Zelfstudie: Een Apache Spark-toepassing maken met IntelliJ met behulp van een Synapse-werkruimte
In deze zelfstudie ziet u hoe u de invoegtoepassing Azure-toolkit voor IntelliJ gebruikt om Apache Spark-toepassingen, die in Scala worden geschreven, te ontwikkelen en naar een serverloze Apache Spark-pool te verzenden, rechtstreeks vanuit de IntelliJ-IDE (Integrated Development Environment). U kunt de invoegtoepassing op een paar manieren gebruiken:
- Ontwikkel een Scala Spark-toepassing en verzend deze naar een Spark-pool.
- Verkrijg toegang tot de resources van uw Spark-pools.
- Ontwikkel een Scala Spark-toepassing en voer deze lokaal uit.
In deze zelfstudie leert u het volgende:
- De invoegtoepassing Azure-toolkit voor IntelliJ gebruiken
- Apache Spark-toepassingen ontwikkelen
- Toepassingen naar Spark-pools verzenden
Vereisten
Invoegtoepassing Azure-toolkit 3.27.0-2019.2 – Installeren vanuit Opslagplaats voor IntelliJ-invoegtoepassingen
Scala-invoegtoepassing – Installeren vanuit Opslagplaats voor IntelliJ-invoegtoepassingen.
De volgende vereiste geldt alleen voor Windows-gebruikers:
Terwijl u de lokale Spark Scala-toepassing uitvoert op een Windows-computer, kan er een uitzondering optreden, zoals uitgelegd in SPARK-2356. De uitzondering treedt op omdat WinUtils.exe ontbreekt op Windows. Om deze fout op te lossen, downloadt u het uitvoerbare bestand WinUtils naar een locatie zoals C:\WinUtils\bin. Vervolgens voegt u de omgevingsvariabele HADOOP_HOME toe en stelt u de waarde van de variabele in op C:\WinUtils.
Een Spark Scala-toepassing maken voor een Spark-pool
Start IntelliJ IDEA en selecteer Create New Project om het venster New Project te openen.
Selecteer Apache Spark/HDInsight in het linkerdeelvenster.
Selecteer Spark Project met voorbeelden (Scala) in het hoofdvenster.
Selecteer in de vervolgkeuzelijst Build-hulpprogramma een van de volgende typen:
- Maven, voor de ondersteuning van de wizard Scala-project maken.
- SBT, voor het beheren van de afhankelijkheden en het maken van het Scala-project.
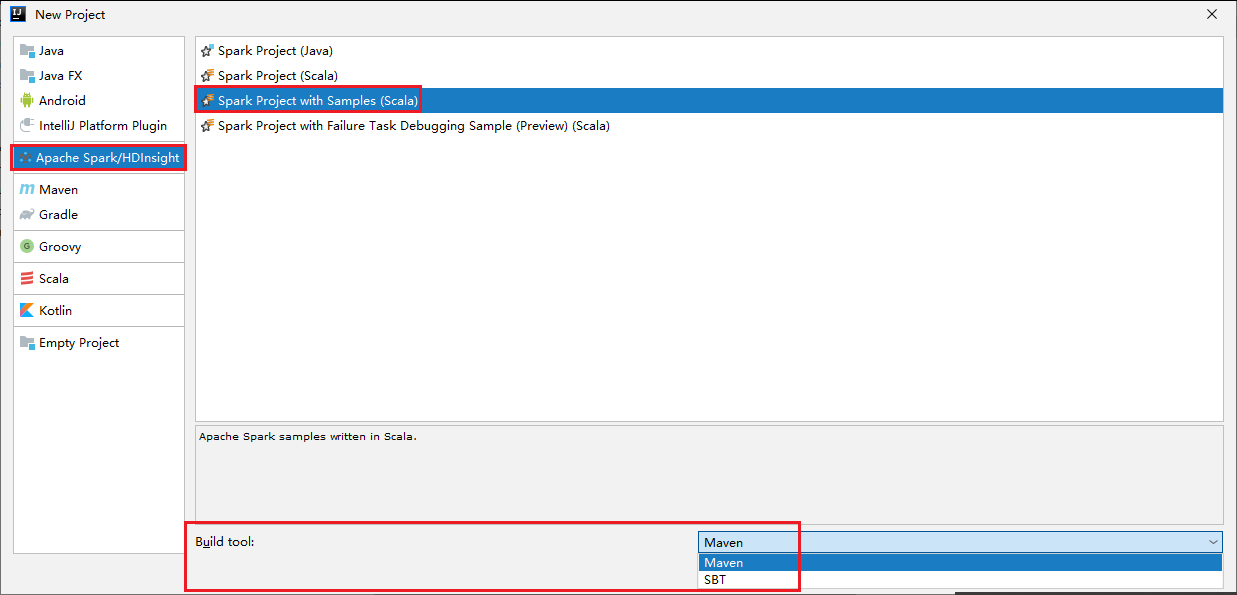
Selecteer Volgende.
Geef in het venster New project de volgende gegevens op:
Eigenschappen Beschrijving Projectnaam Voer een naam in. In deze zelfstudie wordt myAppgebruikt.Projectlocatie Voer de gewenste locatie in om uw project in op te slaan. Project SDK Als u IDEA voor het eerst gebruikt, is dit veld wellicht leeg. Selecteer New... en ga naar uw JDK. Spark-versie De wizard voor het maken van het project integreert de juiste versie voor Spark SDK en Scala SDK. Hier kunt u de Spark-versie kiezen die u nodig hebt. 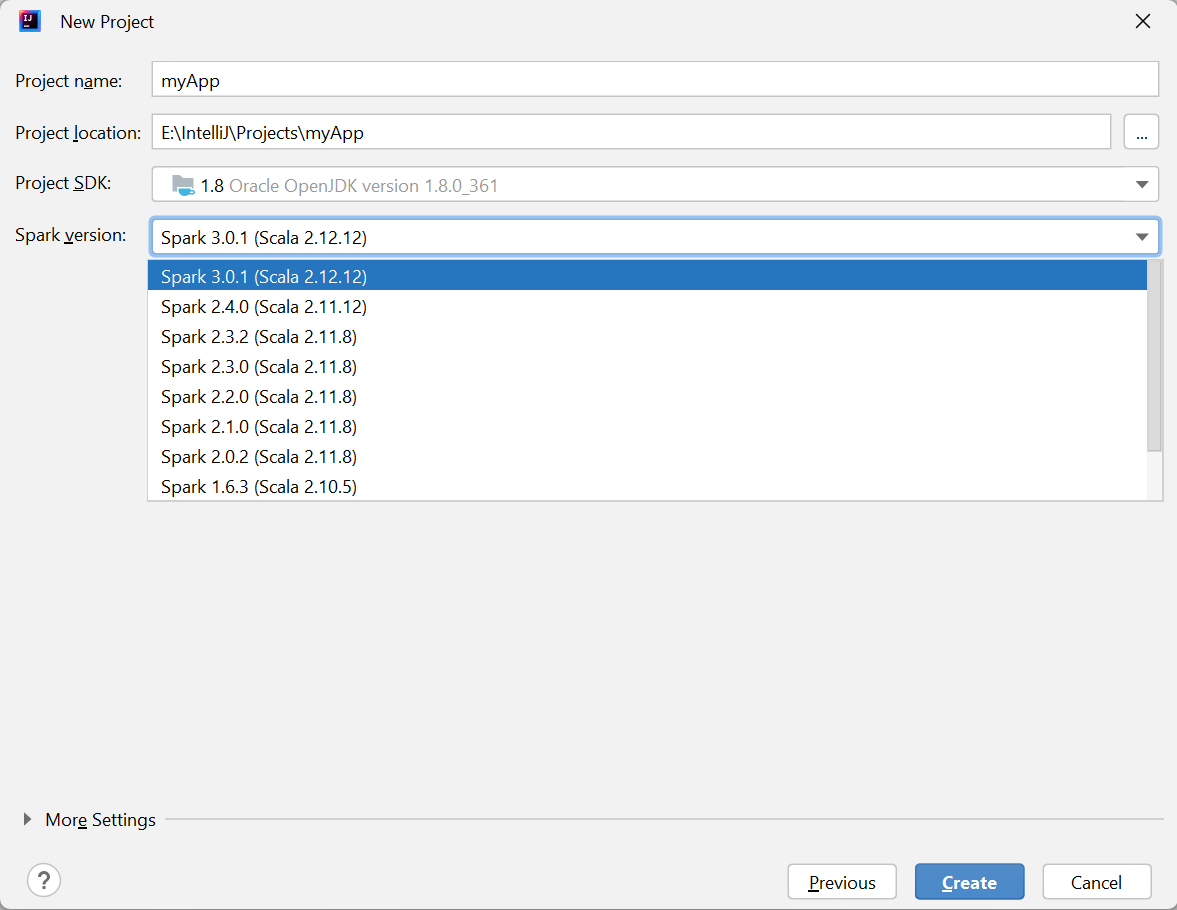
Selecteer Voltooien. Het kan enkele minuten duren voordat het project beschikbaar wordt.
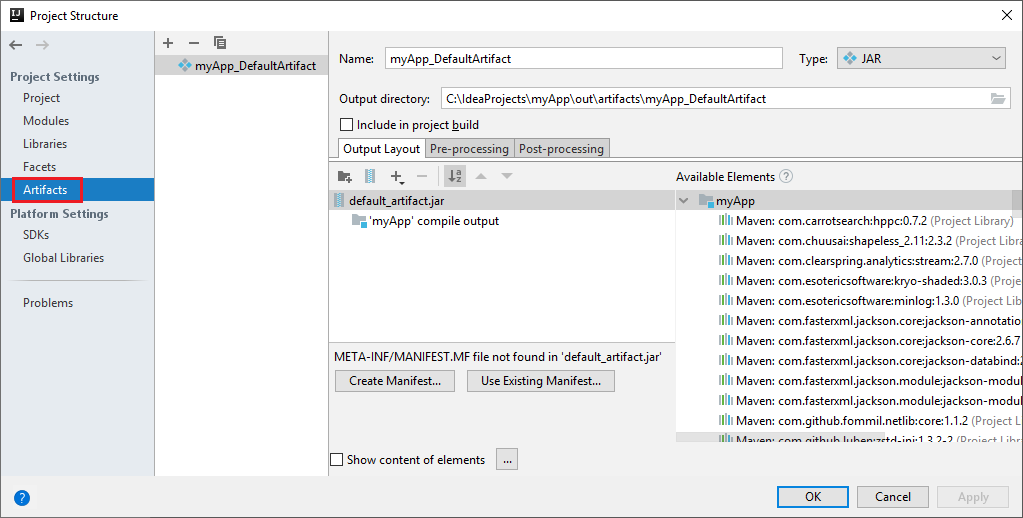
Het Spark-project maakt automatisch een artefact voor u. Doe het volgende om het artefact te bekijken:
a. Navigeer in de menubalk naar Bestand>Projectstructuur....
b. Selecteer in het venster Projectstructuur de optie Artefacten.
c. Selecteer Annuleren nadat u het artefact hebt bekeken.
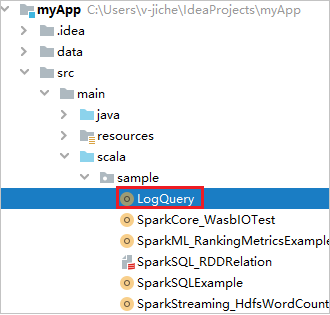
Zoek LogQuery in myApp>src>main>scala>sample>LogQuery. Deze zelfstudie maakt gebruik van LogQuery om te worden uitgevoerd.
Verbinding maken met uw Spark-pools
Meld u aan bij uw Azure-abonnement om verbinding te maken met uw Spark-pools.
Aanmelden bij uw Azure-abonnement
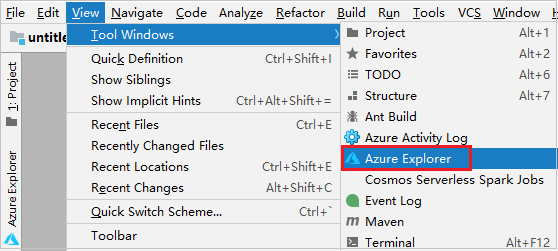
Navigeer in de menubalk naar Beeld>Hulpprogrammavensters>Azure Explorer.
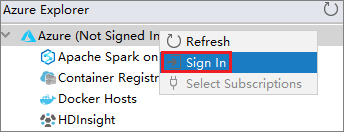
Klik in Azure Explorer met de rechtermuisknop op het knooppunt Azure en selecteer Aanmelden.
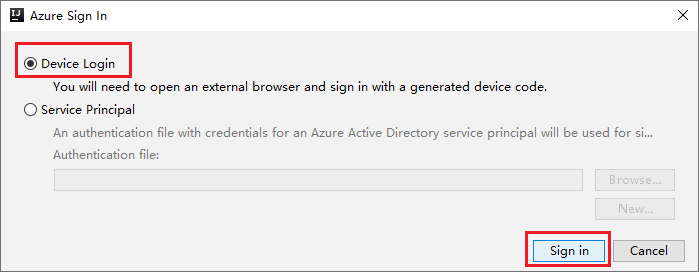
Kies in het dialoogvenster Azure-aanmelding de optie Apparaataanmelding en selecteer Aanmelden.
Selecteer in het dialoogvenster Azure-apparaataanmelding de optie Kopiëren en openen.
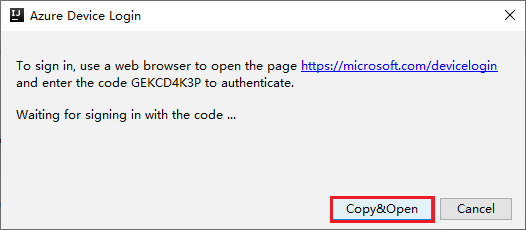
Plak de code in de browserinterface en selecteer Volgende.
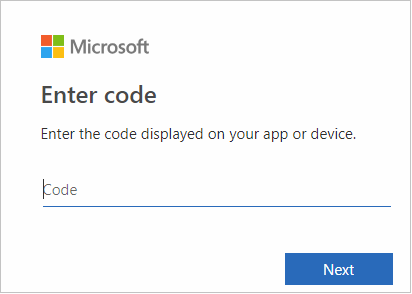
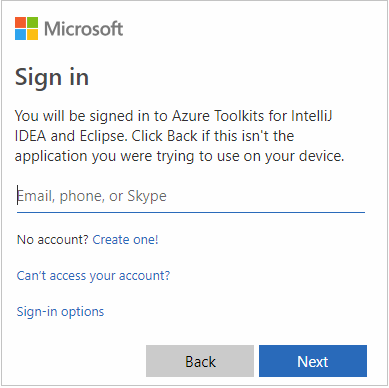
Voer uw referenties voor Azure in en sluit de browser.
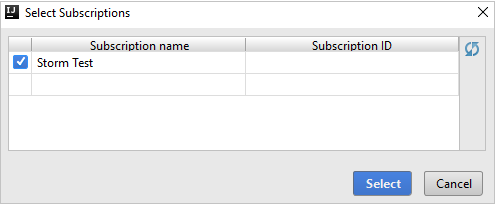
Zodra u bent aangemeld, toont het dialoogvenster Abonnementen selecteren alle Azure-abonnementen die aan de referenties zijn gekoppeld. Selecteer uw abonnement en selecteer Selecteren.
Vouw in Azure Explorer de optie Apache Spark in Synapse uit om de werkruimten te bekijken die in uw abonnementen staan.
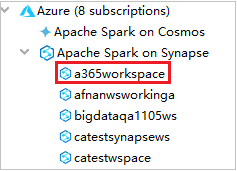
Als u de Spark-pools wilt bekijken, kunt u een werkruimte verder uitvouwen.
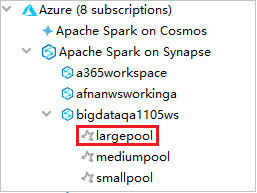
Een Spark Scala-toepassing extern uitvoeren in een Spark-pool
Nadat u een Scala-toepassing hebt gemaakt, kunt u deze extern uitvoeren.
Open het venster Uitvoeren/fouten opsporen van configuraties door het pictogram te selecteren.
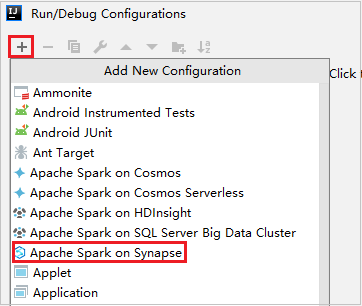
Selecteer in het dialoogvenster Uitvoeren/fouten opsporen van configuraties de optie + en selecteer Apache Spark in Synapse.
Geef in het venster Uitvoeren/fouten opsporen van configuraties de volgende waarden op en selecteer OK:
Eigenschappen Weergegeven als Spark-pools Selecteer de Spark-pools waarop u uw toepassing wilt uitvoeren. Selecteer een artefact om te verzenden Laat de standaardinstelling staan. Hoofdklassenaam De standaardwaarde is de hoofdklasse uit het geselecteerde bestand. U kunt de klasse wijzigen door het beletselteken (...) te selecteren en een andere klasse te kiezen. Taakconfiguraties U kunt de standaardsleutel en -waarden wijzigen. Zie Apache Livy REST API voor meer informatie. Opdrachtregelargumenten U kunt voor de hoofdklasse argumenten invoeren, gescheiden door een spatie, indien nodig. JAR’s en bestanden waarnaar wordt verwezen U kunt de paden invoeren voor de JAR’s en bestanden waarnaar