Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In de vorige fase van deze zelfstudie hebben we de gegevensset verkregen die we gaan gebruiken om ons gegevensanalysemodel te trainen met PyTorch. Nu is het tijd om die gegevens te gebruiken.
Als u het model voor gegevensanalyse wilt trainen met PyTorch, moet u de volgende stappen uitvoeren:
- Laad de gegevens. Als u de vorige stap van deze zelfstudie hebt uitgevoerd, hebt u dit al afgehandeld.
- Definieer een neuraal netwerk.
- Definieer een verliesfunctie.
- Train het model op de trainingsgegevens.
- Test het netwerk op de testgegevens.
Een neuraal netwerk definiëren
In deze zelfstudie bouwt u een eenvoudig neuraal netwerkmodel met drie lineaire lagen. De structuur van het model is als volgt:
Linear -> ReLU -> Linear -> ReLU -> Linear
Een lineaire laag past een lineaire transformatie toe op de binnenkomende gegevens. U moet het aantal invoerfuncties en het aantal uitvoerfuncties opgeven dat overeenkomt met het aantal klassen.
Een ReLU-laag is een activeringsfunctie om alle binnenkomende functies te definiëren die 0 of hoger zijn. Wanneer er dus een ReLU-laag wordt toegepast, wordt een getal kleiner dan 0 gewijzigd in nul, terwijl andere hetzelfde blijven. We passen de activeringslaag toe op de twee verborgen lagen en geen activering op de laatste lineaire laag.
Modelparameters
Modelparameters zijn afhankelijk van ons doel en de trainingsgegevens. De invoergrootte is afhankelijk van het aantal functies dat we het model invoeren: vier in ons geval. De uitvoergrootte is drie omdat er drie mogelijke typen irissen zijn.
Met drie lineaire lagen (4,24) -> (24,24) -> (24,3)heeft het netwerk 744 gewichten (96+576+72).
De leersnelheid (lr) bepaalt hoeveel u de gewichten van uw netwerk aanpast in relatie tot de verliesgradiënt. Hoe lager het is, hoe langzamer de training zal zijn. In deze zelfstudie stelt u lr in op 0.01.
Hoe werkt het netwerk?
Hier bouwen we een feed-forward-netwerk. Tijdens het trainingsproces verwerkt het netwerk de invoer door alle lagen, berekent het de fout om te begrijpen hoe ver het voorspelde label van de afbeelding afwijkt van het juiste, en geeft het de gradiënten terug door aan het netwerk om de gewichten van de lagen bij te werken. Door een enorme gegevensset met invoer te herhalen, leert het netwerk de gewichten ervan in te stellen om de beste resultaten te bereiken.
Een forward-functie berekent de waarde van de verliesfunctie en een achterwaartse functie berekent de kleurovergangen van de leerbare parameters. Wanneer u ons neurale netwerk maakt met PyTorch, hoeft u alleen de doorstuurfunctie te definiëren. De achterwaartse functie wordt automatisch gedefinieerd.
- Kopieer de volgende code naar het
DataClassifier.pybestand in Visual Studio om de modelparameters en het neurale netwerk te definiëren.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
U moet ook het uitvoeringsapparaat definiëren op basis van de beschikbare apparaat op uw pc. PyTorch heeft geen toegewezen bibliotheek voor GPU, maar u kunt het uitvoeringsapparaat handmatig definiëren. Het apparaat is een Nvidia GPU als deze aanwezig is op uw computer of uw CPU als dat niet het geval is.
- Kopieer de volgende code om het uitvoeringsapparaat te definiëren:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- Als laatste stap definieert u een functie om het model op te slaan:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Opmerking
Bent u geïnteresseerd in meer informatie over neuraal netwerk met PyTorch? Bekijk de PyTorch-documentatie.
Een verliesfunctie definiëren
Een verliesfunctie berekent een waarde waarmee wordt geschat hoe ver de uitvoer zich van het doel bevindt. Het belangrijkste doel is om de waarde van de verliesfunctie te verminderen door de gewichtsvectorwaarden te wijzigen door middel van backpropagatie in neurale netwerken.
Verlieswaarde verschilt van modelnauwkeurigheid. De verliesfunctie geeft aan hoe goed ons model zich gedraagt na elke iteratie van optimalisatie in de trainingsset. De nauwkeurigheid van het model wordt berekend op de testgegevens en toont het percentage voorspellingen dat juist is.
In PyTorch bevat het neurale netwerkpakket verschillende verliesfuncties die de bouwstenen van diepe neurale netwerken vormen. Als u meer wilt weten over deze details, begint u met de bovenstaande notitie. Hier gebruiken we de bestaande functies die zijn geoptimaliseerd voor classificatie, zoals deze, en gebruiken we een classificatiefunctie voor verlies tussen entropie en een Adam optimizer. In de optimizer bepaalt de leersnelheid (lr) hoeveel u de gewichten van het netwerk aanpast ten opzichte van de verliesgradiënt. U stelt het in als 0.001 hier- hoe lager het is, hoe langzamer de training zal zijn.
- Kopieer de volgende code naar het
DataClassifier.pybestand in Visual Studio om de verliesfunctie en een optimalisatiefunctie te definiëren.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Train het model op de trainingsgegevens.
Als u het model wilt trainen, moet u onze gegevens-iterator doorlopen, de invoer invoeren in het netwerk en optimaliseren. Als u de resultaten wilt valideren, vergelijkt u de voorspelde labels met de actuele labels in de validatieset na elke trainingscyclus.
