Berichtreplicatie en federatie in meerdere regio's
Binnen naamruimten ondersteunt Azure Service Bus het maken van topologieën van gekoppelde wachtrijen en onderwerpabonnementen met behulp van automatisch doorsturen om de implementatie van verschillende routeringspatronen mogelijk te maken. U kunt bijvoorbeeld partners voorzien van toegewezen wachtrijen waarvoor ze machtigingen hebben voor verzenden of ontvangen, en die indien nodig tijdelijk kunnen worden opgeschort en flexibel verbinding maken met andere entiteiten die privé zijn voor de toepassing. U kunt ook complexe routeringstopologieën met meerdere fasen maken, of u kunt wachtrijen in postvakstijl maken, die de wachtrijachtige abonnementen van onderwerpen leegmaken en meer opslagcapaciteit per abonnee mogelijk maken.
Veel geavanceerde oplossingen vereisen ook dat berichten worden gerepliceerd over de grenzen van naamruimten om deze en andere patronen te kunnen implementeren. Berichten moeten mogelijk stromen tussen naamruimten die zijn gekoppeld aan meerdere, verschillende toepassingstenants of in meerdere Azure-regio's.
Uw oplossing onderhoudt meerdere Service Bus-naamruimten in verschillende regio's en repliceert berichten tussen wachtrijen en onderwerpen en/of die u berichten uitwisselt met bronnen en doelen, zoals Azure Event Hubs, Azure IoT Hub of Apache Kafka.
Deze scenario's zijn de focus van dit artikel.
Federatiepatronen
Er zijn talloze mogelijke redenen waarom u mogelijk berichten wilt verplaatsen tussen Service Bus-entiteiten, zoals wachtrijen of onderwerpen, of tussen Service Bus en andere bronnen en doelen.
Vergeleken met de vergelijkbare reeks patronen voor Event Hubs, is federatie voor wachtrijachtige entiteiten complexer omdat berichtenwachtrijen hun consumenten het exclusieve eigendom van een enkel bericht beloven, naar verwachting de aankomstvolgorde in de berichtbezorging behouden blijven en de broker een eerlijke distributie van berichten tussen concurrerende consumenten coördineert.
Er zijn praktische belemmeringen, met inbegrip van de beperkingen van de CAP-theorema, waardoor het moeilijk is om een uniforme weergave te bieden van een wachtrij die tegelijkertijd beschikbaar is in meerdere regio's, en waarmee concurrerende consumenten regionaal kunnen worden gedistribueerd, exclusieve eigendom van berichten kunnen nemen. Een dergelijke geografisch gedistribueerde wachtrij vereist niet alleen volledige consistente replicatie van berichten, maar ook van de bezorgingsstatus van elk bericht voordat berichten beschikbaar kunnen worden gesteld aan consumenten. Een doel van een volledige consistentie voor een hypothetische, regionaal gedistribueerde wachtrij is in direct conflict met het belangrijkste doel dat praktisch alle Azure Service Bus-klanten hebben bij het overwegen van federatiescenario's: Maximale beschikbaarheid en betrouwbaarheid voor hun oplossingen.
De hier gepresenteerde patronen richten zich daarom op beschikbaarheid en betrouwbaarheid, en streven ernaar om zowel informatieverlies als dubbele verwerking van berichten te voorkomen.
Tolerantie voor regionale beschikbaarheidsgebeurtenissen
Hoewel maximale beschikbaarheid en betrouwbaarheid de belangrijkste operationele prioriteiten voor Service Bus zijn, zijn er echter veel manieren waarop een producent of consument kan worden verhinderd om te praten met de toegewezen 'primaire' Service Bus vanwege netwerk- of naamomzettingsproblemen, of waarbij de Service Bus-entiteit inderdaad tijdelijk niet reageert of fouten retourneert. De aangewezen berichtprocessor is mogelijk ook niet beschikbaar.
