Usługa Azure OpenAI na danych
Skorzystaj z tego artykułu, aby dowiedzieć się więcej o usłudze Azure OpenAI On Your Data, co ułatwia deweloperom szybkie łączenie, pozyskiwanie i uziemianie danych przedsiębiorstwa w celu szybkiego tworzenia spersonalizowanych copilots (wersja zapoznawcza). Zwiększa zrozumienie użytkownika, przyspiesza wykonywanie zadań, poprawia wydajność operacyjną i ułatwia podejmowanie decyzji.
Co to jest usługa Azure OpenAI na danych
Usługa Azure OpenAI On Your Data umożliwia uruchamianie zaawansowanych modeli sztucznej inteligencji, takich jak GPT-35-Turbo i GPT-4, na własnych danych przedsiębiorstwa bez konieczności trenowania lub dostosowywania modeli. Możesz rozmawiać na bieżąco z danymi i analizować je z większą dokładnością. Możesz określić źródła, aby obsługiwać odpowiedzi na podstawie najnowszych informacji dostępnych w wyznaczonych źródłach danych. Dostęp do usługi Azure OpenAI On Your Data można uzyskać przy użyciu interfejsu API REST za pośrednictwem zestawu SDK lub interfejsu internetowego w portalu azure AI Foundry. Możesz również utworzyć aplikację internetową, która łączy się z danymi, aby włączyć ulepszone rozwiązanie do czatu lub wdrożyć ją bezpośrednio jako copilot w programie Copilot Studio (wersja zapoznawcza).
Programowanie za pomocą usługi Azure OpenAI na danych
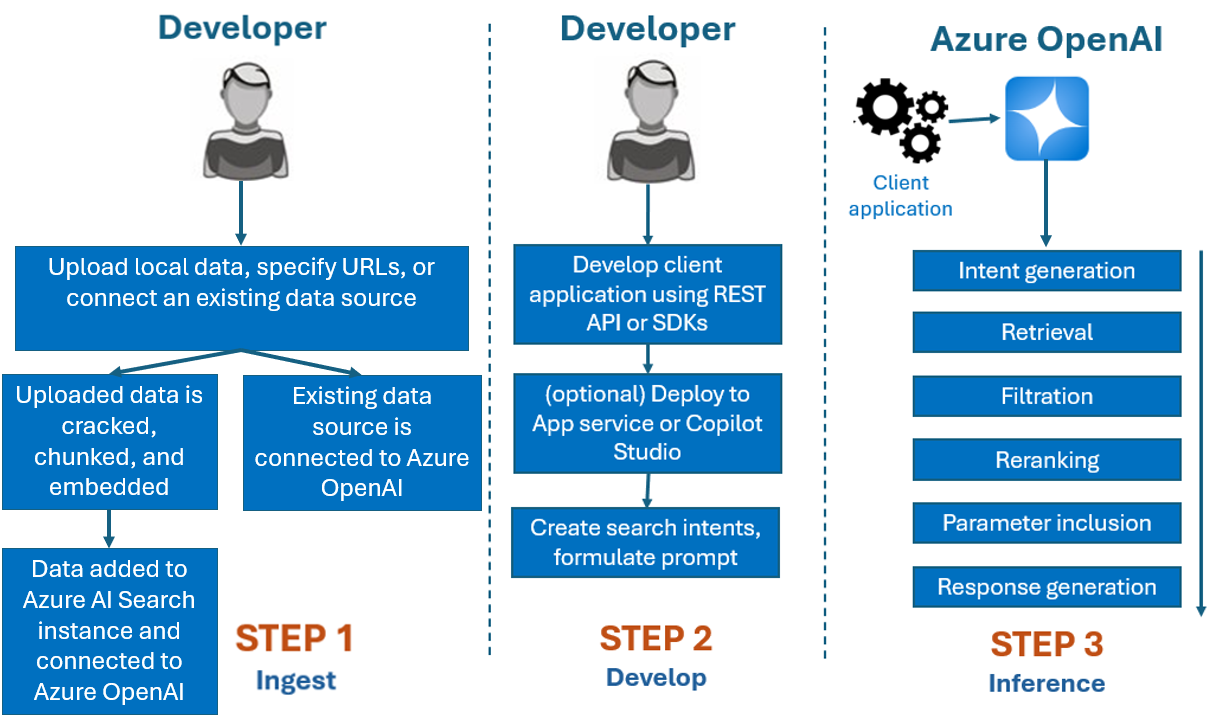
Zazwyczaj proces programowania używany w usłudze Azure OpenAI On Your Data to:
Pozyskiwanie: przekazywanie plików przy użyciu portalu usługi Azure AI Foundry lub interfejsu API pozyskiwania. Dzięki temu dane mogą być pęknięte, fragmentowane i osadzone w wystąpieniu usługi Azure AI Search, które mogą być używane przez modele usługi Azure OpenAI. Jeśli masz istniejące obsługiwane źródło danych, możesz również połączyć je bezpośrednio.
Programowanie: po wypróbowaniu usługi Azure OpenAI w danych rozpocznij tworzenie aplikacji przy użyciu dostępnego interfejsu API REST i zestawów SDK, które są dostępne w kilku językach. Spowoduje to utworzenie monitów i intencji wyszukiwania w celu przekazania do usługi Azure OpenAI.
Wnioskowanie: po wdrożeniu aplikacji w preferowanym środowisku zostanie wyświetlony monit do usługi Azure OpenAI, co spowoduje wykonanie kilku kroków przed zwróceniem odpowiedzi:
Generowanie intencji: usługa określi intencję monitu użytkownika o określenie odpowiedniej odpowiedzi.
Pobieranie: usługa pobiera odpowiednie fragmenty dostępnych danych z połączonego źródła danych, wysyłając do niego zapytanie. Na przykład przy użyciu wyszukiwania semantycznego lub wektorowego. Parametry , takie jak ścisłość i liczba dokumentów do pobrania, są używane do wywierania wpływu na pobieranie.
Filtrowanie i ponowne korbowanie: wyniki wyszukiwania z kroku pobierania są ulepszane przez klasyfikowanie i filtrowanie danych w celu uściślinia istotności.