Het programma geeft het trainingsverlies, validatieverlies en de nauwkeurigheid van het model weer voor elk tijdvak of voor elke volledige iteratie over de trainingsset. Het model wordt met de hoogste nauwkeurigheid opgeslagen en na 10 epochs wordt de uiteindelijke nauwkeurigheid weergegeven.
- Voeg de volgende code toe aan het
DataClassifier.pybestand
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Test het model op de testgegevens.
Nu we het model hebben getraind, kunnen we het model testen met de testgegevensset.
We voegen twee testfuncties toe. De eerste test het model dat u in het vorige deel hebt opgeslagen. Hiermee wordt het model getest met de testgegevensset van 45 items en wordt de nauwkeurigheid van het model afgedrukt. De tweede is een optionele functie om het vertrouwen van het model te testen bij het voorspellen van elk van de drie irissoorten, vertegenwoordigd door de kans op succesvolle classificatie van elke soort.
- Voeg de volgende code toe aan het bestand
DataClassifier.py.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Ten slotte gaan we de hoofdcode toevoegen. Hiermee wordt modeltraining gestart, het model opgeslagen en worden de resultaten op het scherm weergegeven. We voeren slechts twee iteraties [num_epochs = 25] uit via de trainingsset, dus het trainingsproces duurt niet te lang.
- Voeg de volgende code toe aan het bestand
DataClassifier.py.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
We gaan de test uitvoeren. Zorg ervoor dat de vervolgkeuzelijsten in de bovenste werkbalk zijn ingesteld op Debug. Wijzig Solution Platform naar x64 om het project op uw lokale machine uit te voeren als uw apparaat 64-bits is, of naar x86 als het 32-bits is.
- Als u het project wilt uitvoeren, klikt u op de
Start Debuggingknop op de werkbalk of drukt u opF5.
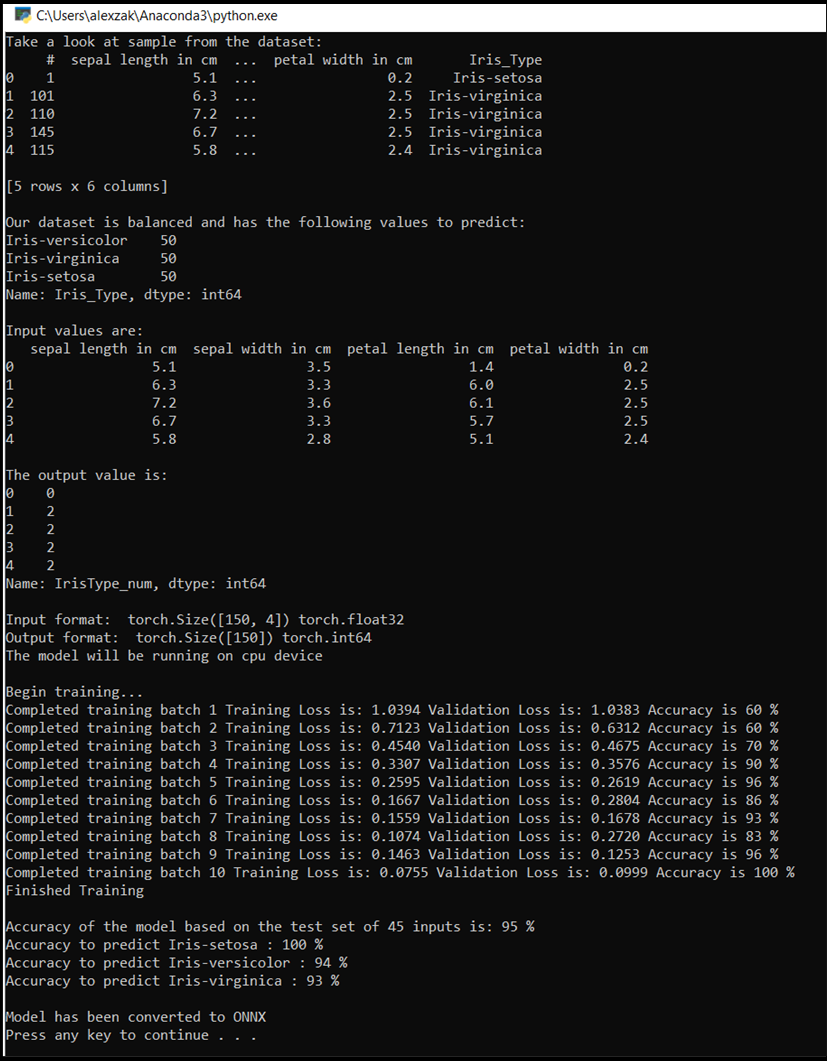
Het consolevenster wordt weergegeven en je ziet het trainingsproces. Zoals u hebt gedefinieerd, wordt de verlieswaarde elke epoch afgedrukt. De verwachting is dat de verlieswaarde met elke lus afneemt.
Zodra de training is voltooid, zult u een uitvoer zien die vergelijkbaar is met de onderstaande. Uw getallen zijn niet precies hetzelfde: training is afhankelijk van veel factoren en retourneert niet altijd identificale resultaten, maar ze moeten er ongeveer als volgt uitzien.
Volgende stappen
Nu we een classificatiemodel hebben, is de volgende stap het converteren van het model naar de ONNX-indeling.