Zelfstudie: Een machine learning-model trainen zonder code
U kunt uw gegevens in Spark-tabellen uitbreiden met nieuwe machine learning-modellen die u traint met behulp van geautomatiseerde machine learning. In Azure Synapse Analytics kunt u een Spark-tabel selecteren in de werkruimte en deze gebruiken als trainingsgegevensset om zonder code machine learning-modellen te bouwen.
In deze zelfstudie leert u hoe u machine learning-modellen traint met behulp van een codevrije ervaring in Synapse Studio. Synapse Studio is een functie van Azure Synapse Analytics.
U gebruikt geautomatiseerde machine learning in Azure Machine Learning, in plaats van de ervaring handmatig te coderen. Het type model dat u traint, is afhankelijk van het probleem dat u probeert op te lossen. Voor deze zelfstudie gebruikt u een regressiemodel om taxitarieven te voorspellen uit de gegevensset taxi's van New York City.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Waarschuwing
- Vanaf 29 september 2023 wordt de officiële ondersteuning voor Spark 2.4 Runtimes stopgezet in Azure Synapse. Na 29 september 2023 behandelen we geen ondersteuningstickets met betrekking tot Spark 2.4. Er is geen release-pijplijn aanwezig voor bug- of beveiligingsoplossingen voor Spark 2.4. Het gebruik van Spark 2.4 na de datum waarop de ondersteuning wordt afgekapt, wordt op eigen risico uitgevoerd. We raden het gebruik ervan sterk af vanwege mogelijke beveiligings- en functionaliteitsproblemen.
- Als onderdeel van het afschaffingsproces voor Apache Spark 2.4 willen we u laten weten dat AutoML in Azure Synapse Analytics ook wordt afgeschaft. Dit omvat zowel de interface met weinig code als de API's die worden gebruikt voor het maken van AutoML-proefversies via code.
- Houd er rekening mee dat de AutoML-functionaliteit uitsluitend beschikbaar is via de Spark 2.4-runtime.
- Voor klanten die gebruik willen blijven maken van AutoML-mogelijkheden, raden we u aan om uw gegevens op te slaan in uw ADLSg2-account (Azure Data Lake Storage Gen2). Van daaruit hebt u naadloos toegang tot de AutoML-ervaring via Azure Machine Learning (AzureML). Meer informatie over deze tijdelijke oplossing vindt u hier.
Vereisten
- Een Azure Synapse Analytics-werkruimte. Zorg ervoor dat er een Azure Data Lake Storage Gen2-opslagaccount is geconfigureerd als de standaardopslag. Voor het Data Lake Storage Gen2-bestandssysteem waarmee u werkt, moet u ervoor zorgen dat u de inzender voor Storage Blob-gegevens bent.
- Een Apache Spark-pool (versie 2.4) in uw Azure Synapse Analytics-werkruimte. Zie quickstart: Een serverloze Apache Spark-pool maken met behulp van Synapse Studio voor meer informatie.
- Een gekoppelde Azure Machine Learning-service in uw Azure Synapse Analytics-werkruimte. Zie quickstart: Een nieuwe gekoppelde Azure Machine Learning-service maken in Azure Synapse Analytics voor meer informatie.
Meld u aan bij Azure Portal
Meld u aan bij het Azure-portaal.
Een Spark-tabel maken voor de trainingsgegevensset
Voor deze zelfstudie hebt u een Spark-tabel nodig. In het volgende notebook wordt er een gemaakt:
Download het notebook Create-Spark-Table-NYCTaxi- Data.ipynb.
Importeer het notebook in Synapse Studio.
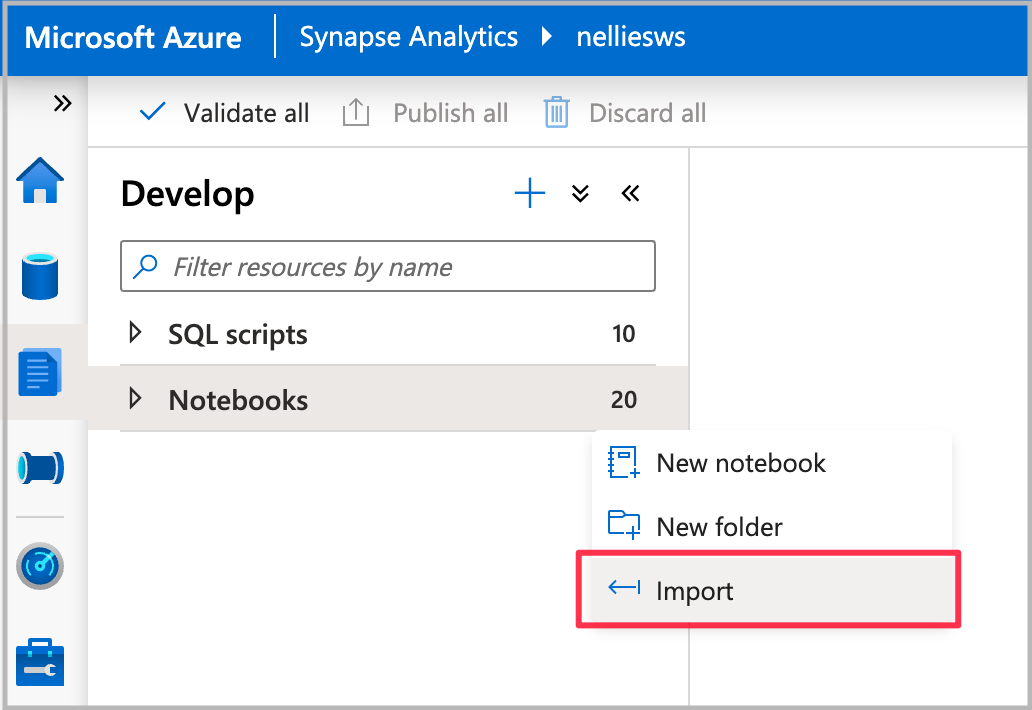
Selecteer de Spark-pool die u wilt gebruiken en selecteer vervolgens Alles uitvoeren. Met deze stap worden taxigegevens uit New York opgehaald uit de geopende gegevensset en worden de gegevens opgeslagen in uw standaard Spark-database.

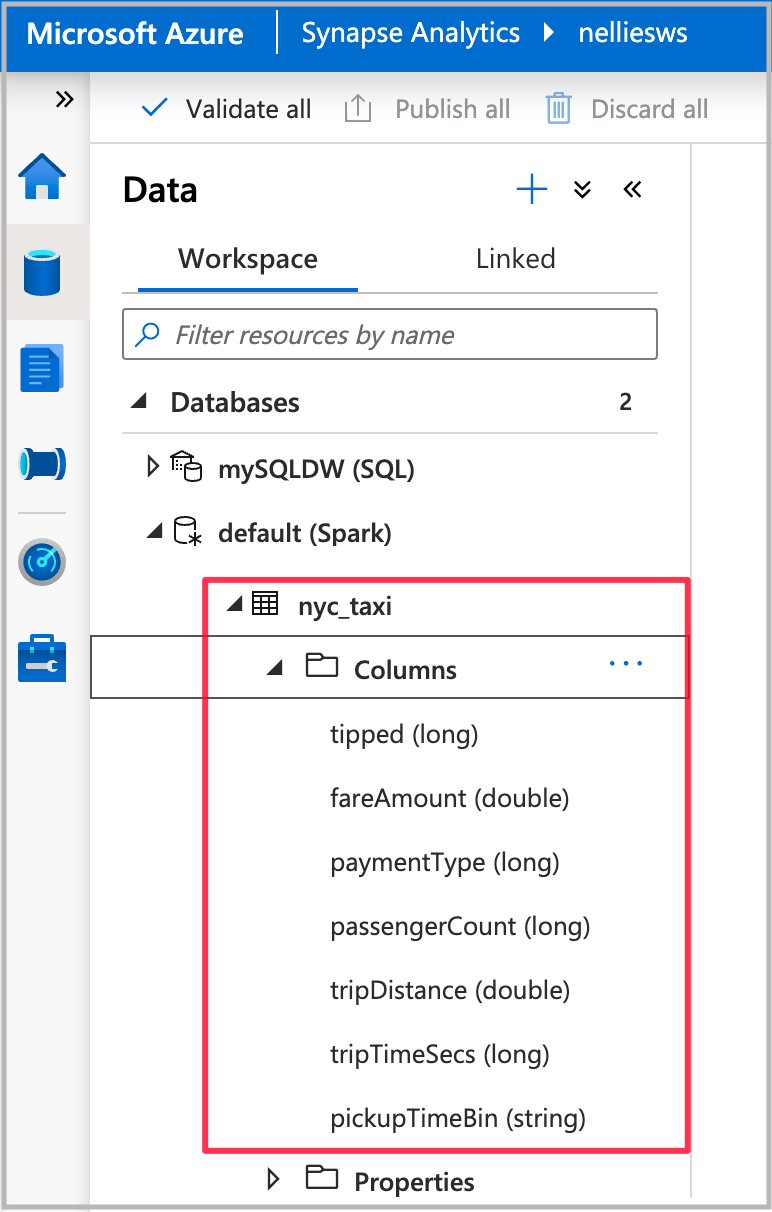
Nadat de uitvoering van het notebook is voltooid, ziet u een nieuwe Spark-tabel in de standaarddatabase in Spark. Zoek vanuit Gegevens de tabel met de naam nyc_taxi.
De wizard geautomatiseerde machine learning openen
Als u de wizard wilt openen, klikt u met de rechtermuisknop op de Spark-tabel die u in de vorige stap hebt gemaakt. Selecteer vervolgens Machine Learning>Train a new model.
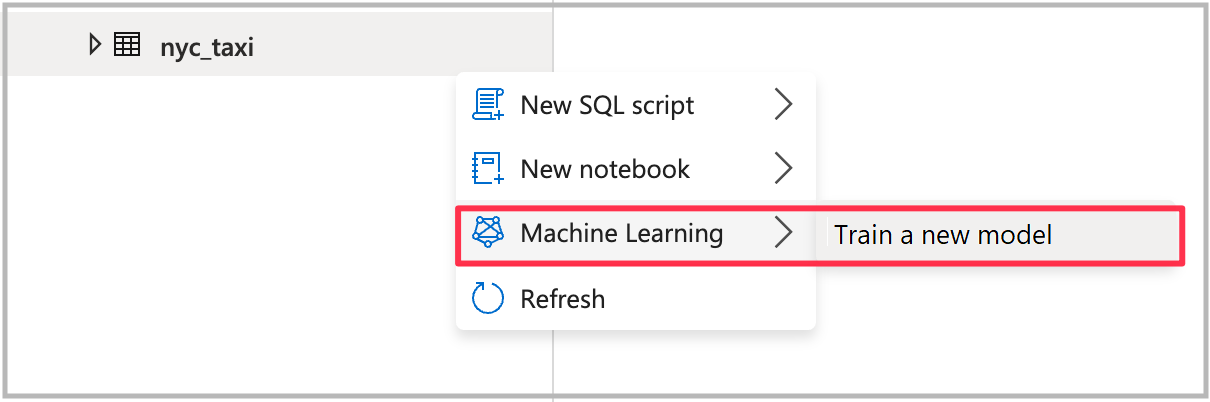
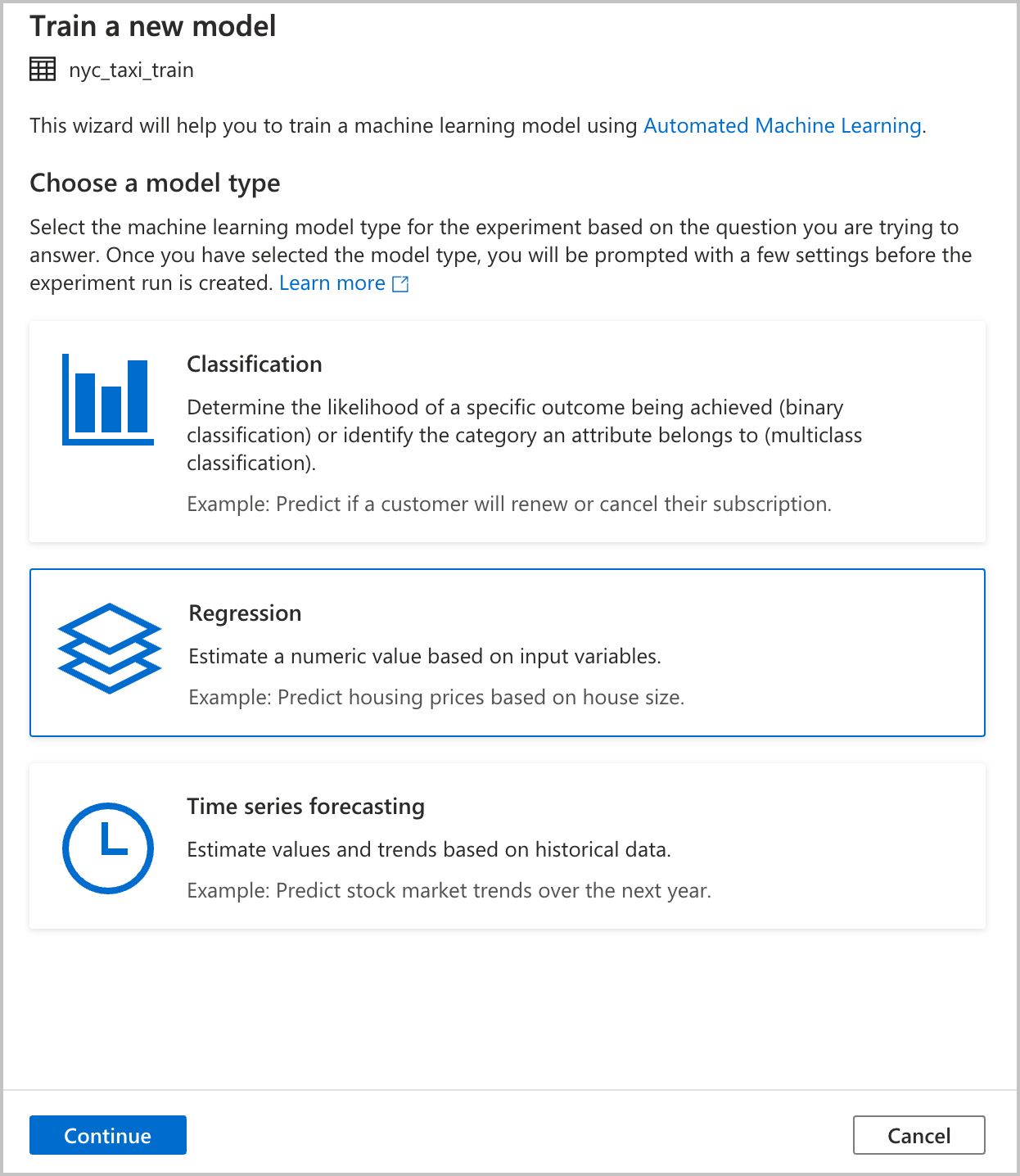
Een modeltype kiezen
Selecteer het type machine learning-model voor het experiment op basis van de vraag die u wilt beantwoorden. Omdat de waarde die u probeert te voorspellen numeriek is (taxitarieven), selecteert u Hier Regressie . Selecteer vervolgens Doorgaan.
Het experiment configureren
Geef configuratiedetails op voor het maken van een geautomatiseerde machine learning-experimentuitvoering in Azure Machine Learning. Hiermee worden meerdere modellen getraind. Het beste model van een geslaagde uitvoering wordt geregistreerd in het Azure Machine Learning-modelregister.
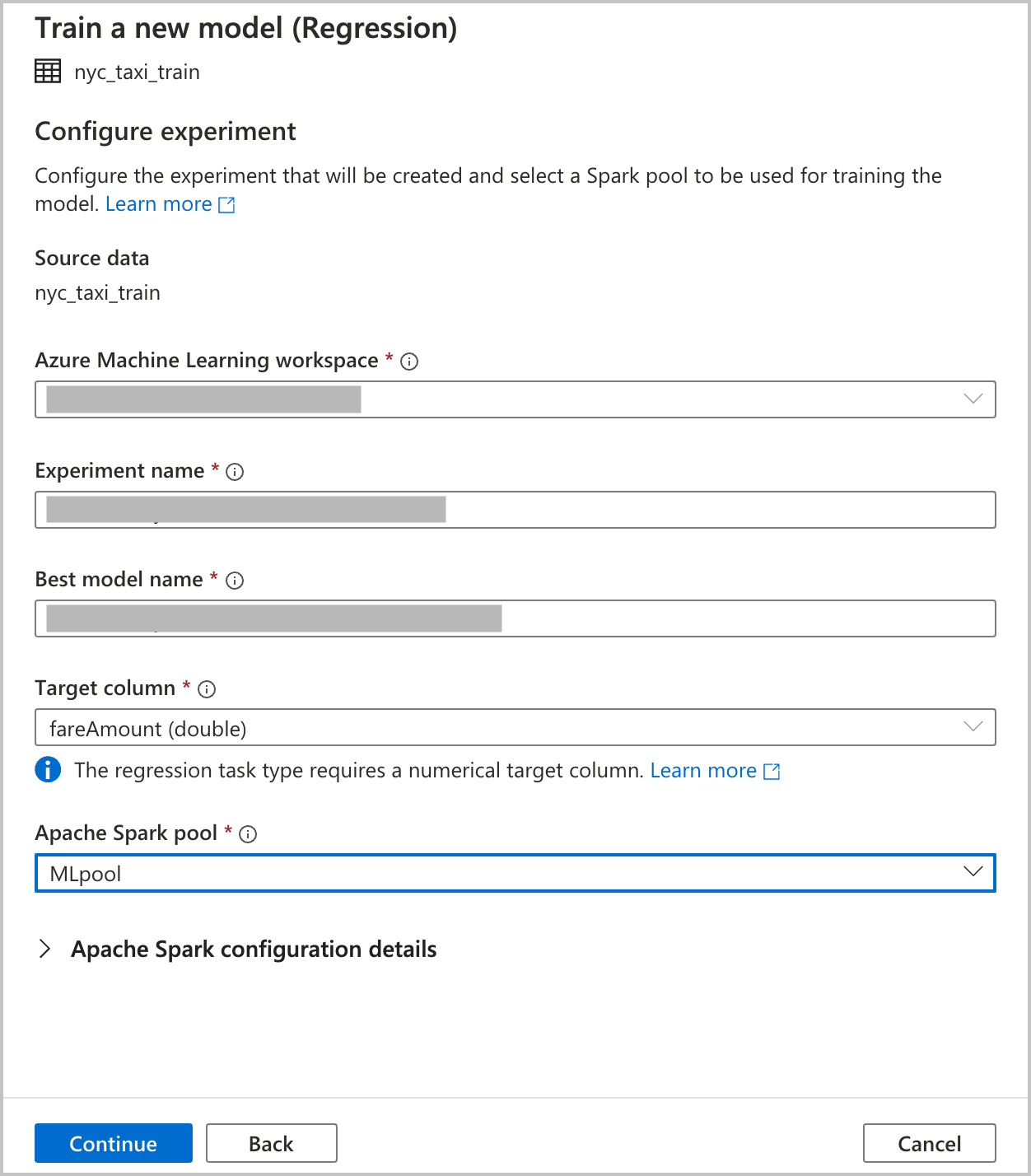
Azure Machine Learning-werkruimte: een Azure Machine Learning-werkruimte is vereist voor het maken van een geautomatiseerde uitvoering van een machine learning-experiment. U moet ook uw Azure Synapse Analytics-werkruimte koppelen aan de Azure Machine Learning-werkruimte met behulp van een gekoppelde service. Nadat u aan alle vereisten hebt voldaan, kunt u de Azure Machine Learning-werkruimte opgeven die u wilt gebruiken voor deze geautomatiseerde uitvoering.
Experimentnaam: Geef de naam van het experiment op. Wanneer u een geautomatiseerde ML-uitvoering verzendt, geeft u een naam op voor het experiment. Informatie over de uitvoering wordt opgeslagen bij dit experiment in de Azure Machine Learning-werkruimte. Deze ervaring maakt standaard een nieuw experiment en genereert een voorgestelde naam, maar u kunt ook de naam van een bestaand experiment opgeven.
Beste modelnaam: geef de naam op van het beste model uit de geautomatiseerde uitvoering. Het beste model krijgt deze naam. Deze wordt na deze uitvoering automatisch opgeslagen in het Azure Machine Learning-modelregister. In een geautomatiseerde ML-uitvoering worden veel ML-modellen gemaakt. Deze modellen kunnen worden vergeleken en het beste model kan worden geselecteerd op basis van de primaire metrische gegevens die u in een latere stap selecteert.