Generowanie odpowiedzi: wynikowe dane są przesyłane wraz z innymi informacjami, takimi jak komunikat systemowy do modelu dużego języka (LLM), a odpowiedź jest wysyłana z powrotem do aplikacji.
Aby rozpocząć pracę, połącz źródło danych przy użyciu portalu Azure AI Foundry i zacznij zadawać pytania i rozmawiać na swoich danych.
Kontrola dostępu oparta na rolach (RBAC) platformy Azure do dodawania źródeł danych
Aby w pełni używać usługi Azure OpenAI Na danych, musisz ustawić co najmniej jedną rolę RBAC platformy Azure. Aby uzyskać więcej informacji, zobacz Azure OpenAI On Your Data configuration (Konfiguracja danych w usłudze Azure OpenAI).
Formaty danych i typy plików
Usługa Azure OpenAI On Your Data obsługuje następujące typy plików:
.txt.md.html.docx.pptx.pdf
Istnieje limit przekazywania i istnieją pewne zastrzeżenia dotyczące struktury dokumentów i sposobu, w jaki może to mieć wpływ na jakość odpowiedzi z modelu:
Jeśli konwertujesz dane z nieobsługiwanego formatu na obsługiwany format, zoptymalizuj jakość odpowiedzi modelu, zapewniając konwersję:
- Nie prowadzi do znacznej utraty danych.
- Nie dodaje nieoczekiwanego szumu do danych.
Jeśli pliki mają specjalne formatowanie, takie jak tabele i kolumny lub punktory, przygotuj dane za pomocą skryptu przygotowywania danych dostępnego w usłudze GitHub.
W przypadku dokumentów i zestawów danych z długim tekstem należy użyć dostępnego skryptu przygotowywania danych. Skrypt fragmentuje dane, aby odpowiedzi modelu były dokładniejsze. Ten skrypt obsługuje również zeskanowane pliki PDF i obrazy.
Obsługiwane źródła danych
Aby przekazać dane, musisz nawiązać połączenie ze źródłem danych. Jeśli chcesz używać danych do rozmowy z modelem usługi Azure OpenAI, dane są podzielone na indeks wyszukiwania, dzięki czemu odpowiednie dane można znaleźć na podstawie zapytań użytkowników.
Zintegrowana baza danych wektorów w usłudze Azure Cosmos DB for MongoDB oparta na rdzeniach wirtualnych natywnie obsługuje integrację z usługą Azure OpenAI On Your Data.
W przypadku niektórych źródeł danych, takich jak przekazywanie plików z komputera lokalnego (wersja zapoznawcza) lub dane zawarte na koncie magazynu obiektów blob (wersja zapoznawcza), jest używana usługa Azure AI Search. Po wybraniu następujących źródeł danych dane są pozyskiwane do indeksu usługi Azure AI Search.
| Dane pozyskiwane za pośrednictwem usługi Azure AI Search | opis |
|---|---|
| Azure AI Search | Użyj istniejącego indeksu usługi Azure AI Search z usługą Azure OpenAI Na danych. |
| Przekazywanie plików (wersja zapoznawcza) | Przekaż pliki z komputera lokalnego do przechowywania w bazie danych usługi Azure Blob Storage i pozyskane do usługi Azure AI Search. |
| Adres URL/adres internetowy (wersja zapoznawcza) | Zawartość internetowa z adresów URL jest przechowywana w usłudze Azure Blob Storage. |
| Azure Blob Storage (wersja zapoznawcza) | Przekazywanie plików z usługi Azure Blob Storage do pozyskiwania do indeksu usługi Azure AI Search. |

- Azure AI Search
- Wektorowa baza danych w usłudze Azure Cosmos DB dla bazy danych MongoDB
- Azure Blob Storage (wersja zapoznawcza)
- Przekazywanie plików (wersja zapoznawcza)
- Adres URL/adres internetowy (wersja zapoznawcza)
- Elasticsearch (wersja zapoznawcza)
- MongoDB Atlas (wersja zapoznawcza)
Warto rozważyć użycie indeksu usługi Azure AI Search, jeśli chcesz:
- Dostosuj proces tworzenia indeksu.
- Użyj ponownie indeksu utworzonego wcześniej przez pozyskiwanie danych z innych źródeł danych.
Uwaga
- Aby użyć istniejącego indeksu, musi mieć co najmniej jedno pole z możliwością wyszukiwania.
- Ustaw opcję CORS Allow Origin Type (Zezwalaj na typ źródła) na
alli opcję Dozwolone źródła na*wartość .
Typy wyszukiwania
Usługa Azure OpenAI On Your Data udostępnia następujące typy wyszukiwania, których można użyć podczas dodawania źródła danych.
Wyszukiwanie wektorowe przy użyciu modeli osadzania Ada, dostępne w wybranych regionach
Aby włączyć wyszukiwanie wektorowe, potrzebny jest istniejący model osadzania wdrożony w zasobie usługi Azure OpenAI. Wybierz wdrożenie osadzania podczas łączenia danych, a następnie wybierz jeden z typów wyszukiwania wektorów w obszarze Zarządzanie danymi. Jeśli używasz usługi Azure AI Search jako źródła danych, upewnij się, że w indeksie znajduje się kolumna wektorowa.
Jeśli używasz własnego indeksu , możesz dostosować mapowanie pól podczas dodawania źródła danych w celu zdefiniowania pól, które będą mapowane podczas odpowiadania na pytania. Aby dostosować mapowanie pól, wybierz pozycję Użyj mapowania pól niestandardowych na stronie Źródło danych podczas dodawania źródła danych.
Ważne
- Wyszukiwanie semantyczne podlega dodatkowym cenom. Aby włączyć wyszukiwanie semantyczne lub wyszukiwanie wektorów, musisz wybrać jednostkę SKU Podstawowa lub nowsza jednostka SKU . Aby uzyskać więcej informacji, zobacz różnice w warstwie cenowej i limity usług.
- Aby poprawić jakość pobierania informacji i odpowiedzi modelu, zalecamy włączenie semantycznego wyszukiwania następujących języków źródła danych: angielski, francuski, hiszpański, portugalski, włoski, niemiecki, chiński (Zh), japoński, koreański, rosyjski i arabski.
| Opcja wyszukiwania | Typ pobierania | Dodatkowe ceny? | Świadczenia |
|---|---|---|---|
| słowo kluczowe | Wyszukiwanie wg słów kluczowych | Brak dodatkowych cen. | Wykonuje szybkie i elastyczne analizowanie zapytań i dopasowywanie w polach z możliwością wyszukiwania, przy użyciu terminów lub fraz w dowolnym obsługiwanym języku z operatorami lub bez nich. |
| semantyczny | Wyszukiwanie semantyczne | Dodatkowe ceny użycia wyszukiwania semantycznego. | Poprawia precyzję i istotność wyników wyszukiwania przy użyciu usługi reranker (z modelami sztucznej inteligencji), aby zrozumieć semantyczne znaczenie terminów zapytań i dokumentów zwracanych przez początkowy rangą wyszukiwania |
| wektor | Wyszukiwanie wektorowe | Dodatkowe ceny na koncie usługi Azure OpenAI z wywoływania modelu osadzania. | Umożliwia znajdowanie dokumentów, które są podobne do danych wejściowych danego zapytania na podstawie wektorowych osadzania zawartości. |
| hybryda (wektor + słowo kluczowe) | Hybryda wyszukiwania wektorów i wyszukiwania słów kluczowych | Dodatkowe ceny na koncie usługi Azure OpenAI z wywoływania modelu osadzania. | Wykonuje wyszukiwanie podobieństwa w polach wektorów przy użyciu osadzania wektorów, a także obsługuje elastyczne analizowanie zapytań i wyszukiwanie pełnotekstowe w polach alfanumerycznych przy użyciu zapytań terminowych. |
| hybrydowe (wektor + słowo kluczowe) + semantyka | Hybryda wyszukiwania wektorowego, wyszukiwania semantycznego i wyszukiwania słów kluczowych. | Dodatkowe ceny na koncie usługi Azure OpenAI z wywoływania modelu osadzania oraz dodatkowe ceny użycia wyszukiwania semantycznego. | Używa osadzania wektorów, interpretacji języka i elastycznego analizowania zapytań, aby tworzyć zaawansowane środowiska wyszukiwania i generujące aplikacje sztucznej inteligencji, które mogą obsługiwać złożone i zróżnicowane scenariusze pobierania informacji. |
Wyszukiwanie inteligentne
Usługa Azure OpenAI On Your Data ma włączone inteligentne wyszukiwanie danych. Wyszukiwanie semantyczne jest domyślnie włączone, jeśli zarówno wyszukiwanie semantyczne, jak i wyszukiwanie słów kluczowych. W przypadku osadzania modeli inteligentne wyszukiwanie jest domyślnie włączone do wyszukiwania hybrydowego i semantycznego.
Kontrola dostępu na poziomie dokumentu
Uwaga
Kontrola dostępu na poziomie dokumentu jest obsługiwana podczas wybierania usługi Azure AI Search jako źródła danych.
Usługa Azure OpenAI On Your Data umożliwia ograniczenie dokumentów, które mogą być używane w odpowiedziach dla różnych użytkowników z filtrami zabezpieczeń usługi Azure AI Search. Po włączeniu dostępu na poziomie dokumentu wyniki wyszukiwania zwracane z usługi Azure AI Search i używane do generowania odpowiedzi są przycinane na podstawie członkostwa w grupie Microsoft Entra użytkownika. Dostęp na poziomie dokumentu można włączyć tylko w istniejących indeksach usługi Azure AI Search. Aby uzyskać więcej informacji, zobacz Artykuł Azure OpenAI On Your Data network and access configuration (Konfiguracja dostępu do usługi Azure OpenAI w sieci danych i konfiguracji dostępu).
Mapowanie pól indeksu
Jeśli używasz własnego indeksu, w portalu usługi Azure AI Foundry zostanie wyświetlony monit o zdefiniowanie pól, które mają być mapowane na potrzeby odpowiadania na pytania podczas dodawania źródła danych. Możesz podać wiele pól dla danych zawartości i powinny zawierać wszystkie pola, które mają tekst odnoszący się do twojego przypadku użycia.

W tym przykładzie pola mapowane na dane zawartości i Tytuł zawierają informacje do modelu w celu udzielenia odpowiedzi na pytania. Tytuł jest również używany do tekstu cytatu tytułowego. Pole mapowane na nazwę pliku generuje nazwy cytatów w odpowiedzi.
Poprawne mapowanie tych pól pomaga upewnić się, że model ma lepszą jakość odpowiedzi i cytatów. Dodatkowo można go skonfigurować w interfejsie API przy użyciu parametru fieldsMapping .
Filtr wyszukiwania (INTERFEJS API)
Jeśli chcesz zaimplementować dodatkowe kryteria oparte na wartości na potrzeby wykonywania zapytań, możesz skonfigurować filtr wyszukiwania przy użyciu parametru filter w interfejsie API REST.
Jak dane są pozyskiwane do wyszukiwania w usłudze Azure AI
Od września 2024 r. interfejsy API pozyskiwania przełączyły się do zintegrowanej wektoryzacji. Ta aktualizacja nie zmienia istniejących kontraktów interfejsu API. Zintegrowana wektoryzacja, nowa oferta usługi Azure AI Search, wykorzystuje wstępnie utworzone umiejętności do fragmentowania i osadzania danych wejściowych. Usługa Azure OpenAI w usłudze pozyskiwania danych nie wykorzystuje już niestandardowych umiejętności. Po migracji do zintegrowanej wektoryzacji proces pozyskiwania przeszedł pewne modyfikacje i w rezultacie tworzone są tylko następujące zasoby:
{job-id}-index-
{job-id}-indexer, jeśli określono harmonogram godzinowy lub dzienny, w przeciwnym razie indeksator jest czyszczony na końcu procesu pozyskiwania. {job-id}-datasource
Kontener fragmentów nie jest już dostępny, ponieważ ta funkcja jest teraz z natury zarządzana przez usługę Azure AI Search.