Dergelijke omstandigheden zijn niet 'rampzalig' zodat u de regionale implementatie helemaal wilt afbreken, zoals u in een noodherstelsituatie zou kunnen doen, maar het bedrijfsscenario van sommige toepassingen kan al worden beïnvloed door beschikbaarheidsgebeurtenissen die niet langer dan een paar minuten of zelfs seconden duren. Azure Service Bus wordt vaak gebruikt in hybride cloudomgevingen en met klanten die zich aan de netwerkrand bevinden, bijvoorbeeld in winkels, restaurants, bankkantoren, productielocaties, logistieke faciliteiten en luchthavens. Het is mogelijk dat een probleem met netwerkroutering of congestie van invloed is op de mogelijkheid van een site om het toegewezen Service Bus-eindpunt te bereiken, terwijl een secundair eindpunt in een andere regio mogelijk bereikbaar is. Tegelijkertijd hebben systemen die berichten verwerken die afkomstig zijn van deze sites mogelijk nog steeds geen toegang tot zowel de primaire als de secundaire Service Bus-eindpunten.
Er zijn veel praktische voorbeelden van dergelijke hybride cloud- en edge-toepassingen met een lage bedrijfstolerantie voor impact van netwerkrouteringsproblemen of tijdelijke beschikbaarheidsproblemen van een Service Bus-entiteit. Deze omvatten de verwerking van betalingen op detailhandelssites, instappen bij luchthavenpoorten en mobiele telefoonorders bij restaurants, die allemaal direct tot stilstand komen en volledig stil staan wanneer het betrouwbare communicatiepad niet beschikbaar is.
In deze categorie bespreken we drie verschillende gedistribueerde patronen: 'all-active'-replicatie, 'actief-passief'-replicatie en 'spillover'-replicatie.
Alle actieve replicatie
Met het replicatiepatroon 'all-active' kan een actieve replica van hetzelfde logische onderwerp (of wachtrij) beschikbaar zijn in meerdere naamruimten (en regio's), en voor alle berichten die beschikbaar zijn in alle replica's, ongeacht waar ze zijn onderzocht. Het patroon behoudt over het algemeen de volgorde van berichten ten opzichte van een uitgever.

Zoals in de afbeelding wordt weergegeven, leunt het patroon over het algemeen op Service Bus-onderwerpen. Eén onderwerp voor elke naamruimte die deelneemt aan het replicatieschema. Elk van deze onderwerpen heeft één 'replicatieabonnement' voor een van de andere onderwerpen waarnaar berichten moeten worden gerepliceerd. In de bovenstaande afbeelding hebben we gewoon een paar onderwerpen en daarom één replicatieabonnement voor het desbetreffende andere onderwerp. In een scenario met drie naamruimten {n1, n2, n3} heeft een onderwerp in naamruimte n1 twee replicatieabonnementen, één voor het bijbehorende onderwerp in n2 en één voor het bijbehorende onderwerp in n3.
Elk replicatieabonnement heeft een regel die een SQL-filterexpressie (replicated <> 1) en een SQL-actie (set replicated = 1) combineert. Het filter van de regel zorgt ervoor dat alleen berichten waarbij de aangepaste eigenschap replication niet is ingesteld of niet in 1 aanmerking komt voor dit abonnement, en de actie stelt die exacte eigenschap in op de waarde 1 voor elk geselecteerd bericht direct daarna. Het effect is dat wanneer het bericht naar het bijbehorende onderwerp wordt gekopieerd, het niet langer in aanmerking komt voor replicatie in de tegenovergestelde richting en daarom voorkomen we berichten die tussen replica's worden geactiveerd.
Een abonnement met een respectieve regel kan eenvoudig worden toegevoegd aan elk onderwerp met behulp van de Azure CLI, zoals deze.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
Als u een wachtrij wilt modelleren, is elk onderwerp beperkt tot slechts één gewoon abonnement (behalve de replicatieabonnementen) die alle consumenten delen.
Het all-actieve replicatiemodel plaatst een kopie van elk bericht dat in een van de onderwerpen in elk van de onderwerpen wordt verzonden. Dat betekent dat uw toepassingscode in elke regio alle berichten ziet en verwerkt. Dit patroon is geschikt voor scenario's waarin gegevens worden gedeeld in meerdere regio's of als redundante verwerking doorgaans gewenst is. Als u elk bericht slechts één keer moet verwerken, zoals bij een normale wachtrij, moet u een van de volgende twee patronen overwegen.
Actief-passieve replicatie
Het replicatiepatroon 'actief-passief' is een variatie van het voorgaande patroon waarbij slechts één van de onderwerpen (de 'primaire') actief wordt gebruikt door de toepassing voor het verzenden en ontvangen van berichten en berichten in een secundair onderwerp voor het geval dat het primaire onderwerp mogelijk niet beschikbaar of onbereikbaar wordt.

