Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Gegevensstromen worden ondersteund voor Gebruikers van Power BI Pro, Premium Per Gebruiker (PPU) en Power BI Premium. Sommige functies zijn alleen beschikbaar met een Power BI Premium-abonnement (een Premium-capaciteit of PPU-licentie). In dit artikel worden de PPU- en Premium-functies en hun gebruik uitgebreid beschreven.
De volgende functies zijn alleen beschikbaar met Power BI Premium (PPU of een Premium-capaciteitsabonnement):
- Verbeterde berekeningsengine
- DirectQuery
- Berekende entiteiten
- Gekoppelde entiteiten
- Incrementele vernieuwing
In de volgende secties wordt elk van deze functies uitgebreid beschreven.
Belangrijk
Dit artikel is van toepassing op de eerste generatie gegevensstromen (Gen1) en is niet van toepassing op de tweede generatie (Gen2) van gegevensstromen, die beschikbaar zijn in Microsoft Fabric. Zie Upgrade van Dataflow Gen1 naar Dataflow Gen2 voor meer informatie.
De verbeterde berekeningsengine
Met de verbeterde berekeningsengine in Power BI kunnen Power BI Premium-abonnees hun capaciteit gebruiken om het gebruik van gegevensstromen te optimaliseren. Het gebruik van de verbeterde berekeningsengine biedt de volgende voordelen:
- Vermindert drastisch de verversingstijd die nodig is voor langlopende ETL-stappen (extraheren, transformeren, laden) voor berekende entiteiten, zoals het uitvoeren van joins, distinct, filters en group by.
- Voert DirectQuery-query's uit op entiteiten.
Notitie
- De validatie- en vernieuwingsprocessen informeren gegevensstromen van het modelschema. Als u het schema van de tabellen zelf wilt instellen, gebruikt u de Power Query-editor en stelt u gegevenstypen in.
- Deze functie is beschikbaar op alle Power BI-clusters, behalve WABI-INDIA-CENTRAAL-A-PRIMARY
De verbeterde berekeningsengine inschakelen
Belangrijk
De verbeterde berekeningsengine werkt alleen voor A3- of grotere Power BI-capaciteiten.
In Power BI Premium wordt de verbeterde berekeningsengine afzonderlijk ingesteld voor elke gegevensstroom. Er zijn drie configuraties waaruit u kunt kiezen:
Uitgeschakeld
Geoptimaliseerd (standaard): de verbeterde berekeningsengine is uitgeschakeld. Deze functie wordt automatisch ingeschakeld wanneer naar een tabel in de gegevensstroom wordt verwezen door een andere tabel of wanneer de gegevensstroom is verbonden met een andere gegevensstroom in dezelfde werkruimte.
On
Voer de volgende stappen uit om de standaardinstelling te wijzigen en de verbeterde berekeningsengine in te schakelen:
Selecteer meer opties in uw werkruimte naast de gegevensstroom waarvoor u de instellingen wilt wijzigen.
Selecteer Instellingen in het menu Meer opties van de gegevensstroom.
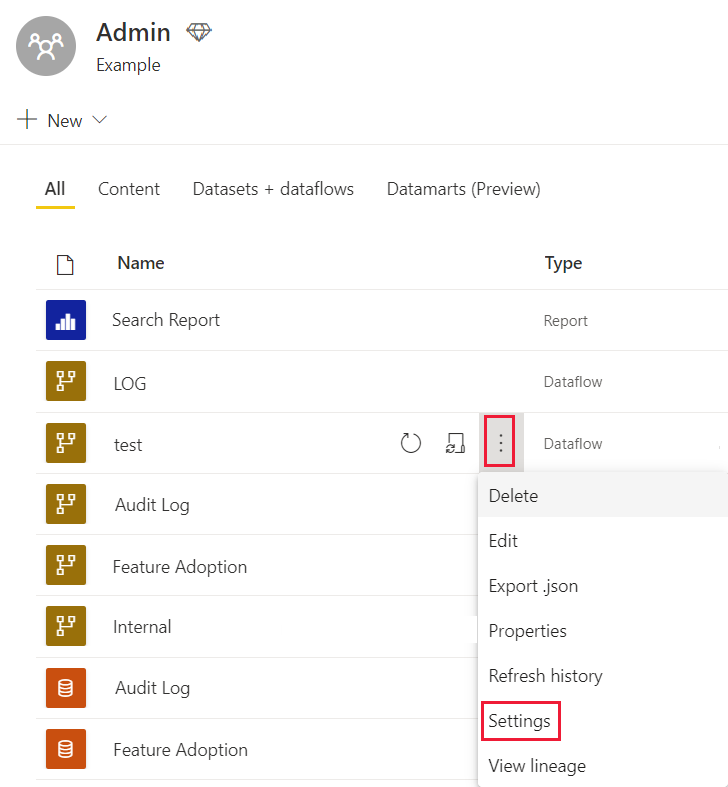
Vouw de instellingen van de verbeterde berekeningsengine uit.