Połączenie danych
Musisz wybrać sposób uwierzytelniania połączenia z usług Azure OpenAI, Azure AI Search i Azure Blob Storage. Możesz wybrać tożsamość zarządzaną przypisaną przez system lub klucz interfejsu API. Po wybraniu klucza interfejsu API jako typu uwierzytelniania system automatycznie wypełni klucz interfejsu API, aby nawiązać połączenie z usługą Azure AI Search, usługą Azure OpenAI i zasobami usługi Azure Blob Storage. Wybierając pozycję Tożsamość zarządzana przypisana przez system, uwierzytelnianie będzie oparte na posiadaniu przypisania roli. Tożsamość zarządzana przypisana przez system jest domyślnie wybierana dla zabezpieczeń.

Po wybraniu następnego przycisku automatycznie zweryfikuje konfigurację, aby użyć wybranej metody uwierzytelniania. Jeśli wystąpi błąd, zapoznaj się z artykułem dotyczącym przypisań ról, aby zaktualizować konfigurację.
Po naprawieniu konfiguracji wybierz ponownie, aby zweryfikować i kontynuować. Użytkownicy interfejsu API mogą również konfigurować uwierzytelnianie przy użyciu przypisanej tożsamości zarządzanej i kluczy interfejsu API.










Wdrażanie w aplikacji copilot (wersja zapoznawcza), aplikacja Teams (wersja zapoznawcza) lub aplikacja internetowa
Po połączeniu usługi Azure OpenAI z danymi możesz wdrożyć je przy użyciu przycisku Wdróż w portalu azure AI Foundry.

Zapewnia to wiele opcji wdrażania rozwiązania.
Możesz wdrożyć w copilot w copilot Studio (wersja zapoznawcza) bezpośrednio z portalu Usługi Azure AI Foundry, co umożliwia przenoszenie środowisk konwersacyjnych do różnych kanałów, takich jak Microsoft Teams, witryny internetowe, dynamics 365 i inne kanały usługi Azure Bot Service. Dzierżawa używana w usłudze Azure OpenAI i Copilot Studio (wersja zapoznawcza) powinna być taka sama. Aby uzyskać więcej informacji, zobacz Use a connection to Azure OpenAI On Your Data (Używanie połączenia z usługą Azure OpenAI w danych).
Uwaga
Wdrażanie w copilot w copilot Studio (wersja zapoznawcza) jest dostępne tylko w regionach USA.
Konfigurowanie dostępu i sieci dla usługi Azure OpenAI na danych
Możesz użyć usługi Azure OpenAI On Your Data i chronić dane i zasoby za pomocą kontroli dostępu opartej na rolach, sieciach wirtualnych i prywatnych punktach końcowych firmy Microsoft. Można również ograniczyć dokumenty, które mogą być używane w odpowiedziach dla różnych użytkowników z filtrami zabezpieczeń usługi Azure AI Search. Zobacz Azure OpenAI On Your Data access and network configuration (Azure OpenAI w obszarze Dostęp do danych i konfiguracja sieci).
Najlepsze rozwiązania
Skorzystaj z poniższych sekcji, aby dowiedzieć się, jak poprawić jakość odpowiedzi udzielanych przez model.
Parametr pozyskiwania
Gdy dane są pozyskiwane do usługi Azure AI Search, możesz zmodyfikować następujące dodatkowe ustawienia w programie Studio lub interfejsie API pozyskiwania.
Rozmiar fragmentu (wersja zapoznawcza)
Usługa Azure OpenAI On Your Data przetwarza dokumenty, dzieląc je na fragmenty przed ich pozyskiwaniem. Rozmiar fragmentu jest maksymalnym rozmiarem pod względem liczby tokenów dowolnego fragmentu w indeksie wyszukiwania. Rozmiar fragmentu i liczba pobranych dokumentów razem kontrolują, ile informacji (tokenów) jest uwzględnionych w wierszu polecenia wysłanego do modelu. Ogólnie rzecz biorąc, rozmiar fragmentu pomnożony przez liczbę pobranych dokumentów jest całkowitą liczbą tokenów wysyłanych do modelu.
Ustawianie rozmiaru fragmentu dla przypadku użycia
Domyślny rozmiar fragmentu to 1024 tokeny. Jednak biorąc pod uwagę unikatowość danych, można znaleźć inny rozmiar fragmentu (np. 256, 512 lub 1536 tokenów).
Dostosowanie rozmiaru fragmentu może zwiększyć wydajność czatbota. Podczas znajdowania optymalnego rozmiaru fragmentu wymagana jest próba i błąd, zacznij od rozważenia charakteru zestawu danych. Mniejszy rozmiar fragmentu jest ogólnie lepszy w przypadku zestawów danych z bezpośrednimi faktami i mniejszym kontekstem, podczas gdy większy rozmiar fragmentu może być korzystny dla bardziej kontekstowych informacji, choć może to mieć wpływ na wydajność pobierania.
Mały rozmiar fragmentu, taki jak 256, produkuje bardziej szczegółowe fragmenty. Ten rozmiar oznacza również, że model będzie wykorzystywać mniej tokenów do generowania danych wyjściowych (chyba że liczba pobranych dokumentów jest bardzo wysoka), potencjalnie kosztując mniej. Mniejsze fragmenty oznaczają również, że model nie musi przetwarzać i interpretować długich sekcji tekstu, zmniejszając szum i rozpraszanie uwagi. Ten stopień szczegółowości i fokus stanowią jednak potencjalny problem. Ważne informacje mogą nie być jednymi z najważniejszych pobranych fragmentów, zwłaszcza jeśli liczba pobranych dokumentów jest ustawiona na niską wartość, na przykład 3.
Napiwek
Należy pamiętać, że zmiana rozmiaru fragmentu wymaga ponownego pozyskiwania dokumentów, dlatego warto najpierw dostosować parametry środowiska uruchomieniowego, takie jak ścisłość i liczba pobranych dokumentów. Rozważ zmianę rozmiaru fragmentu, jeśli nadal nie otrzymujesz żądanych wyników:
- Jeśli napotykasz dużą liczbę odpowiedzi, takich jak "Nie wiem" na pytania z odpowiedziami, które powinny znajdować się w dokumentach, rozważ zmniejszenie rozmiaru fragmentu do 256 lub 512, aby zwiększyć stopień szczegółowości.
- Jeśli czatbot udostępnia poprawne szczegóły, ale brakuje innych, co staje się widoczne w cytatach, zwiększenie rozmiaru fragmentu do 1536 może pomóc w przechwyceniu bardziej kontekstowych informacji.
Parametry środowiska uruchomieniowego
Następujące dodatkowe ustawienia można zmodyfikować w sekcji Parametry danych w portalu usługi Azure AI Foundry i interfejsie API. Nie musisz ponownie pozyskiwać danych podczas aktualizowania tych parametrów.
| Nazwa parametru | opis |
|---|---|
| Ograniczanie odpowiedzi na dane | Ta flaga umożliwia skonfigurowanie podejścia czatbota do obsługi zapytań niepowiązanych ze źródłem danych lub gdy dokumenty wyszukiwania nie są wystarczające dla pełnej odpowiedzi. Gdy to ustawienie jest wyłączone, model uzupełnia swoje odpowiedzi własną wiedzą oprócz dokumentów. Po włączeniu tego ustawienia model próbuje polegać tylko na dokumentach na potrzeby odpowiedzi. Jest inScope to parametr w interfejsie API i domyślnie ustawiony na wartość true. |
| Pobrane dokumenty | Ten parametr jest liczbą całkowitą, którą można ustawić na 3, 5, 10 lub 20, i kontroluje liczbę fragmentów dokumentów dostarczonych do dużego modelu językowego na potrzeby formułowania ostatecznej odpowiedzi. Domyślnie jest ustawiona wartość 5. Proces wyszukiwania może być hałaśliwy, a czasami ze względu na fragmentowanie istotne informacje mogą być rozłożone na wiele fragmentów w indeksie wyszukiwania. Wybranie numeru top-K, na przykład 5, gwarantuje, że model może wyodrębnić odpowiednie informacje, pomimo istotnych ograniczeń wyszukiwania i fragmentowania. Jednak zwiększenie zbyt dużej liczby może potencjalnie rozpraszać model. Ponadto maksymalna liczba dokumentów, które mogą być skutecznie używane, zależy od wersji modelu, ponieważ każdy z nich ma inny rozmiar kontekstu i pojemność do obsługi dokumentów. Jeśli okaże się, że brakuje ważnego kontekstu odpowiedzi, spróbuj zwiększyć ten parametr. Jest topNDocuments to parametr w interfejsie API i jest domyślnie 5. |
| Ścisłość | Określa agresywność systemu w filtrowaniu dokumentów wyszukiwania na podstawie ich wyników podobieństwa. System wysyła zapytania do usługi Azure Search lub innych magazynów dokumentów, a następnie decyduje, które dokumenty mają być zapewniane dużym modelom językowym, na przykład ChatGPT. Filtrowanie nieistotnych dokumentów może znacznie zwiększyć wydajność kompleksowego czatbota. Niektóre dokumenty są wykluczone z wyników top-K, jeśli mają wyniki niskiej podobieństwa przed przekazaniem ich do modelu. Jest to kontrolowane przez wartość całkowitą z zakresu od 1 do 5. Ustawienie tej wartości na 1 oznacza, że system będzie minimalnie filtrować dokumenty na podstawie podobieństwa wyszukiwania do zapytania użytkownika. Z drugiej strony ustawienie 5 wskazuje, że system będzie agresywnie filtrować dokumenty, stosując bardzo wysoki próg podobieństwa. Jeśli okaże się, że czatbot pomija istotne informacje, obniż ścisłość filtru (ustaw wartość bliżej 1), aby uwzględnić więcej dokumentów. Z drugiej strony, jeśli nieistotne dokumenty rozpraszają odpowiedzi, zwiększ próg (ustaw wartość bliżej 5). Jest strictness to parametr w interfejsie API i domyślnie ustawiony na 3. |
Nie cytowane odwołania
Model może zwracać "TYPE":"UNCITED_REFERENCE" zamiast "TYPE":CONTENT interfejsu API dla dokumentów pobranych ze źródła danych, ale nie uwzględnianych w cytatie. Może to być przydatne do debugowania i można kontrolować to zachowanie, modyfikując ścisłe ipobrane parametry środowiska uruchomieniowego dokumentów opisane powyżej.
Komunikat systemowy
Możesz zdefiniować komunikat systemowy, aby kierować odpowiedzią modelu podczas korzystania z usługi Azure OpenAI On Your Data. Ten komunikat umożliwia dostosowanie odpowiedzi na podstawie wzorca rozszerzonej generacji (RAG) pobierania używanego przez usługę Azure OpenAI On Your Data. Komunikat systemowy jest używany oprócz wewnętrznego monitu podstawowego w celu zapewnienia środowiska. Aby to umożliwić, obcinamy komunikat systemowy po określonej liczbie tokenów , aby upewnić się, że model może odpowiedzieć na pytania przy użyciu danych. Jeśli definiujesz dodatkowe zachowanie na podstawie domyślnego środowiska, upewnij się, że monit systemowy jest szczegółowy i wyjaśnia dokładne oczekiwane dostosowanie.
Po wybraniu pozycji Dodaj zestaw danych możesz użyć sekcji Komunikat systemowy w portalu usługi Azure AI Foundry lub role_informationparametru w interfejsie API.

Potencjalne wzorce użycia
Definiowanie roli
Możesz zdefiniować rolę, która ma być asystentem. Jeśli na przykład tworzysz bota pomocy technicznej, możesz dodać " Jesteś asystentem pomocy technicznej ekspertów, który pomaga użytkownikom rozwiązywać nowe problemy".
Definiowanie typu pobieranych danych
Możesz również dodać charakter danych, które udostępniasz asystentowi.
- Zdefiniuj temat lub zakres zestawu danych, taki jak "raport finansowy", "dokument akademicki" lub "raport o zdarzeniach". Na przykład w przypadku pomocy technicznej możesz dodać " Odpowiadasz na zapytania przy użyciu informacji z podobnych zdarzeń w pobranych dokumentach".