Het belangrijkste verschil tussen dit patroon en het vorige patroon is dat replicatie unidirectioneel is van het primaire onderwerp in het secundaire onderwerp. Het secundaire onderwerp wordt nooit het primaire onderwerp, maar is een back-upoptie voor wanneer het primaire onderwerp tijdelijk onbruikbaar is.
Het voordeel van het gebruik van dit patroon is dat het probeert dubbele verwerking te minimaliseren. Tijdens de replicatie wordt de TimeToLive berichteigenschap ingesteld op een duur van de gerepliceerde berichten die overeenkomen met de verwachte tijd waarin een storing van de primaire server tot een failover leidt. Als voor uw use-casescenario bijvoorbeeld een overschakeling van de consument naar de secundaire is vereist binnen maximaal 1 minuut na het ophalen van berichten vanaf het primaire begin met problemen, moet de secundaire in het ideale geval alle berichten hebben die u niet in de primaire server kunt openen, maar een minimaal aantal berichten dat u al van de primaire server hebt verwerkt voordat de problemen worden weergegeven. Als we de TimeToLive op twee keer die periode, 2 minuten, tijdens de replicatie (set sys.TimeToLive = '0:2:0' in de regelactie) hebben ingesteld, bewaart de secundaire regel alleen berichten gedurende 2 minuten en worden oudere berichten verwijderd. Dat betekent dat wanneer de ontvanger overschakelt naar de secundaire, berichten snel kan lezen en verwijderen die ouder zijn dan het laatste bericht dat is verwerkt en vervolgens verwerkt vanaf het eerste bericht dat het nog niet heeft gezien. De werkelijke bewaarduur is afhankelijk van de specifieke use-case en van snel dat u wilt en kunt overschakelen naar de secundaire in uw toepassing. De TimeToLive instelling wordt gehonoreerd in het bereik van een paar seconden tot dagen.
Hoewel de toepassing gebruikmaakt van de secundaire, kan deze ook rechtstreeks naar het secundaire onderwerp publiceren, dat vervolgens fungeert als een gewoon onderwerp. Na de overstap naar de secundaire, ziet de consument daarom een combinatie van gerepliceerde berichten en berichten die rechtstreeks naar de secundaire worden gepubliceerd. De toepassing moet daarom eerst overschakelen naar de primaire publicatie en toch het leegmaken van de lokaal gepubliceerde berichten toestaan voordat de consument terugschakelt naar de secundaire. Vanwege de replicatie die automatisch wordt hervat zodra de primaire opnieuw beschikbaar is, krijgt de consument ook nieuwe berichten die gedurende die tijd naar de primaire server worden gepubliceerd, zij het met een iets hogere latentie.
Dit patroon is geschikt voor scenario's waarin berichten slechts één keer moeten worden verwerkt. De toepassing moet samenwerken bij het bijhouden van berichten die het heeft verwerkt van de primaire, omdat er duplicaten worden gevonden voor de duur van het failovervenster in de secundaire, waarna er opnieuw duplicaten worden gevonden tijdens het terugschakelen. Het criterium voor de duplicatie moet het beste een door de toepassing verstrekte
MessageIdaanvraag zijn. DeEnqueuedTimeUtcwaarde is ook geschikt als watermerkindicator, maar de toepassing moet enige hoeveelheid klokdrift (enkele seconden) tussen primair en secundair toestaan, net als bij elk gedistribueerd systeem.
Overloopreplicatie
Met het replicatiepatroon 'overloop' kan actief/actief gebruik worden gemaakt van meerdere Service Bus-entiteiten in meerdere regio's om te gaan met het scenario waarin Service Bus in orde is, maar de consument wordt overweldigd met het aantal in behandeling zijnde berichten of is niet meer beschikbaar. Een reden hiervoor is dat een database die het consumentenproces back-up maakt mogelijk traag of niet beschikbaar is. Dit patroon werkt met gewone wachtrijen en met onderwerpabonnementen.

Zoals wordt weergegeven in de afbeelding, repliceert het replicatiepatroon voor overloop berichten uit de gekoppelde wachtrij met dode letters van een wachtrij of abonnement naar een gekoppelde wachtrij of een gekoppeld onderwerp in een andere naamruimte.
