Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP:![]() Power BI Desktop-Power BI-service
Power BI Desktop-Power BI-service ![]()
De visual van de belangrijkste beïnvloeders helpt u inzicht te geven in de factoren die een kengetal beïnvloeden dat u interesseert. Het analyseert uw gegevens, rangschikt de factoren die belangrijk zijn en geeft ze weer als belangrijkste beïnvloeders. Stel dat u wilt achterhalen wat invloed heeft op het personeelsverloop, ook bekend als verloop. De ene factor kan de duur van het arbeidscontract zijn en een andere factor kan de reistijd zijn.
Dit artikel biedt een stapsgewijze handleiding over het gebruik van de visualisatie van de belangrijkste beïnvloeders in Power BI. Hierin wordt uitgelegd hoe u de visual instelt, de resultaten interpreteert en veelvoorkomende problemen oplost. Als u wilt weten welke factoren specifieke resultaten in uw gegevens stimuleren, zoals feedback van klanten, verkoop of andere metrische gegevens, kunt u met deze handleiding praktische inzichten verkrijgen met behulp van ai-analysehulpprogramma's van Power BI.
Wanneer belangrijkste beïnvloeders gebruiken
De visual van belangrijke beïnvloeders is een uitstekende keuze als u dit wilt:
- Bekijk welke factoren van invloed zijn op de metrische gegevens die worden geanalyseerd.
- Vergelijk het relatieve belang van deze factoren. Zijn contracten op korte termijn bijvoorbeeld van invloed op het verloop meer dan langetermijncontracten?
Functies van de visualisatie van belangrijkste beïnvloeders
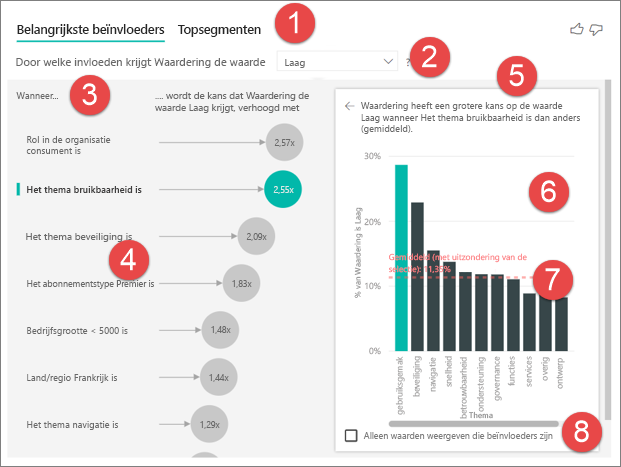
Tabbladen: Selecteer een tabblad en schakel tussen weergaven. Belangrijke beïnvloeders tonen u de belangrijkste inzenders voor de geselecteerde metrische waarde. Topsegmenten tonen u de topsegmenten die bijdragen aan de geselecteerde metrische waarde. Een segment bestaat uit een combinatie van waarden. Een segment kan bijvoorbeeld consumenten zijn die langetermijnklanten zijn en wonen in de regio West.
Vervolgkeuzelijst: De waarde van de metriek die wordt geanalyseerd. In dit voorbeeld bekijkt u de metrische waardering. De geselecteerde waarde is Laag.
Herformulering: Dit helpt u om de visual in het linker paneel te interpreteren.
Linkerdeelvenster: het linkerdeelvenster bevat één visual. In dit geval wordt in het linkerdeelvenster een lijst weergegeven met de belangrijkste beïnvloeders.
Herformulering: Hiermee kunt u de afbeelding in het rechterdeelvenster interpreteren.
Rechterdeelvenster: Het rechterdeelvenster bevat één visual. In dit geval worden in het kolomdiagram alle waarden weergegeven voor het thema van de belangrijkste beïnvloeder die is geselecteerd in het linkerdeelvenster. De specifieke waarde van bruikbaarheid in het linkerdeelvenster wordt groen weergegeven. Alle andere waarden voor Thema worden zwart weergegeven.
Gemiddelde regel: Het gemiddelde wordt berekend voor alle mogelijke waarden voor Thema , behalve bruikbaarheid (de geselecteerde beïnvloeder). De berekening is dus van toepassing op alle waarden in het zwart. Er wordt aangegeven welk percentage van de andere thema's een lage waardering heeft. In dit geval had 11,35% een lage waardering (weergegeven door de stippellijn).
Selectievakje: filtert de visual in het rechterdeelvenster om alleen invloedrijke waarden voor dat veld weer te geven.
Een metrische waarde analyseren die categorisch is
- Uw productmanager wil dat u weet welke factoren ertoe leiden dat klanten negatieve beoordelingen over uw cloudservice achterlaten. Als u mee wilt doen in Power BI Desktop, opent u het PBIX-bestand klantenfeedback.
Notitie
De gegevensset Feedback van klanten is gebaseerd op [Moro et al., 2014] S. Moro, P. Cortez en P. Rita. "Een Data-Driven-benadering om het succes van banktelemarketing te voorspellen." Decision Support Systems, Elsevier, 62:22-31, juni 2014.
Selecteer in het gedeelte Visual bouwen van het deelvenster Visualisaties het pictogram Belangrijkste beïnvloeders.
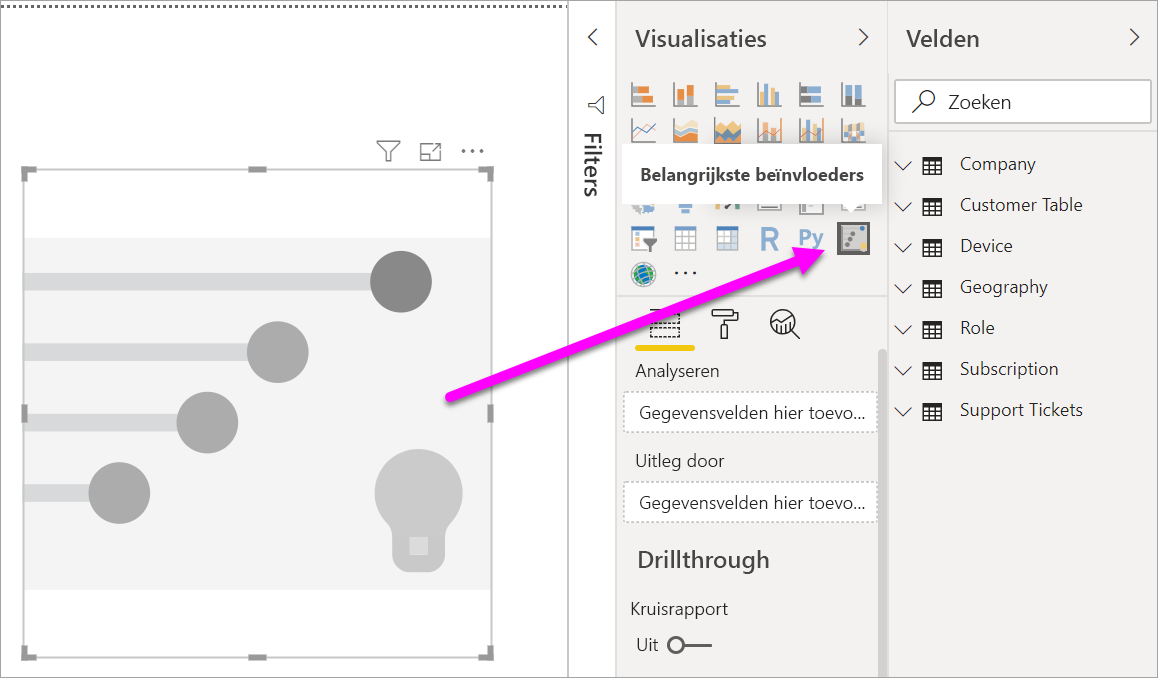
Verplaats de metrische waarde die u wilt onderzoeken naar het veld Analyseren . Als u wilt zien waarom de beoordeling van de service door klanten laag is, selecteert u Klantentabel>Waardering.
Verplaats velden die u denkt, mogelijk invloed hebben op waardering in het veld Uitleg per . U kunt zoveel velden verplaatsen als u wilt. In dit geval begint u met:
- Land/regio
- Rol in organisatie
- Abonnementstype
- Bedrijfsgrootte
- Thema
Laat het veld Uitvouwen leeg. Dit veld wordt alleen gebruikt bij het analyseren van een meting of een samengevat veld.
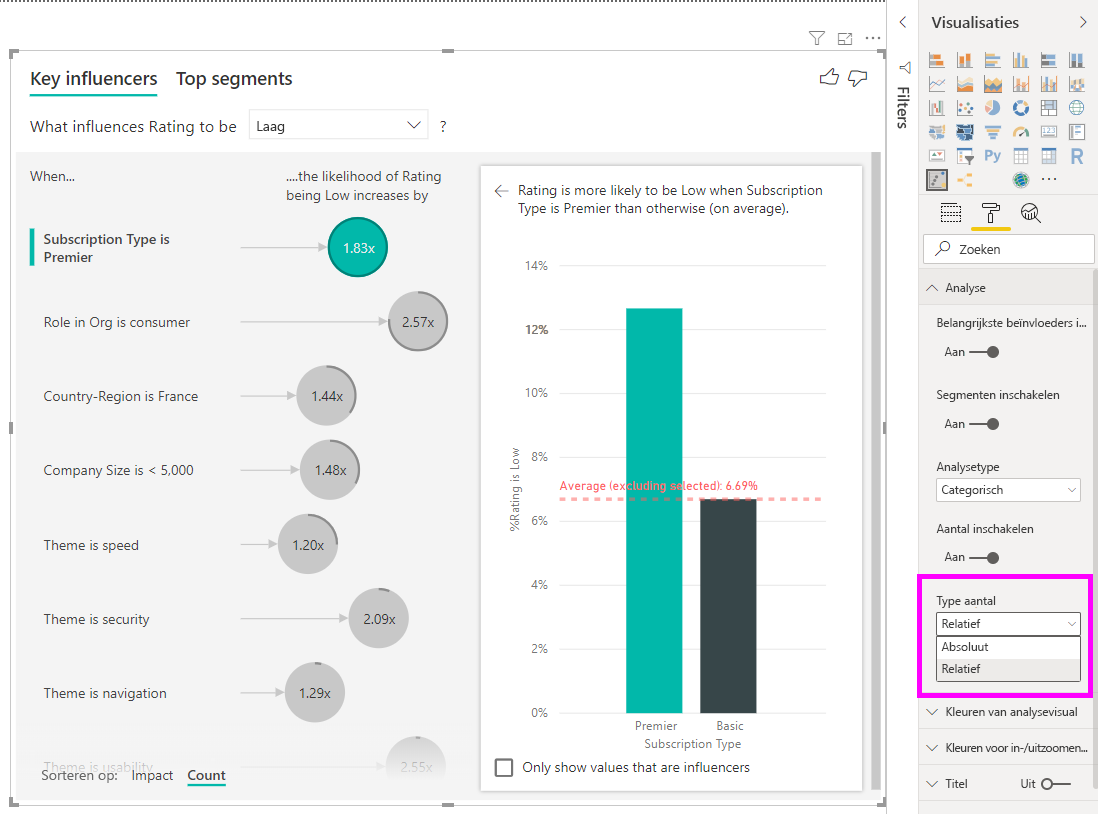
Als u zich wilt richten op de negatieve waarderingen, selecteert u Laag in de vervolgkeuzelijst Wat invloed heeft op waardering.
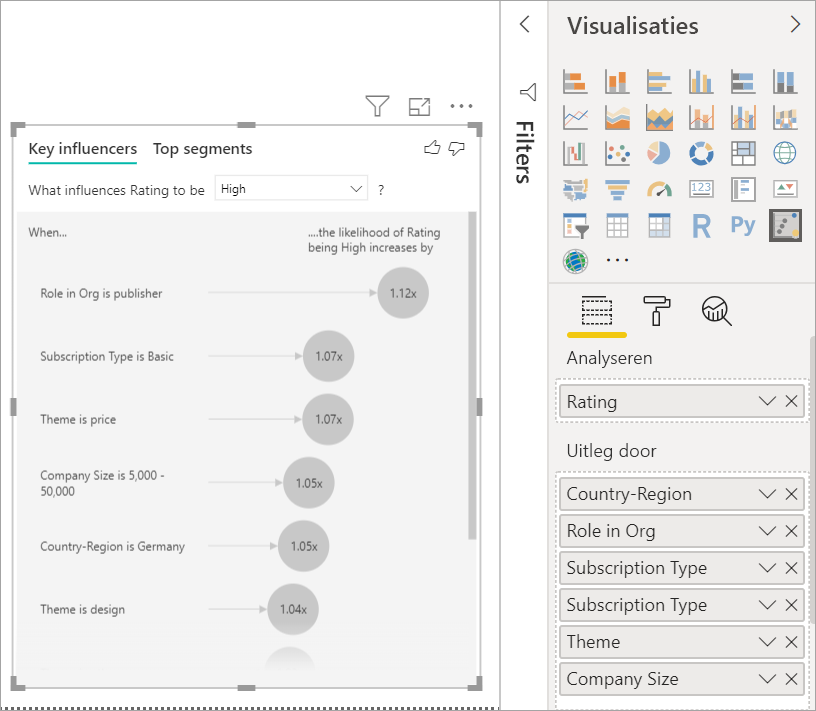
De analyse wordt uitgevoerd op het tabelniveau van het veld dat wordt geanalyseerd. In dit geval is dit de metrische waarde Rating . Deze metrische waarde wordt gedefinieerd op klantniveau. Elke klant geeft een hoge score of een lage score. Alle verklarende factoren moeten worden gedefinieerd op klantniveau, zodat de visual deze kan gebruiken.
In het vorige voorbeeld hebben alle verklarende factoren ofwel een een-op-een- of een veel-op-een-relatie met de metrische waarde. In dit geval heeft elke klant één thema toegewezen aan hun beoordeling. Op dezelfde manier komen klanten uit één land of regio, hebben één lidmaatschapstype en hebben ze één rol in hun organisatie. De verklarende factoren zijn al kenmerken van een klant en er zijn geen transformaties nodig. Het visuele element kan er onmiddellijk gebruik van maken.
Verderop in de zelfstudie bekijkt u complexere voorbeelden met een-op-veel-relaties. In die gevallen moeten de kolommen eerst worden samengevoegd tot het niveau van de klant voordat u de analyse kunt uitvoeren.
Metingen en aggregaties die als verklarende factoren worden gebruikt, worden ook geëvalueerd op tabelniveau van de metrische waarde Analyseren . Verderop in dit artikel worden enkele voorbeelden weergegeven.
Categorische belangrijkste beïnvloeders interpreteren
Laten we eens kijken naar de belangrijkste beïnvloeders voor lage waarderingen.
Belangrijkste enkele factor die de kans op een lage waardering beïnvloedt
De klant in dit voorbeeld kan een van de volgende drie rollen hebben: consument, beheerder of uitgever. Het zijn van een consument is de belangrijkste factor die bijdraagt aan een lage waardering.
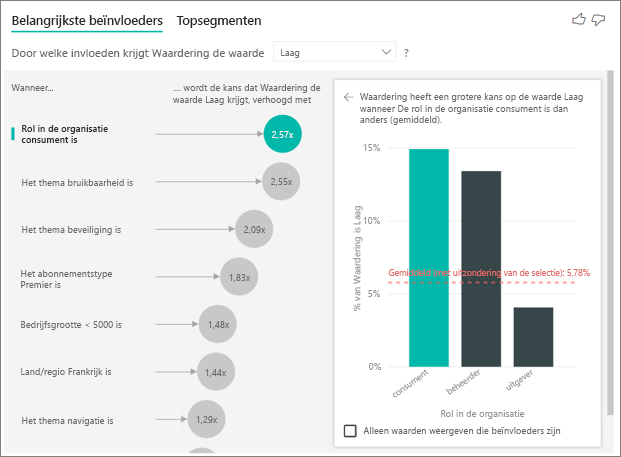
Om precies te zijn, zijn uw consumenten 2,57 keer vaker geneigd om uw service een negatieve score te geven. De grafiek belangrijkste beïnvloeders vermeldt Rol in de organisatie is consument als eerste in de lijst aan de linkerkant. Als u Rol in organisatie is consument selecteert, geeft Power BI meer gedetailleerde informatie weer in het rechterpaneel. Het vergelijkende effect van elke rol op de waarschijnlijkheid van een lage waardering wordt weergegeven.
- 14,93% van de consumenten geeft een lage score.
- Gemiddeld geven alle andere rollen een lage score van 5,78% van de tijd.
- Consumenten hebben 2,57 keer meer kans om een lage score te geven in vergelijking met alle andere rollen. U kunt deze score bepalen door de groene balk te delen door de rode stippellijn.
Tweede enkele factor die de kans op een lage waardering beïnvloedt
De 'Belangrijkste beïnvloeders' visual vergelijkt en rangschikt factoren van verschillende variabelen. De tweede beïnvloeder heeft niets te maken met Role in Org. Selecteer de tweede beïnvloeder in de lijst, namelijk Thema is bruikbaarheid.
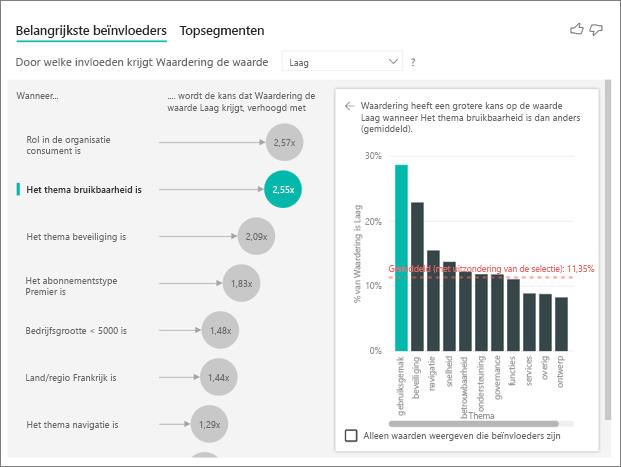
De tweede belangrijkste factor is gerelateerd aan het thema van de beoordeling van de klant. Klanten die commentaar hebben gegeven over de bruikbaarheid van het product, waren 2,55 keer vaker geneigd een lage score te geven in vergelijking met klanten die opmerkingen hadden over andere thema's, zoals betrouwbaarheid, ontwerp of snelheid.
Tussen de visuals is het gemiddelde, dat wordt weergegeven door de rode stippellijn, gewijzigd van 5,78% in 11,35%. Het gemiddelde is dynamisch omdat het is gebaseerd op het gemiddelde van alle andere waarden. Voor de eerste beïnvloeder heeft het gemiddelde de rol van de klant uitgesloten. Voor de tweede beïnvloeder werd het bruikbaarheidsthema uitgesloten.
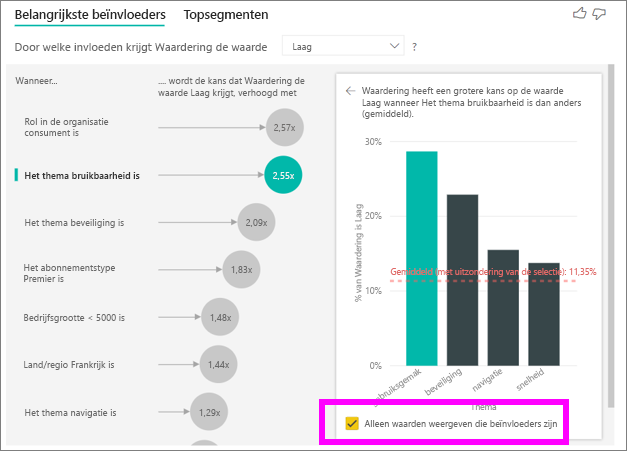
Schakel het selectievakje Alleen waarden weergeven die beïnvloeders zijn in om de gegevens te filteren met alleen de invloedrijke waarden. In dit geval zijn dit de rollen die een lage score aansturen. 12 thema's worden gereduceerd tot de vier thema's die door Power BI zijn geïdentificeerd als de thema's die lage waarderingen stimuleren.
Interactie met andere visuals
Telkens wanneer u een slicer, filter of andere visual op het canvas selecteert, voert de visual voor belangrijkste beïnvloeders de analyse opnieuw uit op het nieuwe gedeelte van de gegevens. U kunt bijvoorbeeld bedrijfsgrootte naar het rapport verplaatsen en als slicer gebruiken. Gebruik deze om te zien of de belangrijkste beïnvloeders voor uw zakelijke klanten afwijken van de algemene populatie. Een bedrijfsgrootte is groter dan 50.000 werknemers.
Selecteer >50.000 om de analyse opnieuw uit te voeren en u kunt zien dat de beïnvloeders zijn gewijzigd. Voor grote zakelijke klanten heeft de belangrijkste beïnvloeder voor lage waarderingen een thema met betrekking tot beveiliging. Mogelijk wilt u verder onderzoeken of er specifieke beveiligingsfuncties zijn waar uw grote klanten ongelukkig over zijn.
Doorlopende belangrijkste beïnvloeders interpreteren
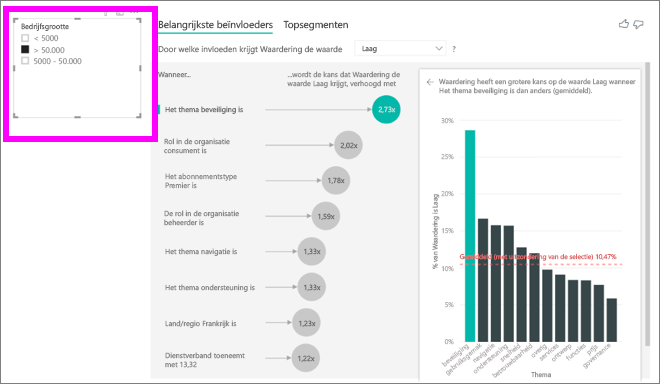
Tot nu toe hebt u geleerd hoe u de visual kunt gebruiken om te verkennen hoe verschillende categorische velden van invloed zijn op lage waarderingen. Het is ook mogelijk om doorlopende factoren te hebben, zoals leeftijd, hoogte en prijs in het veld Uitleg per . Laten we eens kijken wat er gebeurt wanneer Tenure wordt verplaatst van de tabel Klant naar Uitleg door. Tenure geeft weer hoe lang een klant gebruikmaakt van de service.
Naarmate de gebruiksduur toeneemt, neemt de kans op een lagere waardering ook toe. Deze trend geeft aan dat de langere termijn klanten waarschijnlijk een negatieve score zullen geven. Dit inzicht is interessant en een die u mogelijk later wilt opvolgen.
In de visualisatie ziet u dat telkens wanneer de anciënniteit met 13,44 maanden toeneemt, de kans op een lage waardering gemiddeld 1,23 keer groter wordt. In dit geval geven 13,44 maanden de standaarddeviatie van de diensttijd weer. Het inzicht dat u ontvangt, onderzoekt hoe het verhogen van de ambtstermijn met een standaardbedrag, namelijk de standaarddeviatie van de ambtstermijn, invloed heeft op de kans om een lage beoordeling te ontvangen.
In het spreidingsdiagram in het rechterdeelvenster wordt het gemiddelde percentage lage waarderingen voor elke waarde van duur uitgezet. De helling wordt gemarkeerd met een trendlijn.
Onderverdeelde continue sleutelinvloeden
In sommige gevallen kan het zijn dat uw doorlopende factoren automatisch zijn omgezet in categorische factoren. Als de relatie tussen de variabelen niet lineair is, kunnen we de relatie niet als gewoon vergroten of verlagen beschrijven (zoals in het vorige voorbeeld).
We voeren correlatietests uit om te bepalen hoe lineair de beïnvloeder wordt vergeleken met het doel. Als het doel continu is, voeren we Pearson-correlatie uit; als het doel categorisch is, voeren we Point Biserial-correlatietests uit. Als we detecteren dat de relatie niet voldoende lineair is, voeren we binning onder supervisie uit en genereren we maximaal vijf bins. Om erachter te komen welke bins het meest zinvol zijn, gebruiken we een binning-methode onder supervisie. De methode binning onder supervisie kijkt naar de relatie tussen de verklarende factor en het doel dat wordt geanalyseerd.
Metingen en aggregaties interpreteren als belangrijkste beïnvloeders
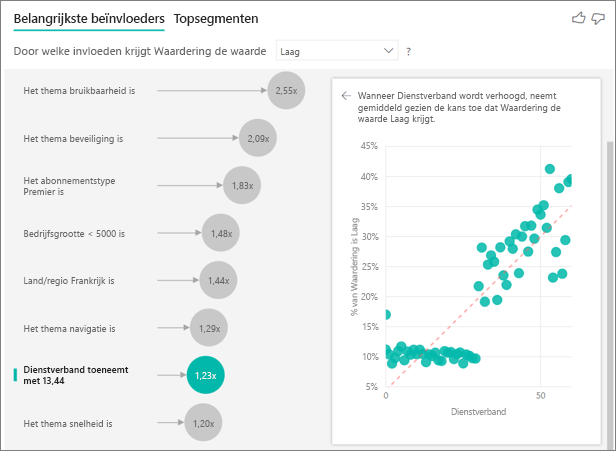
U kunt metingen en aggregaties gebruiken als verklarende factoren in uw analyse. Welk effect heeft bijvoorbeeld het aantal klantondersteuningstickets op de score die u ontvangt. Of welk effect heeft de gemiddelde duur van een open ticket op de score die u ontvangt.
In dit geval wilt u zien of het aantal ondersteuningstickets dat een klant heeft invloed heeft op de score die ze geven. Nu haalt u de ondersteuningsticket-id op uit de tabel Support Tickets. Omdat een klant meerdere ondersteuningstickets kan hebben, aggregeert u de ID op klantniveau. Aggregatie is belangrijk omdat de analyse wordt uitgevoerd op klantniveau, dus alle stuurprogramma's moeten worden gedefinieerd op dat granulariteitsniveau.
Laten we eens kijken naar het aantal id's. Aan elke klantrij is een aantal ondersteuningstickets gekoppeld. Naarmate het aantal ondersteuningstickets toeneemt, neemt de kans dat de waardering laag is 4,08 keer toe. In de schermopname ziet u het gemiddelde aantal ondersteuningstickets op basis van verschillende waarderingswaarden die op klantniveau worden geëvalueerd.
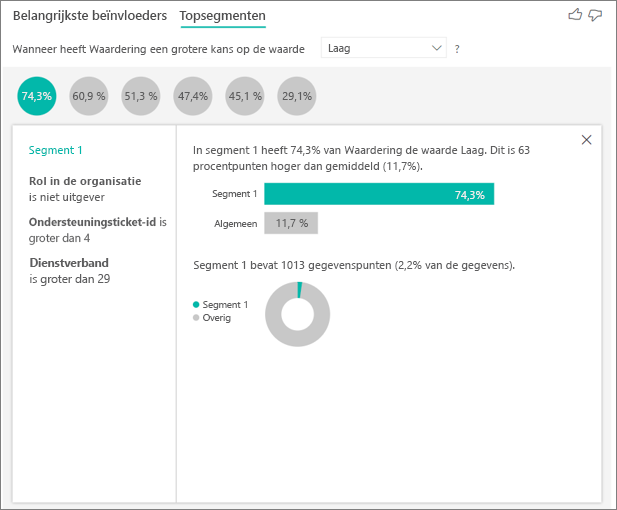
De resultaten interpreteren: Topsegmenten
U kunt het tabblad Belangrijkste beïnvloeders gebruiken om elke factor afzonderlijk te beoordelen. U kunt ook het tabblad Topsegmenten gebruiken om te zien hoe een combinatie van factoren van invloed is op de metrische gegevens die u analyseert.
Topsegmenten geven in eerste instantie een overzicht weer van alle segmenten die door Power BI zijn gedetecteerd. In het volgende voorbeeld ziet u dat er zes segmenten zijn gevonden. Het percentage lage waarderingen binnen het segment bepaalt de rangorde. Segment 1 heeft bijvoorbeeld 74,3% klantbeoordelingen die laag zijn. Hoe hoger de bubbel, hoe hoger het aandeel lage waarderingen. De grootte van de bubbel geeft weer hoeveel klanten zich in het segment bevinden.
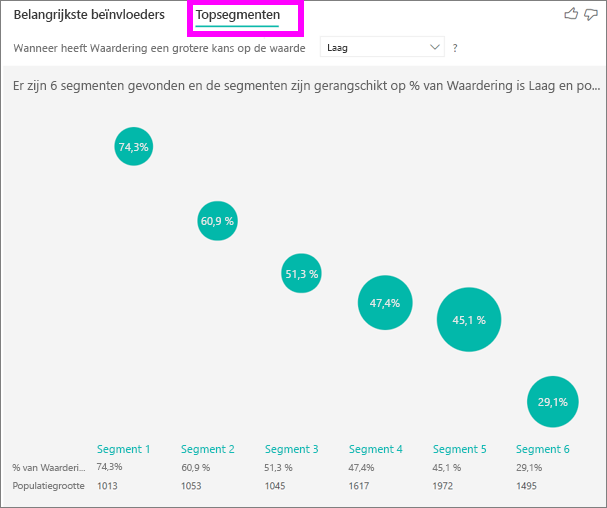
Wanneer u een bubbel selecteert, worden de details van dat segment weergegeven. Als u bijvoorbeeld Segment 1 selecteert, ziet u dat het gevestigde klanten vertegenwoordigt. Ze zijn al meer dan 29 maanden klanten en hebben meer dan vier ondersteuningstickets. Ten slotte zijn ze geen uitgevers, dus ze zijn consumenten of beheerders.
In deze groep gaf 74,3% van de klanten een lage waardering. De gemiddelde klant gaf een lage waardering van 11,7% van de tijd, dus dit segment heeft een groter aandeel lage waarderingen. Het is 63 procent hoger. Segment 1 bevat ook ongeveer 2,2% van de gegevens, dus het vertegenwoordigt een adresseerbaar deel van de populatie.
Aantallen toevoegen
Soms kan een beïnvloeder een aanzienlijk effect hebben, maar weinig van de gegevens vertegenwoordigen. Bijvoorbeeld, Thema is bruikbaarheid, dat is de derde grootste beïnvloeder voor lage waarderingen. Er is echter mogelijk slechts een handvol klanten geweest die klaagden over bruikbaarheid. Aantallen kunnen u helpen prioriteit te geven aan de beïnvloeders waarop u zich wilt richten.
U kunt tellingen inschakelen via de analysekaart van het deelvenster Visuele opmaak.
Nadat tellingen zijn ingeschakeld, ziet u een ring om de cirkel van elke beïnvloeder, die het geschatte percentage gegevens vertegenwoordigt dat de beïnvloeder bevat. Hoe meer van de bel de ring omsluit, hoe meer gegevens ze bevat. We kunnen zien dat themabruikbaarheid slechts een klein deel van de gegevens beslaat.
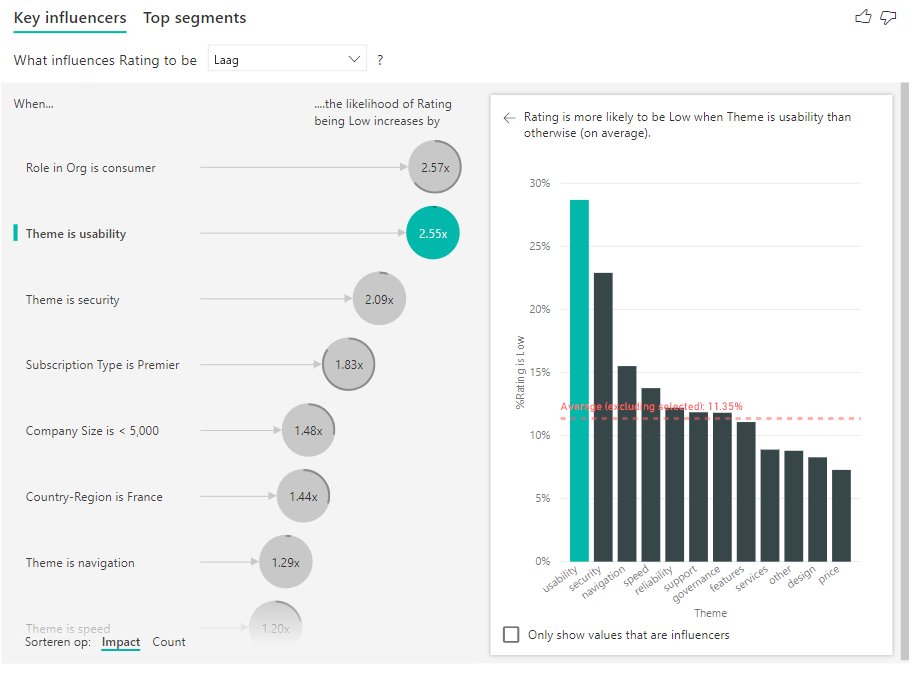
U kunt ook de schuifknop Sorteren op in de linkerbenedenhoek van de visual gebruiken om de bellen eerst op aantal in plaats van impact te sorteren. Abonnementstype is Premier is de belangrijkste beïnvloeder op basis van het aantal.
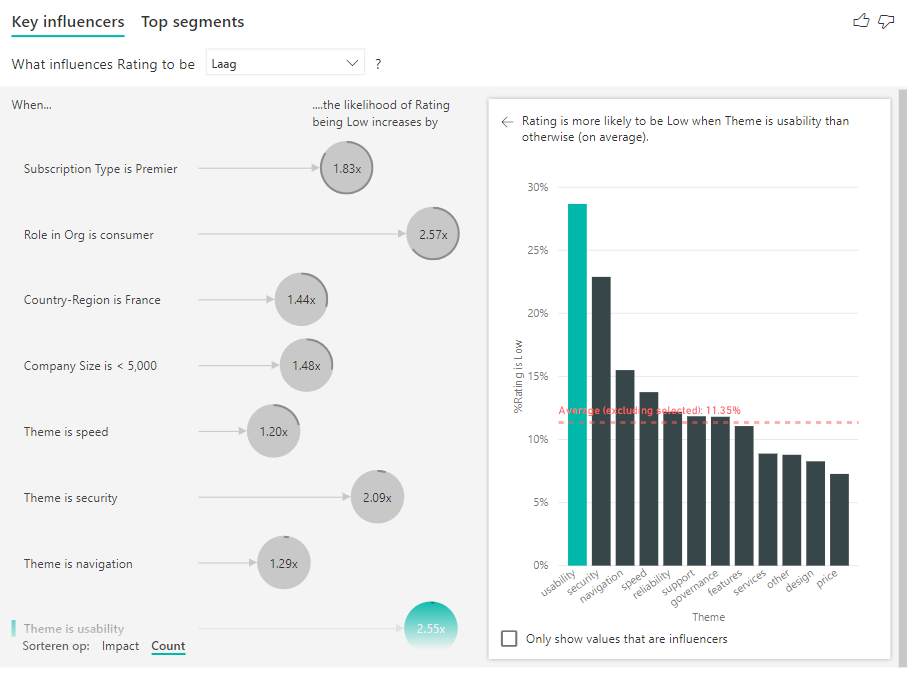
Een volledige ring rond de cirkel betekent dat de beïnvloeder 100% van de gegevens bevat. U kunt het aantaltype wijzigen in verhouding tot de maximale beïnvloeder met behulp van de vervolgkeuzelijst Aantaltype op de analysekaart van het deelvenster Visuele opmaak. De beïnvloeder met de meeste hoeveelheid gegevens wordt nu weergegeven door een volledige ring en alle andere aantallen zijn relatief.
Een metrische waarde analyseren die numeriek is
Als u een niet-samengevat numeriek veld naar het veld Analyseren verplaatst, kunt u kiezen hoe u dat scenario kunt afhandelen. U kunt het gedrag van de visual wijzigen door naar het deelvenster Visual Opmaken te gaan en te schakelen tussen categorisch analysetype en doorlopend analysetype.
Een categorisch analysetype wordt eerder in dit artikel beschreven. Als u bijvoorbeeld enquêtescores bekijkt, variërend van 1 tot 10, kunt u vragen 'Welke invloed heeft de enquêtescores op 1?'
Een continu analyse type verandert de vraag in een doorlopende vraag. In het vorige voorbeeld is onze nieuwe vraag 'Wat beïnvloedt enquête-scores om te stijgen of te dalen?'
Dit onderscheid is handig wanneer u veel unieke waarden in het veld hebt dat u analyseert. In het volgende voorbeeld kijken we naar huizenprijzen. Het is niet zinvol om te vragen "Welke invloed heeft de huizenprijs op 156.214?" omdat dat specifiek is en we waarschijnlijk niet voldoende gegevens hebben om een patroon af te leiden.
In plaats daarvan willen we misschien vragen: "Wat beïnvloedt huizenprijs om te verhogen", waardoor we huizenprijzen kunnen behandelen als een bereik in plaats van afzonderlijke waarden.
De resultaten interpreteren: Belangrijkste beïnvloeders
Notitie
In de voorbeelden in deze sectie worden gegevens over huizenprijzen uit het publieke domein gebruikt. U kunt de voorbeeldgegevensset downloaden als u mee wilt doen.
