Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie leert u hoe u statistieken over uw containers verzamelt met behulp van Azure Blob Storage-inventaris, samen met Azure Databricks.
In deze handleiding leer je hoe je:
- Een inventarisrapport genereren
- Een Azure Databricks-werkruimte en -notebook maken
- Het blob-inventarisbestand lezen
- Het aantal en de totale grootte van blobs, momentopnamen en versies ophalen
- Het aantal blobs ophalen op blobtype en inhoudstype
Prerequisites
Een Azure-abonnement - gratis een account maken
Een Azure-opslagaccount - een opslagaccount maken
Zorg ervoor dat aan uw gebruikersidentiteit de rol Inzender voor opslagblobgegevens is toegewezen.
Een inventarisrapport genereren
Schakel blob-inventarisrapporten in voor uw opslagaccount. Zie Azure Storage-blobinventarisrapporten inschakelen.
Gebruik de volgende configuratie-instellingen:
| Setting | Value |
|---|---|
| Naam van de regel | blobinventory |
| Container | <naam van uw container> |
| Objecttype voor voorraadbeheer | Blob |
| Blobtypen | Blok-blobs, pagina-blobs en toevoeg-blobs |
| Subtypes | blobversies opnemen, momentopnamen opnemen, verwijderde blobs opnemen |
| Blob-inventarisvelden | All |
| Inventarisfrequentie | Daily |
| Exportindeling | CSV |
Mogelijk moet u maximaal 24 uur wachten nadat u inventarisrapporten hebt ingeschakeld voordat uw eerste rapport is gegenereerd.
Azure Databricks configureren
In deze sectie maakt u een Azure Databricks-werkruimte en -notebook. Verderop in deze zelfstudie plakt u codefragmenten in notebookcellen en voert u deze uit om containerstatistieken te verzamelen.
Maak een Azure Databricks-werkruimte. Zie Een Azure Databricks-werkruimte maken.
Maak een nieuw notitieblok. Zie Een notitieblok maken.
Kies Python als de standaardtaal van het notebook.
Het blob-inventarisbestand lezen
Kopieer en plak het volgende codeblok in de eerste cel, maar voer deze code nog niet uit.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')Vervang in dit codeblok de volgende waarden:
Vervang de waarde van de tijdelijke plaatsaanduiding
<storage-account-name>door de naam van uw opslagaccount.Vervang de waarde van de
<storage-account-key>tijdelijke aanduiding door de accountsleutel van uw opslagaccount.Vervang de waarde van de
<container-name>tijdelijke aanduiding door de container die de inventarisrapporten bevat.Vervang de
<blob-inventory-file-name>tijdelijke aanduiding door de volledig gekwalificeerde naam van het inventarisbestand (bijvoorbeeld:2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv).Als uw account een hiërarchische naamruimte heeft, stelt u de
hierarchical_namespace_enabledvariabele in opTrue.
Druk op de knop Uitvoeren om de code in deze cel uit te voeren.
Blobaantal en -grootte ophalen
Plak de volgende code in een nieuwe cel:
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Druk op de knop Uitvoeren om de cel uit te voeren.
In het notebook wordt het aantal blobs in een container en het aantal bytes weergegeven dat door blobs in de container wordt bezet.

Aantal momentopnamen en grootte ophalen
Plak de volgende code in een nieuwe cel:
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Druk op de knop Uitvoeren om de cel uit te voeren.
In het notebook wordt het aantal momentopnamen en het totale aantal bytes weergegeven dat wordt bezet door blob-momentopnamen.

Aantal versies en grootte ophalen
Plak de volgende code in een nieuwe cel:
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Druk op Shift+Enter om de cel uit te voeren.
In het notebook worden het aantal blobversies en het totale aantal bytes weergegeven dat door blobversies in beslag wordt genomen.

Het aantal blobs ophalen op blobtype
Plak de volgende code in een nieuwe cel:
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))Druk op Shift+Enter om de cel uit te voeren.
In het notebook wordt het aantal blobtypen per type weergegeven.

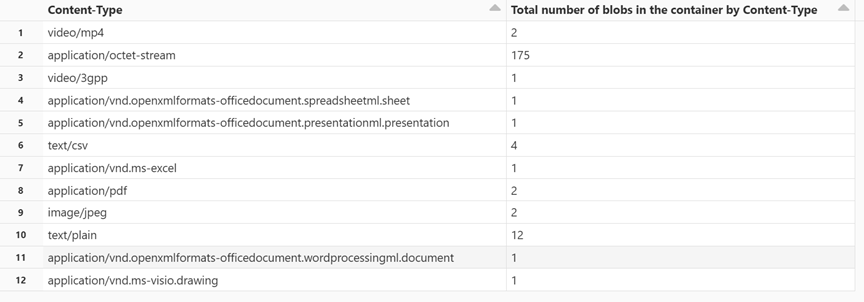
Blobaantal ophalen per inhoudstype
Plak de volgende code in een nieuwe cel:
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))Druk op Shift+Enter om de cel uit te voeren.
In het notebook wordt het aantal blobs weergegeven dat aan elk inhoudstype is gekoppeld.
Het cluster beëindigen
Als u onnodige facturering wilt voorkomen, beëindigt u uw rekenresource. Zie Een berekening beëindigen.
Volgende stappen
Meer informatie over het gebruik van Azure Synapse om het aantal blobs en de totale grootte van blobs per container te berekenen. Zie Blob-telling en totale grootte per container berekenen met behulp van Azure Storage-inventaris
Meer informatie over het genereren en visualiseren van statistieken die containers en blobs beschrijven. Zie Tutorial: Blob-inventarisrapporten analyseren
Ontdek hoe u de kosten kunt optimaliseren door uw blobs en containers te analyseren. Zie de volgende artikelen:
Kosten plannen en beheren voor Azure Blob-opslag
De kosten van archiveringsgegevens schatten
Kosten optimaliseren door de levenscyclus van gegevens automatisch te beheren