Zonder dat er een foutsituatie is, worden de twee naamruimten parallel gebruikt, waarbij elk een subset van het algemene berichtverkeer ontvangt en de bijbehorende consumenten die deze subset verwerken. Zodra een van de consumenten hoge foutpercentages vertoont of direct stopt, komen de respectieve berichten in de wachtrij met dode brieven terecht door het overschrijden van het aantal bezorgingen of omdat deze verloopt. De replicatietaken halen ze vervolgens op en volgen ze opnieuw in de gekoppelde wachtrij, waar ze vervolgens worden gepresenteerd aan de vermoedelijk gezonde consument.
Als de verwerking binnen een bepaalde deadline moet plaatsvinden, moeten de TimeToLive voor de wachtrij en/of berichten zodanig worden ingesteld dat de verwerking nog steeds op tijd kan plaatsvinden door de secundaire overloop, bijvoorbeeld TimeToLive ingesteld op de helft van de toegestane tijd.
Net als bij het all-actieve patroon kan de toepassing een indicator toevoegen aan het bericht of het bericht al is gerepliceerd, zodat deze niet tussen het paar wachtrijen stuiteren, maar in plaats daarvan worden geplaatst in een hulpwachtrij die fungeert als de wachtrij met dode letters voor het samengestelde patroon.
Dit patroon is geschikt voor scenario's waarbij de belangrijkste zorg is om zich te beschermen tegen beschikbaarheidsproblemen in consumenten of resources waarvan de consumenten afhankelijk zijn, en ook om pieken in verkeer opnieuw te distribueren op een van de gekoppelde wachtrijen. Het biedt ook bescherming tegen een van de naamruimten die niet beschikbaar zijn als gebruikers lezen uit beide wachtrijen, maar de replicatievertraging die door de
TimeToLivevervaldatum wordt opgelegd, kan ertoe leiden dat berichten binnen dat tijdvenster worden vastgelopen in de niet-beschikbare naamruimte.
Optimalisatie van latentie
Onderwerpen worden gebruikt om informatie te distribueren naar meerdere consumenten. In sommige gevallen, met name de consumenten met een brede geografische distributie, kan het nuttig zijn om berichten van een onderwerp te repliceren naar een onderwerp in een secundaire naamruimte dichter bij consumenten.

Wanneer u bijvoorbeeld gegevens deelt tussen regionale, continentale hubs, is het efficiënter om informatie slechts eenmaal over te dragen tussen hubs en consumenten hun kopie van de gegevens van die hubs te laten ophalen.
Replicatieoverdrachten kunnen worden uitgevoerd in batches, die consumenten vaak één voor één berichten verkrijgen en vereffenen. Met een basisnetwerklatentie van 100 ms tussen bijvoorbeeld Noord-Amerika en Europa duurt het 200 ms langer voordat de twee retouren naar een externe entiteit worden verwerkt voor het verkrijgen en vereffenen van de berichten, vergeleken met een entiteit in dezelfde regio.
Validatie, reductie en verrijking
Berichten kunnen worden ingediend in een Service Bus-wachtrij of -onderwerp door clients buiten uw eigen oplossing.

Voor dergelijke berichten kan moeten worden gecontroleerd op naleving van een bepaald schema en of niet-compatibele berichten moeten worden verwijderd of niet-conform zijn. Sommige berichten moeten mogelijk in complexiteit worden verminderd door gegevens weg te laten en sommige moeten mogelijk worden verrijkt door gegevens toe te voegen op basis van zoekacties naar referentiegegevens. De bewerkingen kunnen worden uitgevoerd met aangepaste functionaliteit in de replicatietaak.
Stream-naar-wachtrijreplicatie
Azure Event Hubs is een ideale oplossing voor het verwerken van extreme volumes binnenkomende gebeurtenissen. Maar event hubs en vergelijkbare engines zoals Apache Kafka bieden geen servicebeheerd consumentenmodel , waarbij meerdere consumenten berichten van dezelfde bron gelijktijdig kunnen verwerken zonder dat er een risico bestaat voor dubbele verwerking en ten slotte deze berichten vereffenen zodra ze zijn verwerkt.
