Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Is van toepassing op de aanbeveling voor azure Well-Architected Framework Security-controlelijst:
| SE:12 | Definieer en test effectieve procedures voor incidentrespons die betrekking hebben op een spectrum van incidenten, van gelokaliseerde problemen tot herstel na noodgevallen. Definieer duidelijk welk team of individu een procedure uitvoert. |
|---|
In deze handleiding worden de aanbevelingen beschreven voor het implementeren van een reactie op beveiligingsincidenten voor een workload. Als er sprake is van een beveiligingsrisico voor een systeem, helpt een systematische benadering van incidentrespons om de tijd te verminderen die nodig is om beveiligingsincidenten te identificeren, te beheren en te beperken. Deze incidenten kunnen de vertrouwelijkheid, integriteit en beschikbaarheid van softwaresystemen en gegevens bedreigen.
De meeste ondernemingen hebben een centraal beveiligingsteam (ook wel BEKEND als Security Operations Center (SOC) of SecOps). De verantwoordelijkheid van het beveiligingsteam is het snel detecteren, prioriteren en classificeren van mogelijke aanvallen. Het team bewaakt ook beveiligingsgerelateerde telemetriegegevens en onderzoekt beveiligingsschendingen.
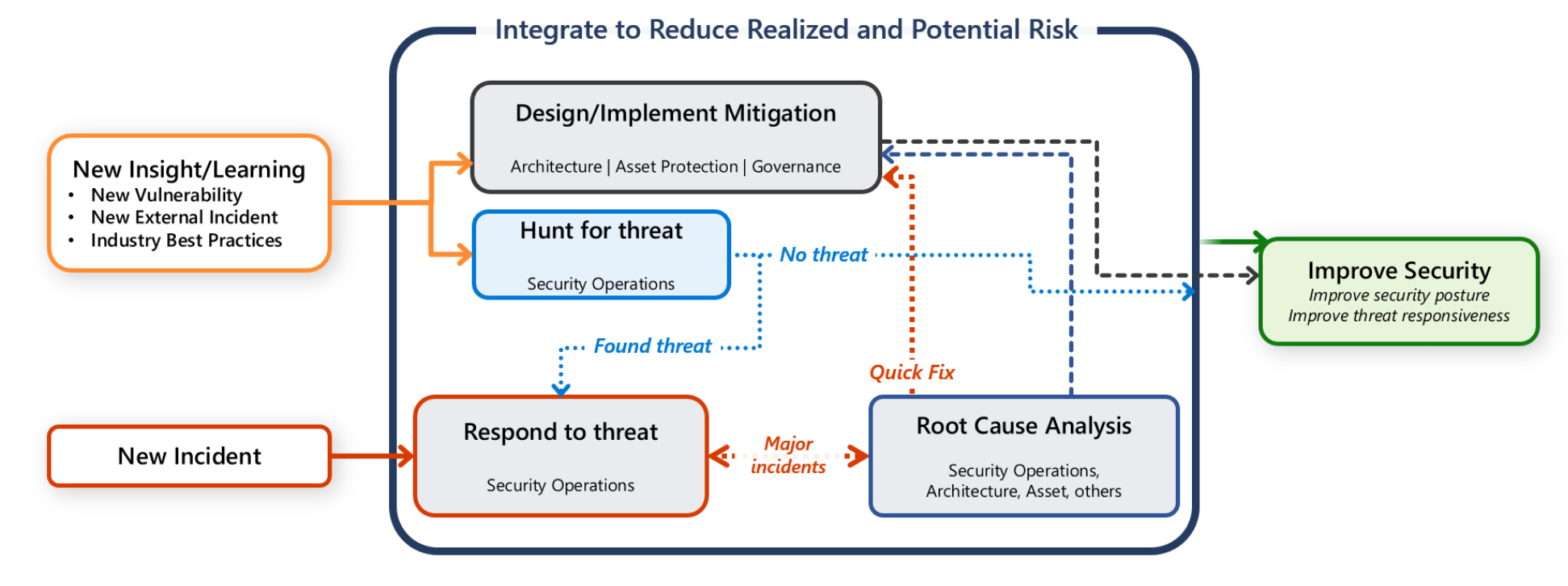
U hebt echter ook de verantwoordelijkheid om uw workload te beschermen. Het is belangrijk dat communicatie-, onderzoeks- en opsporingsactiviteiten samenwerken tussen het workloadteam en het SecOps-team.