- Jeśli dane mają pewne cechy, możesz dodać te szczegóły do komunikatu systemowego. Jeśli na przykład dokumenty znajdują się w języku japońskim, możesz dodać " Pobierz japońskie dokumenty i należy je uważnie przeczytać w języku japońskim i odpowiedzieć w języku japońskim".
- Jeśli dokumenty zawierają dane ustrukturyzowane, takie jak tabele z raportu finansowego, możesz również dodać ten fakt do monitu systemowego. Jeśli na przykład dane zawierają tabele, możesz dodać " Dane są podane w postaci tabel odnoszących się do wyników finansowych i należy przeczytać wiersz tabeli według wiersza, aby wykonać obliczenia, aby odpowiedzieć na pytania użytkownika".
Definiowanie stylu danych wyjściowych
Możesz również zmienić dane wyjściowe modelu, definiując komunikat systemowy. Jeśli na przykład chcesz upewnić się, że asystent odpowiedzi jest w języku francuskim, możesz dodać monit, taki jak "Jesteś asystentem sztucznej inteligencji, który pomaga użytkownikom, którzy rozumieją francuskie informacje. Pytania użytkownika mogą być w języku angielskim lub francuskim. Dokładnie przeczytaj pobrane dokumenty i odpowiedz na nie w języku francuskim. Przetłumacz wiedzę z dokumentów na francuski, aby upewnić się, że wszystkie odpowiedzi są w języku francuskim.
Potwierdzanie zachowania krytycznego
Usługa Azure OpenAI On Your Data działa, wysyłając instrukcje do dużego modelu językowego w postaci monitów o udzielenie odpowiedzi na zapytania użytkowników przy użyciu danych. Jeśli istnieje pewne zachowanie, które ma kluczowe znaczenie dla aplikacji, możesz powtórzyć zachowanie w komunikacie systemowym, aby zwiększyć jego dokładność. Aby na przykład pokierować modelem tylko na odpowiedź z dokumentów, możesz dodać "Odpowiedz tylko przy użyciu pobranych dokumentów i bez korzystania z twojej wiedzy. Wygeneruj cytaty, aby pobrać dokumenty dla każdego oświadczenia w odpowiedzi. Jeśli nie można odpowiedzieć na pytanie użytkownika przy użyciu pobranych dokumentów, wyjaśnij uzasadnienie, dlaczego dokumenty są istotne dla zapytań użytkowników. W każdym razie nie odpowiadaj na własną wiedzę".
Monity inżynieryjne
Istnieje wiele wskazówek w zakresie monitowania inżynieryjnego, które można spróbować poprawić dane wyjściowe. Jednym z przykładów jest monitowanie o łańcuch myśli, w którym można dodać "Pomyślmy krok po kroku o informacjach w pobranych dokumentach, aby odpowiedzieć na zapytania użytkowników. Wyodrębnij odpowiednią wiedzę dla zapytań użytkowników z dokumentów krok po kroku i wydziel odpowiedź od wyodrębnionych informacji z odpowiednich dokumentów.
Uwaga
Komunikat systemowy służy do modyfikowania sposobu odpowiadania asystenta GPT na pytanie użytkownika na podstawie pobranej dokumentacji. Nie ma to wpływu na proces pobierania. Jeśli chcesz podać instrukcje dotyczące procesu pobierania, lepiej uwzględnić je w pytaniach. Komunikat systemowy jest tylko wskazówkami. Model może nie być zgodny z każdą określoną instrukcją, ponieważ został zagruntowany pewnymi zachowaniami, takimi jak obiektywność, i unikając kontrowersyjnych stwierdzeń. Może wystąpić nieoczekiwane zachowanie, jeśli komunikat systemowy jest sprzeczny z tymi zachowaniami.
Maksymalna odpowiedź
Ustaw limit liczby tokenów na odpowiedź modelu. Górny limit dla usługi Azure OpenAI na danych wynosi 1500. Jest to odpowiednik ustawienia parametru max_tokens w interfejsie API.
Ograniczanie odpowiedzi na dane
Ta opcja zachęca model do reagowania tylko na dane i jest domyślnie wybierany. Jeśli usuniesz zaznaczenie tej opcji, model może bardziej łatwo zastosować swoją wewnętrzną wiedzę, aby odpowiedzieć. Określ prawidłowy wybór na podstawie przypadku użycia i scenariusza.
Interakcja z modelem
Skorzystaj z poniższych rozwiązań, aby uzyskać najlepsze wyniki podczas rozmowy z modelem.
Historia konwersacji
- Przed rozpoczęciem nowej konwersacji (lub zadawaniem pytania, które nie jest związane z poprzednimi), wyczyść historię czatów.
- Uzyskanie różnych odpowiedzi na to samo pytanie między pierwszym kolei konwersacyjnym a kolejnymi zakrętami może być oczekiwane, ponieważ historia konwersacji zmienia bieżący stan modelu. Jeśli otrzymasz nieprawidłowe odpowiedzi, zgłoś ją jako usterkę jakości.
Odpowiedź modelu
Jeśli nie masz zadowolenia z odpowiedzi modelu na konkretne pytanie, spróbuj użyć pytania bardziej szczegółowego lub bardziej ogólnego, aby zobaczyć, jak model odpowiada, i odpowiednio przeprojektuj pytanie.
Pokazano, że tworzenie łańcuchów myślowych monitów było skuteczne w uzyskaniu modelu w celu wygenerowania żądanych danych wyjściowych dla złożonych pytań/zadań.
Długość pytania
Unikaj zadawania długich pytań i podziel je na wiele pytań, jeśli to możliwe. Modele GPT mają limity liczby tokenów, które mogą zaakceptować. Limity tokenów są liczone w kierunku: pytanie użytkownika, komunikat systemowy, pobrane dokumenty wyszukiwania (fragmenty), monity wewnętrzne, historia konwersacji (jeśli istnieje) i odpowiedź. Jeśli pytanie przekroczy limit tokenu, zostanie obcięte.
Obsługa wielu języków
Obecnie wyszukiwanie słów kluczowych i wyszukiwanie semantyczne w usłudze Azure OpenAI On Your Data obsługuje zapytania w tym samym języku co dane w indeksie. Jeśli na przykład dane są w języku japońskim, zapytania wejściowe również muszą znajdować się w języku japońskim. W przypadku pobierania dokumentów międzyjęzycznych zalecamy utworzenie indeksu z włączonym wyszukiwaniem wektorowym.
Aby poprawić jakość pobierania informacji i odpowiedzi modelu, zalecamy włączenie semantycznego wyszukiwania następujących języków: angielski, francuski, hiszpański, portugalski, włoski, niemiecki, chiński (Zh), japoński, koreański, rosyjski, arabski
Zalecamy użycie komunikatu systemowego w celu poinformowania modelu, że dane są w innym języku. Na przykład:
*"*Jesteś asystentem sztucznej inteligencji zaprojektowanym w celu ułatwienia użytkownikom wyodrębniania informacji z pobranych dokumentów japońskich. Przed sformułowaniem odpowiedzi należy dokładnie zapoznać się z japońskimi dokumentami. Zapytanie użytkownika będzie znajdować się w języku japońskim i musisz odpowiedź również w języku japońskim".
Jeśli masz dokumenty w wielu językach, zalecamy utworzenie nowego indeksu dla każdego języka i połączenie ich oddzielnie z usługą Azure OpenAI.
Dane przesyłane strumieniowo
Żądanie przesyłania strumieniowego można wysłać przy użyciu parametru stream , co umożliwia wysyłanie i odbieranie danych przyrostowo bez oczekiwania na całą odpowiedź interfejsu API. Może to poprawić wydajność i środowisko użytkownika, szczególnie w przypadku dużych lub dynamicznych danych.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Historia konwersacji w celu uzyskania lepszych wyników
Podczas rozmowy z modelem udostępnienie historii czatu pomoże modelowi zwrócić wyniki o wyższej jakości. Nie musisz uwzględniać context właściwości komunikatów asystenta w żądaniach interfejsu API w celu uzyskania lepszej jakości odpowiedzi. Zobacz dokumentację referencyjną interfejsu API, aby zapoznać się z przykładami.
Wywoływanie funkcji
Niektóre modele usługi Azure OpenAI umożliwiają definiowanie narzędzi i tool_choice parametrów w celu włączenia wywoływania funkcji. Możesz skonfigurować wywoływanie funkcji za pomocą interfejsu API/chat/completionsREST. Jeśli zarówno źródła danych, jak tools i znajdują się w żądaniu, zostaną zastosowane następujące zasady.
- Jeśli
tool_choiceparametr tonone, narzędzia są ignorowane, a tylko źródła danych są używane do generowania odpowiedzi. - W przeciwnym razie, jeśli
tool_choicenie zostanie określony lub określony jakoautolub obiekt, źródła danych zostaną zignorowane, a odpowiedź będzie zawierać wybraną nazwę funkcji i argumenty, jeśli istnieją. Nawet jeśli model nie zdecyduje się na wybranie żadnej funkcji, źródła danych są nadal ignorowane.
Jeśli powyższe zasady nie spełniają Twoich potrzeb, rozważ inne opcje, na przykład: przepływ monitu lub interfejs API Asystentów.
Szacowanie użycia tokenu dla usługi Azure OpenAI na danych
Azure OpenAI On Your Data Retrieval Augmented Generation (RAG) to usługa, która korzysta zarówno z usługi wyszukiwania (takiej jak Azure AI Search) i generowania (modeli Azure OpenAI), aby umożliwić użytkownikom uzyskanie odpowiedzi na pytania na podstawie dostarczonych danych.
W ramach tego potoku RAG istnieją trzy kroki na wysokim poziomie:
Przeformatuj zapytanie użytkownika na listę intencji wyszukiwania. Jest to wykonywane przez wywołanie modelu z monitem zawierającym instrukcje, pytanie użytkownika i historię konwersacji. Wywołajmy ten monit o intencję.
Dla każdej intencji wiele fragmentów dokumentu jest pobieranych z usługi wyszukiwania. Po odfiltrowaniu nieistotnych fragmentów na podstawie określonego przez użytkownika progu ścisłej i ponownego korbowania/agregowania fragmentów na podstawie logiki wewnętrznej wybierana jest określona przez użytkownika liczba fragmentów dokumentu.
Te fragmenty dokumentu wraz z pytaniem użytkownika, historią konwersacji, informacjami o roli i instrukcjami są wysyłane do modelu w celu wygenerowania ostatecznej odpowiedzi modelu. Wywołajmy to w wierszu polecenia generowania.
W sumie do modelu są wykonywane dwa wywołania:
Do przetwarzania intencji: szacowanie tokenu dla monitu o intencję obejmuje te dla pytania użytkownika, historii konwersacji i instrukcje wysyłane do modelu na potrzeby generowania intencji.
W przypadku generowania odpowiedzi: oszacowanie tokenu dla monitu generowania zawiera te dotyczące pytania użytkownika, historii konwersacji, pobranej listy fragmentów dokumentów, informacji o rolach i instrukcji wysłanych do niego na potrzeby generowania.
Model wygenerował tokeny wyjściowe (zarówno intencje, jak i odpowiedź) muszą być brane pod uwagę w celu oszacowania łącznego tokenu. Sumowanie wszystkich czterech kolumn poniżej daje średnie tokeny całkowite używane do generowania odpowiedzi.
| Model | Liczba tokenów monitu generacji | Liczba tokenów monitu intencji | Liczba tokenów odpowiedzi | Liczba tokenów intencji |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
Powyższe liczby są oparte na testowaniu zestawu danych z:
- Konwersacje z 191 r.
- 250 pytań
- 10 średnich tokenów na pytanie
- 4 konwersacje zamienia się średnio na konwersację
I następujące parametry.
| Ustawienie | Wartość |
|---|---|
| Liczba pobranych dokumentów | 5 |
| Ścisłość | 3 |
| Rozmiar fragmentu | 1024 |
| Czy ograniczyć odpowiedzi na pozyskane dane? | Prawda |
Te oszacowania będą się różnić w zależności od wartości ustawionych dla powyższych parametrów. Jeśli na przykład liczba pobranych dokumentów jest ustawiona na 10, a wartość ścisłej wynosi 1, liczba tokenów wzrośnie. Jeśli zwrócone odpowiedzi nie są ograniczone do pozyskanych danych, istnieje mniej instrukcji podanych dla modelu, a liczba tokenów spadnie.