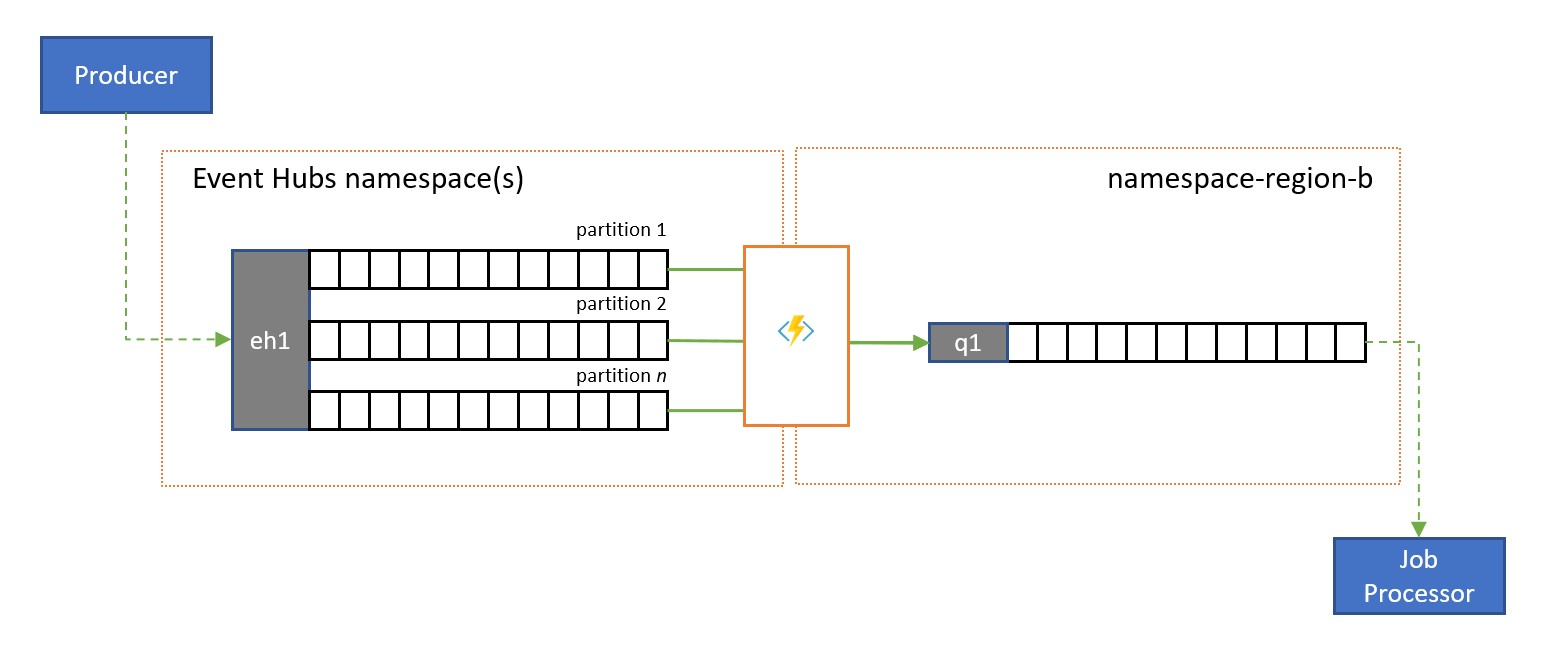
Een stream naar wachtrijreplicatie draagt de inhoud van één Event Hub-partitie of de inhoud van een volledige Event Hub over in een Service Bus-wachtrij, van waaruit de berichten veilig, transactioneel en met concurrerende consumenten kunnen worden verwerkt. Deze replicatie maakt het ook mogelijk om alle andere Service Bus-mogelijkheden voor deze berichten te gebruiken, inclusief routering met onderwerpen en sessiegebaseerde demultiplexing.
Consolidatie en normalisatie
Wereldwijde oplossingen bestaan vaak uit regionale footprints die grotendeels onafhankelijk zijn, waaronder het hebben van hun eigen verwerkingsmogelijkheden, maar supra-regionale en wereldwijde perspectieven vereisen gegevensintegratie en daarom een centrale samenvoeging van dezelfde berichtgegevens die worden geëvalueerd in de respectieve regionale footprints voor het lokale perspectief.

Normalisatie is een variant van het consolidatiescenario, waarbij twee of meer binnenkomende reeksen berichten hetzelfde soort informatie bevatten, maar met verschillende structuren of verschillende coderingen, en de berichten moeten worden getranscodeerd of getransformeerd voordat ze kunnen worden gebruikt.