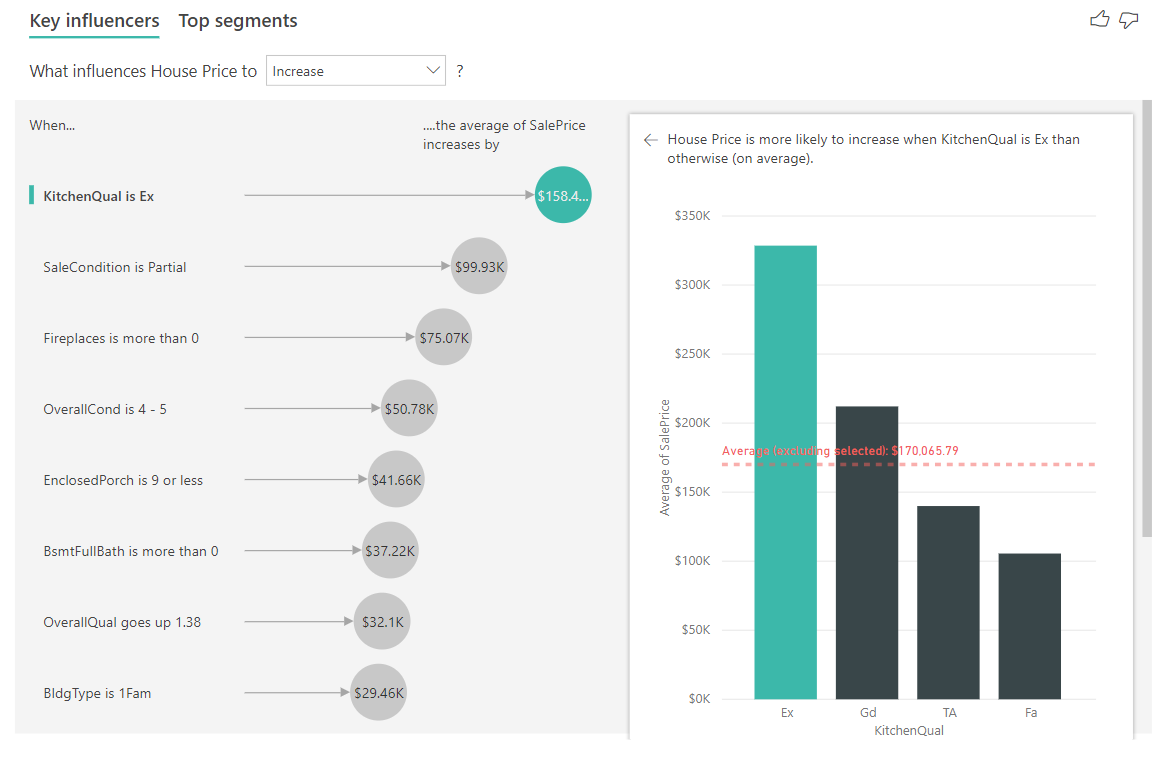
In dit scenario kijken we naar 'Wat is van invloed op de huizenprijs om te verhogen'. Een aantal verklarende factoren kan van invloed zijn op een woningprijs, zoals Year Built (jaar dat het huis is gebouwd), KitchenQual (keukenkwaliteit) en YearRemodAdd (jaar dat het huis is gerenoveerd).
In het onderstaande voorbeeld kijken we naar onze belangrijkste factor, waarbij de keukenkwaliteit Uitstekend is. De resultaten zijn vergelijkbaar met de resultaten die we zagen toen we categorische metrische gegevens analyseerden met enkele belangrijke verschillen:
- Het kolomdiagram aan de rechterkant bekijkt de gemiddelden in plaats van percentages. Het laat ons daarom zien wat de gemiddelde woningprijs van een huis met een uitstekende keuken is (groene bar) vergeleken met de gemiddelde woningprijs van een huis zonder een uitstekende keuken (stippellijn).
- Het getal in de bel is nog steeds het verschil tussen de rode stippellijn en de groene balk, maar wordt uitgedrukt als een getal (\$158,49K) in plaats van een waarschijnlijkheid (1,93x). Dus gemiddeld zijn huizen met uitstekende keukens bijna \$ 160K duurder dan huizen zonder uitstekende keukens.
In het volgende voorbeeld kijken we naar de impact die een doorlopende factor (jaar huis is hermodelleerd) heeft op de huizenprijs. De verschillen ten opzichte van hoe we continue beïnvloeders analyseren voor categorische metrische gegevens zijn als volgt:
- In het spreidingsdiagram in het rechterdeelvenster wordt de gemiddelde huizenprijs uitgezet voor elke afzonderlijke waarde van het renovatiejaar.
- De waarde in de luchtbel laat zien hoeveel de gemiddelde huizenprijs toeneemt (in dit geval $2.87K) wanneer het jaar dat het huis werd gerenoveerd met zijn standaarddeviatie toeneemt (in dit geval 20 jaar).
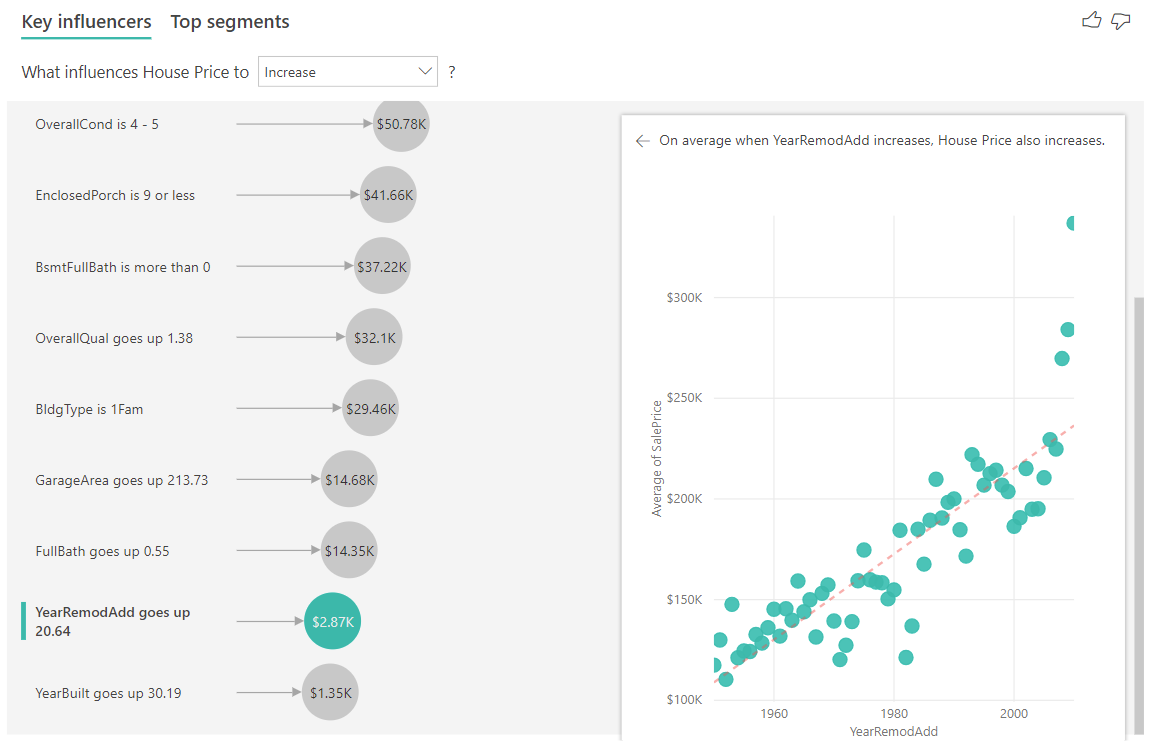
Ten slotte kijken we in het geval van metingen naar het gemiddelde jaar dat er een huis is gebouwd. De analyse is als volgt:
- In het spreidingsdiagram in het rechterdeelvenster wordt de gemiddelde huizenprijs voor elke afzonderlijke waarde in de tabel uitgezet.
- De waarde in de bel laat zien hoeveel de gemiddelde huizenprijs toeneemt (in dit geval \$1,35K) wanneer het gemiddelde jaar toeneemt met de standaarddeviatie (in dit geval 30 jaar).
De resultaten interpreteren met topsegmenten
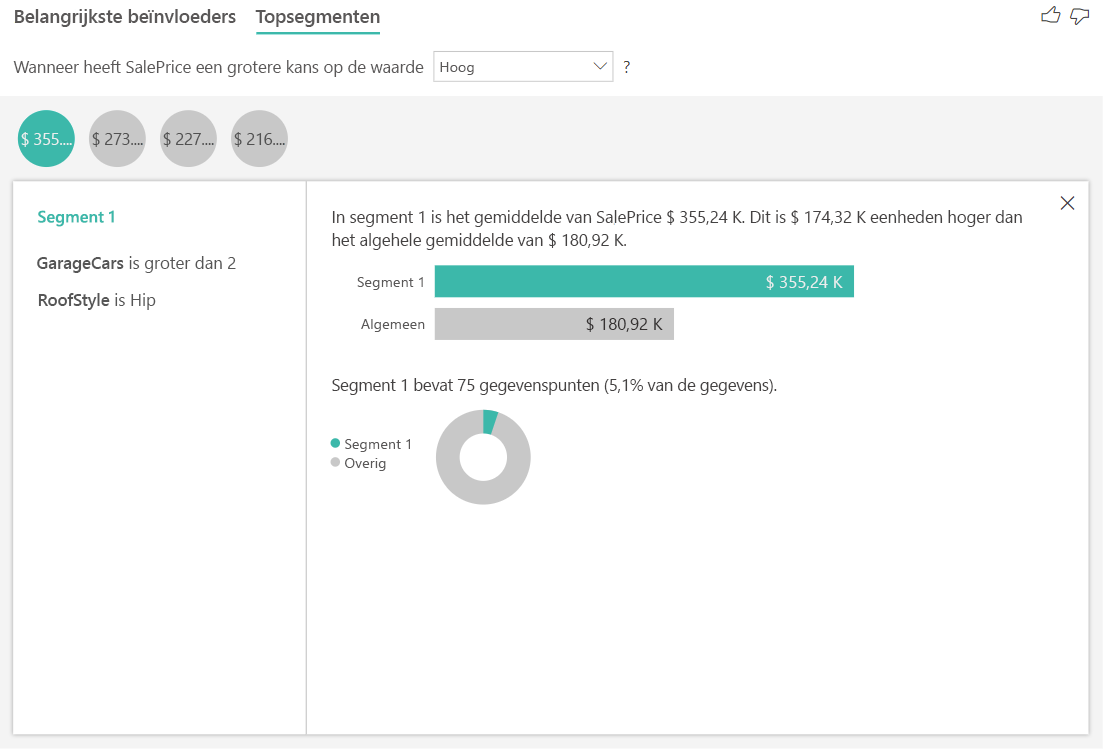
Topsegmenten voor numerieke doelen tonen groepen waar de huizenprijzen gemiddeld hoger zijn dan in de algemene gegevensset. Hieronder ziet u bijvoorbeeld dat Segment 1 bestaat uit huizen waarin GarageCars (aantal auto's dat de garage kan passen) groter is dan 2 en de RoofStyle Hip is. Huizen met deze kenmerken hebben een gemiddelde prijs van \$ 355K vergeleken met het totale gemiddelde in de gegevens die \$ 180K zijn.
Een metrische waarde analyseren die een meting of een samengevatte kolom is
Voor een meting of samengevatte kolom wordt de analyse standaard ingesteld op het type continue analyse dat eerder in dit artikel is beschreven. Deze waarde kan niet worden gewijzigd. Het grootste verschil tussen het analyseren van een meting/samengevatte kolom en een niet-samengevatte numerieke kolom is het niveau waarop de analyse wordt uitgevoerd.
Voor niet-samengevatte kolommen wordt de analyse altijd uitgevoerd op tabelniveau. In het voorbeeld van de woningprijs hebben we de metrische woningprijs geanalyseerd om te zien wat invloed heeft op een woningprijs om te stijgen/dalen. De analyse wordt automatisch uitgevoerd op tabelniveau. Onze tabel heeft een unieke id voor elk huis, zodat de analyse op huisniveau wordt uitgevoerd.
Voor metingen en samengevatte kolommen weten we niet meteen op welk niveau ze moeten worden geanalyseerd. Als de woningprijs als gemiddelde is samengevat, moeten we overwegen welk niveau we zouden willen berekenen voor deze gemiddelde woningprijs. Is het de gemiddelde woningprijs op wijkniveau? Of misschien een regionaal niveau?
Metingen en samengevatte kolommen worden automatisch geanalyseerd op het niveau van de uitleg door velden die worden gebruikt. Stel dat we drie velden willen onderzoeken in Uitleg door: Keukenkwaliteit, Bouwtype en Airconditioning. Het gemiddelde van de woningprijs wordt berekend voor elke unieke combinatie van deze drie velden. Het is vaak handig om over te schakelen naar een tabelweergave om te zien hoe de gegevens eruitzien die worden geëvalueerd.
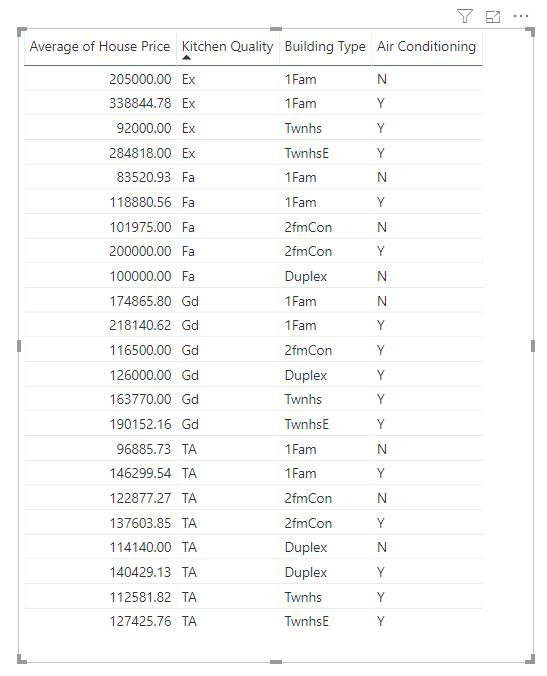
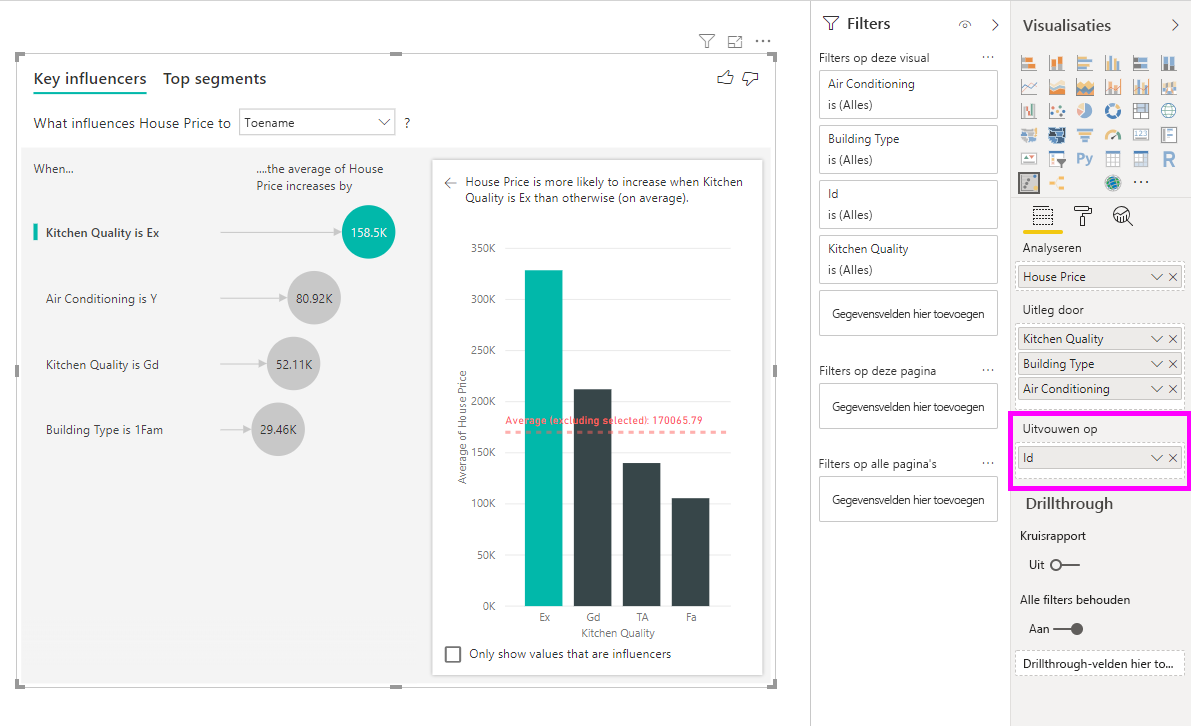
Deze analyse wordt sterk samengevat, dus het kan lastig zijn voor het regressiemodel om patronen te vinden in de gegevens waaruit ze kunnen leren. We moeten de analyse op een gedetailleerder niveau uitvoeren om betere resultaten te krijgen. Als we de woningprijs op huisniveau willen analyseren, moeten we het id-veld expliciet toevoegen aan de analyse. Toch willen we niet dat de huis-id als beïnvloeder wordt beschouwd. Het is niet behulpzaam om te leren dat als de huisidentificatie toeneemt, de prijs van een huis stijgt. De veldaanvuloptie Uitvouwen op komt hier goed van pas. U kunt Uitbreiden gebruiken door velden toe te voegen die u wilt gebruiken voor het instellen van het niveau van de analyse zonder dat u op zoek bent naar nieuwe beïnvloeders.
Bekijk hoe de visualisatie eruitziet zodra we ID toevoegen bij Uitbreiden. Zodra u het niveau definieert waarop de meting moet worden geëvalueerd, is het interpreteren van beïnvloeders precies hetzelfde als voor niet-samengevatte numerieke kolommen.
Als u wilt weten hoe Power BI ML.NET achter de schermen gebruikt om gegevens te analyseren en inzichten op een natuurlijke manier naar voren te brengen, zie Power BI identificeert belangrijkste beïnvloeders met behulp van ML.NET.
Overwegingen en probleemoplossing
Wat zijn de beperkingen voor de visual?
De visual van belangrijkste beïnvloeders heeft enkele beperkingen:
- Direct Query wordt niet ondersteund.
- Liveverbinding met Azure Analysis Services en SQL Server Analysis Services wordt niet ondersteund.
- Publiceren op internet wordt niet ondersteund.
- .NET Framework 4.6 of hoger is vereist.
- Insluiten van SharePoint Online wordt niet ondersteund.
- Een categorische metriek analyseren wordt niet ondersteund als Impliciete metingen ontmoedigen is ingesteld op true voor het gegevensmodel (bijvoorbeeld wanneer berekeningsgroepen in het gegevensmodel zijn gedefinieerd).
Ik zie een fout dat er geen beïnvloeders of segmenten zijn gevonden. Waarom is dat?
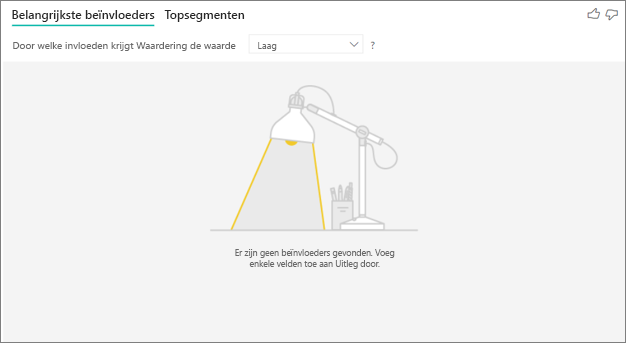
Deze fout treedt op wanneer u velden in Uitleg door hebt opgenomen, maar er geen beïnvloeders zijn gevonden. Controleer of een van de volgende problemen van toepassing kan zijn.
- U hebt de metrische gegevens opgenomen die u analyseerde in zowel Analyseren als Uitleggen door. Verwijder het uit Explain by.
- Uw verklarende velden hebben te veel categorieën met weinig waarnemingen. Deze situatie maakt het moeilijk voor de visualisatie om te bepalen welke factoren beïnvloeders zijn. Het is moeilijk om te generaliseren op basis van slechts een paar waarnemingen. Als u een numeriek veld analyseert, wilt u mogelijk overschakelen van categorische analyse naar continue analyse in het deelvenster Visuele opmaak op de analysekaart.
- Uw verklarende factoren hebben voldoende waarnemingen om te generaliseren, maar de visualisatie heeft geen zinvolle correlaties gevonden om te rapporteren.
Ik zie een fout dat de data voor de metric die ik analyseer onvoldoende is om de analyse uit te voeren. Waarom is dat?
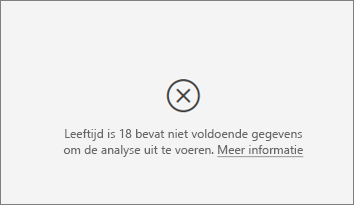
De visualisatie werkt door patronen in de gegevens voor de ene groep te bekijken in vergelijking met andere groepen. Het zoekt bijvoorbeeld naar klanten die lage waarderingen hebben gegeven in vergelijking met klanten die hoge waarderingen hebben gegeven. Als de gegevens in uw model slechts enkele waarnemingen bevatten, zijn patronen moeilijk te vinden. Als de visualisatie onvoldoende gegevens heeft om zinvolle beïnvloeders te vinden, geeft deze aan dat er meer gegevens nodig zijn om de analyse uit te voeren.
U wordt aangeraden ten minste 100 waarnemingen voor de geselecteerde status te hebben. In dit geval is de status klanten die zijn afgehaakt. U hebt ook ten minste 10 waarnemingen nodig voor de statussen die u voor vergelijking gebruikt. In dit geval is de vergelijkingsstatus klanten die geen verloop hebben.
Als u een numeriek veld analyseert, wilt u mogelijk overschakelen van categorische analyse naar continue analyse in het deelvenster voor visualisatieopmaak op de Analyse-kaart.
Ik zie een fout waarbij, wanneer 'Analyseren' niet wordt samengevat, de analyse altijd op het rijniveau van de bovenliggende tabel wordt uitgevoerd. Het wijzigen van dit niveau via 'Uitvouwen op' velden is niet toegestaan. Waarom is dat?
Bij het analyseren van een numerieke of categorische kolom wordt de analyse altijd uitgevoerd op tabelniveau. Als u bijvoorbeeld huizenprijzen analyseert en uw tabel een id-kolom bevat, wordt de analyse automatisch uitgevoerd op huis-id-niveau.
Wanneer u een meting of samengevatte kolom analyseert, moet u expliciet aangeven op welk niveau de analyse moet worden uitgevoerd. U kunt Uitbreiden gebruiken om het niveau van de analyse voor metingen en samengevatte kolommen te wijzigen zonder nieuwe beïnvloeders toe te voegen. Als de woningprijs is gedefinieerd als een meting, kunt u de kolom huis-id toevoegen aan Uitbreiden door het niveau van de analyse te wijzigen.
Ik zie een fout dat een veld in Uitleg door niet uniek is gerelateerd aan de tabel die de metrische waarde bevat die ik analyseer. Waarom is dat?
De analyse wordt uitgevoerd op het tabelniveau van het veld dat wordt geanalyseerd. Als u bijvoorbeeld feedback van klanten voor uw service analyseert, hebt u mogelijk een tabel die aangeeft of een klant een hoge waardering of een lage waardering heeft gegeven. In dit geval wordt uw analyse uitgevoerd op het niveau van de klanttabel.
Als u een gerelateerde tabel hebt gedefinieerd op een gedetailleerder niveau dan de tabel die uw metrische gegevens bevat, ziet u deze fout. Hier volgt een voorbeeld:
- U analyseert wat klanten ertoe aanstuurt om een lage waardering van uw service te geven.
- U wilt zien of het apparaat waarop de klant uw service gebruikt invloed heeft op de beoordelingen die ze geven.
- Een klant kan de service op verschillende manieren gebruiken.
- In het volgende voorbeeld gebruikt klant 10000000 zowel een browser als een tablet om met de service te communiceren.
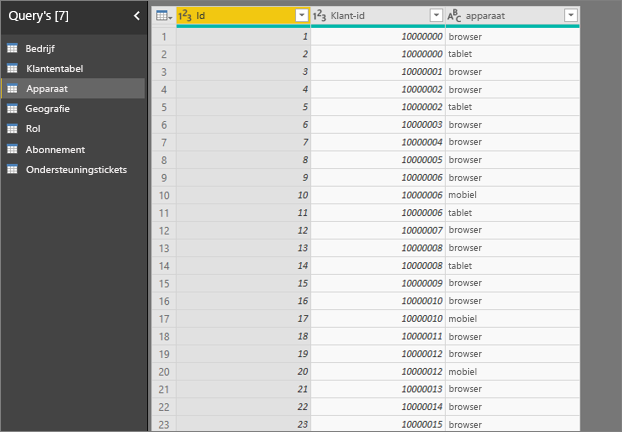
Als u de apparaatkolom als verklarende factor probeert te gebruiken, ziet u de volgende fout:

Deze fout wordt weergegeven omdat het apparaat niet is gedefinieerd op klantniveau. Eén klant kan de service op meerdere apparaten gebruiken. Om voor de visualisatie patronen te kunnen vinden, moet het apparaat een kenmerk van de klant zijn. Er zijn verschillende oplossingen die afhankelijk zijn van uw kennis van het bedrijf:
- U kunt de samenvatting van apparaten wijzigen om te tellen. Gebruik bijvoorbeeld aantal als het aantal apparaten van invloed kan zijn op de score die een klant geeft.
- U kunt de kolom van het apparaat draaien om te zien of het verbruik van de service op een specifiek apparaat invloed heeft op de waardering van een klant.
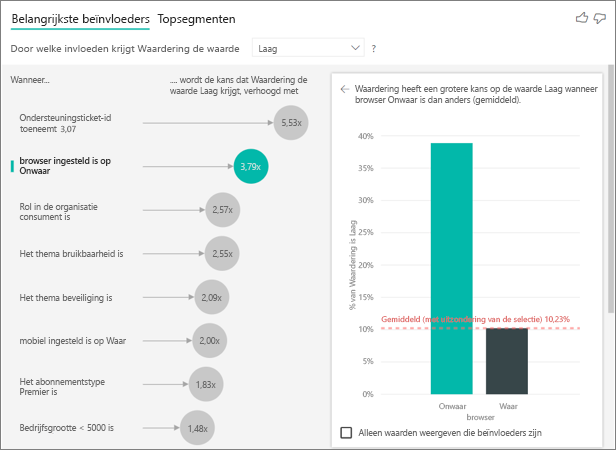
In dit voorbeeld zijn de gegevens gedraaid om nieuwe kolommen te maken voor browser, mobiel en tablet (zorg ervoor dat u uw relaties in de modelweergave verwijdert en opnieuw maakt nadat u uw gegevens hebt gedraaid). U kunt deze specifieke apparaten nu gebruiken in Explain by. Alle apparaten blijken beïnvloeders te zijn en de browser heeft het grootste effect op de klantscore.
Klanten die de browser niet gebruiken om de service te gebruiken, zijn 3,79 keer vaker geneigd een lage score te geven dan de klanten die dat doen. Lager in de lijst is de inverse waar voor mobiele apparaten. Klanten die de mobiele app gebruiken, geven waarschijnlijk een lage score dan de klanten die dat niet doen.
Ik zie een waarschuwing dat metingen niet zijn opgenomen in mijn analyse. Waarom is dat?
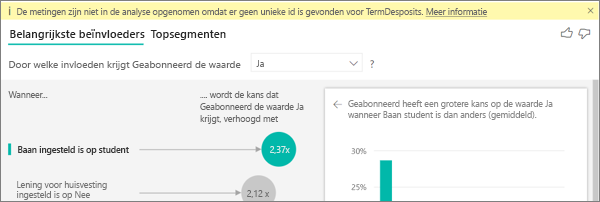
De analyse wordt uitgevoerd op het tabelniveau van het veld dat wordt geanalyseerd. Als u klantverloop analyseert, hebt u mogelijk een tabel die aangeeft of een klant heeft opgezegd of niet. In dit geval wordt uw analyse uitgevoerd op het niveau van de klanttabel.
Standaard worden metingen en aggregaties standaard geanalyseerd op tabelniveau. Als er een meting is voor de gemiddelde maandelijkse uitgaven, wordt deze geanalyseerd op het niveau van de klanttabel.
Als de klanttabel geen unieke id heeft, kunt u de meting niet evalueren en wordt deze genegeerd door de analyse. Om deze situatie te voorkomen, moet u ervoor zorgen dat de tabel met uw metrische gegevens een unieke id heeft. In dit geval is het de klanttabel en de unieke identificatie is klant-id. Het is ook eenvoudig om een indexkolom toe te voegen met behulp van Power Query.
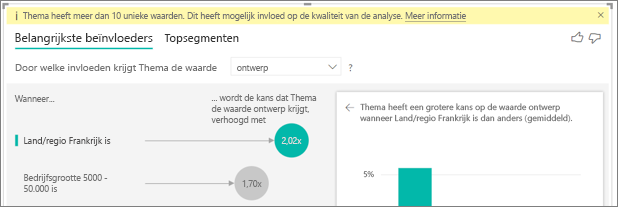
Ik zie een waarschuwing dat de metrische waarde die ik analyseer meer dan 10 unieke waarden heeft en dat dit bedrag van invloed kan zijn op de kwaliteit van mijn analyse. Waarom is dat?
De AI-visualisatie kan categorische velden en numerieke velden analyseren. Voor categorische velden is het verloop bijvoorbeeld Ja of Nee, en Klanttevredenheid is Hoog, Gemiddeld of Laag. Als u het aantal te analyseren categorieën verhoogt, betekent dit dat er minder waarnemingen per categorie zijn. Deze situatie maakt het moeilijker voor de visualisatie om patronen in de gegevens te vinden.
Bij het analyseren van numerieke velden hebt u de mogelijkheid om de numerieke velden zoals tekst te behandelen. In dat geval voert u dezelfde analyse uit als voor categorische gegevens (Categorische analyse). Als u veel afzonderlijke waarden hebt, raden we u aan om de analyse over te schakelen naar Continue analyse. Dit betekent dat we patronen kunnen afleiden van wanneer getallen toenemen of afnemen in plaats van ze als afzonderlijke waarden te behandelen. U kunt overschakelen van Categorische analyse naar Doorlopende analyse in het deelvenster Visuele opmaak op de kaart Analyse .
Als u sterkere beïnvloeders wilt vinden, raden we u aan vergelijkbare waarden in één eenheid te groeperen. Als u bijvoorbeeld een metrische waarde voor prijs hebt, krijgt u waarschijnlijk betere resultaten door vergelijkbare prijzen te groeperen in categorieën Hoog, Gemiddeld en Laag versus het gebruik van afzonderlijke prijspunten.
Er zijn factoren in mijn gegevens die eruitzien alsof ze belangrijke beïnvloeders moeten zijn, maar dat zijn ze niet. Hoe kan dat gebeuren?
In het volgende voorbeeld zorgen klanten die consumenten zijn voor lage waarderingen, met 14,93% van de waarderingen als laag. De beheerdersrol heeft ook een groot aandeel lage waarderingen op 13,42%, maar wordt niet beschouwd als een beïnvloeder.
De reden voor deze bepaling is dat de visualisatie ook rekening houdt met het aantal gegevenspunten wanneer er beïnvloeders worden gevonden. Het volgende voorbeeld heeft meer dan 29.000 consumenten en 10 keer minder beheerders, ongeveer 2900. Slechts 390 van hen gaven een lage waardering. De visualisatie heeft niet genoeg gegevens om te bepalen of er een patroon is gevonden met beheerdersbeoordelingen of dat het slechts om een toevallige vondst gaat.

Wat zijn de limieten voor gegevenspunten voor belangrijke beïnvloeders?
We voeren de analyse uit op een steekproef van 10.000 gegevenspunten. De bubbels aan de ene kant tonen alle influencers die zijn gevonden. De kolomdiagrammen en spreidingsdiagrammen aan de andere zijde houden zich aan de samplingstrategieën voor die kernvisuals.
Hoe berekent u de belangrijkste beïnvloeders voor categorische analyse?
Achter de schermen gebruikt de AI-visualisatie ML.NET om een logistieke regressie uit te voeren om de belangrijkste beïnvloeders te berekenen. Een logistieke regressie is een statistisch model dat verschillende groepen met elkaar vergelijkt.
Als u wilt zien wat lage waarderingen aanstuurt, kijkt de logistieke regressie naar hoe klanten die een lage score gaven verschillen van de klanten die een hoge score gaven. Als u meerdere categorieën hebt, zoals hoge, neutrale en lage scores, bekijkt u hoe de klanten die een lage waardering gaven verschillen van de klanten die geen lage waardering gaven. In dit geval verschillen de klanten die een lage score gaven van de klanten die een hoge waardering of een neutrale waardering gaven?
De logistieke regressie zoekt naar patronen in de gegevens en zoekt naar hoe klanten die een lage waardering hebben gegeven, kunnen verschillen van de klanten die een hoge waardering hebben gegeven. Het kan bijvoorbeeld zijn dat klanten met meer ondersteuningstickets een hoger percentage lage waarderingen geven dan klanten met weinig of geen ondersteuningstickets.
De logistieke regressie houdt ook rekening met het aantal gegevenspunten. Als klanten die een beheerdersrol spelen bijvoorbeeld proportioneel negatievere scores geven, maar er slechts een paar beheerders zijn, wordt deze factor niet als invloedrijk beschouwd. Deze bepaling wordt gemaakt omdat er onvoldoende gegevenspunten beschikbaar zijn om een patroon af te leiden. Een statistische test, ook wel een Wald-test genoemd, wordt gebruikt om te bepalen of een factor wordt beschouwd als een beïnvloeder. De visual gebruikt een p-waarde van 0,05 om de drempelwaarde te bepalen.
Hoe berekent u belangrijke beïnvloeders voor numerieke analyse?
Achter de schermen gebruikt de AI-visualisatie ML.NET om een lineaire regressie uit te voeren om de belangrijkste beïnvloeders te berekenen. Een lineaire regressie is een statistisch model dat bekijkt hoe de uitkomst van het veld dat u onderzoekt verandert op basis van uw verklarende factoren.
Als we bijvoorbeeld huizenprijzen analyseren, kijkt een lineaire regressie naar het effect dat een uitstekende keuken heeft op de woningprijs. Hebben huizen met uitstekende keukens over het algemeen lagere of hogere huizenprijzen in vergelijking met huizen zonder uitstekende keukens?
De lineaire regressie houdt ook rekening met het aantal gegevenspunten. Als huizen met tennisbanen bijvoorbeeld hogere prijzen hebben, maar we weinig huizen hebben met een tennisbaan, wordt deze factor niet beschouwd als invloedrijk. Deze bepaling wordt gemaakt omdat er onvoldoende gegevenspunten beschikbaar zijn om een patroon af te leiden. Een statistische test, ook wel een Wald-test genoemd, wordt gebruikt om te bepalen of een factor wordt beschouwd als een beïnvloeder. De visual gebruikt een p-waarde van 0,05 om de drempelwaarde te bepalen.
Hoe berekent u segmenten?
Achter de schermen gebruikt de AI-visualisatie ML.NET om een beslissingsstructuur uit te voeren om interessante subgroepen te vinden. Het doel van de beslissingsstructuur is om te eindigen met een subgroep van gegevenspunten die relatief hoog zijn in de metrische gegevens waarin u geïnteresseerd bent. Het kunnen klanten zijn met lage waarderingen of huizen met hoge prijzen.
De beslissingsboom neemt elke verklarende factor en probeert te berekenen welke factor de beste splitsing geeft. Als u bijvoorbeeld de gegevens filtert om alleen grote zakelijke klanten op te nemen, zijn er dan klanten die een hoge waardering hebben gegeven of een lage waardering? Of misschien is het beter om de gegevens te filteren om alleen klanten op te nemen die commentaar hebben gegeven over beveiliging?
Nadat de beslissingsstructuur een splitsing heeft uitgevoerd, wordt de subgroep met gegevens gebruikt en wordt de volgende beste splitsing voor die gegevens bepaald. In dit geval is de subgroep klanten die commentaar hebben gegeven op beveiliging. Na elke splitsing wordt in de beslissingsstructuur ook nagegaan of deze voldoende gegevenspunten heeft om deze groep representatief genoeg te maken om een patroon af te leiden. Zo niet, dan is het een anomalie in de gegevens en niet een echt segment. Een andere statistische test wordt toegepast om te controleren op de statistische significantie van de splitsingsvoorwaarde met een p-waarde van 0,05.
Nadat de beslissingsboom is uitgevoerd, worden alle splitsingen, zoals beveiligingsopmerkingen en grote ondernemingen, omgezet in Power BI-filters. Deze combinatie van filters wordt verpakt als een segment in de visual.
Waarom worden bepaalde factoren beïnvloeders of stoppen met het zijn van beïnvloeders terwijl ik meer velden verplaats naar Uitleg door?
De visualisatie evalueert alle verklarende factoren samen. Een factor kan zelf een beïnvloeder zijn, maar wanneer dit wordt overwogen met andere factoren, is dit mogelijk niet mogelijk. Stel dat u wilt analyseren wat ervoor zorgt dat een woningprijs hoog is, met slaapkamers en huisgrootte als verklarende factoren:
- Op zichzelf zouden meer slaapkamers een aanjager kunnen zijn voor hoge huizenprijzen.
- Inclusief huisgrootte in de analyse betekent dat u nu kijkt wat er gebeurt met slaapkamers terwijl de huisgrootte constant blijft.
- Als huisgrootte is vastgesteld op 1500 vierkante meter, is het onwaarschijnlijk dat een continue toename van het aantal slaapkamers de woningprijs aanzienlijk verhoogt.
- Slaapkamers zijn misschien niet zo belangrijk als het was voordat huisgrootte werd overwogen.
Als u uw rapport deelt met een Power BI-collega, moet u beide afzonderlijke Fabric- of Power BI Pro-licenties hebben of dat het rapport wordt opgeslagen in een Premium-capaciteit. Zie rapporten delen.