wordt verwezen, indien aanwezig. U kunt ook bladeren door bestanden in het virtuele Azure-bestandssysteem, dat momenteel alleen ADLS Gen2-cluster ondersteunt. Voor meer informatie: Apache Spark-configuratie en het uploaden van resources naar cluster. Opslag van taakuploads Vouw uit om aanvullende opties te onthullen. Opslagtype Selecteer Azure Blob gebruiken voor uploaden of Standaardopslagaccount van cluster gebruiken voor uploaden in de vervolgkeuzelijst. Opslagaccount Voer uw opslagaccount in. Opslagsleutel Voer uw opslagsleutel in. Opslagcontainer Selecteer uw opslagcontainer in de vervolgkeuzelijst zodra Opslagaccount en Opslagsleutel zijn ingevoerd. 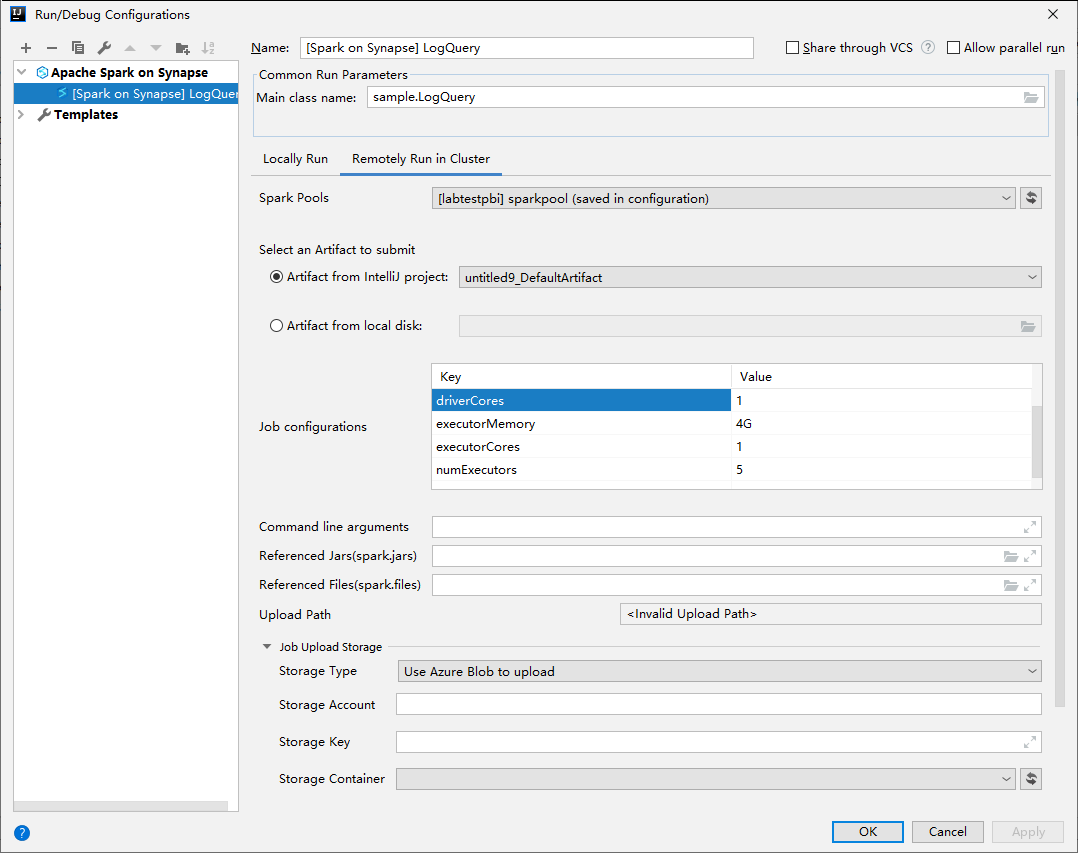
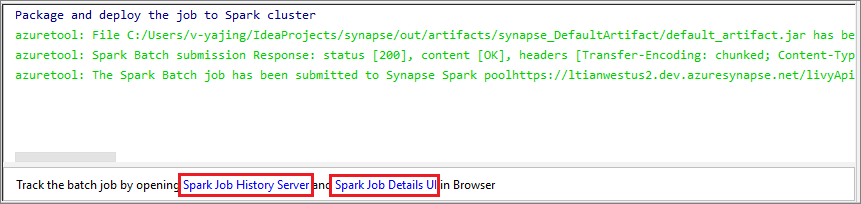
Selecteer het pictogram SparkJobRun om uw project te verzenden naar de geselecteerde Spark-pool. Onderaan het tabblad Externe Spark-taak in cluster wordt de voortgang van de taakuitvoering weergegeven. U kunt de toepassing stoppen door de rode knop te selecteren.

Lokaal uitvoeren/fouten opsporen van Apache Spark-toepassingen
U kunt de onderstaande instructies volgen om uw lokale uitvoering en lokale foutopsporing voor uw Apache Spark-taak in te stellen.
Scenario 1: Lokale uitvoering uitvoeren
Open het dialoogvenster Uitvoeren/fouten opsporen van configuraties en selecteer het plusteken (+). Selecteer vervolgens de optie Apache Spark in Synapse. Voer informatie in voor Naam, Hoofdklassenaam om op te slaan.

- Omgevingsvariabelen en WinUtils.exe-locatie zijn alleen voor Windows-gebruikers.
- Omgevingsvariabelen: de omgevingsvariabele van het systeem kan automatisch worden gedetecteerd als u deze eerder hebt ingesteld en u hoeft deze niet handmatig toe te voegen.
- WinUtils.exe Locatie: U kunt de WinUtils-locatie opgeven door het mappictogram aan de rechterkant te selecteren.
Selecteer vervolgens de knop Lokaal afspelen.

Zodra de lokale uitvoering is voltooid, kunt u (als het script uitvoer bevat) het uitvoerbestand controleren via gegevens>standaard.
Scenario 2: Lokale foutopsporing uitvoeren
Open het LogQuery-script en stel onderbrekingspunten in.
Selecteer het pictogram Lokale foutopsporing om lokaal fouten op te sporen.

Synapse-werkruimte openen en beheren
U kunt verschillende bewerkingen in Azure Explorer uitvoeren in Azure-toolkit voor IntelliJ. Navigeer in de menubalk naar Beeld>Hulpprogrammavensters>Azure Explorer.
Werkruimte starten
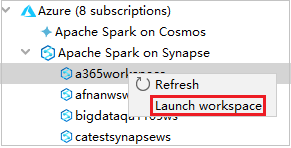
Navigeer in Azure Explorer naar Apache Spark in Synapse en vouw het uit.
Klik met de rechtermuisknop op een werkruimte en selecteer Werkruimte starten, waarna een website wordt geopend.
Spark-console
U kunt de lokale Spark-console (Scala) uitvoeren of de interactieve Spark Livy-sessieconsole (Scala) uitvoeren.
Lokale Spark-console (Scala)
Verzeker dat u aan de WINUTILS.EXE-vereiste voldoet.
Navigeer in de menubalk naar Uitvoeren>Configuraties bewerken....
Navigeer in het linkerdeelvenster van het venster Uitvoeren/fouten opsporen van configuraties naar Apache Spark in Synapse>[Spark in Synapse] myApp.
Selecteer in het hoofdvenster het tabblad Lokaal uitvoeren.
Geef de volgende waarden op en selecteer OK:
Eigenschappen Weergegeven als Omgevingsvariabelen Verzeker dat de waarde voor HADOOP_HOME correct is. WINUTILS.exe-locatie Verzeker dat het pad correct is. 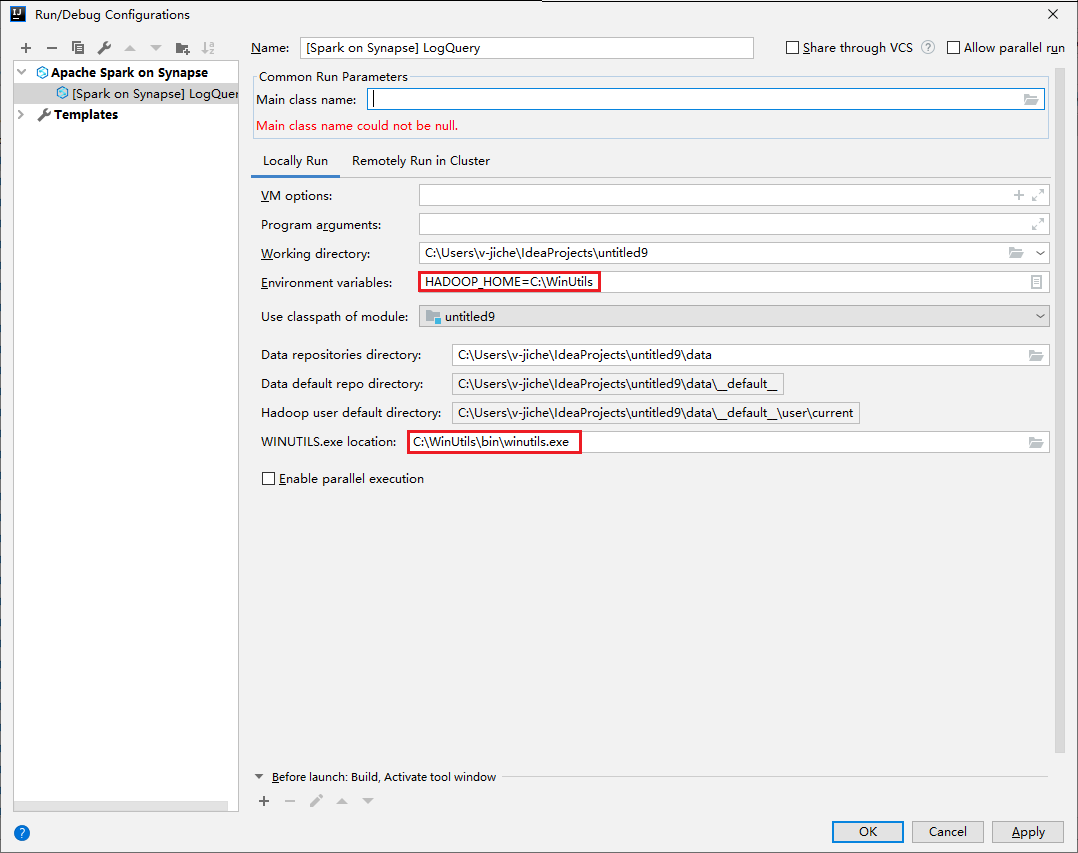
Navigeer in Project naar myApp>src>main>scala>myApp.