Normalisatie kan ook cryptografisch werk omvatten, zoals het ontsleutelen van end-to-end versleutelde nettoladingen en het opnieuw versleutelen met verschillende sleutels en algoritmen voor de downstream-consumenten doelgroep.
Splitsen en routeren
Service Bus-onderwerpen en hun abonnementsregels worden vaak gebruikt voor het filteren van een stroom berichten voor een bepaalde doelgroep en die doelgroep heeft vervolgens de gefilterde set opgehaald uit een abonnement.

In een globaal systeem waarin de doelgroep voor deze berichten wereldwijd wordt gedistribueerd of deel uitmaakt van verschillende toepassingen, kan replicatie worden gebruikt om berichten van een dergelijk abonnement over te dragen naar een wachtrij of onderwerp in een andere naamruimte waar ze worden gebruikt.
Replicatietoepassingen in Azure Functions
Voor het implementeren van de bovenstaande patronen is een schaalbare en betrouwbare uitvoeringsomgeving vereist voor de replicatietaken die u wilt configureren en uitvoeren. In Azure is de runtime-omgeving die het meest geschikt is voor staatloze taken Azure Functions.
Azure Functions kan worden uitgevoerd onder een door Azure beheerde identiteit , zodat de replicatietaken kunnen worden geïntegreerd met de regels voor op rollen gebaseerd toegangsbeheer van de bron- en doelservices zonder dat u geheimen langs het replicatiepad hoeft te beheren. Voor replicatiebronnen en -doelen waarvoor expliciete referenties zijn vereist, kan Azure Functions de configuratiewaarden voor deze referenties bevatten in strikt toegangsbeheerde opslag in Azure Key Vault.
Met Azure Functions kunnen de replicatietaken bovendien rechtstreeks worden geïntegreerd met virtuele Azure-netwerken en service-eindpunten voor alle Azure-berichtenservices en is deze direct geïntegreerd met Azure Monitor.
Het belangrijkste is dat Azure Functions vooraf gebouwde, schaalbare triggers en uitvoerbindingen heeft voor Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid en Azure Queue Storage, aangepaste extensies voor RabbitMQ en Apache Kafka. De meeste triggers passen zich dynamisch aan de doorvoerbehoeften aan door het aantal gelijktijdige uitvoerexemplaren omhoog en omlaag te schalen op basis van gedocumenteerde metrische gegevens.
Met het Azure Functions-verbruiksplan kunnen de vooraf gemaakte triggers zelfs omlaag worden geschaald naar nul, terwijl er geen berichten beschikbaar zijn voor replicatie. Dit betekent dat u geen kosten in rekening brengt voor het gereed houden van de configuratie om weer omhoog te schalen. Het belangrijkste nadeel van het gebruik van het verbruiksabonnement is dat de latentie voor replicatietaken 'wakker worden' van deze status aanzienlijk hoger is dan bij de hostingplannen waar de infrastructuur wordt uitgevoerd.
In tegenstelling tot al deze, de meest voorkomende replicatie-engines voor berichten en gebeurtenissen, zoals De MirrorMaker van Apache Kafka, moet u zelf een hostingomgeving bieden en de replicatie-engine zelf schalen. Dit omvat het configureren en integreren van de beveiligings- en netwerkfuncties en het faciliteren van de stroom van bewakingsgegevens, en u hebt nog steeds geen mogelijkheid om aangepaste replicatietaken in de stroom te injecteren.
Replicatietaken met Azure Logic Apps
Een niet-coderend alternatief voor het uitvoeren van replicatie met Behulp van Functions is in plaats daarvan Logic Apps te gebruiken. Logic Apps heeft vooraf gedefinieerde replicatietaken voor Service Bus. Dit kan helpen bij het instellen van replicatie tussen verschillende exemplaren en kan worden aangepast voor verdere aanpassingen.
Volgende stappen
In dit artikel hebben we een reeks federatiepatronen verkend en de rol van Azure Functions uitgelegd als de gebeurtenis- en berichtenreplicatieruntime in Azure.
Vervolgens kunt u lezen hoe u een replicatortoepassing instelt met Azure Functions en hoe u vervolgens gebeurtenisstromen repliceert tussen Event Hubs en verschillende andere gebeurtenis- en berichtensystemen: