Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In de vorige fase van deze zelfstudie hebben we PyTorch op uw computer geïnstalleerd. Nu gebruiken we deze om onze code in te stellen met de gegevens die we gaan gebruiken om ons model te maken.
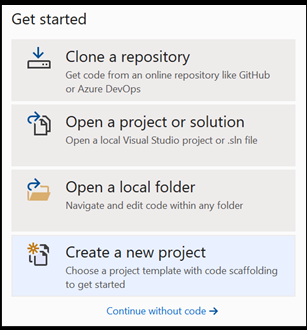
Open een nieuw project in Visual Studio.
- Open Visual Studio en kies
create a new project.
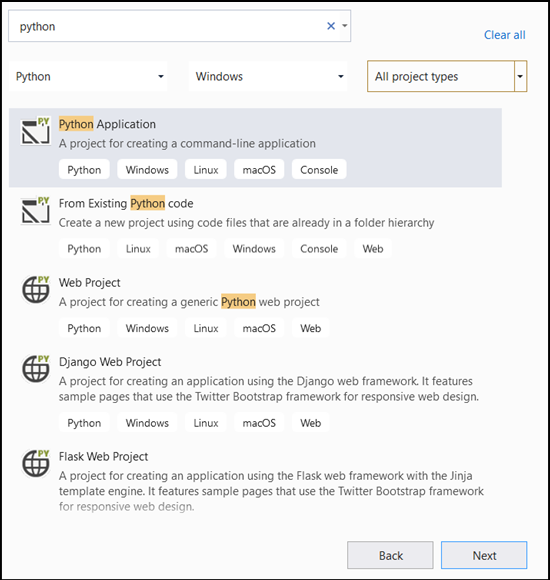
- Typ
Pythonen selecteerPython Applicationdeze in de zoekbalk als uw projectsjabloon.
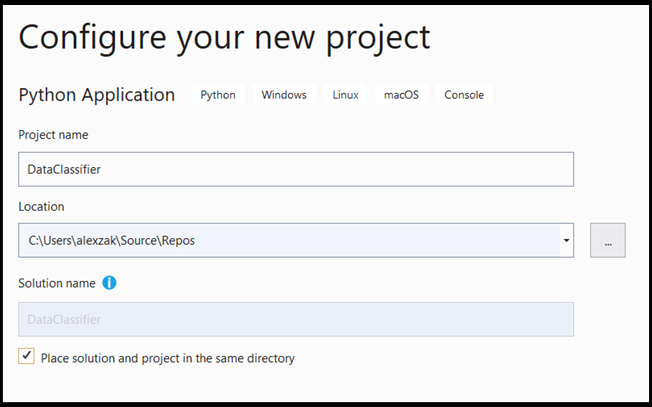
- In het configuratievenster:
- Geef uw project een naam. Hier noemen we het DataClassifier.
- Kies de locatie van uw project.
- Als u VS2019 gebruikt, zorg er dan voor dat
Create directory for solutionis ingeschakeld. - Als u VS2017 gebruikt, controleert u of
Place solution and project in the same directorydit selectievakje is uitgeschakeld.
Druk create om uw project te maken.
Een Python-interpreter maken
Nu moet u een nieuwe Python-interpreter definiëren. Dit moet het PyTorch-pakket bevatten dat u onlangs hebt geïnstalleerd.
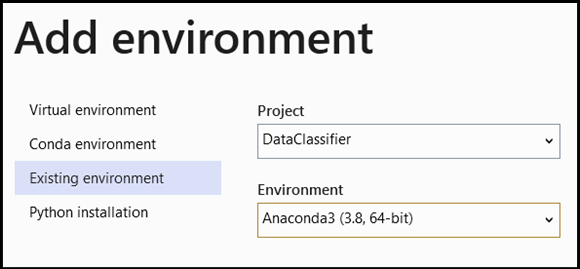
- Navigeer naar de selectie van de interpreter en selecteer
Add Environment:

- Selecteer
Add Environmenten kiesExisting environmentin hetAnaconda3 (3.6, 64-bit)venster. Dit omvat het PyTorch-pakket.
Als u het nieuwe Python-interpreter- en PyTorch-pakket wilt testen, voert u de volgende code in voor het DataClassifier.py bestand:
from __future__ import print_function
import torch
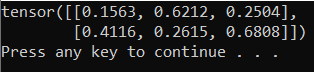
x=torch.rand(2, 3)
print(x)
De uitvoer moet een willekeurige 5x3-tensor zijn die vergelijkbaar is met de onderstaande.
Opmerking
Bent u geïnteresseerd in meer informatie? Bezoek de officiële website van PyTorch.
Inzicht in de gegevens
We trainen het model op de Iris-bloemgegevensset van Fisher. Deze beroemde gegevensset bevat 50 records voor elk van de drie irissoorten: Iris setosa, Iris virginica en Iris versicolor.
Er zijn verschillende versies van de gegevensset gepubliceerd. U kunt Iris-gegevensset vinden in de UCI Machine Learning-opslagplaats, de gegevensset rechtstreeks importeren uit de Python Scikit-learn-bibliotheek of een andere versie gebruiken die eerder is gepubliceerd. Ga naar de Wikipedia-pagina voor meer informatie over irisbloemgegevensset.
In deze zelfstudie word je getoond hoe je het model kunt trainen met tabulaire invoer, waarbij je de Iris-gegevensset gebruikt die is geëxporteerd naar een Excel-bestand.
