Ontwerp en prestaties voor Netezza-migraties
Dit artikel is deel één van een zevendelige reeks met richtlijnen voor het migreren van Netezza naar Azure Synapse Analytics. De focus van dit artikel ligt op best practices voor ontwerp en prestaties.
Overzicht
Vanwege het einde van de ondersteuning van IBM willen veel bestaande gebruikers van Netezza-datawarehousesystemen profiteren van de innovaties van moderne cloudomgevingen. Met IaaS- en PaaS-cloudomgevingen (Platform as a Service) kunt u taken zoals infrastructuuronderhoud en platformontwikkeling delegeren aan de cloudprovider.
Tip
Meer dan alleen een database: de Azure-omgeving bevat een uitgebreide set mogelijkheden en hulpprogramma's.
Hoewel Netezza en Azure Synapse Analytics beide SQL-databases zijn die MPP-technieken (Massively Parallel Processing) gebruiken om hoge queryprestaties te behalen op uitzonderlijk grote gegevensvolumes, zijn er enkele fundamentele verschillen in benadering:
Verouderde Netezza-systemen worden vaak on-premises geïnstalleerd en maken gebruik van eigen hardware, terwijl Azure Synapse cloudgebaseerd is en gebruikmaakt van Azure-opslag- en rekenresources.
Het upgraden van een Netezza-configuratie is een belangrijke taak met extra fysieke hardware en mogelijk langdurige herconfiguratie van databases, of dumpen en opnieuw laden. Omdat opslag- en rekenresources gescheiden zijn in de Azure-omgeving en elastisch kunnen worden geschaald, kunnen deze resources onafhankelijk van elkaar omhoog of omlaag worden geschaald.
U kunt Azure Synapse zo nodig onderbreken of het formaat ervan wijzigen om het resourcegebruik en de kosten te verminderen.
Microsoft Azure is een wereldwijd beschikbare, zeer veilige, schaalbare cloudomgeving met Azure Synapse en een ecosysteem van ondersteunende hulpprogramma's en mogelijkheden. Het volgende diagram bevat een overzicht van het Azure Synapse ecosysteem.
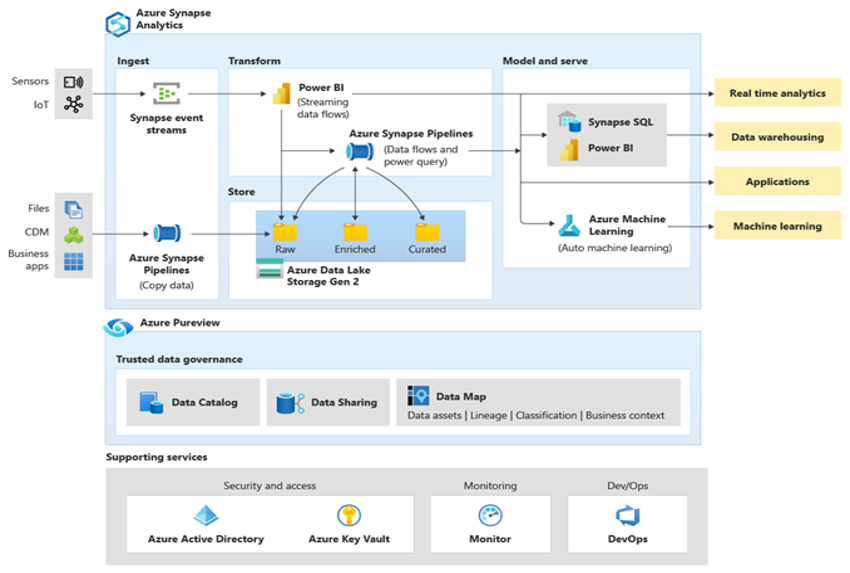
Azure Synapse biedt de beste prestaties van relationele databases door gebruik te maken van technieken zoals MPP en meerdere niveaus van geautomatiseerde caching voor veelgebruikte gegevens. U kunt de resultaten van deze technieken zien in onafhankelijke benchmarks, zoals die onlangs is uitgevoerd door GigaOm, waarin Azure Synapse worden vergeleken met andere populaire clouddatawarehouse-aanbiedingen. Klanten die migreren naar de Azure Synapse-omgeving, zien veel voordelen, waaronder:
Verbeterde prestaties en prijs/prestatie.
Meer flexibiliteit en kortere time to value.
Snellere serverimplementatie en toepassingsontwikkeling.
Elastische schaalbaarheid: betaal alleen voor het werkelijke gebruik.
Verbeterde beveiliging/naleving.
Lagere kosten voor opslag en herstel na noodgevallen.
Lagere totale TCO, betere kostenbeheersing en gestroomlijnde operationele uitgaven (OPEX).
Als u deze voordelen wilt maximaliseren, migreert u nieuwe of bestaande gegevens en toepassingen naar het Azure Synapse-platform. In veel organisaties omvat migratie het verplaatsen van een bestaand datawarehouse van een verouderd on-premises platform, zoals Netezza, naar Azure Synapse. Op hoog niveau omvat het migratieproces de volgende stappen:
Voorbereiding 🡆
Definieer het bereik: wat moet worden gemigreerd.
Inventaris maken van gegevens en processen voor migratie.
Gegevensmodelwijzigingen definiëren (indien aanwezig).
Mechanisme voor het extraheren van brongegevens definiëren.
Identificeer de juiste hulpprogramma's en functies van Azure en derden die moeten worden gebruikt.
Train personeel vroeg op het nieuwe platform.
Stel het Azure-doelplatform in.
Migratie 🡆
Begin klein en eenvoudig.
Automatiseer waar mogelijk.
Maak gebruik van ingebouwde Azure-hulpprogramma's en -functies om de migratie-inspanning te verminderen.
Metagegevens migreren voor tabellen en weergaven.
Historische gegevens migreren die moeten worden onderhouden.
Opgeslagen procedures en bedrijfsprocessen migreren of herstructureren.
Processen voor incrementele etl-/ELT-belasting migreren of herstructureren.
Na de migratie
Bewaak en documenteer alle fasen van het proces.
Gebruik de opgedane ervaring om een sjabloon te bouwen voor toekomstige migraties.
Herwerk het gegevensmodel indien nodig (met behulp van nieuwe platformprestaties en schaalbaarheid).
Toepassingen en hulpprogramma's voor query's testen.
Benchmark en optimaliseer queryprestaties.
Dit artikel bevat algemene informatie en richtlijnen voor het optimaliseren van prestaties bij het migreren van een datawarehouse van een bestaande Netezza-omgeving naar Azure Synapse. Het doel van prestatieoptimalisatie is om dezelfde of betere prestaties van het datawarehouse te bereiken in Azure Synapse na de migratie van het schema.
Overwegingen bij het ontwerpen
Migratiebereik
Wanneer u de migratie vanuit een Netezza-omgeving voorbereidt, moet u rekening houden met de volgende migratieopties.
Kies de workload voor de eerste migratie
Normaal gesproken zijn verouderde Netezza-omgevingen in de loop van de tijd ontwikkeld om meerdere vakgebieden en gemengde workloads te omvatten. Wanneer u besluit waar u aan een migratieproject wilt beginnen, kiest u een gebied waarin u het volgende kunt doen:
Bewijs de levensvatbaarheid van migreren naar Azure Synapse door snel de voordelen van de nieuwe omgeving te leveren.
Laat uw interne technische medewerkers relevante ervaring opdoen met de processen en hulpprogramma's die ze gebruiken wanneer ze andere gebieden migreren.
Maak een sjabloon voor verdere migraties die specifiek is voor de Netezza-bronomgeving en de huidige hulpprogramma's en processen die al aanwezig zijn.
Een goede kandidaat voor een initiële migratie vanuit een Netezza-omgeving ondersteunt de voorgaande items, en:
Implementeert een BI/Analytics-workload in plaats van een OLTP-workload (Online Transaction Processing).
Heeft een gegevensmodel, zoals een ster of sneeuwvlokschema, dat met minimale wijziging kan worden gemigreerd.
Tip
Maak een inventaris van objecten die moeten worden gemigreerd en documenteer het migratieproces.
Het volume van gemigreerde gegevens in een eerste migratie moet groot genoeg zijn om de mogelijkheden en voordelen van de Azure Synapse omgeving te demonstreren, maar niet te groot om snel de waarde aan te tonen. Een grootte in het bereik van 1-10 terabyte is typisch.
Minimaliseer voor uw eerste migratieproject het risico, de inspanning en de migratietijd, zodat u snel de voordelen van de Azure-cloudomgeving kunt zien. Zowel de lift-and-shift-benadering als de gefaseerde migratie beperken het bereik van de initiële migratie tot alleen de datamarts en hebben geen betrekking op bredere migratieaspecten, zoals ETL-migratie en historische gegevensmigratie. U kunt deze aspecten echter in latere fasen van het project aanpakken zodra de gemigreerde datamartlaag is gevuld met gegevens en de vereiste buildprocessen.
Lift-and-shift-migratie versus gefaseerde benadering
In het algemeen zijn er twee typen migraties, ongeacht het doel en het bereik van de geplande migratie: lift-and-shift as-is en een gefaseerde benadering die wijzigingen omvat.
Lift-and-shift
Bij een lift-and-shift-migratie wordt een bestaand gegevensmodel, zoals een stervormig schema, ongewijzigd gemigreerd naar het nieuwe Azure Synapse-platform. Deze benadering minimaliseert risico's en migratietijd door het werk te verminderen dat nodig is om de voordelen van de overstap naar de Azure-cloudomgeving te realiseren. Lift-and-shift-migratie is geschikt voor deze scenario's:
- U een bestaande Netezza-omgeving hebt met één datamart om te migreren, of
- U een bestaande Netezza-omgeving hebt met gegevens die zich al in een goed ontworpen ster- of sneeuwvlokschema bevinden, of
- U staat onder druk van tijd en kosten om over te stappen naar een moderne cloudomgeving.
Tip
Lift and Shift is een goed uitgangspunt, zelfs als in volgende fasen wijzigingen in het gegevensmodel worden geïmplementeerd.
Gefaseerde aanpak met wijzigingen
Als een verouderd datawarehouse zich gedurende een lange periode heeft ontwikkeld, moet u het mogelijk opnieuw ontwikkelen om de vereiste prestatieniveaus te behouden. Mogelijk moet u ook opnieuw ontwerpen om nieuwe gegevens te ondersteunen, zoals IoT-stromen (Internet of Things). Als onderdeel van het her-engineeringproces migreert u naar Azure Synapse om de voordelen van een schaalbare cloudomgeving te krijgen. Migratie kan ook een wijziging in het onderliggende gegevensmodel omvatten, zoals een verplaatsing van een Inmon-model naar een gegevenskluis.
Microsoft raadt aan uw bestaande gegevensmodel as-is te verplaatsen naar Azure en de prestaties en flexibiliteit van de Azure-omgeving te gebruiken om de wijzigingen in de her-engineering toe te passen. Op die manier kunt u de mogelijkheden van Azure gebruiken om de wijzigingen aan te brengen zonder dat dit van invloed is op het bestaande bronsysteem.
Gebruik Azure Data Factory om een migratie op basis van metagegevens te implementeren
U kunt het migratieproces automatiseren en organiseren met behulp van de mogelijkheden van de Azure-omgeving. Deze benadering minimaliseert de prestatietreffer in de bestaande Netezza-omgeving, die mogelijk al dicht bij de capaciteit wordt uitgevoerd.
Azure Data Factory is een cloudservice voor gegevensintegratie die ondersteuning biedt voor het maken van gegevensgestuurde werkstromen in de cloud die gegevensverplaatsing en gegevenstransformatie organiseren en automatiseren. U kunt Data Factory gebruiken om gegevensgestuurde werkstromen (pijplijnen) te maken en te plannen die gegevens opnemen uit verschillende gegevensarchieven. Data Factory kan gegevens verwerken en transformeren met behulp van rekenservices zoals Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics en Azure Machine Learning.
Wanneer u van plan bent om Data Factory-faciliteiten te gebruiken om het migratieproces te beheren, maakt u metagegevens met een lijst met alle gegevenstabellen die moeten worden gemigreerd en hun locatie.
Ontwerpverschillen tussen Netezza en Azure Synapse
Zoals eerder vermeld, zijn er enkele fundamentele verschillen in de aanpak tussen Netezza en Azure Synapse Analytics-databases. Deze verschillen worden hierna besproken.
Meerdere databases versus één database en schema's
De Netezza-omgeving bevat vaak meerdere afzonderlijke databases. Er kunnen bijvoorbeeld afzonderlijke databases zijn voor: gegevensopname- en faseringstabellen, kernwarehousetabellen en datamarts (ook wel de semantische laag genoemd). ETL- of ELT-pijplijnprocessen kunnen cross-database joins implementeren en gegevens verplaatsen tussen de afzonderlijke databases.
De omgeving Azure Synapse daarentegen bevat één database en maakt gebruik van schema's om tabellen te scheiden in logisch gescheiden groepen. U wordt aangeraden een reeks schema's binnen de doeldatabase Azure Synapse te gebruiken om de afzonderlijke databases na te bootsen die zijn gemigreerd vanuit de Netezza-omgeving. Als de Netezza-omgeving al schema's gebruikt, moet u mogelijk een nieuwe naamconventie gebruiken wanneer u de bestaande Netezza-tabellen en -weergaven naar de nieuwe omgeving verplaatst. U kunt bijvoorbeeld de bestaande netezza-schema- en tabelnamen samenvoegen in de nieuwe Azure Synapse tabelnaam en schemanamen gebruiken in de nieuwe omgeving om de oorspronkelijke afzonderlijke databasenamen te behouden. Als de naamgeving van schemaconsolidatie puntjes bevat, kan Azure Synapse Spark problemen ondervinden. Hoewel u SQL-weergaven boven op de onderliggende tabellen kunt gebruiken om de logische structuren te onderhouden, zijn er mogelijke nadelen aan deze aanpak:
Weergaven in Azure Synapse zijn alleen-lezen, dus alle updates van de gegevens moeten plaatsvinden in de onderliggende basistabellen.
Er bestaan mogelijk al een of meer lagen met weergaven en het toevoegen van een extra laag met weergaven kan de prestaties en ondersteuning beïnvloeden, omdat geneste weergaven moeilijk kunnen worden opgelost.
Tip
Combineer meerdere databases in één database binnen Azure Synapse en gebruik schemanamen om de tabellen logisch van elkaar te scheiden.
Tabeloverwegingen
Wanneer u tabellen migreert tussen verschillende omgevingen, worden doorgaans alleen de onbewerkte gegevens en de metagegevens waarin deze worden beschreven fysiek gemigreerd. Andere database-elementen van het bronsysteem, zoals indexen, worden meestal niet gemigreerd omdat ze mogelijk niet nodig zijn of anders zijn geïmplementeerd in de nieuwe omgeving.
Prestatieoptimalisaties in de bronomgeving, zoals indexen, geven aan waar u prestatieoptimalisatie in de nieuwe omgeving kunt toevoegen. Als query's in de Netezza-bronomgeving bijvoorbeeld vaak zonetoewijzingen gebruiken, suggereert dit dat er een niet-geclusterde index moet worden gemaakt binnen Azure Synapse. Andere systeemeigen optimalisatietechnieken voor prestaties, zoals tabelreplicatie, zijn mogelijk meer van toepassing dan het maken van een rechte index.
Tip
Bestaande indexen geven kandidaten aan voor indexering in het gemigreerde magazijn.
Niet-ondersteunde Netezza-databaseobjecttypen
Netezza-specifieke functies kunnen vaak worden vervangen door Azure Synapse functies. Sommige Netezza-databaseobjecten worden echter niet rechtstreeks ondersteund in Azure Synapse. In de volgende lijst met niet-ondersteunde Netezza-databaseobjecten wordt beschreven hoe u een gelijkwaardige functionaliteit kunt bereiken in Azure Synapse.
Zonekaarten: in Netezza worden zonekaarten automatisch gemaakt en onderhouden voor de volgende kolomtypen en worden ze tijdens het uitvoeren van query's gebruikt om de hoeveelheid gegevens te beperken die moet worden gescand:
INTEGERkolommen met een lengte van 8 bytes of minder.- Tijdelijke kolommen, zoals
DATE,TIMEenTIMESTAMP. CHARkolommen als ze deel uitmaken van een gerealiseerde weergave en worden vermeld in deORDER BY-component.
U kunt nagaan welke kolommen zonetoewijzingen hebben met behulp van het
nz_zonemaphulpprogramma, dat deel uitmaakt van de NZ Toolkit. Azure Synapse bevat geen zonetoewijzingen, maar u kunt vergelijkbare resultaten bereiken door andere door de gebruiker gedefinieerde indextypen en/of partitionering te gebruiken.Geclusterde basistabellen (CGT): in Netezza worden CGT's vaak gebruikt voor feitentabellen, die miljarden records kunnen bevatten. Het scannen van zo'n enorme tabel vereist veel verwerkingstijd, omdat een volledige tabelscan nodig kan zijn om de relevante records op te halen. Door records te ordenen op beperkende CGT's kan Netezza records groeperen in dezelfde of nabijgelegen gebieden. Met dit proces worden ook zonetoewijzingen gemaakt die de prestaties verbeteren door de hoeveelheid gegevens te verminderen die moet worden gescand.
In Azure Synapse kunt u een vergelijkbaar effect bereiken door andere indexen te partitioneren en/of te gebruiken.
Gerealiseerde weergaven: Netezza ondersteunt gerealiseerde weergaven en raadt aan om een of meer gerealiseerde weergaven te gebruiken voor grote tabellen met veel kolommen als er regelmatig slechts enkele kolommen worden gebruikt in query's. Gerealiseerde weergaven worden automatisch vernieuwd door het systeem wanneer gegevens in de basistabel worden bijgewerkt.
Azure Synapse ondersteunt gerealiseerde weergaven, met dezelfde functionaliteit als Netezza.
Toewijzing van Netezza-gegevenstypen
De meeste Netezza-gegevenstypen hebben een direct equivalent in Azure Synapse. In de volgende tabel ziet u de aanbevolen aanpak voor het toewijzen van Netezza-gegevenstypen aan Azure Synapse.
| Netezza-gegevenstype | Azure Synapse gegevenstype |
|---|---|
| BIGINT | BIGINT |
| BINAIR VARIËREND(n) | VARBINARY(n) |
| BOOLEAN | BEETJE |
| BYTEINT | TINYINT |
| TEKEN VARIËREND(n) | VARCHAR(n) |
| TEKEN(n) | TEKEN(n) |
| DATE | DATUM(datum) |
| DECIMAAL(p,s) | DECIMAAL(p,s) |
| DUBBELE PRECISIE | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVAL | INTERVAL-gegevenstypen worden momenteel niet rechtstreeks ondersteund in Azure Synapse, maar kunnen worden berekend met tijdelijke functies zoals DATEDIFF. |
| GELD | GELD |
| NATIONAAL KARAKTER VARIËREND(n) | NVARCHAR(n) |
| NATIONAAL KARAKTER(n) | NCHAR(n) |
| GETAL(p;s) | GETAL(p;s) |
| REAL | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Ruimtelijke gegevenstypen zoals ST_GEOMETRY worden momenteel niet ondersteund in Azure Synapse, maar de gegevens kunnen worden opgeslagen als VARCHAR of VARBINARY. |
| TIME | TIME |
| TIJD MET TIJDZONE | DATETIMEOFFSET |
| TIMESTAMP | DATETIME |
Tip
Evalueer het aantal en het type niet-ondersteunde gegevenstypen tijdens de voorbereidingsfase van de migratie.
Externe leveranciers bieden hulpprogramma's en services voor het automatiseren van migratie, waaronder het toewijzen van gegevenstypen. Als een ETL-hulpprogramma van derden al in gebruik is in de Netezza-omgeving, gebruikt u dat hulpprogramma om eventuele vereiste gegevenstransformaties te implementeren.
Verschillen in SQL DML-syntaxis
Er bestaan verschillen in SQL DML-syntaxis tussen Netezza SQL en Azure Synapse T-SQL. Deze verschillen worden uitgebreid besproken in SQL-problemen voor Netezza-migraties minimaliseren.
STRPOS: in Netezza retourneert deSTRPOSfunctie de positie van een subtekenreeks binnen een tekenreeks. De equivalente functie in Azure Synapse isCHARINDEXmet de volgorde van de argumenten omgekeerd. In Is Netezza bijvoorbeeldSELECT STRPOS('abcdef','def')...gelijk aanSELECT CHARINDEX('def','abcdef')...in Azure Synapse.AGE: Netezza ondersteunt deAGEoperator om het interval tussen twee tijdelijke waarden op te geven, zoals tijdstempels of datums, bijvoorbeeld:SELECT AGE('23-03-1956','01-01-2019') FROM.... Gebruik in Azure SynapseDATEDIFFom het interval op te halen, bijvoorbeeld:SELECT DATEDIFF(day, '1956-03-26','2019-01-01') FROM.... Noteer de volgorde van de datumweergave.NOW(): Netezza gebruiktNOW()om te vertegenwoordigenCURRENT_TIMESTAMPin Azure Synapse.
Functies, opgeslagen procedures en reeksen
Wanneer u een datawarehouse migreert vanuit een volwassen omgeving zoals Netezza, moet u waarschijnlijk andere elementen dan eenvoudige tabellen en weergaven migreren. Controleer of hulpprogramma's in de Azure-omgeving de functionaliteit van functies, opgeslagen procedures en reeksen kunnen vervangen, omdat het meestal efficiënter is om ingebouwde Azure-hulpprogramma's te gebruiken dan om deze elementen opnieuw te coderen voor Azure Synapse.
Als onderdeel van de voorbereidingsfase maakt u een inventaris van objecten die moeten worden gemigreerd, definieert u een methode voor de verwerking ervan en wijst u de juiste resources toe in uw migratieplan.
Partners voor gegevensintegratie bieden hulpprogramma's en services waarmee u de migratie van functies, opgeslagen procedures en reeksen kunt automatiseren.
In de volgende secties wordt verder de migratie van functies, opgeslagen procedures en reeksen besproken.
Functions
Net als bij de meeste databaseproducten ondersteunt Netezza systeem- en door de gebruiker gedefinieerde functies binnen een SQL-implementatie. Wanneer u een verouderd databaseplatform migreert naar Azure Synapse, kunnen algemene systeemfuncties meestal zonder wijzigingen worden gemigreerd. Sommige systeemfuncties hebben mogelijk een iets andere syntaxis, maar eventuele vereiste wijzigingen kunnen worden geautomatiseerd.
Voor Netezza-systeemfuncties of willekeurige door de gebruiker gedefinieerde functies die geen equivalent hebben in Azure Synapse, moet u deze functies opnieuw coderen met behulp van een doelomgevingstaal. Netezza door de gebruiker gedefinieerde functies zijn gecodeerd in nzlua- of C++-talen. Azure Synapse gebruikt de Transact-SQL-taal om door de gebruiker gedefinieerde functies te implementeren.
Opgeslagen procedures
De meeste moderne databaseproducten ondersteunen het opslaan van procedures in de database. Netezza biedt voor dit doel de NZPLSQL-taal, die is gebaseerd op Postgres PL/pgSQL. Een opgeslagen procedure bevat doorgaans zowel SQL-instructies als procedurelogica en retourneert gegevens of een status.
Azure Synapse ondersteunt opgeslagen procedures met behulp van T-SQL, dus u moet alle gemigreerde opgeslagen procedures in die taal opnieuw coderen.
Reeksen
In Netezza is een reeks een benoemd databaseobject dat is gemaakt met behulp van CREATE SEQUENCE. Een reeks biedt unieke numerieke waarden via de NEXT VALUE FOR -methode. U kunt de gegenereerde unieke getallen gebruiken als surrogaatsleutelwaarden voor primaire sleutels.
Azure Synapse implementeert CREATE SEQUENCEniet , maar u kunt reeksen implementeren met behulp van IDENTITEITSkolommen of SQL-code waarmee het volgende reeksnummer in een reeks wordt gegenereerd.
Metagegevens en gegevens extraheren uit een Netezza-omgeving
DDL-generatie (Data Definition Language)
De ANSI SQL-standaard definieert de basissyntaxis voor DDL-opdrachten (Data Definition Language). Sommige DDL-opdrachten, zoals CREATE TABLE en CREATE VIEW, zijn gebruikelijk voor zowel Netezza als Azure Synapse, maar zijn uitgebreid om implementatiespecifieke functies te bieden.
U kunt bestaande Netezza CREATE TABLE en CREATE VIEW scripts bewerken om gelijkwaardige definities in Azure Synapse te bereiken. Hiervoor moet u mogelijk aangepaste gegevenstypen gebruiken en Netezza-specifieke componenten verwijderen of wijzigen, zoals ORGANIZE ON.