Navigeer in de menubalk naar Hulpprogramma’s>Spark-console>Lokale Spark-console (Scala) uitvoeren.
Er kunnen dan twee dialoogvensters worden weergegeven waarin u wordt gevraagd of u afhankelijkheden automatisch wilt oplossen. Als u dat wilt doen, selecteert u Automatisch oplossen.
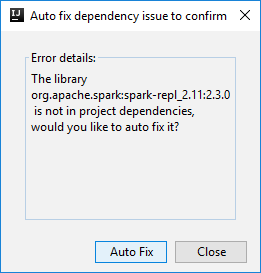
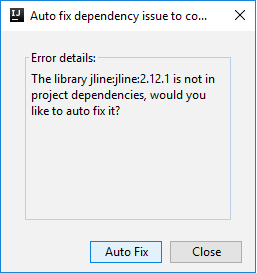
De console moet er ongeveer uitzien zoals in de onderstaande afbeelding. Typ
sc.appNamein het consolevenster en druk op Ctrl+Enter. Het resultaat wordt weergegeven. U kunt de lokale console stoppen door de rode knop te selecteren.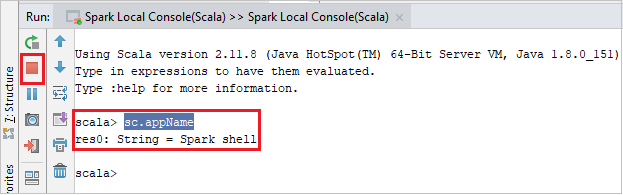
Interactieve Spark Livy-sessieconsole (Scala)
Deze wordt alleen ondersteund in IntelliJ 2018.2 en 2018.3.
Navigeer in de menubalk naar Uitvoeren>Configuraties bewerken....
Navigeer in het linkerdeelvenster van het venster Uitvoeren/fouten opsporen van configuraties naar Apache Spark in Synapse>[Spark in Synapse] myApp.
Selecteer in het hoofdvenster het tabblad Extern uitvoeren in cluster.
Geef de volgende waarden op en selecteer OK:
Eigenschappen Weergegeven als Hoofdklassenaam Selecteer de hoofdklassenaam. Spark-pools Selecteer de Spark-pools waarop u uw toepassing wilt uitvoeren. 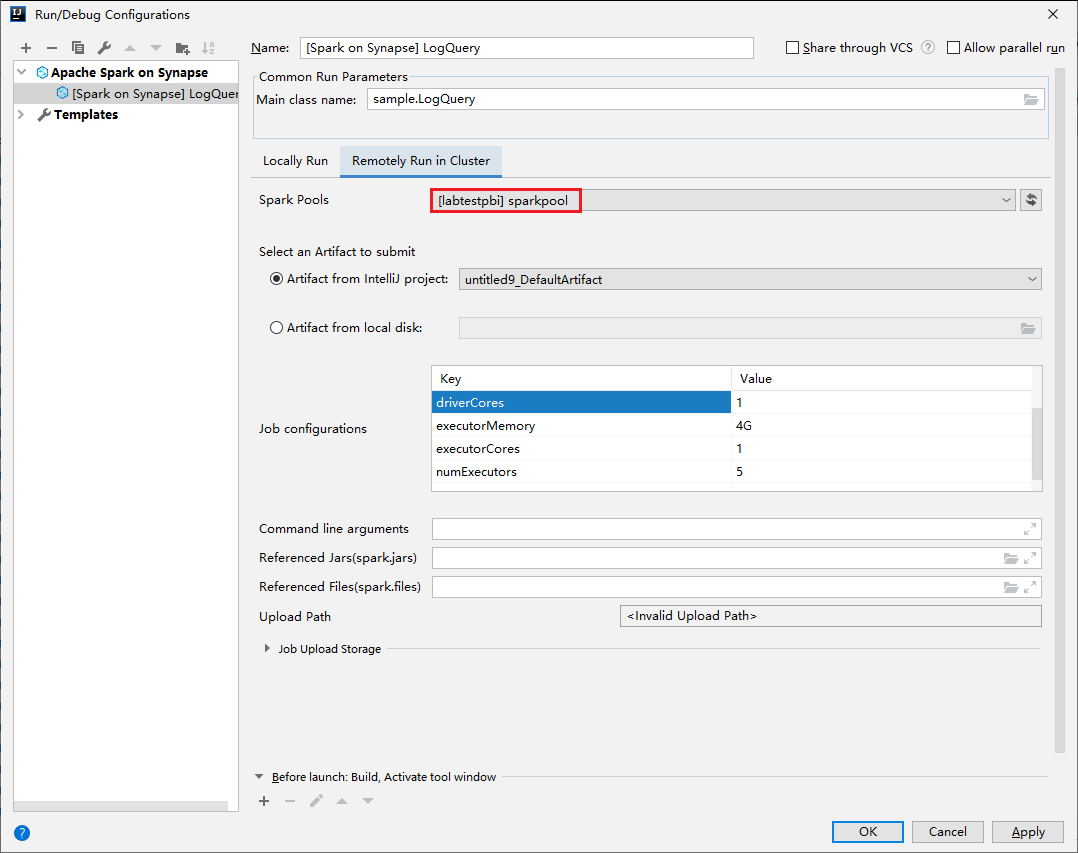
Navigeer in Project naar myApp>src>main>scala>myApp.