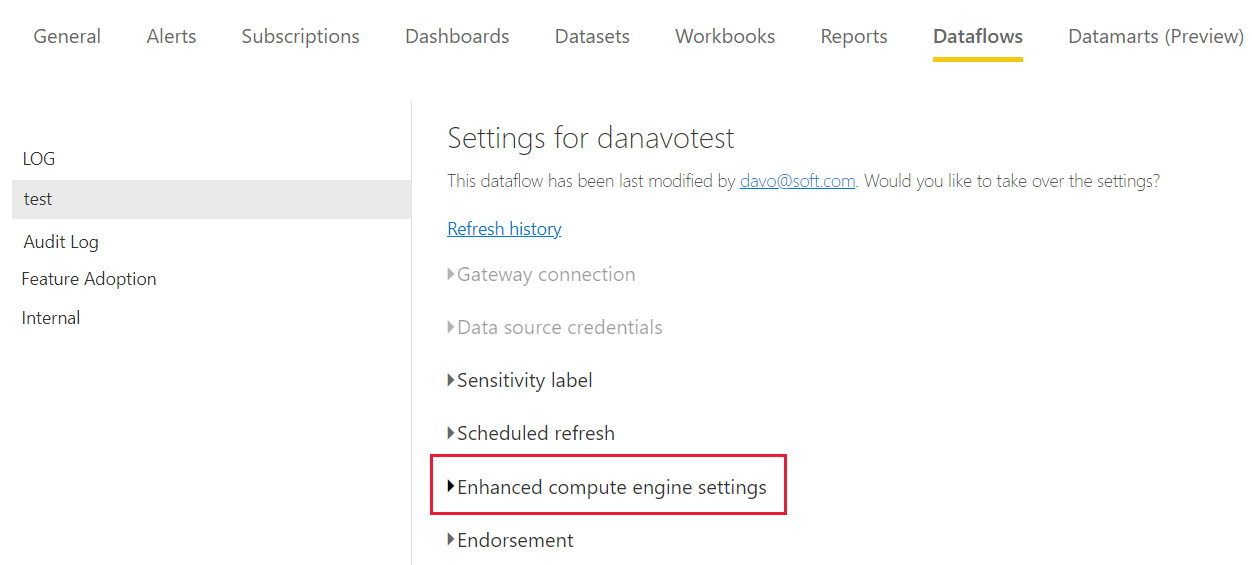
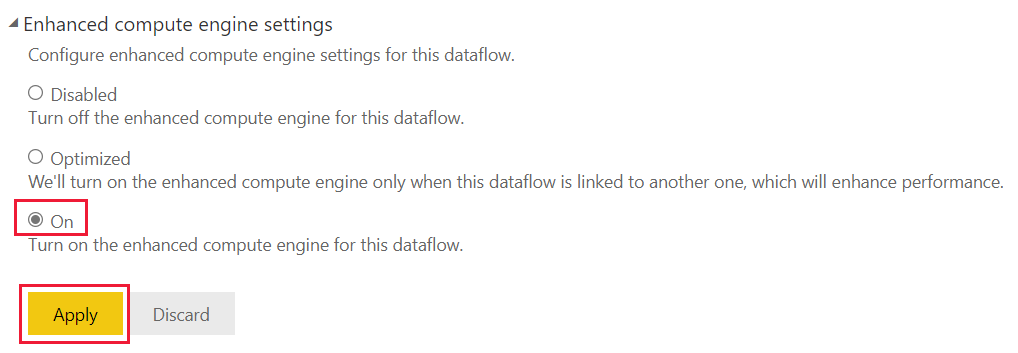
Selecteer In de instellingen van de verbeterde berekeningsengine de optie Aan en kies Vervolgens Toepassen.
De verbeterde berekeningsengine gebruiken
Nadat de verbeterde berekeningsengine is ingeschakeld, keert u terug naar gegevensstromen en zou u een prestatieverbetering moeten zien in elke berekende tabel die complexe bewerkingen uitvoert, zoals joins of groeperen op bewerkingen voor gegevensstromen die zijn gemaakt op basis van bestaande gekoppelde entiteiten met dezelfde capaciteit.
Als u optimaal gebruik wilt maken van de berekeningsengine, splitst u de ETL-fase op in twee afzonderlijke gegevensstromen in dezelfde werkruimte, op de volgende manier:
- Gegevensstroom 1 : deze gegevensstroom mag alleen alle vereiste gegevens uit een gegevensbron opnemen.
- Gegevensstroom 2 : voer alle ETL-bewerkingen in deze tweede gegevensstroom uit, maar zorg ervoor dat u verwijst naar gegevensstroom 1, die zich in dezelfde capaciteit moet bevinden. Zorg er ook voor dat u bewerkingen uitvoert die als eerst gevouwen kunnen worden: filteren, groeperen op, onderscheiden, samenvoegen). En voer deze bewerkingen uit vóór een andere bewerking om ervoor te zorgen dat de berekeningsengine wordt gebruikt.
Veelgestelde vragen en antwoorden
Vraag: Ik heb de verbeterde rekenengine ingeschakeld, maar mijn vernieuwingen zijn langzamer. Waarom?
Antwoord: Als u de verbeterde berekeningsengine inschakelt, zijn er twee mogelijke verklaringen die kunnen leiden tot tragere vernieuwingstijden:
Wanneer de verbeterde berekeningsengine is ingeschakeld, is enige geheugen vereist om goed te functioneren. Als zodanig wordt het geheugen dat beschikbaar is om een vernieuwing uit te voeren verminderd en wordt de kans groter dat vernieuwingen in de wachtrij worden geplaatst. Deze toename vermindert vervolgens het aantal gegevensstromen dat gelijktijdig kan worden vernieuwd. Om dit probleem op te lossen, kunt u bij het inschakelen van verbeterde berekeningen gegevensstromen in de loop van de tijd verspreiden en evalueren of uw capaciteitsgrootte voldoende is om ervoor te zorgen dat er geheugen beschikbaar is voor gelijktijdige gegevensstroomvernieuwing.
Een andere reden waarom u tragere vernieuwingen kunt tegenkomen, is dat de berekeningsengine alleen op bestaande entiteiten werkt. Als uw gegevensstroom verwijst naar een gegevensbron die geen gegevensstroom is, ziet u geen verbetering. Er is geen prestatieverhoging, omdat in sommige big data-scenario's de initiële leesbewerking van een gegevensbron langzamer is omdat de gegevens moeten worden doorgegeven aan de verbeterde berekeningsengine.
Vraag: Ik zie de wisselknop voor de verbeterde rekenengine niet. Waarom?
Antwoord: De verbeterde berekeningsengine wordt uitgebracht in fasen naar regio's over de hele wereld, maar is nog niet beschikbaar in elke regio.
Vraag: Wat zijn de ondersteunde gegevenstypen voor de berekeningsengine?
Antwoord: De verbeterde berekeningsengine en gegevensstromen ondersteunen momenteel de volgende gegevenstypen. Als uw gegevensstroom geen van de volgende gegevenstypen gebruikt, treedt er een fout op tijdens het vernieuwen:
- Datum/tijd
- Decimaal getal
- Tekst
- Geheel getal
- Datum/tijd/zone
- Waar/onwaar
- Datum
- Tijd
DirectQuery gebruiken met gegevensstromen in Power BI
U kunt DirectQuery gebruiken om rechtstreeks verbinding te maken met gegevensstromen en zo rechtstreeks verbinding te maken met uw gegevensstroom zonder dat u de gegevens hoeft te importeren.