Szacunki zależą również od charakteru zadawanych dokumentów i pytań. Jeśli na przykład pytania są otwarte, odpowiedzi mogą być dłuższe. Podobnie dłuższy komunikat systemowy przyczyni się do dłuższego monitu, który zużywa więcej tokenów, a jeśli historia konwersacji będzie długa, monit będzie dłuższy.
| Model | Maksymalna liczba tokenów dla komunikatu systemowego |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
W powyższej tabeli przedstawiono maksymalną liczbę tokenów, których można użyć dla komunikatu systemowego. Aby wyświetlić maksymalne tokeny odpowiedzi modelu, zobacz artykuł modele. Ponadto następujące elementy używają również tokenów:
Meta monit: jeśli ograniczysz odpowiedzi z modelu do zawartości danych uziemienia (
inScope=Truew interfejsie API), maksymalna liczba tokenów jest wyższa. W przeciwnym razie (na przykład jeśliinScope=False) wartość maksymalna jest niższa. Ta liczba jest zmienna w zależności od długości tokenu pytania użytkownika i historii konwersacji. To oszacowanie obejmuje monit podstawowy i monit o ponowne zapisywanie zapytań w celu pobrania.Pytanie użytkownika i historia: zmienna, ale ograniczona do 2000 tokenów.
Pobrane dokumenty (fragmenty): liczba tokenów używanych przez pobrane fragmenty dokumentu zależy od wielu czynników. Górna granica jest liczbą pobranych fragmentów dokumentu pomnożonych przez rozmiar fragmentu. Zostanie on jednak obcięty na podstawie tokenów dostępnych tokenów dla określonego modelu używanego po zliczaniu pozostałych pól.
20% dostępnych tokenów jest zarezerwowanych dla odpowiedzi modelu. Pozostałe 80% dostępnych tokenów obejmuje meta monit, pytanie użytkownika i historię konwersacji oraz komunikat systemowy. Pozostały budżet tokenu jest używany przez fragmenty pobranego dokumentu.
Aby obliczyć liczbę tokenów używanych przez dane wejściowe (na przykład pytanie, komunikat systemowy/informacje o roli), użyj poniższego przykładu kodu.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Rozwiązywanie problemów
Aby rozwiązać problemy z nieudanymi operacjami, zawsze poszukaj błędów lub ostrzeżeń określonych w odpowiedzi interfejsu API lub portalu usługi Azure AI Foundry. Poniżej przedstawiono niektóre typowe błędy i ostrzeżenia:
Zadania pozyskiwania nie powiodły się
Problemy z ograniczeniami przydziału
Nie można utworzyć indeksu o nazwie X w usłudze Y. Przekroczono limit przydziału indeksu dla tej usługi. Najpierw należy usunąć nieużywane indeksy, dodać opóźnienie między żądaniami tworzenia indeksu lub uaktualnić usługę, aby uzyskać wyższe limity.
Przekroczono limit przydziału indeksatora standardowego X dla tej usługi. Obecnie masz indeksatory standardowe X. Najpierw należy usunąć nieużywane indeksatory, zmienić indeksator "executionMode" lub uaktualnić usługę, aby uzyskać wyższe limity.
Rozwiązanie:
Uaktualnij do wyższej warstwy cenowej lub usuń nieużywane zasoby.
Problemy z limitem czasu przetwarzania wstępnego
Nie można wykonać umiejętności, ponieważ żądanie internetowego interfejsu API nie powiodło się
Nie można wykonać umiejętności, ponieważ odpowiedź umiejętności internetowego interfejsu API jest nieprawidłowa
Rozwiązanie:
Podziel dokumenty wejściowe na mniejsze dokumenty i spróbuj ponownie.
Problemy z uprawnieniami
To żądanie nie jest autoryzowane do wykonania tej operacji
Rozwiązanie:
Oznacza to, że konto magazynu nie jest dostępne z podanymi poświadczeniami. W takim przypadku przejrzyj poświadczenia konta magazynu przekazane do interfejsu API i upewnij się, że konto magazynu nie jest ukryte za prywatnym punktem końcowym (jeśli prywatny punkt końcowy nie jest skonfigurowany dla tego zasobu).
Błędy 503 podczas wysyłania zapytań za pomocą usługi Azure AI Search
Każdy komunikat użytkownika może tłumaczyć się na wiele zapytań wyszukiwania, z których wszystkie są wysyłane do zasobu wyszukiwania równolegle. Może to spowodować zachowanie ograniczania przepustowości, gdy liczba replik wyszukiwania i partycji jest niska. Maksymalna liczba zapytań na sekundę, którą może obsłużyć pojedyncza partycja i pojedyncza replika, może nie być wystarczająca. W takim przypadku rozważ zwiększenie liczby replik i partycji lub dodanie logiki uśpienia/ponawiania prób w aplikacji. Aby uzyskać więcej informacji, zobacz dokumentację usługi Azure AI Search.
Obsługa regionalnej dostępności i modelu
| Region (Region) | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Australia Wschodnia | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Kanada Wschodnia | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| East US | ✅ | ✅ | ✅ | |||||
| Wschodnie stany USA 2 | ✅ | ✅ | ✅ | ✅ | ||||
| Francja Środkowa | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Japonia Wschodnia | ✅ | |||||||
| Północno-środkowe stany USA | ✅ | ✅ | ✅ | |||||
| Norwegia Wschodnia | ✅ | ✅ | ||||||
| South Central US | ✅ | ✅ | ||||||
| Indie Południowe | ✅ | ✅ | ||||||
| Szwecja Środkowa | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Szwajcaria Północna | ✅ | ✅ | ✅ | |||||
| Południowe Zjednoczone Królestwo | ✅ | ✅ | ✅ | ✅ | ||||
| Zachodnie stany USA | ✅ | ✅ | ✅ |
**Jest to implementacja tylko tekstowa
Jeśli zasób usługi Azure OpenAI znajduje się w innym regionie, nie będzie można używać usługi Azure OpenAI On Your Data.