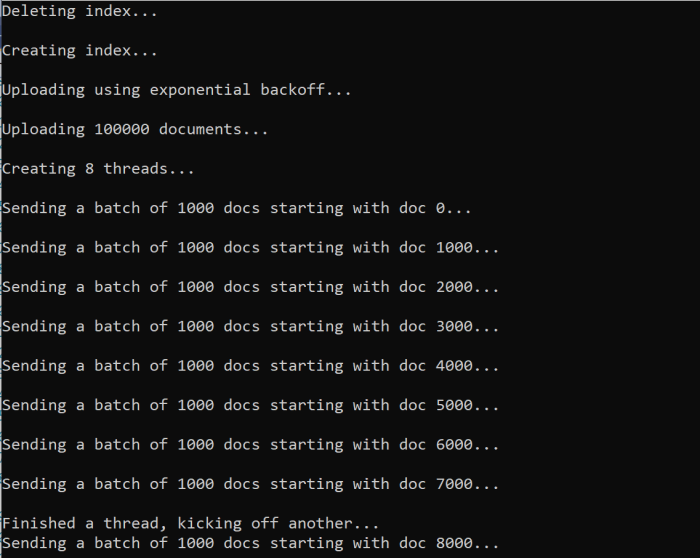
Wanneer een batch met documenten mislukt, wordt er een fout afgedrukt die de fout aangeeft en of de batch opnieuw wordt geprobeerd.
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Nadat de functie is uitgevoerd, kunt u controleren of alle documenten aan de index zijn toegevoegd.
De index verkennen
Nadat het programma is uitgevoerd, kunt u de ingevulde zoekindex programmatisch verkennen of de Search Explorer gebruiken in Azure Portal.
Programmatisch
Er zijn twee belangrijkste opties voor het controleren van het aantal documenten in een index: de API Aantal documenten en de API Indexstatistieken ophalen. Voor beide paden is tijd nodig om te verwerken, dus wees niet bezorgd als het aantal geretourneerde documenten in eerste instantie lager is dan verwacht.
Documenten tellen
Met de bewerking Documenten tellen wordt een telling opgehaald van het aantal documenten in een zoekindex.
long indexDocCount = await searchClient.GetDocumentCountAsync();
Indexstatistieken ophalen
De bewerking Indexstatistieken ophalen retourneert een aantal documenten voor de huidige index, plus opslaggebruik. Het duurt langer om indexstatistieken bij te werken dan het aantal documenten.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure portal
In de Azure-portal, in het linkerdeelvenster, zoek de optimize-indexing index in de lijst Indexen.

Het aantal documenten en de opslaggrootte zijn gebaseerd op de API Indexstatistieken ophalen en kan enkele minuten duren om bij te werken.
Opnieuw instellen en uitvoeren
In de vroege experimentele ontwikkelingsfasen is de meest praktische benadering voor het ontwerpen van iteratie het verwijderen van de objecten uit Azure AI Search en het mogelijk maken van uw code om ze opnieuw te bouwen. Resourcenamen zijn uniek. Na het verwijderen van een object kunt u het opnieuw maken met dezelfde naam.
De voorbeeldcode voor deze zelfstudie controleert op bestaande indexen en verwijdert deze, zodat u de code opnieuw kunt uitvoeren.
U kunt azure Portal ook gebruiken om indexen te verwijderen.
De hulpbronnen opschonen
Wanneer je in je eigen abonnement werkt, is het aan het einde van een project een goed idee om de resources die je niet meer nodig hebt te verwijderen. Ressources die actief blijven draaien, kunnen geld kosten. U kunt resources afzonderlijk verwijderen, maar u kunt ook de resourcegroep verwijderen als u de volledige resourceset wilt verwijderen.
U kunt resources vinden en beheren in Azure Portal met behulp van de koppeling Alle resources of resourcegroepen in het linkernavigatiedeelvenster.
Volgende stap
Raadpleeg de volgende zelfstudie voor meer informatie over het indexeren van grote hoeveelheden gegevens: