Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Door te begrijpen hoe uw blobs en containers worden opgeslagen, georganiseerd en gebruikt in productie, kunt u de balans tussen kosten en prestaties beter optimaliseren.
In deze zelfstudie leert u hoe u statistieken kunt genereren en visualiseren, zoals gegevensgroei in de loop van de tijd, gegevens die in de loop van de tijd zijn toegevoegd, het aantal gewijzigde bestanden, de grootte van blobmomentopnamen, toegangspatronen voor elke laag en hoe gegevens worden gedistribueerd, zowel op dit moment als in de loop van de tijd (bijvoorbeeld gegevens over lagen, bestandstypen, in containers en blobtypen).
In deze zelfstudie leert u het volgende:
- Een blob-inventarisrapport genereren
- Een Synapse-werkruimte instellen
- Synapse Studio instellen
- Analytische gegevens genereren in Synapse Studio
- Resultaten visualiseren in Power BI
Vereisten
Een Azure-abonnement - gratis een account maken
Een Azure-opslagaccount - een opslagaccount maken
Zorg ervoor dat aan uw gebruikersidentiteit de rol Inzender voor opslagblobgegevens is toegewezen.
Een inventarisrapport genereren
Schakel blob-inventarisrapporten in voor uw opslagaccount. Zie Azure Storage-blobinventarisrapporten inschakelen.
Mogelijk moet u maximaal 24 uur wachten nadat u inventarisrapporten hebt ingeschakeld voordat uw eerste rapport is gegenereerd.
Een Synapse-werkruimte instellen
Een Azure Synapse-werkruimte maken. Zie Een Azure Synapse-werkruimte maken.
Notitie
Als onderdeel van het maken van de werkruimte maakt u een opslagaccount met een hiërarchische naamruimte. Azure Synapse slaat Spark-tabellen en toepassingslogboeken op in dit account. Azure Synapse verwijst naar dit account als het primaire opslagaccount. Om verwarring te voorkomen, wordt in dit artikel het rapportaccount voor de termenvoorraad gebruikt om te verwijzen naar het account dat inventarisrapporten bevat.
Wijs in de Synapse-werkruimte de rol Inzender toe aan uw gebruikersidentiteit . Zie Azure RBAC: De rol Eigenaar voor de werkruimte.
Geef de Synapse-werkruimte toestemming om toegang te krijgen tot de inventarisrapporten in uw opslagaccount door naar uw voorraadrapportaccount te navigeren en vervolgens de rol Inzender voor opslagblobgegevens toe te wijzen aan de door het systeem beheerde identiteit van de werkruimte. Zie Azure-rollen toewijzen met Azure Portal.
Navigeer naar het primaire opslagaccount en wijs de rol Inzender voor Blob Storage toe aan uw gebruikersidentiteit.
Synapse Studio instellen
Open uw Synapse-werkruimte in Synapse Studio. Zie Synapse Studio openen.
Zorg ervoor dat in Synapse Studio de rol van Synapse-beheerder is toegewezen aan uw identiteit. Zie Synapse RBAC: Synapse Administrator-rol voor de werkruimte.
Maak een Apache Spark-pool. Zie Een serverloze Apache Spark-pool maken.
Het voorbeeldnotebook instellen en uitvoeren
In deze sectie genereert u statistische gegevens die u in een rapport visualiseert. Ter vereenvoudiging van deze zelfstudie maakt deze sectie gebruik van een voorbeeldconfiguratiebestand en een pySpark-voorbeeldnotebook. Het notebook bevat een verzameling query's die worden uitgevoerd in Azure Synapse Studio.
Het voorbeeldconfiguratiebestand wijzigen en uploaden
Download het BlobInventoryStorageAccountConfiguration.json-bestand .
Werk de volgende tijdelijke aanduidingen van dat bestand bij:
Stel
storageAccountNamedeze in op de naam van uw voorraadrapportaccount.Stel
destinationContainerin op de naam van de container die de inventarisrapporten bevat.Stel
blobInventoryRuleNamedeze in op de naam van de inventarisrapportregel die de resultaten heeft gegenereerd die u wilt analyseren.Ingesteld
accessKeyop de accountsleutel van het voorraadrapportaccount.
Upload dit bestand naar de container in uw primaire opslagaccount dat u hebt opgegeven toen u de Synapse-werkruimte maakte.
Het PySpark-voorbeeldnotebook importeren
Download het voorbeeldnotebook ReportAnalysis.ipynb .
Notitie
Zorg ervoor dat u dit bestand opslaat met de
.ipynbextensie.Open uw Synapse-werkruimte in Synapse Studio. Zie Synapse Studio openen.
Selecteer in Synapse Studio het tabblad Ontwikkelen .
Selecteer het plusteken (+) om een item toe te voegen.
Selecteer Importeren, blader naar het voorbeeldbestand dat u hebt gedownload, selecteer dat bestand en selecteer Openen.
Het dialoogvenster Eigenschappen wordt weergegeven.
Selecteer in het dialoogvenster Eigenschappen de koppeling Sessie configureren.
Het dialoogvenster Sessie configureren wordt geopend.
Selecteer in de vervolgkeuzelijst Koppelen aan het dialoogvenster Sessie configureren de Spark-pool die u eerder in dit artikel hebt gemaakt. Selecteer vervolgens de knop Toepassen .
Het Python-notebook wijzigen
Stel in de eerste cel van het Python-notebook de waarde van de
storage_accountvariabele in op de naam van het primaire opslagaccount.Werk de waarde van de
container_namevariabele bij naar de naam van de container in dat account dat u hebt opgegeven toen u de Synapse-werkruimte maakte.Selecteer de knop Publiceren.
Het PySpark-notebook uitvoeren
Selecteer Alles uitvoeren in het PySpark-notebook.
Het duurt enkele minuten om de Spark-sessie te starten en nog een paar minuten om de inventarisrapporten te verwerken. De eerste uitvoering kan enige tijd duren als er talloze inventarisrapporten moeten worden verwerkt. Volgende uitvoeringen verwerken alleen de nieuwe inventarisrapporten die zijn gemaakt sinds de laatste uitvoering.
Notitie
Als u wijzigingen aanbrengt in het notitieblok, wordt het notitieblok uitgevoerd, moet u deze wijzigingen publiceren met behulp van de knop Publiceren .
Controleer of het notitieblok is uitgevoerd door het tabblad Gegevens te selecteren.
Een database met de naam reportdata moet worden weergegeven op het tabblad Werkruimte van het deelvenster Gegevens . Als deze database niet wordt weergegeven, moet u mogelijk de webpagina vernieuwen.
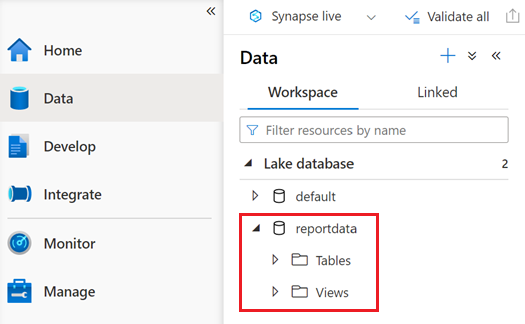
De database bevat een set tabellen. Elke tabel bevat informatie die wordt verkregen door de query's uit te voeren vanuit het PySpark-notebook.
Als u de inhoud van een tabel wilt bekijken, vouwt u de map Tabellen van de rapportgegevensdatabase uit. Klik vervolgens met de rechtermuisknop op een tabel, selecteer SQL-script selecteren en selecteer vervolgens TOP 100 rijen selecteren.
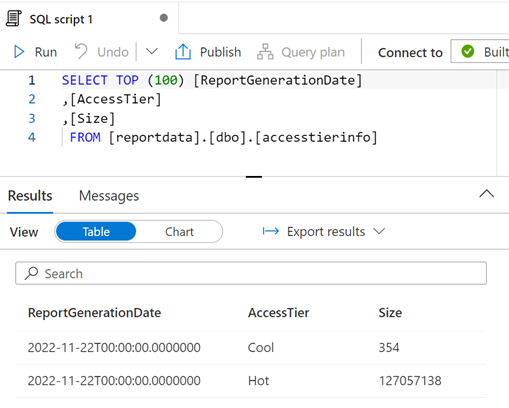
U kunt de query indien nodig wijzigen en vervolgens Uitvoeren selecteren om de resultaten weer te geven.
De gegevens visualiseren
Download het reportAnalysis.pbit-voorbeeldrapportbestand .
Open Power BI Desktop. Zie Power BI Desktop downloaden voor installatierichtlijnen.
Selecteer in Power BI Bestand, Rapport openen en blader vervolgens door rapporten.
Wijzig in het dialoogvenster Openen het bestandstype in Power BI-sjabloonbestanden (*.pbit).).

Blader naar de locatie van het ReportAnalysis.pbit-bestand dat u hebt gedownload en selecteer vervolgens Openen.
Er wordt een dialoogvenster weergegeven waarin u wordt gevraagd de naam van de Synapse-werkruimte en de naam van de gegevensdatabase op te geven.
Stel in het dialoogvenster het veld synapse_workspace_name in op de naam van de werkruimte en stel het veld database_name in op
reportdata. Selecteer vervolgens de knop Laden .
Er wordt een rapport weergegeven met visualisaties van de gegevens die door het notebook zijn opgehaald. In de volgende afbeeldingen ziet u de typen grafieken en grafieken die in dit rapport worden weergegeven.
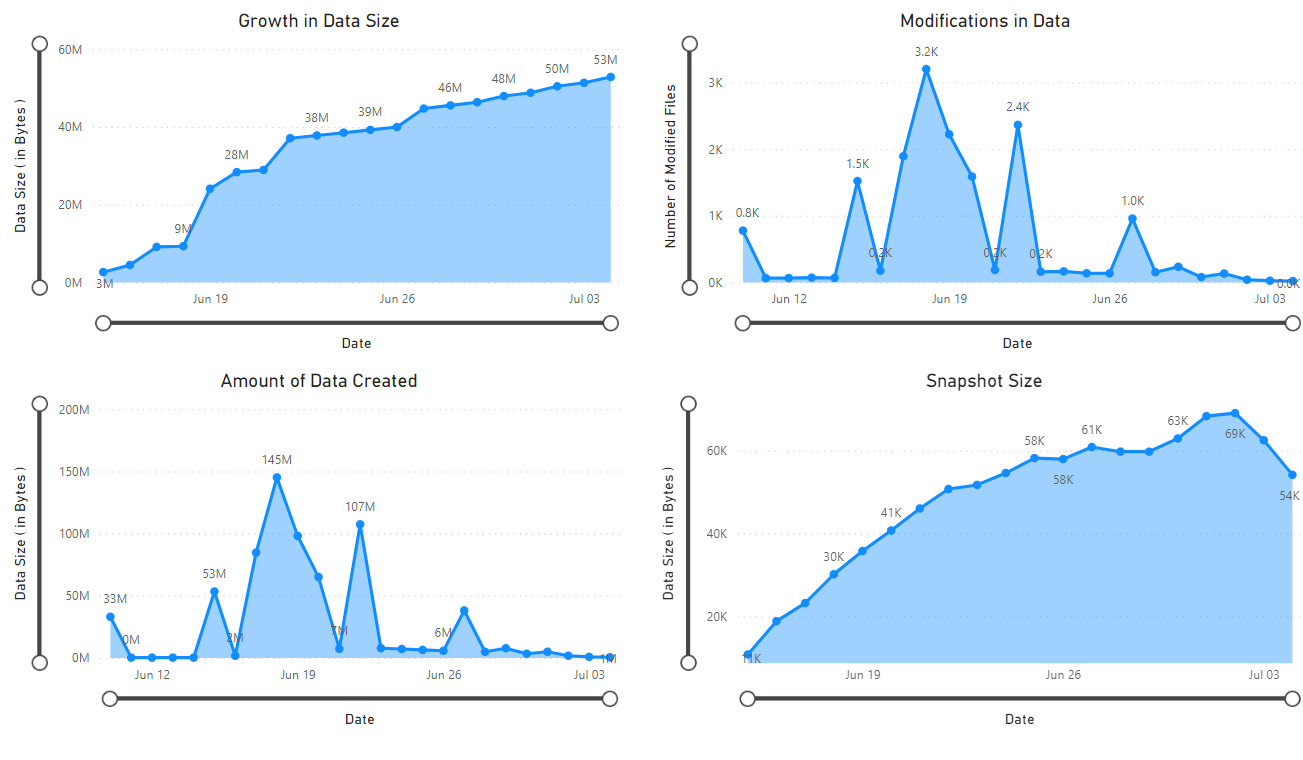
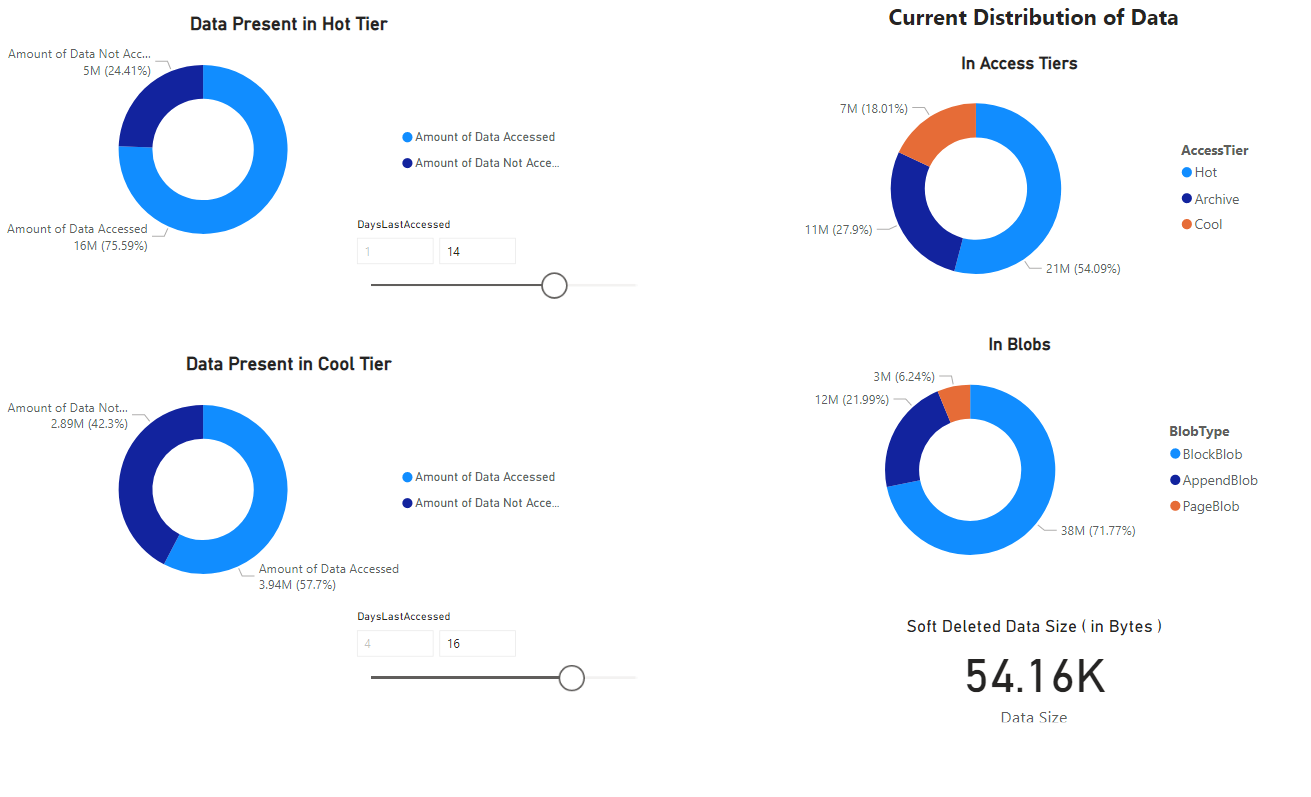
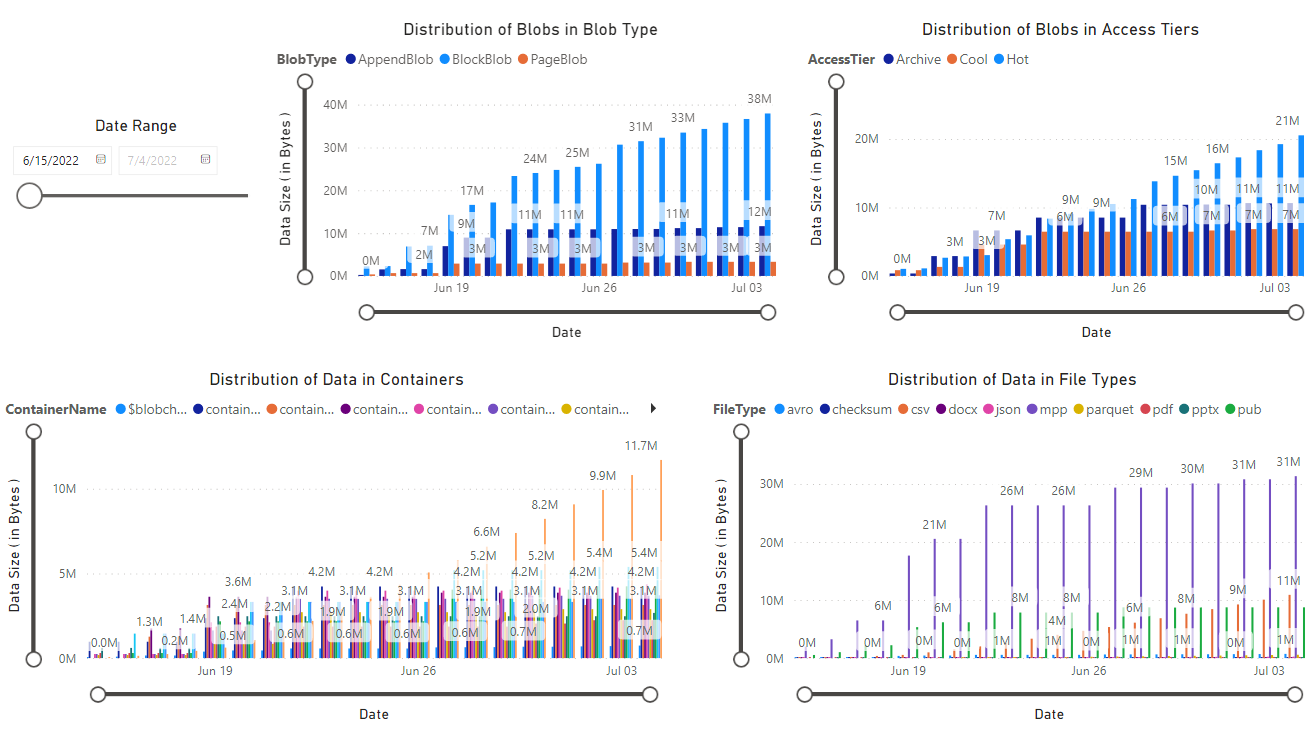
Volgende stappen
Stel een Azure Synapse-pijplijn in om uw notebook regelmatig uit te voeren. Op die manier kunt u nieuwe inventarisrapporten verwerken terwijl ze worden gemaakt. Na de eerste uitvoering analyseert elk van de volgende uitvoeringen incrementele gegevens en werkt u vervolgens de tabellen bij met de resultaten van die analyse. Zie Integreren met pijplijnen voor hulp.
Meer informatie over manieren om afzonderlijke containers in uw opslagaccount te analyseren. Zie de volgende artikelen:
Bereken het aantal blobs en de totale grootte per container met behulp van Azure Storage-inventaris
Zelfstudie: Containerstatistieken berekenen met behulp van Databricks
Meer informatie over manieren om uw kosten te optimaliseren op basis van de analyse van uw blobs en containers. Zie de volgende artikelen:
Kosten plannen en beheren voor Azure Blob-opslag
De kosten van archiveringsgegevens schatten
Kosten optimaliseren door de levenscyclus van gegevens automatisch te beheren