Instructies: Een lake-database wijzigen
In dit artikel leert u hoe u een bestaande lake-database in Azure Synapse kunt wijzigen met behulp van de ontwerpfunctie voor databases. Met de databaseontwerper kunt u eenvoudig een database maken en implementeren zonder code te schrijven.
Vereisten
- Synapse-beheerdersmachtigingen of Synapse-inzenders zijn vereist voor de Synapse-werkruimte voor het maken van een lake-database.
- Inzendermachtigingen voor Opslagblobgegevens zijn vereist voor data lake wanneer u de optie Tabel maken van data lake gebruikt.
Database-eigenschappen wijzigen
Selecteer in de startpagina van de Azure Synapse Analytics-werkruimte het tabblad Gegevens aan de linkerkant. Het tabblad Gegevens wordt geopend, u ziet de lijst met databases die al aanwezig zijn in uw werkruimte.
Beweeg de muisaanwijzer over de sectie Databases en selecteer het beletselteken ... naast de database die u wilt wijzigen en kies vervolgens Openen.
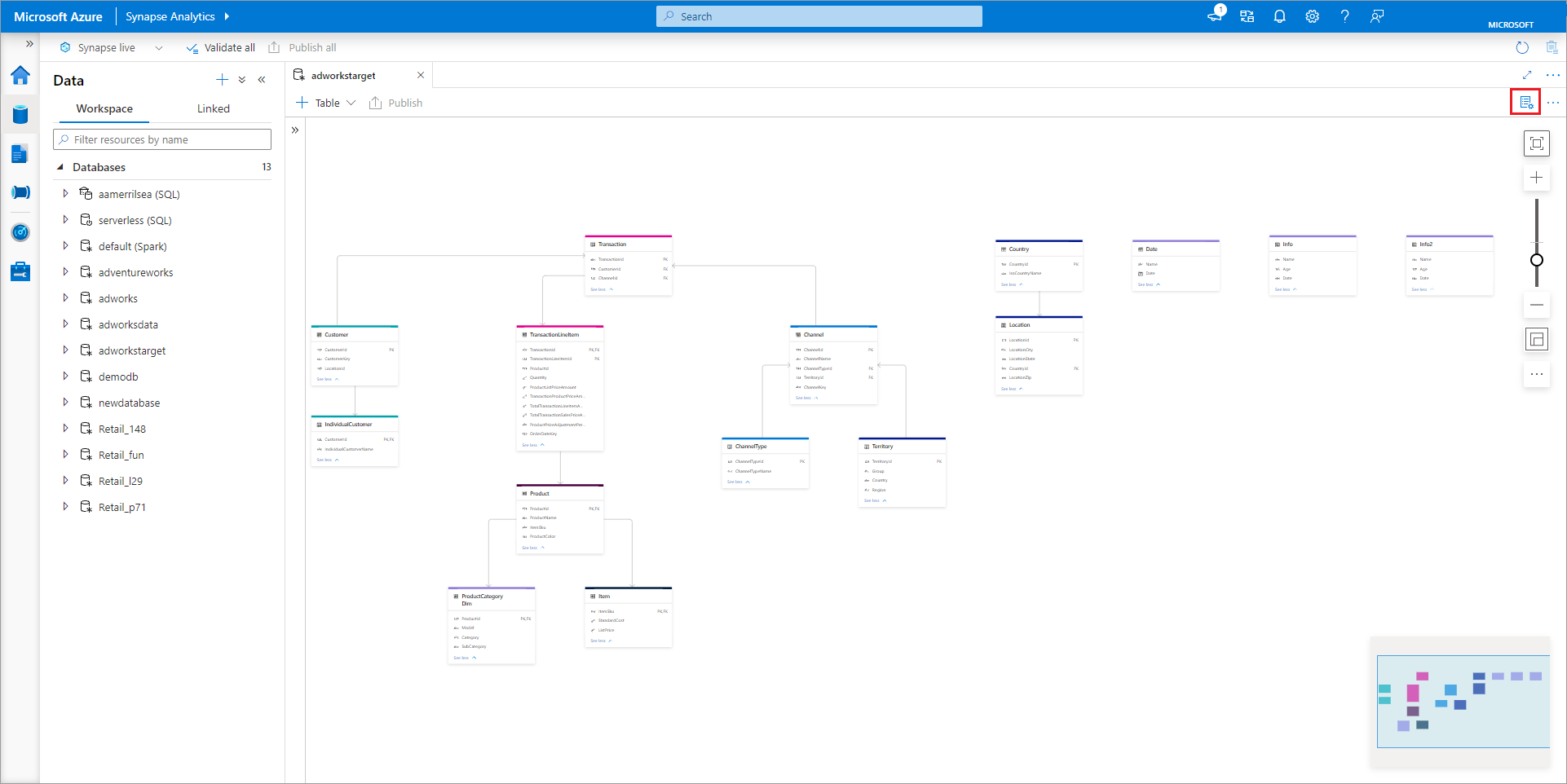
Het tabblad Databaseontwerper wordt geopend met de geselecteerde database die op het canvas is geladen.
