Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Dit artikel bevat richtlijnen voor best practices waarmee u de prestaties kunt optimaliseren, kosten kunt verlagen en uw Azure Storage-account met Data Lake Storage kunt beveiligen.
Zie de volgende artikelen voor algemene suggesties voor het structureren van een data lake:
- Overzicht van Azure Data Lake Storage voor het scenario voor gegevensbeheer en analyse
- Drie Azure Data Lake Storage-accounts inrichten voor elke datalandingszone
Documentatie zoeken
Azure Data Lake Storage is geen toegewezen service of accounttype. Het is een set mogelijkheden die ondersteuning bieden voor analyseworkloads met hoge doorvoer. De Data Lake Storage-documentatie bevat aanbevolen procedures en richtlijnen voor het gebruik van deze mogelijkheden. Zie de documentatie-inhoud voor Blob Storage voor alle andere aspecten van accountbeheer, zoals het instellen van netwerkbeveiliging, ontwerpen voor hoge beschikbaarheid en herstel na noodgevallen.
Functieondersteuning en bekende problemen evalueren
Gebruik het volgende patroon wanneer u uw account configureert voor het gebruik van Blob Storage-functies.
Raadpleeg het artikel over de ondersteuning van Blob Storage-functies in Azure Storage-accounts om te bepalen of een functie volledig wordt ondersteund in uw account. Sommige functies worden nog niet ondersteund of hebben gedeeltelijke ondersteuning in accounts met Data Lake Storage. Functieondersteuning wordt altijd uitgebreid, dus zorg ervoor dat u dit artikel regelmatig bekijkt voor updates.
Raadpleeg het artikel Bekende problemen met Azure Data Lake Storage om te zien of er beperkingen of speciale richtlijnen zijn voor de functie die u wilt gebruiken.
Scan feature-artikelen voor richtlijnen die specifiek zijn voor accounts met Data Lake Storage.
Meer informatie over de termen die worden gebruikt in documentatie
Wanneer u tussen inhoudssets navigeert, ziet u enkele kleine terminologieverschillen. Inhoud die wordt aanbevolen in de documentatie voor Blob Storage, gebruikt bijvoorbeeld de term blob in plaats van het bestand. Technisch gezien worden de bestanden die u uploadt naar uw opslagaccount blobs in uw account. Daarom is de term juist. De term blob kan echter verwarring veroorzaken als u gewend bent aan de term bestand. U ziet ook de term container die wordt gebruikt om naar een bestandssysteem te verwijzen. Beschouw deze termen als synoniem.
Overweeg premium
Als uw workloads een lage consistente latentie vereisen en/of een groot aantal invoeruitvoerbewerkingen per seconde (IOP) vereisen, kunt u overwegen om een premium blok-blobopslagaccount te gebruiken. Dit type account maakt gegevens beschikbaar via hardware met hoge prestaties. Gegevens worden opgeslagen op SSD's (Solid State Drives), die zijn geoptimaliseerd voor lage latentie. SSD's bieden een hogere doorvoer in vergelijking met traditionele harde schijven. De opslagkosten van premiumprestaties zijn hoger, maar transactiekosten zijn lager. Als uw workloads daarom een groot aantal transacties uitvoeren, kan een Premium Performance Block Blob-account voordelig zijn.
Als uw opslagaccount wordt gebruikt voor analyse, raden we u ten zeerste aan Azure Data Lake Storage te gebruiken samen met een premium blok-blob-opslagaccount. Deze combinatie van premium blok-blob-opslagaccounts samen met een Data Lake Storage-account wordt de Premium-laag voor Azure Data Lake Storage genoemd.
Optimaliseren voor datainvoer
Wanneer u gegevens uit een bronsysteem opneemt, kunnen de bronhardware, de bronnetwerkhardware of de netwerkverbinding met uw opslagaccount een knelpunt zijn.
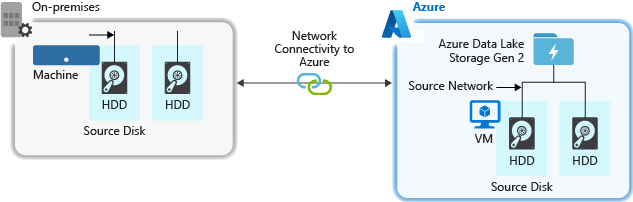
Hardwarebronnen
Of u nu on-premises machines of virtuele machines (VM's) in Azure gebruikt, zorg ervoor dat u zorgvuldig de juiste hardware selecteert. Voor schijfhardware kunt u ssd's (Solid State Drives) gebruiken en schijfhardware kiezen met snellere spindels. Gebruik voor netwerkhardware de snelste NIC (Network Interface Controllers) zo mogelijk. In Azure raden we Azure D14-VM's aan, die over de juiste krachtige schijf- en netwerkhardware beschikken.
Netwerkverbinding met het opslagaccount
De netwerkverbinding tussen uw brongegevens en uw opslagaccount kan soms een knelpunt zijn. Wanneer uw brongegevens on-premises zijn, kunt u overwegen een toegewezen koppeling met Azure ExpressRoute te gebruiken. Als uw brongegevens zich in Azure bevinden, kunnen de prestaties het beste worden uitgevoerd wanneer de gegevens zich in dezelfde Azure-regio bevinden als uw Data Lake Storage-account.
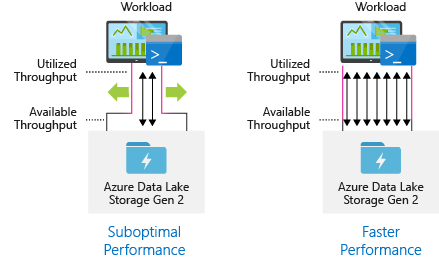
Hulpprogramma's voor gegevensopname configureren voor maximale parallelle uitvoering
Als u de beste prestaties wilt bereiken, gebruikt u alle beschikbare doorvoer door zoveel mogelijk lees- en schrijfbewerkingen parallel uit te voeren.
De volgende tabel bevat een overzicht van de belangrijkste instellingen voor verschillende populaire data-ingestietools.
| Werktuig | Instellingen |
|---|---|
| DistCp | -m (toewijzer) |
| Azure Data Factory | parallelle kopieën |
| Sqoop | fs.azure.block.size, -m (mapper) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Notitie
De algehele prestaties van uw opnamebewerkingen zijn afhankelijk van andere factoren die specifiek zijn voor het hulpprogramma dat u gebruikt om gegevens op te nemen. Zie de documentatie voor elk hulpprogramma dat u wilt gebruiken voor de beste actuele richtlijnen.
Uw account kan worden geschaald om de benodigde doorvoer voor alle analysescenario's te bieden. Standaard biedt een Data Lake Storage-account voldoende doorvoer in de standaardconfiguratie om te voldoen aan de behoeften van een brede categorie gebruiksvoorbeelden. Als u de standaardlimiet bereikt, kan het account worden geconfigureerd om meer doorvoer te bieden door contact op te leggen met de ondersteuning van Azure.
Gestructureerde gegevenssets
Overweeg de structuur van uw gegevens vooraf te plannen. Bestandsindeling, bestandsgrootte en mapstructuur kunnen allemaal van invloed zijn op de prestaties en kosten.
Bestandsindelingen
Gegevens kunnen in verschillende indelingen worden opgenomen. Gegevens kunnen worden weergegeven in door mensen leesbare indelingen, zoals JSON, CSV of XML of als gecomprimeerde binaire indelingen, zoals .tar.gz. Gegevens kunnen ook in verschillende grootten worden geleverd. Gegevens kunnen bestaan uit grote bestanden (een paar terabytes), zoals gegevens uit een export van een SQL-tabel uit uw on-premises systemen. Gegevens kunnen ook worden geleverd in de vorm van een groot aantal kleine bestanden (een paar kilobytes), zoals gegevens uit realtimegebeurtenissen van een IoT-oplossing (Internet of Things). U kunt de efficiëntie en kosten optimaliseren door een geschikte bestandsindeling en bestandsgrootte te kiezen.
Hadoop ondersteunt een set bestandsindelingen die zijn geoptimaliseerd voor het opslaan en verwerken van gestructureerde gegevens. Sommige veelgebruikte indelingen zijn avro-, Parquet- en ORC-indeling (Optimized Row Columnar). Al deze indelingen zijn machineleesbare binaire bestandsindelingen. Ze worden gecomprimeerd om u te helpen bij het beheren van de bestandsgrootte. Ze hebben een schema dat is ingesloten in elk bestand, waardoor ze zelfbeschrijfd worden. Het verschil tussen deze indelingen is de wijze waarop gegevens worden opgeslagen. Avro slaat gegevens op in een rijindeling en de Parquet- en ORC-indelingen slaan gegevens op in een kolomindeling.
Overweeg het gebruik van de Avro-bestandsindeling in gevallen waarin uw I/O-patronen veel meer schrijfintensief zijn of de querypatronen de voorkeur geven aan het ophalen van meerdere rijen met records in hun geheel. De Avro-indeling werkt bijvoorbeeld goed met een berichtenbus zoals Event Hubs of Kafka die meerdere gebeurtenissen/berichten achter elkaar schrijven.
Overweeg Parquet- en ORC-bestandsindelingen wanneer de I/O-patronen meer leesintensief zijn of wanneer de querypatronen zijn gericht op een subset van kolommen in de records. Leestransacties kunnen worden geoptimaliseerd om specifieke kolommen op te halen in plaats van de hele record te lezen.
Apache Parquet is een opensource-bestandsindeling die is geoptimaliseerd voor het lezen van zware analysepijplijnen. Met de kolomopslagstructuur van Parquet kunt u niet-relevante gegevens overslaan. Uw query's zijn veel efficiënter omdat ze het bereik kunnen beperken van welke gegevens moeten worden verzonden van opslag naar de analyse-engine. Omdat vergelijkbare gegevenstypen (voor een kolom) samen worden opgeslagen, ondersteunt Parquet ook efficiënte gegevenscompressie- en coderingsschema's die de kosten voor gegevensopslag kunnen verlagen. Services zoals Azure Synapse Analytics, Azure Databricks en Azure Data Factory hebben systeemeigen functionaliteit die profiteert van Parquet-bestandsindelingen.
Bestandsgrootte
Grotere bestanden leiden tot betere prestaties en lagere kosten.
Analyse-engines zoals HDInsight hebben doorgaans een overhead per bestand die taken omvat, zoals het weergeven, controleren van de toegang en het uitvoeren van verschillende metagegevensbewerkingen. Als u uw gegevens zo veel kleine bestanden opslaat, kan dit de prestaties negatief beïnvloeden. In het algemeen kunt u uw gegevens ordenen in grotere bestanden voor betere prestaties (256 MB tot 100 GB). Sommige engines en toepassingen kunnen problemen ondervinden bij het efficiënt verwerken van bestanden die groter zijn dan 100 GB.
Het vergroten van de bestandsgrootte kan ook de transactiekosten verlagen. Lees- en schrijfbewerkingen worden gefactureerd in stappen van 4 megabyte, zodat er kosten in rekening worden gebracht voor bewerkingen, ongeacht of het bestand 4 megabytes of slechts een paar kilobytes bevat. Zie Prijzen voor Azure Data Lake Storage voor meer informatie.