Deze handleiding bevat aanbevelingen voor u en uw workloadteam om u te helpen bij het snel detecteren, classificeren en onderzoeken van aanvallen.
Definities
| Termijn | Definitie |
|---|---|
| Waarschuwing | Een melding met informatie over een incident. |
| Betrouwbaarheid van waarschuwingen | De nauwkeurigheid van de gegevens die een waarschuwing bepalen. Waarschuwingen met hoge kwaliteit bevatten de beveiligingscontext die nodig is om onmiddellijk acties uit te voeren. Waarschuwingen met lage kwaliteit ontbreken informatie of bevatten ruis. |
| Fout-positief | Een waarschuwing die aangeeft dat er geen incident is gebeurd. |
| Incident | Een gebeurtenis die aangeeft dat onbevoegde toegang tot een systeem is. |
| Reageren op incidenten | Een proces dat risico's detecteert, beantwoordt en beperkt die zijn gekoppeld aan een incident. |
| Sorteren | Een reactiebewerking voor incidenten waarmee beveiligingsproblemen worden geanalyseerd en prioriteit wordt gegeven aan de risicobeperking. |
Belangrijke ontwerpstrategieën
U en uw team voeren incidentresponsbewerkingen uit wanneer er een signaal of waarschuwing is voor een mogelijk compromis. Waarschuwingen met hoge kwaliteit bevatten voldoende beveiligingscontext waarmee analisten eenvoudig beslissingen kunnen nemen. Waarschuwingen met hoge kwaliteit resulteren in een laag aantal fout-positieven. In deze handleiding wordt ervan uitgegaan dat een waarschuwingssysteem signalen met lage beeldkwaliteit filtert en zich richt op waarschuwingen met hoge kwaliteit die een echt incident kunnen aangeven.
Contactpersonen voor incidentmeldingen aanwijzen
Beveiligingswaarschuwingen moeten de juiste personen in uw team en in uw organisatie bereiken. Stel een aangewezen contactpunt in voor uw workloadteam om incidentmeldingen te ontvangen. Deze meldingen moeten zoveel mogelijk informatie bevatten over de resource die is aangetast en het systeem. De waarschuwing moet de volgende stappen bevatten, zodat uw team acties kan versnellen.
U wordt aangeraden incidentenmeldingen en acties te registreren en te beheren met behulp van gespecialiseerde hulpprogramma's waarmee een audittrail wordt bijgehouden. Met behulp van standaardhulpprogramma's kunt u bewijs bewaren dat mogelijk vereist is voor mogelijke juridische onderzoeken. Zoek naar mogelijkheden om automatisering te implementeren die meldingen kan verzenden op basis van de verantwoordelijkheden van verantwoordelijke partijen. Houd een duidelijke keten van communicatie en rapportage tijdens een incident.
Profiteer van SIEM-oplossingen (Security Information Event Management) en SOAR-oplossingen (Security Orchestration Automated Response) die uw organisatie biedt. U kunt ook hulpprogramma's voor incidentbeheer aanschaffen en uw organisatie aanmoedigen om ze te standaardiseren voor alle workloadteams.
Onderzoeken met een triageteam
Het teamlid dat een incidentmelding ontvangt, is verantwoordelijk voor het instellen van een triageproces waarbij de juiste personen zijn betrokken op basis van de beschikbare gegevens. Het triageteam, ook wel het brugteam genoemd, moet akkoord gaan met de modus en het communicatieproces. Zijn voor dit incident asynchrone discussies of brugaanroepen vereist? Hoe moet het team de voortgang van onderzoeken bijhouden en doorgeven? Waar kan het team toegang krijgen tot incidentassets?
Reactie op incidenten is een cruciale reden om documentatie up-to-date te houden, zoals de architectuurindeling van het systeem, informatie op onderdeelniveau, privacy- of beveiligingsclassificatie, eigenaren en belangrijke contactpunten. Als de informatie onnauwkeurig of verouderd is, verspilt het brugteam waardevolle tijd om te begrijpen hoe het systeem werkt, wie verantwoordelijk is voor elk gebied en wat het effect van de gebeurtenis kan zijn.