De databaseontwerper heeft het deelvenster Eigenschappen dat kan worden geopend door in de rechterbovenhoek van het tabblad het pictogram Eigenschappen te selecteren.
- Naam Namen kunnen niet worden bewerkt nadat de database is gepubliceerd, dus controleer of de naam die u kiest juist is.
- Beschrijving Het is optioneel om uw database een beschrijving te geven, maar hiermee kunnen gebruikers het doel van de database begrijpen.
- Opslaginstellingen voor database is een sectie met de standaardopslaggegevens voor tabellen in de database. De standaardinstellingen worden toegepast op elke tabel in de database, tenzij deze wordt overschreven op de tabel zelf.
- Gekoppelde service is de standaard gekoppelde service die wordt gebruikt om uw gegevens op te slaan in Azure Data Lake Storage. De standaard gekoppelde service die is gekoppeld aan de Synapse-werkruimte wordt weergegeven, maar u kunt de gekoppelde service wijzigen in elk GEWENST ADLS-opslagaccount.
- Invoermap die wordt gebruikt voor het instellen van de standaardcontainer en het standaardmappad binnen die gekoppelde service met behulp van de bestandsbrowser of het handmatig bewerken van het pad met het potloodpictogram.
- Lake-databases in Azure Synapse ondersteuning bieden voor parquet en tekst met scheidingstekens als opslagindelingen voor gegevens.
Als u een tabel wilt toevoegen aan de database, selecteert u de knop + Tabel .
- Met Aangepast wordt een nieuwe tabel aan het canvas toegevoegd.
- Vanuit sjabloon opent u de galerie en kunt u een databasesjabloon selecteren die u wilt gebruiken bij het toevoegen van een nieuwe tabel. Zie Lake Database maken op basis van databasesjabloon voor meer informatie.
- Vanuit data lake kunt u een tabelschema importeren met behulp van gegevens die al in uw lake aanwezig zijn.
selecteer Aangepast. Er wordt een nieuwe tabel weergegeven op het canvas met de naam Table_1.
Vervolgens kunt u Table_1 aanpassen, inclusief de tabelnaam, beschrijving, opslaginstellingen, kolommen en relaties. Zie de sectie Tabellen in een database aanpassen hieronder.
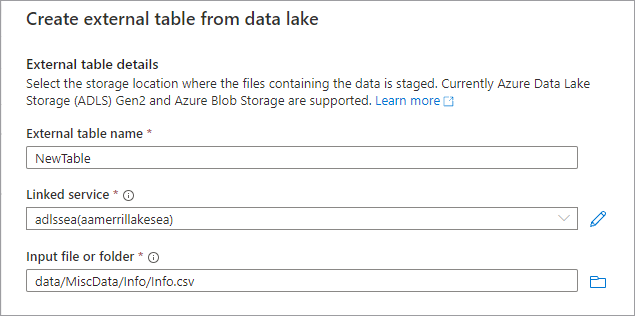
Voeg een nieuwe tabel toe vanuit de data lake door + Tabel en vervolgens Van data lake te selecteren.
Het deelvenster Externe tabel maken op basis van data lake wordt weergegeven. Vul het deelvenster in met de onderstaande details en selecteer Doorgaan.
- De naam van de externe tabel is de naam die u wilt geven aan de tabel die u maakt.
- Gekoppelde service de gekoppelde service met de Azure Data Lake Storage locatie waar uw gegevensbestand zich bevindt.
-
Invoerbestand of -map gebruikt de bestandsbrowser om naar een bestand in uw lake te navigeren en het bestand te selecteren dat u wilt gebruiken om een tabel te maken.
- In het volgende scherm ziet Azure Synapse een voorbeeld van het bestand en detecteert het schema.
- U komt terecht op de pagina Nieuwe externe tabel, waar u alle instellingen met betrekking tot de gegevensindeling kunt bijwerken en Een voorbeeld van gegevens kunt bekijken om te controleren of Azure Synapse het bestand correct hebt geïdentificeerd.
- Als u tevreden bent met de instellingen, selecteert u Maken.
- Een nieuwe tabel met de naam die u hebt geselecteerd, wordt toegevoegd aan het canvas en in de sectie Opslaginstellingen voor tabel wordt het bestand weergegeven dat u hebt opgegeven.
Nu de database is aangepast, is het tijd om deze te publiceren. Als u Git-integratie met uw Synapse-werkruimte gebruikt, moet u uw wijzigingen doorvoeren en samenvoegen in de samenwerkingsvertakking. Meer informatie over broncodebeheer vindt u in Azure Synapse. Als u de Synapse Live-modus gebruikt, kunt u 'publiceren' selecteren.
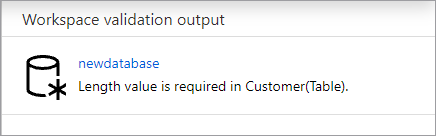
Uw database wordt gevalideerd op fouten voordat deze wordt gepubliceerd. Eventuele gevonden fouten worden weergegeven op het tabblad Meldingen met instructies voor het oplossen van de fout.
Als u publiceert, wordt uw databaseschema gemaakt in de Azure Synapse Metastore. Na publicatie zijn de database- en tabelobjecten zichtbaar voor andere Azure-services en kunnen de metagegevens van uw database naar apps zoals Power BI of Microsoft Purview stromen.
Tabellen in een database aanpassen
Met de databaseontwerper kunt u alle tabellen in uw database volledig aanpassen. Wanneer u een tabel selecteert, zijn er drie tabbladen beschikbaar, elk met instellingen die betrekking hebben op het schema of de metagegevens van de tabel.
Algemeen
Het tabblad Algemeen bevat informatie die specifiek is voor de tabel zelf.
Geef de naam van de tabel een naam. De tabelnaam kan worden aangepast aan elke unieke waarde in de database. Meerdere tabellen met dezelfde naam zijn niet toegestaan.
Overgenomen van (optioneel) is deze waarde aanwezig als de tabel is gemaakt op basis van een databasesjabloon. Het kan niet worden bewerkt en vertelt de gebruiker van welke sjabloontabel deze is afgeleid.
Beschrijving een beschrijving van de tabel. Als de tabel is gemaakt op basis van een databasesjabloon, bevat deze een beschrijving van het concept dat door deze tabel wordt vertegenwoordigd. Dit veld kan worden bewerkt en kan worden gewijzigd zodat deze overeenkomt met de beschrijving die overeenkomt met uw bedrijfsvereisten.
Weergavemap bevat de naam van de bedrijfsmap waaronder deze tabel is gegroepeerd als onderdeel van de databasesjabloon. Voor aangepaste tabellen is deze waarde 'Overige'.