Doelkolom: Dit is wat het model wordt getraind om te voorspellen. Kies de kolom in de gegevensset die de gegevens bevat die u wilt voorspellen. Voor deze zelfstudie selecteert u de numerieke kolom
fareAmountals doelkolom.Spark-pool: geef de Spark-pool op die u wilt gebruiken voor de uitvoering van het geautomatiseerde experiment. De berekeningen worden uitgevoerd in de pool die u opgeeft.
Spark-configuratiedetails: naast de Spark-pool hebt u de mogelijkheid om sessieconfiguratiegegevens op te geven.
Selecteer Doorgaan.
Het model configureren
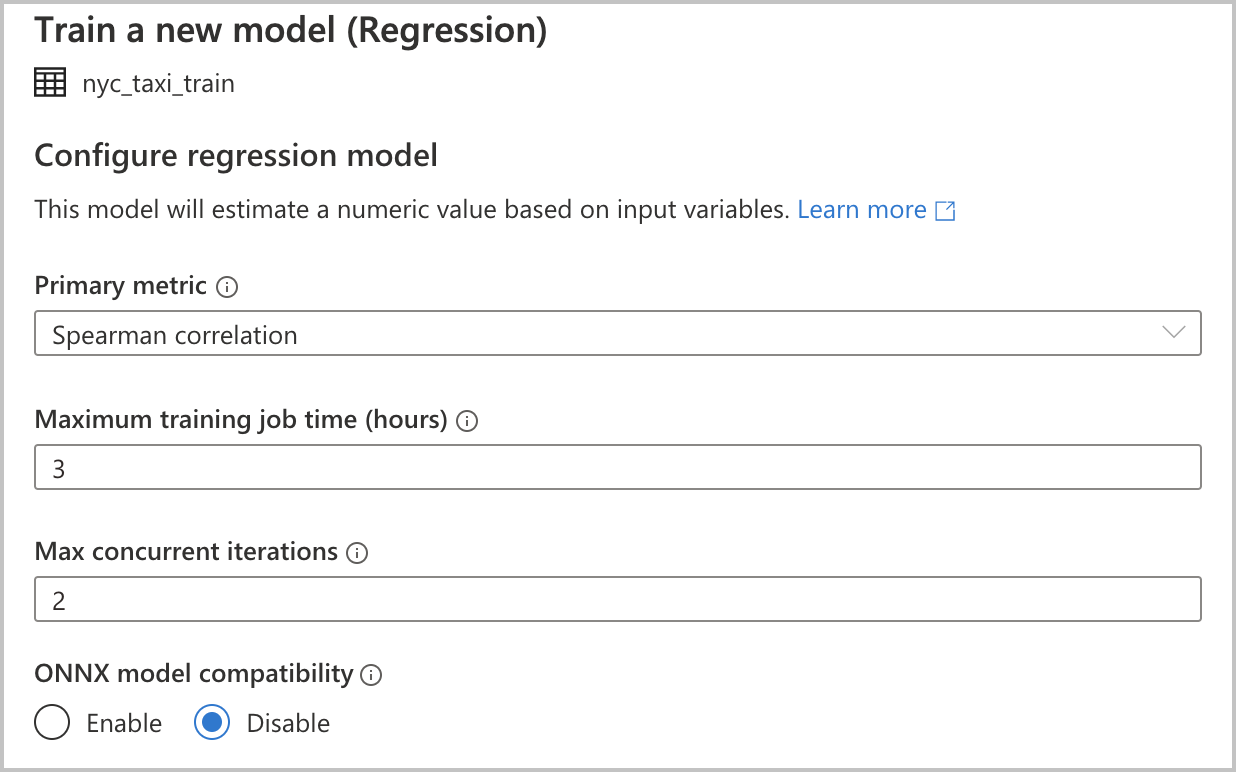
Omdat u Regressie hebt geselecteerd als uw modeltype in de vorige sectie, zijn de volgende configuraties beschikbaar (deze zijn ook beschikbaar voor het type classificatiemodel):
Primaire metrische waarde: voer de metrische waarde in die meet hoe goed het model presteert. U gebruikt deze metrische waarde om verschillende modellen te vergelijken die zijn gemaakt in de geautomatiseerde uitvoering en om te bepalen welk model het beste heeft gepresteerd.
Trainingstaaktijd (uren): geef de maximale tijdsduur, in uren, op voor een experiment om modellen uit te voeren en te trainen. U kunt ook waarden opgeven die kleiner zijn dan 1 (bijvoorbeeld 0,5).
Maximum aantal gelijktijdige iteraties: kies het maximum aantal iteraties dat parallel wordt uitgevoerd.
Compatibiliteit met ONNX-modellen: als u deze optie inschakelt, worden de modellen die zijn getraind door geautomatiseerde machine learning geconverteerd naar de ONNX-indeling. Dit is met name relevant als u het model wilt gebruiken in SQL-pools van Azure Synapse Analytics.
Deze instellingen hebben allemaal een standaardwaarde die u kunt aanpassen.
Een uitvoering starten
Zodra alle vereiste configuraties zijn uitgevoerd, kunt u de geautomatiseerde uitvoering starten. U kunt ervoor kiezen om rechtstreeks een uitvoering te maken door De uitvoering maken te selecteren. Hiermee wordt de uitvoering zonder code gestart. Als u de voorkeur geeft aan code, kunt u ook Openen in notebook selecteren . Hiermee opent u een notitieblok met de code waarmee de uitvoering wordt gemaakt, zodat u de code kunt bekijken en de uitvoering zelf kunt starten.

Notitie
Als u tijdreeksprognoses hebt geselecteerd als het modeltype in de vorige sectie, moet u aanvullende configuraties maken. Het maken van een prognose biedt ook geen ondersteuning voor compatibiliteit met ONNX-modellen.
Rechtstreeks een uitvoering maken
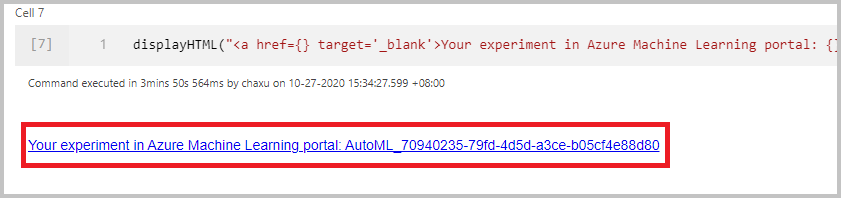
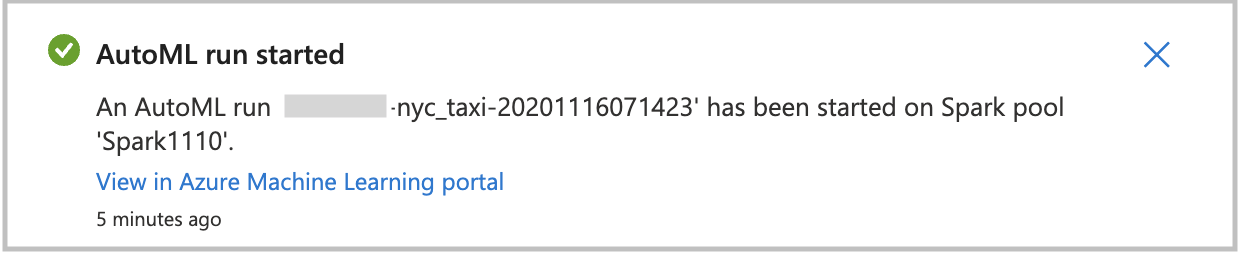
Als u uw geautomatiseerde machine learning rechtstreeks wilt starten, selecteert u Uitvoeren maken. U ziet een melding waarin wordt aangegeven dat de uitvoering wordt gestart. Vervolgens ziet u een andere melding die aangeeft dat het is gelukt. U kunt ook de status in Azure Machine Learning controleren door de koppeling in de melding te selecteren.
Een uitvoering maken met een notebook
Selecteer Openen in notebook om een notebook te genereren. Dit biedt u de mogelijkheid om instellingen toe te voegen of de code voor uw geautomatiseerde machine learning-uitvoering op een andere manier te wijzigen. Wanneer u klaar bent om de code uit te voeren, selecteert u Alles uitvoeren.

De uitvoering bewaken
Nadat u de uitvoering hebt verzonden, ziet u een koppeling naar de uitvoering van het experiment in de Azure Machine Learning-werkruimte in de uitvoer van het notebook. Selecteer de koppeling om de geautomatiseerde uitvoering te bewaken in Azure Machine Learning.