Navigeer in de menubalk naar Hulpprogramma’s>Spark-console>Interactieve Spark Livy-sessieconsole (Scala) uitvoeren.
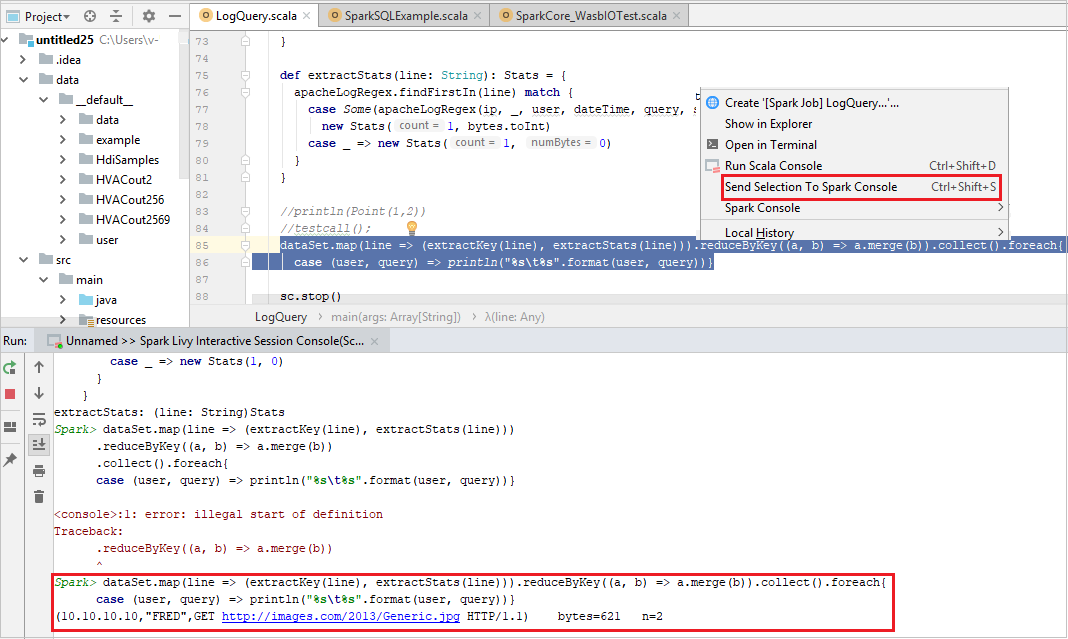
De console moet er ongeveer uitzien zoals in de onderstaande afbeelding. Typ
sc.appNamein het consolevenster en druk op Ctrl+Enter. Het resultaat wordt weergegeven. U kunt de lokale console stoppen door de rode knop te selecteren.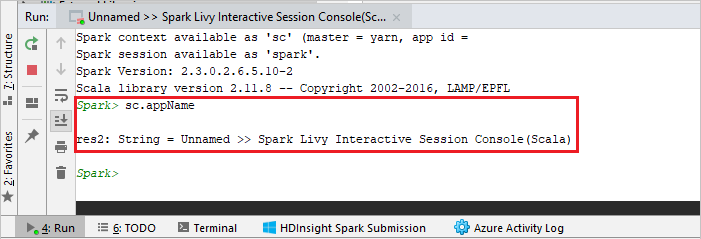
Selectie verzenden naar Spark-console
U kunt het scriptresultaat te voorzien door wat code naar de lokale console of de interactieve Livy-sessieconsole (Scala) te verzenden. Daarvoor kunt u wat code in het Scala-bestand markeren en vervolgens met de rechtermuisknop op Selectie verzenden naar Spark-console klikken. De geselecteerde code wordt dan naar de console verzonden en uitgevoerd. Het resultaat wordt achter de code weergegeven in de console. De console controleert de aanwezige fouten.