Betrek voor verder onderzoek de juiste personen. U kunt een incidentmanager, beveiligingsmedewerker of workloadgerichte leads opnemen. Als u de sortering gefocust wilt houden, sluit u personen uit die buiten het bereik van het probleem vallen. Soms onderzoeken afzonderlijke teams het incident. Er kan een team zijn dat het probleem in eerste instantie onderzoekt en probeert het incident te beperken, en een ander gespecialiseerd team dat forensische gegevens kan uitvoeren voor een grondig onderzoek om brede problemen vast te stellen. U kunt de workloadomgeving in quarantaine plaatsen om het forensische team in staat te stellen hun onderzoeken uit te voeren. In sommige gevallen kan hetzelfde team het hele onderzoek afhandelen.
In de eerste fase is het triageteam verantwoordelijk voor het bepalen van de potentiële vector en het effect ervan op de vertrouwelijkheid, integriteit en beschikbaarheid (ook wel de CIA genoemd) van het systeem.
Wijs binnen de categorieën CIA een eerste ernstniveau toe dat de diepte van de schade en de urgentie van herstel aangeeft. Dit niveau wordt naar verwachting in de loop van de tijd gewijzigd, omdat er meer informatie wordt gedetecteerd in de triageniveaus.
In de detectiefase is het belangrijk om direct actie- en communicatieplannen te bepalen. Zijn er wijzigingen in de actieve status van het systeem? Hoe kan de aanval worden opgenomen om verdere exploitatie te stoppen? Moet het team interne of externe communicatie verzenden, zoals een verantwoorde openbaarmaking? Houd rekening met detectie en reactietijd. U bent mogelijk wettelijk verplicht om bepaalde soorten schendingen binnen een bepaalde periode aan een regelgevende instantie te melden, wat vaak uren of dagen is.
Als u besluit het systeem af te sluiten, leiden de volgende stappen tot het herstel na noodgeval (DR) van de workload.
Als u het systeem niet afsluit, bepaalt u hoe u het incident herstelt zonder dat dit van invloed is op de functionaliteit van het systeem.
Herstellen van een incident
Behandel een beveiligingsincident als een noodgeval. Als voor het herstel volledig herstel is vereist, gebruikt u de juiste herstelmechanismen vanuit het oogpunt van beveiliging. Het herstelproces moet de kans op terugkeerpatroon voorkomen. Anders wordt het probleem opnieuw door herstel vanuit een beschadigde back-up opnieuw ingevoerd. Het opnieuw implementeren van een systeem met hetzelfde beveiligingsprobleem leidt tot hetzelfde incident. Failover- en failbackstappen en -processen valideren.
Als het systeem blijft functioneren, beoordeelt u het effect op de actieve onderdelen van het systeem. Blijf het systeem bewaken om ervoor te zorgen dat aan andere betrouwbaarheids- en prestatiedoelen wordt voldaan of aangepast door de juiste degradatieprocessen te implementeren. Maak geen inbreuk op privacy vanwege risicobeperking.
Diagnose is een interactief proces totdat de vector, en een mogelijke oplossing en terugval, wordt geïdentificeerd. Na diagnose werkt het team aan herstel, waarmee de vereiste oplossing binnen een acceptabele periode wordt geïdentificeerd en toegepast.
Metrische herstelgegevens meten hoe lang het duurt om een probleem op te lossen. In het geval van een afsluiting kan er een urgentie zijn met betrekking tot de hersteltijden. Om het systeem te stabiliseren, kost het tijd om fixes, patches en tests toe te passen en updates te implementeren. Bepaal insluitingsstrategieën om verdere schade en de verspreiding van het incident te voorkomen. Ontwikkel uitroeiingsprocedures om de bedreiging volledig uit het milieu te verwijderen.
Compromis: Er is een compromis tussen betrouwbaarheidsdoelen en hersteltijden. Tijdens een incident is het waarschijnlijk dat u niet voldoet aan andere niet-functionele of functionele vereisten. U moet bijvoorbeeld onderdelen van uw systeem uitschakelen tijdens het onderzoeken van het incident, of u moet zelfs het hele systeem offline halen totdat u het bereik van het incident bepaalt. Zakelijke besluitvormers moeten expliciet bepalen wat de acceptabele doelen zijn tijdens het incident. Geef duidelijk de persoon op die verantwoordelijk is voor die beslissing.