Soms hebben gegevenspijplijnen beperkte controle over de onbewerkte gegevens, die veel kleine bestanden bevatten. Over het algemeen raden we aan dat uw systeem een soort proces heeft om kleine bestanden samen te voegen in grotere bestanden voor gebruik door downstreamtoepassingen. Als u in realtime gegevens verwerkt, kunt u een realtime streaming-engine (zoals Azure Stream Analytics of Spark Streaming) gebruiken met een berichtenbroker (zoals Event Hubs of Apache Kafka) om uw gegevens op te slaan als grotere bestanden. Wanneer u kleine bestanden samenvoegt in grotere bestanden, kunt u deze opslaan in een indeling die is geoptimaliseerd voor lezen, zoals Apache Parquet voor downstreamverwerking.
Mappenstructuur
Elke workload heeft verschillende vereisten voor de manier waarop de gegevens worden gebruikt, maar dit zijn enkele algemene indelingen waarmee u rekening moet houden bij het werken met Internet of Things (IoT), batchscenario's of bij het optimaliseren van tijdreeksgegevens.
IoT-structuur
In IoT-workloads kunnen er veel gegevens worden opgenomen die betrekking hebben op talloze producten, apparaten, organisaties en klanten. Het is belangrijk dat u de indeling van de adreslijst vooraf plant voor de organisatie, beveiliging en efficiënte verwerking van de gegevens voor downstreamgebruikers. Een algemene sjabloon die u moet overwegen, kan de volgende indeling zijn:
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Landingstelemetrie voor een vliegtuigmotor in het VERENIGD Koninkrijk kan er bijvoorbeeld uitzien als de volgende structuur:
- UK/Planes/BA1293/Engine1/2017/08/11/12/
In dit voorbeeld kunt u ACL's gebruiken om de datum aan het einde van de adreslijststructuur te plaatsen om regio's gemakkelijker te beveiligen en zaken te onderwerpen aan specifieke gebruikers en groepen. Als u de datumstructuur aan het begin plaatst, is het veel moeilijker om deze regio's en onderwerpen te beveiligen. Als u bijvoorbeeld alleen toegang wilt verlenen tot UK-gegevens of gegevens van bepaalde vliegtuigen, moet u een afzonderlijke machtiging toepassen voor talloze directory's onder elke uur-directory. Deze structuur zou ook het aantal directory's exponentieel verhogen naarmate de tijd verstrijkt.
Structuur batchtaken
Een veelgebruikte benadering in batchverwerking is het plaatsen van gegevens in een map 'in'. Nadat de gegevens zijn verwerkt, plaatst u de nieuwe gegevens in een 'out'-map, zodat vervolgprocessen deze kunnen gebruiken. Deze mapstructuur wordt soms gebruikt voor taken waarvoor verwerking van afzonderlijke bestanden is vereist en die mogelijk geen enorme parallelle verwerking van grote gegevenssets vereisen. Net zoals de hierboven aanbevolen IoT-structuur heeft een goede directory-structuur de directory's op het hoofdniveau voor zaken zoals regio en onderwerp (bijvoorbeeld organisatie, product of producent). Overweeg datum en tijd in de structuur om betere organisatie, gefilterde zoekopdrachten, beveiliging en automatisering in de verwerking mogelijk te maken. Het granulariteitsniveau voor de datumstructuur wordt bepaald door het interval waarop de gegevens worden geüpload of verwerkt, zoals elk uur, dagelijks of zelfs maandelijks.
Soms is bestandsverwerking mislukt vanwege beschadigde gegevens of onverwachte indelingen. In dergelijke gevallen kan een mapstructuur profiteren van een /slecht map om de bestanden voor verdere inspectie naartoe te verplaatsen. De batchtaak kan ook de rapportage of melding van deze ongeldige bestanden verwerken voor handmatige interventie. Houd rekening met de volgende sjabloonstructuur:
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Regio}/{Onderwerp(en)}/Slecht/{jjjj}/{mm}/{dd}/{uu}/
Een marketingbedrijf ontvangt bijvoorbeeld dagelijkse gegevens van klantupdates van hun klanten in Noord-Amerika. Het kan eruitzien als het volgende fragment voor en na verwerking:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
In het gebruikelijke geval dat batchgegevens rechtstreeks worden verwerkt in databases zoals Hive of traditionele SQL-databases, is er geen behoefte aan een /in- of /out-map, omdat de output al in een aparte map voor de Hive-tabel of externe database wordt geplaatst. Dagelijkse extracten van klanten komen bijvoorbeeld terecht in hun respectieve directory's. Vervolgens zou een service zoals Azure Data Factory, Apache Oozie of Apache Airflow een dagelijkse Hive- of Spark-taak activeren om de gegevens te verwerken en te schrijven in een Hive-tabel.
Tijdreeksgegevensstructuur
Voor Hive-workloads kan partitionering van tijdreeksgegevens helpen sommige query's alleen een subset van de gegevens te lezen, waardoor de prestaties worden verbeterd.
Deze pijplijnen die tijdreeksgegevens opnemen, plaatsen hun bestanden vaak met een gestructureerde naamgeving voor bestanden en mappen. Hieronder ziet u een algemeen voorbeeld voor gegevens die zijn gestructureerd op datum:
/DataSet/JJJJ/MM/DD/datafile_YYYY_MM_DD.tsv
U ziet dat de datum/tijd-informatie zowel als mappen als in de bestandsnaam wordt weergegeven.
Voor datum en tijd is het volgende een gemeenschappelijk patroon
/DataSet/JJJJ/MM/DD/UU/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Nogmaals, de keuze die u maakt met de map en bestandsorganisatie moet optimaliseren voor de grotere bestandsgrootten en een redelijk aantal bestanden in elke map.
Beveiliging instellen
Bekijk eerst de aanbevelingen in het artikel Beveiligingsaanbevelingen voor Blob-opslag. U vindt best practice-richtlijnen voor het beveiligen van uw gegevens tegen onbedoelde of schadelijke verwijdering, het beveiligen van gegevens achter een firewall en het gebruik van Microsoft Entra-id als basis van identiteitsbeheer.
Lees vervolgens het Access Control-model in Azure Data Lake Storage voor richtlijnen die specifiek zijn voor accounts met Data Lake Storage. Dit artikel helpt u inzicht te krijgen in het gebruik van azure RBAC-rollen (op rollen gebaseerd toegangsbeheer) in combinatie met toegangsbeheerlijsten (ACL's) voor het afdwingen van beveiligingsmachtigingen voor mappen en bestanden in uw hiërarchische bestandssysteem.
Opnemen, verwerken en analyseren
Er zijn veel verschillende gegevensbronnen en verschillende manieren waarop die gegevens kunnen worden opgenomen in een Data Lake Storage-account dat is ingeschakeld.
U kunt bijvoorbeeld grote sets gegevens opnemen uit HDInsight- en Hadoop-clusters of kleinere sets met ad-hocgegevens voor prototypetoepassingen. U kunt gestreamde gegevens opnemen die worden gegenereerd door verschillende bronnen, zoals toepassingen, apparaten en sensoren. Voor dit type gegevens kunt u hulpprogramma's gebruiken om de gegevens in realtime vast te leggen en te verwerken en de gebeurtenissen vervolgens in batches naar uw account te schrijven. U kunt ook webserverlogboeken opnemen, die informatie bevatten, zoals de geschiedenis van paginaaanvragen. Voor logboekgegevens kunt u aangepaste scripts of toepassingen schrijven om ze te uploaden, zodat u de flexibiliteit hebt om uw gegevens te uploaden als onderdeel van uw grotere big data-toepassing.
Zodra de gegevens beschikbaar zijn in uw account, kunt u analyses uitvoeren op die gegevens, visualisaties maken en zelfs gegevens downloaden naar uw lokale computer of naar andere opslagplaatsen, zoals een Azure SQL-database of EEN SQL Server-exemplaar.
In de volgende tabel worden hulpprogramma's aanbevolen die u kunt gebruiken voor het opnemen, analyseren, visualiseren en downloaden van gegevens. Gebruik de koppelingen in deze tabel voor hulp bij het configureren en gebruiken van elk hulpprogramma.
| Doel | Gereedschappen & Gereedschapsrichtlijnen |
|---|---|
| Ad-hocgegevens opnemen | Azure Portal, Azure PowerShell, Azure CLI, REST, Azure Storage Explorer, Apache DistCp, AzCopy |
| Relationele gegevens opnemen | Azure Data Factory |
| Webserverlogboeken opnemen | Azure PowerShell, Azure CLI, REST, Azure SDK's (.NET, Java, Python en Node.js), Azure Data Factory |
| Opnemen vanuit HDInsight-clusters | Azure Data Factory, Apache DistCp, AzCopy |
| Opnemen vanuit Hadoop-clusters | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator voor Azure, Azure Data Box |
| Grote gegevenssets opnemen (verschillende terabytes) | Azure ExpressRoute |
| Gegevens verwerken en analyseren | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Gegevens visualiseren | Power BI, Azure Data Lake Storage query versnelling |
| Gegevens downloaden | Azure Portal, PowerShell, Azure CLI, REST, Azure SDK's (.NET, Java, Python en Node.js), Azure Storage Explorer, AzCopy, Azure Data Factory, Apache DistCp |
Notitie
Deze tabel bevat niet de volledige lijst met Azure-services die Data Lake Storage ondersteunen. Zie Azure-services die ondersteuning bieden voor Azure Data Lake Storage voor een lijst met ondersteunde Azure-services, hun ondersteuningsniveau.
Telemetrie bewaken
Het bewaken van het gebruik en de prestaties is een belangrijk onderdeel van het operationeel maken van uw service. Voorbeelden hiervan zijn frequente bewerkingen, bewerkingen met hoge latentie of bewerkingen die leiden tot drosseling aan de servicezijde.
Alle telemetriegegevens voor uw opslagaccount zijn beschikbaar via Azure Storage-logboeken in Azure Monitor. Deze functie integreert uw opslagaccount met Log Analytics en Event Hubs, terwijl u ook logboeken kunt archiveren naar een ander opslagaccount. Als u de volledige lijst met metrische gegevens en resourcelogboeken en het bijbehorende schema wilt bekijken, raadpleeg dan de Azure Storage-referentie voor bewakingsgegevens.
Waar u ervoor kiest om uw logboeken op te slaan, is afhankelijk van hoe u deze wilt openen. Als u bijvoorbeeld in bijna realtime toegang wilt tot uw logboeken en gebeurtenissen in logboeken met andere metrische gegevens van Azure Monitor wilt correleren, kunt u uw logboeken opslaan in een Log Analytics-werkruimte. Voer vervolgens query's uit op uw logboeken met behulp van KQL en ontwerpquery's, waarmee de StorageBlobLogs tabel in uw werkruimte wordt opgesomd.
Als u uw logboeken wilt opslaan voor zowel bijna realtime query's als langetermijnretentie, kunt u uw diagnostische instellingen configureren om logboeken te verzenden naar zowel een Log Analytics-werkruimte als een opslagaccount.
Als u uw logboeken wilt openen via een andere query-engine, zoals Splunk, kunt u uw diagnostische instellingen configureren om logboeken naar een Event Hub te verzenden en logboeken van de Event Hub op te nemen naar uw gekozen bestemming.
Azure Storage-logboeken in Azure Monitor kunnen worden ingeschakeld via Azure Portal, PowerShell, de Azure CLI en Azure Resource Manager-sjablonen. Voor implementaties op schaal kan Azure Policy worden gebruikt met volledige ondersteuning voor hersteltaken. Zie ciphertxt/AzureStoragePolicy voor meer informatie.