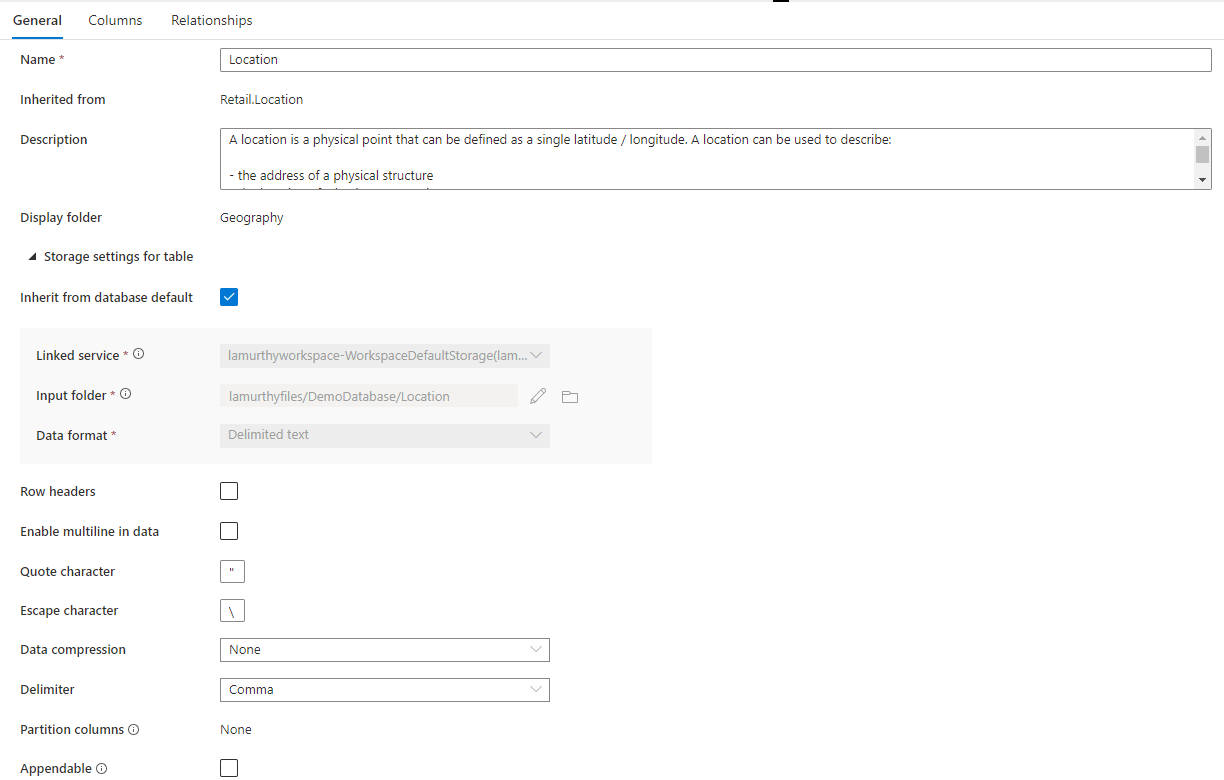
Daarnaast is er een samenvouwbare sectie met de naam Opslaginstellingen voor tabel die instellingen biedt voor de onderliggende opslaggegevens die door de tabel worden gebruikt.
Standaard overnemen van database een selectievakje waarmee wordt bepaald of de onderstaande opslaginstellingen worden overgenomen van de waarden die zijn ingesteld op het tabblad Eigenschappen van de database of afzonderlijk worden ingesteld. Als u de opslagwaarden wilt aanpassen, schakelt u dit selectievakje uit.
- Gekoppelde service is de standaard gekoppelde service die wordt gebruikt om uw gegevens op te slaan in Azure Data Lake Storage. Wijzig dit om een ander ADLS-account te kiezen.
- Voer de map in de map in ADLS in waar de gegevens die in deze tabel worden geladen, worden opgeslagen. U kunt door de maplocatie bladeren of deze handmatig bewerken met behulp van het potloodpictogram.
- Gegevensindeling De gegevensindeling van de gegevens in de invoermap Lake-databases in Azure Synapse ondersteuning bieden voor Parquet en tekst met scheidingstekens als opslagindelingen voor gegevens. Als de gegevensindeling niet overeenkomt met de gegevens in de map, mislukken query's naar de tabel.
Voor een gegevensindeling met tekst met scheidingstekens zijn er andere instellingen:
- Rijkoppen schakel dit selectievakje in als de gegevens rijkoppen bevatten.
- Schakel meerdere regels in gegevens in als de gegevens meerdere regels in een tekenreekskolom bevatten.
- Aanhalingsteken geeft het aangepaste aanhalingsteken op voor een tekstbestand met scheidingstekens.
- Escape-teken geeft het aangepaste escapeteken op voor een tekstbestand met scheidingstekens.
- Gegevenscompressie het compressietype dat voor de gegevens wordt gebruikt.
- Scheidingsteken voor het veldscheidingsteken dat in de gegevensbestanden wordt gebruikt. Ondersteunde waarden zijn: komma (,), tab (\t) en pipe (|).
- Partitiekolommen de lijst met partitiekolommen wordt hier weergegeven.
- Schakel dit selectievakje in als u een query uitvoert op Dataverse-gegevens uit SQL Serverless.
Voor Parquet-gegevens is er de volgende instelling:
- Gegevenscompressie het compressietype dat voor de gegevens wordt gebruikt.
Kolommen
Op het tabblad Kolommen worden de kolommen voor de tabel weergegeven en kunnen deze worden gewijzigd. Op dit tabblad staan twee lijsten met kolommen: Standaardkolommen en Partitiekolommen.
Standaardkolommen zijn elke kolom waarin gegevens worden opgeslagen, een primaire sleutel is en anders niet wordt gebruikt voor het partitioneren van de gegevens.
In partitiekolommen worden ook gegevens opgeslagen, maar deze worden gebruikt om de onderliggende gegevens in mappen te partitioneren op basis van de waarden in de kolom. Elke kolom heeft de volgende eigenschappen.
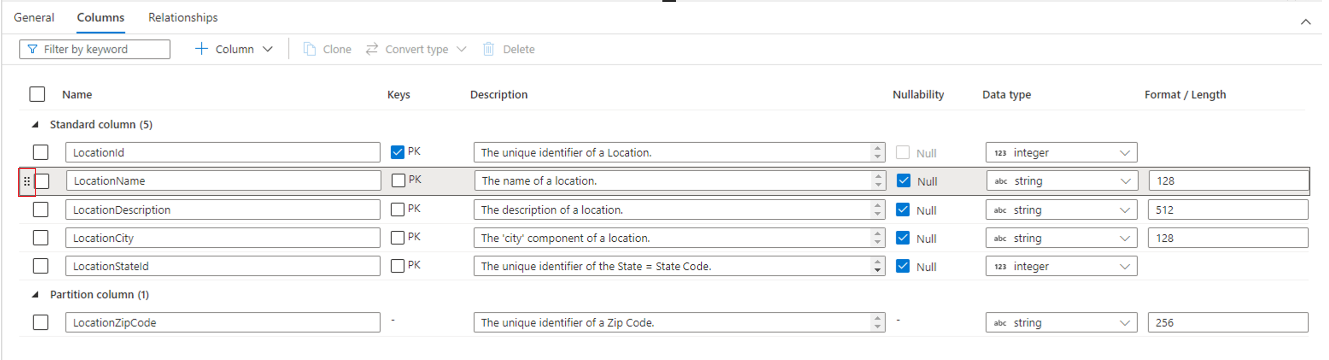
- Geef de naam van de kolom een naam. Moet uniek zijn binnen de tabel.
- Sleutels geeft aan of de kolom een primaire sleutel (PK) en/of een refererende sleutel (FK) voor de tabel is. Niet van toepassing op partitiekolommen.
- Beschrijving een beschrijving van de kolom. Als de kolom is gemaakt op basis van een databasesjabloon, wordt de beschrijving weergegeven van het concept dat door deze kolom wordt vertegenwoordigd. Dit veld kan worden bewerkt en kan worden gewijzigd zodat deze overeenkomt met de beschrijving die overeenkomt met uw bedrijfsvereisten.
- Nullability geeft aan of er null-waarden in deze kolom kunnen zijn. Niet van toepassing op partitiekolommen.
- Met gegevenstype wordt het gegevenstype voor de kolom ingesteld op basis van de beschikbare lijst met Spark-gegevenstypen.
- Met opmaak/lengte kunt u de opmaak of de maximale lengte van de kolom aanpassen, afhankelijk van het gegevenstype. Gegevenstypen datum en tijdstempel hebben vervolgkeuzelijsten voor notatie en andere typen, zoals tekenreeks, hebben een veld met een maximale lengte. Niet alle gegevenstypen hebben een waarde, omdat sommige typen een vaste lengte hebben. Boven aan het tabblad Kolommen bevindt zich een opdrachtbalk die kan worden gebruikt voor interactie met de kolommen.
- Filteren op trefwoord filtert de lijst met kolommen op items die overeenkomen met het opgegeven trefwoord.
-
Met + Kolom kunt u een nieuwe kolom toevoegen. Er zijn drie mogelijke opties.
- Nieuwe kolom maakt een nieuwe aangepaste standaardkolom.
- Met Behulp van sjabloon opent u het deelvenster Verkennen en kunt u kolommen uit een databasesjabloon identificeren die u in uw tabel wilt opnemen. Als uw database niet is gemaakt met behulp van een databasesjabloon, wordt deze optie niet weergegeven.
- Met de partitiekolom wordt een nieuwe aangepaste partitiekolom toegevoegd.
- Met klonen wordt de geselecteerde kolom gedupliceerd. Gekloonde kolommen zijn altijd van hetzelfde type als de geselecteerde kolom.
- Type converteren wordt gebruikt om de geselecteerde standaardkolom te wijzigen in een partitiekolom en andersom. Deze optie wordt grijs weergegeven als u meerdere kolommen van verschillende typen hebt geselecteerd of als de geselecteerde kolom niet in aanmerking komt voor conversie vanwege een PK - of Null-markering die is ingesteld op de kolom.
- Met Verwijderen worden de geselecteerde kolommen uit de tabel verwijderd. Deze actie kan niet ongedaan worden gemaakt.
U kunt de volgorde van de kolommen ook wijzigen door te slepen en neer te zetten met behulp van de dubbele verticale beletseltekens die links van de kolomnaam worden weergegeven wanneer u de muisaanwijzer over de kolom beweegt of op de kolom klikt, zoals wordt weergegeven in de bovenstaande afbeelding.
Partitiekolommen
Partitiekolommen worden gebruikt om de fysieke gegevens in uw database te partitioneren op basis van waarden in die kolommen. Partitiekolommen bieden een eenvoudige manier om gegevens op schijf te verdelen over beter presterende segmenten. Partitiekolommen in Azure Synapse bevinden zich altijd aan het einde van het tabelschema. Bovendien worden ze van boven naar beneden gebruikt bij het maken van de partitiemappen. Als uw partitiekolommen bijvoorbeeld Year en Month zijn, krijgt u uiteindelijk een structuur in ADLS als volgt:
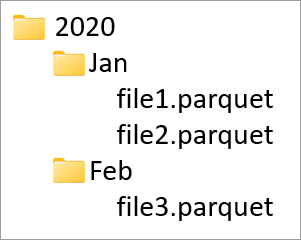
Waarbij bestand1 en bestand2 alle rijen bevatten met de waarden van Year en Month respectievelijk 2020 en Jan. Naarmate er meer partitiekolommen aan een tabel worden toegevoegd, worden er meer bestanden aan deze hiërarchie toegevoegd, waardoor de totale bestandsgrootte van de partities kleiner wordt.
Azure Synapse dwingt deze hiërarchie niet af of maakt deze niet door partitiekolommen toe te voegen aan een tabel. Gegevens moeten in de tabel worden geladen met synapse-pijplijnen of een Spark-notebook om de partitiestructuur te kunnen maken.
Relaties
Op het tabblad Relaties kunt u relaties tussen tabellen in de database opgeven. Relaties in de databaseontwerper zijn informatief en dwingen geen beperkingen af voor de onderliggende gegevens. Ze worden gelezen door andere Microsoft-toepassingen om transformaties te versnellen of zakelijke gebruikers inzicht te geven in hoe tabellen zijn verbonden. Het deelvenster Relaties bevat de volgende informatie.
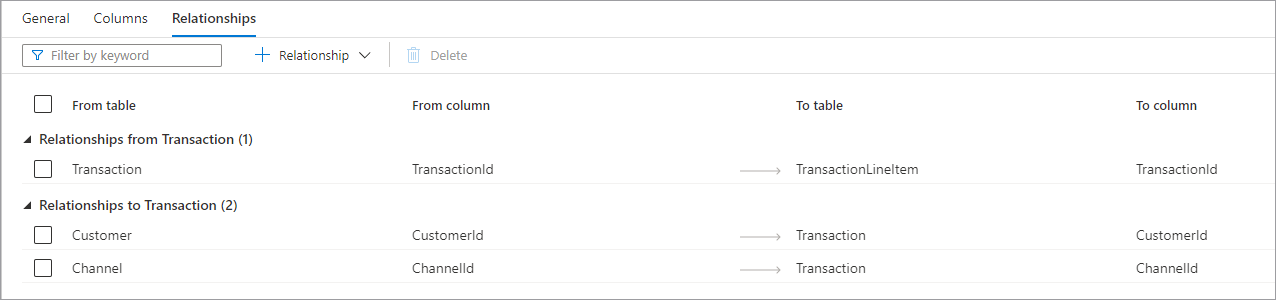
- Relaties van (Tabel) is wanneer een of meer tabellen refererende sleutels hebben die aan deze tabel zijn gekoppeld. Dit wordt ook wel een bovenliggende relatie genoemd.
- Relaties met (Tabel) is wanneer een tabel een refererende sleutel heeft en is verbonden met een andere tabel. Dit wordt ook wel een onderliggende relatie genoemd.
- Beide relatietypen hebben de volgende eigenschappen.
- Uit de tabel de bovenliggende tabel in de relatie of de 'een'-kant.
- In kolom de kolom in de bovenliggende tabel waarop de relatie is gebaseerd.
- Als u de onderliggende tabel in de relatie of de 'veel'-kant wilt weergeven.
- De kolom in de onderliggende tabel waarop de relatie is gebaseerd, wilt kolomen. Boven aan het tabblad Relaties bevindt zich de opdrachtbalk die kan worden gebruikt om te communiceren met de relaties
- Filteren op trefwoord filtert de lijst met kolommen op items die overeenkomen met het opgegeven trefwoord.
-
Met + Relatie kunt u een nieuwe relatie toevoegen. Er zijn twee opties.
- Met tabel maakt u een nieuwe relatie van de tabel waaraan u werkt en een andere tabel.
- Met tabel maakt u een nieuwe relatie van een andere tabel met de tabel waaraan u werkt.
- Met sjabloon opent u het deelvenster Verkennen en kunt u kiezen uit relaties in de databasesjabloon die u wilt opnemen in uw database. Als uw database niet is gemaakt met behulp van een databasesjabloon, wordt deze optie niet weergegeven.
Volgende stappen
Ga verder met het verkennen van de mogelijkheden van de databaseontwerper met behulp van de onderstaande koppelingen.