Leren van een incident
Een incident ontdekt hiaten of kwetsbare punten in een ontwerp of implementatie. Het is een verbeteringskans die wordt aangestuurd door lessen in technische ontwerpaspecten, automatisering, productontwikkelingsprocessen die testen en de effectiviteit van het incidentresponsproces omvatten. Houd gedetailleerde incidentrecords bij, inclusief acties, tijdlijnen en bevindingen.
We raden u ten zeerste aan gestructureerde incidentbeoordelingen uit te voeren, zoals hoofdoorzaakanalyse en retrospectieven. Houd het resultaat van deze beoordelingen bij en geef prioriteit aan het gebruik van wat u in toekomstige workloadontwerpen leert.
Verbeteringsplannen moeten updates bevatten voor beveiligingsanalyses en -tests, zoals BCDR-drills (bedrijfscontinuïteit en herstel na noodgevallen). Gebruik beveiligingsrisico's als scenario voor het uitvoeren van een BCDR-analyse. Met drills kunt u valideren hoe de gedocumenteerde processen werken. Er mogen niet meerdere playbooks voor incidentrespons zijn. Gebruik één bron die u kunt aanpassen op basis van de grootte van het incident en hoe wijdverspreid of gelokaliseerd het effect is. Drills zijn gebaseerd op hypothetische situaties. Voer analyses uit in een omgeving met een laag risico en neem de leerfase op in de oefeningen.
Voer incidentbeoordelingen, of postmortems, uit om zwakke plekken in het reactieproces en terreinen voor verbetering te identificeren. Op basis van de lessen die u van het incident leert, werkt u het incidentresponsplan (IRP) en de beveiligingscontroles bij.
Een communicatieplan definiëren
Implementeer een communicatieplan om gebruikers op de hoogte te stellen van een onderbreking en interne belanghebbenden te informeren over het herstel en de verbeteringen. Andere personen in uw organisatie moeten op de hoogte worden gesteld van wijzigingen in de beveiligingsbasislijn van de workload om toekomstige incidenten te voorkomen.
Incidentrapporten genereren voor intern gebruik en, indien nodig, voor naleving van regelgeving of juridische doeleinden. Gebruik ook een standaardindelingsrapport (een documentsjabloon met gedefinieerde secties) die het SOC-team gebruikt voor alle incidenten. Zorg ervoor dat aan elk incident een rapport is gekoppeld voordat u het onderzoek sluit.
Azure-facilitering
Microsoft Sentinel is een SIEM- en SOAR-oplossing. Het is één oplossing voor waarschuwingsdetectie, zichtbaarheid van bedreigingen, proactieve opsporing en reactie op bedreigingen. Zie Microsoft Sentinel voor meer informatie ?
Zorg ervoor dat de Azure-inschrijvingsportal contactgegevens voor beheerders bevat, zodat beveiligingsbewerkingen rechtstreeks via een intern proces kunnen worden gewaarschuwd. Zie Instellingen voor updatemeldingen voor meer informatie.
Zie E-mailmeldingen configureren voor beveiligingswaarschuwingen voor meer informatie over het tot stand brengen van een aangewezen contactpunt dat azure-incidentmeldingen ontvangt van Microsoft Defender voor Cloud.
Uitlijning van de organisatie
Cloud Adoption Framework voor Azure biedt richtlijnen over planning en beveiligingsbewerkingen voor incidentrespons. Zie Beveiligingsbewerkingen voor meer informatie.
Verwante koppelingen
- Automatisch incidenten maken van Microsoft-beveiligingswaarschuwingen
- End-to-end opsporing van bedreigingen uitvoeren met behulp van de opsporingsfunctie
- E-mailmeldingen configureren voor beveiligingswaarschuwingen
- Overzicht van reactie op incidenten
- Gereedheid voor Microsoft Azure-incidenten
- Navigeren en onderzoeken van incidenten in Microsoft Sentinel
- Beveiligingsbeheer: reactie op incidenten
- SOAR-oplossingen in Microsoft Sentinel
- Training: Inleiding tot azure-incidentgereedheid
- Instellingen voor meldingen in Azure Portal bijwerken
- Wat is een SOC?
- Wat is Microsoft Sentinel?
Controlelijst voor beveiliging
Raadpleeg de volledige set aanbevelingen.