In de Netezza-omgeving geven systeemcatalogustabellen de huidige tabel- en weergavedefinitie op. In tegenstelling tot door de gebruiker onderhouden documentatie is de gegevens van de systeemcatalogus altijd volledig en synchroon met de huidige tabeldefinities. Met behulp van hulpprogramma's zoals nz_ddl_table, hebt u toegang tot systeemcatalogusgegevens om DDL-instructies te genereren CREATE TABLE waarmee gelijkwaardige tabellen in Azure Synapse worden gemaakt.
U kunt ook migratie - en ETL-hulpprogramma's van derden gebruiken die systeemcatalogusgegevens verwerken om vergelijkbare resultaten te bereiken.
Gegevensextractie van Netezza
U kunt onbewerkte tabelgegevens uit Netezza-tabellen extraheren naar platte bestanden, zoals CSV-bestanden, met behulp van standaard Netezza-hulpprogramma's zoals nzsql en nzunload, of via externe tabellen. Vervolgens kunt u de platte bestanden comprimeren met behulp van gzip en de gecomprimeerde bestanden uploaden naar Azure Blob Storage met behulp van AzCopy of Azure-hulpprogramma's voor gegevenstransport, zoals Azure Data Box.
Tabelgegevens zo efficiënt mogelijk extraheren. Gebruik de methode voor externe tabellen, omdat dit de snelste methode voor extraheren is. Voer meerdere extracten parallel uit om de doorvoer van gegevensextractie te maximaliseren. Met de volgende SQL-instructie wordt een externe tabelextract uitgevoerd:
CREATE EXTERNAL TABLE '/tmp/export_tab1.csv' USING (DELIM ',') AS SELECT * from <TABLENAME>;
Als er voldoende netwerkbandbreedte beschikbaar is, kunt u gegevens uit een on-premises Netezza-systeem rechtstreeks extraheren in Azure Synapse tabellen of Azure Blob Data Storage. Gebruik hiervoor Data Factory-processen of gegevensmigraties van derden of ETL-producten.
Tip
Gebruik externe Netezza-tabellen voor de meest efficiënte gegevensextractie.
Geëxtraheerde gegevensbestanden moeten tekst met scheidingstekens bevatten in DE INDELING CSV, Geoptimaliseerde rijkolommen (ORC) of Parquet.
Zie Gegevensmigratie, ETL en laden voor Netezza-migraties voor meer informatie over het migreren van gegevens en ETL vanuit een Netezza-omgeving.
Prestatieaanbevelingen voor Netezza-migraties
Het doel van prestatieoptimalisatie is dezelfde of betere prestaties van het datawarehouse na de migratie naar Azure Synapse.
Overeenkomsten in concepten van de aanpak voor het afstemmen van prestaties
Veel concepten voor het afstemmen van prestaties voor Netezza-databases gelden voor Azure Synapse databases. Bijvoorbeeld:
Gebruik gegevensdistributie om gegevens die moeten worden samengevoegd op hetzelfde verwerkingsknooppunt te plaatsen.
Gebruik het kleinste gegevenstype voor een bepaalde kolom om opslagruimte te besparen en de verwerking van query's te versnellen.
Zorg ervoor dat kolommen die moeten worden samengevoegd hetzelfde gegevenstype hebben om de joinverwerking te optimaliseren en de noodzaak van gegevenstransformaties te verminderen.
Om het optimalisatieprogramma te helpen het beste uitvoeringsplan te produceren, moet u ervoor zorgen dat de statistieken up-to-date zijn.
Bewaak de prestaties met behulp van ingebouwde databasemogelijkheden om ervoor te zorgen dat resources efficiënt worden gebruikt.
Tip
Geef prioriteit aan de bekendheid met de afstemmingsopties in Azure Synapse aan het begin van een migratie.
Verschillen in aanpak voor het afstemmen van prestaties
In deze sectie worden de verschillen in implementaties voor het afstemmen van prestaties op laag niveau tussen Netezza en Azure Synapse beschreven.
Opties voor gegevensdistributie
Voor prestaties is Azure Synapse ontworpen met architectuur met meerdere knooppunten en maakt gebruik van parallelle verwerking. Als u de tabelprestaties wilt optimaliseren, kunt u een optie voor gegevensdistributie definiëren in CREATE TABLE instructies met behulp van DISTRIBUTION in Azure Synapse en DISTRIBUTE ON in Netezza.
In tegenstelling tot Netezza ondersteunt Azure Synapse lokale joins tussen een kleine tabel en een grote tabel via kleine tabelreplicatie. Denk bijvoorbeeld aan een kleine dimensietabel en een grote feitentabel binnen een stervormig schemamodel. Azure Synapse kunt de kleinere dimensietabel repliceren op alle knooppunten om ervoor te zorgen dat de waarde van elke joinsleutel voor de grote tabel een overeenkomende, lokaal beschikbare dimensierij heeft. De overhead van replicatie van dimensietabellen is relatief laag voor een kleine dimensietabel. Voor grote dimensietabellen is een hash-distributiebenadering beter geschikt. Zie Ontwerprichtlijnen voor het gebruik van gerepliceerde tabellen en Richtlijnen voor het ontwerpen van gedistribueerde tabellen voor meer informatie over opties voor gegevensdistributie.
Gegevensindexering
Azure Synapse ondersteunt verschillende door de gebruiker gedefinieerde indexeringsopties die een andere bewerking en gebruik hebben dan door het systeem beheerde zonekaarten in Netezza. Zie Indexen op toegewezen SQL-pooltabellen voor meer informatie over de verschillende indexeringsopties in Azure Synapse.
De bestaande door het systeem beheerde zonekaarten binnen een Netezza-bronomgeving bieden een nuttige indicatie van het gegevensgebruik en de kandidaatkolommen voor indexering in de Azure Synapse omgeving.
Gegevenspartitionering
In een datawarehouse voor ondernemingen kunnen feitentabellen miljarden rijen bevatten. Partitionering optimaliseert het onderhoud en de queryprestaties van deze tabellen door ze op te splitsen in afzonderlijke delen om de hoeveelheid verwerkte gegevens te verminderen. In Azure Synapse definieert de CREATE TABLE instructie de partitioneringsspecificatie voor een tabel.
U kunt slechts één veld per tabel gebruiken voor partitionering. Dit veld is vaak een datumveld, omdat veel query's worden gefilterd op datum of datumbereik. Het is mogelijk om de partitionering van een tabel na de eerste belasting te wijzigen door de CREATE TABLE AS CTAS-instructie (CTAS) te gebruiken om de tabel opnieuw te maken met een nieuwe distributie. Zie Partitioning tables in dedicated SQL pool (Tabellen partitioneren in een toegewezen SQL-pool) voor een gedetailleerde bespreking van partitionering in Azure Synapse.
Statistieken van gegevenstabellen
U moet ervoor zorgen dat statistieken voor gegevenstabellen up-to-date zijn door een statistische stap in te bouwen voor ETL-/ELT-taken.
PolyBase of COPY INTO voor het laden van gegevens
PolyBase ondersteunt het efficiënt laden van grote hoeveelheden gegevens in een datawarehouse door gebruik te maken van stromen voor parallel laden. Zie PolyBase-strategie voor het laden van gegevens voor meer informatie.
COPY INTO biedt ook ondersteuning voor gegevensopname met hoge doorvoer, en:
Gegevens ophalen uit alle bestanden in een map en submappen.
Gegevens ophalen vanaf meerdere locaties in hetzelfde opslagaccount. U kunt meerdere locaties opgeven met behulp van door komma's gescheiden paden.
Azure Data Lake Storage (ADLS) en Azure Blob Storage.
CSV-, PARQUET- en ORC-bestandsindelingen.
Werklastbeheer
Het uitvoeren van gemengde workloads kan problemen met resources opleveren op drukke systemen. Een succesvol workloadbeheerschema beheert resources effectief, zorgt voor een zeer efficiënt resourcegebruik en maximaliseert het rendement op investeringen( ROI). Workloadclassificatie, workloadbelang en isolatie van werkbelastingen geven meer controle over hoe de workload gebruikmaakt van systeembronnen.
In de handleiding voor workloadbeheer worden de technieken beschreven voor het analyseren van de workload, het beheren en bewaken van het belang van de workload, en de stappen voor het converteren van een resourceklasse naar een workloadgroep. Gebruik de Azure Portal- en T-SQL-query's op DMV's om de workload te controleren om ervoor te zorgen dat de toepasselijke resources efficiënt worden gebruikt.
Volgende stappen
Zie het volgende artikel in deze reeks voor meer informatie over ETL en laden voor Netezza-migratie: Gegevensmigratie, ETL en laden voor Netezza-migraties.