Elke regel van de Excel-tabel toont vier eigenschappen van irissen: kelklengte in cm, kelkbreedte in cm, bloembladlengte in cm en bloembladbreedte in cm. Deze eigenschappen dienen als invoer. De laatste kolom bevat het Iris-type dat is gerelateerd aan deze parameters en vertegenwoordigt de regressie-uitvoer. In totaal bevat de gegevensset 150 invoer van vier functies, die elk overeenkomen met het relevante Iris-type.
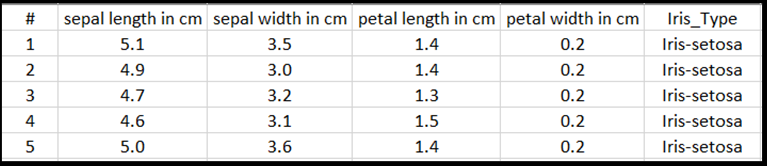
Regressieanalyse kijkt naar de relatie tussen invoervariabelen en het resultaat. Op basis van de invoer leert het model het juiste type uitvoer te voorspellen: een van de drie Iris-typen: Iris-setosa, Iris-versicolor, Iris-virginica.
Belangrijk
Als u besluit om een andere gegevensset te gebruiken om uw eigen model te maken, moet u uw modelinvoervariabelen en -uitvoer opgeven volgens uw scenario.
Laad de gegevensset.
Download de Iris-dataset in Excel-formaat. U kunt het hier vinden.
Voeg in het
DataClassifier.pybestand in de map Solution Explorer-bestanden de volgende importinstructie toe om toegang te krijgen tot alle pakketten die we nodig hebben.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Zoals u kunt zien, gebruikt u het pandas-pakket (Python-gegevensanalyse) om gegevens en het torch.nn-pakket te laden en bewerken dat modules en uitbreidbare klassen bevat voor het bouwen van neurale netwerken.
- Laad de gegevens in het geheugen en controleer het aantal klassen. We verwachten 50 items van elk Irissoort te zien. Zorg ervoor dat u de locatie van de gegevensset op uw pc opgeeft.
Voeg de volgende code toe aan het bestand DataClassifier.py.
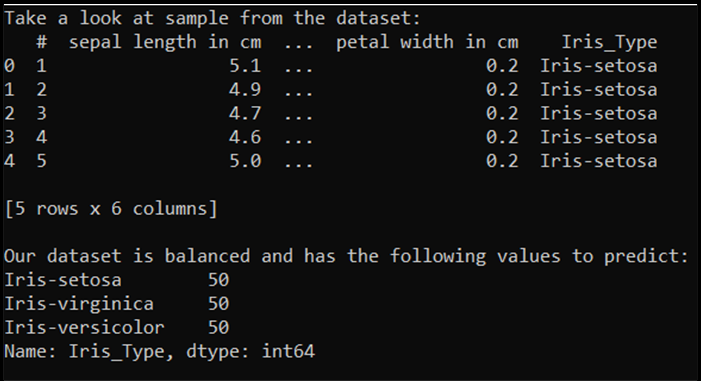
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Wanneer we deze code uitvoeren, is de verwachte uitvoer als volgt:
Om de gegevensset te kunnen gebruiken en het model te trainen, moeten we invoer en uitvoer definiëren. De invoer bevat 150 regels functies en de uitvoer is de kolom Iris-type. Voor het neurale netwerk dat we gaan gebruiken, zijn numerieke variabelen vereist, dus converteert u de uitvoervariabele naar een numerieke indeling.
- Maak een nieuwe kolom in de gegevensset die de uitvoer in een numerieke indeling vertegenwoordigt en definieer een regressie-invoer en -uitvoer.
Voeg de volgende code toe aan het bestand DataClassifier.py.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
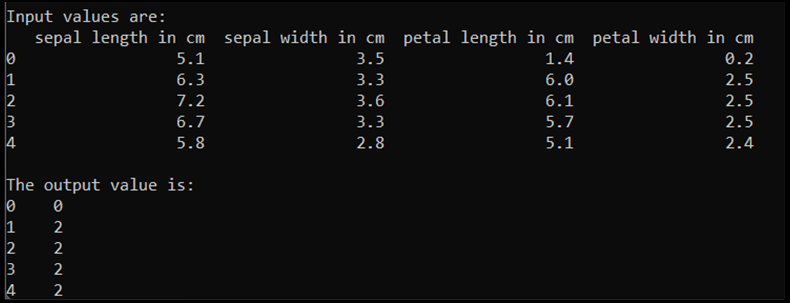
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Wanneer we deze code uitvoeren, is de verwachte uitvoer als volgt:
Als u het model wilt trainen, moeten we de modelinvoer en -uitvoer converteren naar de Tensor-indeling:
- Converteren naar Tensor:
Voeg de volgende code toe aan het bestand DataClassifier.py.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Als we de code uitvoeren, wordt in de verwachte uitvoer de invoer- en uitvoerindeling weergegeven, zoals volgt:

Er zijn 150 invoerwaarden. Ongeveer 60% zijn de modeltrainingsgegevens. U behoudt 20% voor validatie en 30% voor een test.
In deze zelfstudie wordt de batchgrootte voor een trainingsgegevensset gedefinieerd als 10. Er zijn 95 items in de trainingsset, wat betekent dat er gemiddeld 9 volledige batches zijn om de trainingsset eenmaal te doorlopen (één epoch). U behoudt de batchgrootte van de validatie- en testsets als 1.
- Splits de gegevens om sets te trainen, valideren en testen:
Voeg de volgende code toe aan het bestand DataClassifier.py.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Volgende stappen
Nu de gegevens klaar zijn, is het tijd om ons PyTorch-model te trainen