Het gebruik van DirectQuery met gegevensstromen maakt de volgende verbeteringen mogelijk voor uw Power BI- en gegevensstromen:
Vermijd afzonderlijke vernieuwingsschema's : DirectQuery maakt rechtstreeks verbinding met een gegevensstroom, waardoor u geen geïmporteerd semantisch model hoeft te maken. Als zodanig betekent het gebruik van DirectQuery met uw gegevensstromen dat u geen afzonderlijke vernieuwingsschema's meer nodig hebt voor de gegevensstroom en het semantische model om ervoor te zorgen dat uw gegevens worden gesynchroniseerd.
Gegevens filteren: DirectQuery is handig voor het werken aan een gefilterde weergave van gegevens in een gegevensstroom. U kunt DirectQuery gebruiken met de berekeningsengine om gegevensstroomgegevens te filteren en te werken met de gefilterde subset die u nodig hebt. Door gegevens te filteren, kunt u werken met een kleinere en beter beheerbare subset van de gegevens in uw gegevensstroom.
DirectQuery gebruiken voor gegevensstromen
DirectQuery gebruiken met gegevensstromen is beschikbaar in Power BI Desktop.
Er zijn vereisten voor het gebruik van DirectQuery met gegevensstromen:
- Uw gegevensstroom moet zich in een werkruimte met Power BI Premium bevinden.
- De berekeningsengine moet zijn ingeschakeld.
Zie DirectQuery gebruiken met gegevensstromen voor meer informatie over DirectQuery met gegevensstromen.
DirectQuery inschakelen voor gegevensstromen
Om ervoor te zorgen dat uw gegevensstroom beschikbaar is voor DirectQuery-toegang, moet de verbeterde berekeningsengine de geoptimaliseerde status hebben. Als u DirectQuery wilt inschakelen voor gegevensstromen, stelt u de nieuwe optie verbeterde berekeningsengine in op Aan.

Nadat u deze instelling hebt toegepast, vernieuwt u de gegevensstroom zodat de optimalisatie van kracht wordt.
Overwegingen en beperkingen voor DirectQuery
Er zijn enkele bekende beperkingen met DirectQuery en gegevensstromen:
Samengestelde/gemengde modellen met import- en DirectQuery-gegevensbronnen worden momenteel niet ondersteund.
Grote gegevensstromen kunnen problemen hebben met time-outproblemen bij het weergeven van visualisaties. Grote gegevensstromen die problemen ondervinden met time-outproblemen, moeten de importmodus gebruiken.
Onder instellingen voor gegevensbronnen zal de gegevensstroomconnector ongeldige referenties weergeven wanneer u gebruikmaakt van DirectQuery. Deze waarschuwing heeft geen invloed op het gedrag en het semantische model werkt correct.
Wanneer een gegevensstroom 340 kolommen of meer heeft, leidt het gebruik van de gegevensstroomconnector in Power BI Desktop met de instelling voor de verbeterde berekeningsengine ingeschakeld tot het uitschakelen van de DirectQuery-optie voor de gegevensstroom. Als u DirectQuery in dergelijke configuraties wilt gebruiken, gebruikt u minder dan 340 kolommen.
Berekende entiteiten
U kunt berekeningen in de opslag uitvoeren bij het gebruik van gegevensstromen met een Power BI Premium-abonnement. Met deze functie kunt u berekeningen uitvoeren op uw bestaande gegevensstromen en resultaten retourneren waarmee u zich kunt richten op het maken en analyseren van rapporten.
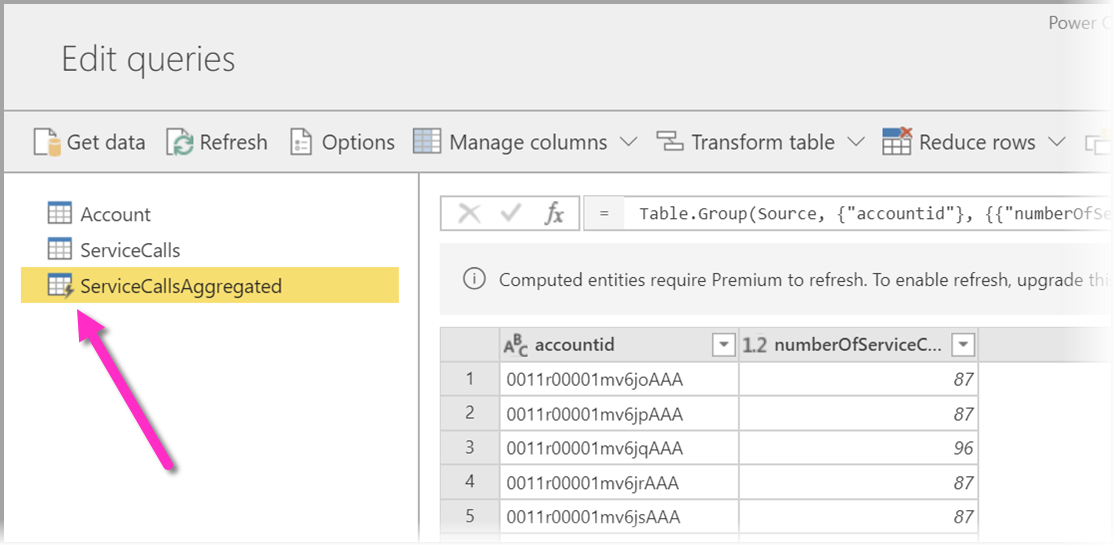
Als u berekeningen in de opslag wilt uitvoeren, moet u eerst de gegevensstroom maken en gegevens in die Power BI-gegevensstroomopslag brengen. Nadat u een gegevensstroom hebt die gegevens bevat, kunt u berekende entiteiten maken. Dit zijn entiteiten die berekeningen in de opslag uitvoeren.
Overwegingen en beperkingen van berekende entiteiten
Wanneer u werkt met gegevensstromen die zijn gemaakt in het Azure Data Lake Storage Gen2-account van een organisatie, werken gekoppelde entiteiten en berekende entiteiten alleen goed wanneer de entiteiten zich in hetzelfde opslagaccount bevinden.
Berekende entiteiten worden alleen ondersteund binnen één werkruimte.
Als best practice kunt u bij het uitvoeren van berekeningen op gegevens die zijn toegevoegd door on-premises en cloudgegevens, een nieuwe gegevensstroom maken voor elke bron (één voor on-premises en één voor de cloud) en vervolgens een derde gegevensstroom maken om deze twee gegevensbronnen samen te voegen/te berekenen.
Gekoppelde entiteiten
U kunt verwijzen naar bestaande gegevensstromen in dezelfde werkruimte met behulp van gekoppelde entiteiten met een Power BI Premium-abonnement. Hiermee kunt u berekeningen uitvoeren op deze entiteiten met behulp van berekende entiteiten of kunt u een tabel met één bron van de waarheid maken die u binnen meerdere gegevensstromen kunt hergebruiken.
Incrementele vernieuwing
Gegevensstromen kunnen stapsgewijs worden vernieuwd om te voorkomen dat alle gegevens bij elke vernieuwing moeten worden opgehaald. Selecteer hiervoor de gegevensstroom en kies vervolgens het pictogram Incrementeel vernieuwen.

Als u incrementeel vernieuwen instelt, worden parameters toegevoegd aan de gegevensstroom om het datumbereik op te geven. ZieIncrementeel vernieuwen gebruiken met gegevensstromen voor gedetailleerde informatie over het instellen van incrementeel vernieuwen.
Overwegingen voor het niet instellen van incrementeel vernieuwen
Stel in de volgende situaties geen gegevensstroom in op incrementeel vernieuwen:
- Gekoppelde entiteiten mogen geen incrementeel vernieuwen gebruiken als ze verwijzen naar een gegevensstroom.
Gerelateerde inhoud
De volgende artikelen bevatten meer informatie over gegevensstromen en Power BI: