Odporność i odzyskiwanie po awarii w usłudze Azure Web PubSub Service
Odporność i odzyskiwanie po awarii to typowe potrzeby systemów online. Usługa Azure Web PubSub Service gwarantuje już dostępność na poziomie 99,9%, ale nadal jest to usługa regionalna. W przypadku awarii całego regionu usługa ma kluczowe znaczenie dla dalszego przetwarzania komunikatów w czasie rzeczywistym w innym regionie.
W przypadku regionalnego odzyskiwania po awarii zalecamy następujące dwa podejścia:
- Włącz replikację geograficzną (łatwy sposób). Ta funkcja będzie obsługiwać automatyczne przełączanie w tryb failover w regionie. Po włączeniu pozostaje tylko jedno wystąpienie usługi Azure SignalR i nie wprowadzono żadnych zmian w kodzie. Sprawdź replikację geograficzną, aby uzyskać szczegółowe informacje.
- Korzystanie z wielu punktów końcowych. Dowiedz się, jak to zrobić w tym dokumencie
Architektura o wysokiej dostępności dla usługi Web PubSub
Istnieją dwa typowe wzorce korzystające z usługi Web PubSub:
- Jednym z nich jest wzorzec klient-serwer, który klienci wysyłają zdarzenia do serwera i serwera wypycha komunikaty do klientów.
- Innym jest wzorzec klient-klient, który klienci pub/sub komunikaty za pośrednictwem usługi Web PubSub do innych klientów.
W poniższych sekcjach opisano różne sposoby odzyskiwania po awarii dla tych dwóch wzorców
Architektura o wysokiej dostępności dla wzorca klient-serwer
Aby zapewnić odporność między regionami dla usługi Web PubSub, należy skonfigurować wiele wystąpień usługi w różnych regionach. Wtedy gdy jeden region nie działa, można użyć innych jako zapasowych.
Jedną z typowych konfiguracji scenariusza między regionami jest posiadanie dwóch (lub więcej) par wystąpień usługi Web PubSub i serwerów aplikacji.
Wewnątrz każdej pary serwer aplikacji i usługa Web PubSub znajdują się w tym samym regionie, a usługa Web PubSub ustawić program obsługi zdarzeń nadrzędnie na serwer aplikacji w tym samym regionie.
Aby lepiej zilustrować architekturę, wywołamy usługę Web PubSub jako usługę podstawową na serwerze aplikacji w tej samej parze. Usługa Web PubSub jest wywoływana w innych parach jako usługi pomocnicze na serwerze aplikacji.
Serwer aplikacji może używać interfejsu API sprawdzania kondycji usługi do wykrywania, czy jego podstawowe i pomocnicze usługi są w dobrej kondycji, czy nie. Na przykład w przypadku usługi Web PubSub o nazwie demopunkt końcowy https://demo.webpubsub.azure.com/api/health zwraca wartość 200, gdy usługa jest w dobrej kondycji. Serwer aplikacji może okresowo wywoływać punkty końcowe lub wywoływać punkty końcowe na żądanie, aby sprawdzić, czy punkty końcowe są w dobrej kondycji. Klienci protokołu WebSocket zazwyczaj negocjują ze swoim serwerem aplikacji najpierw, aby uzyskać adres URL łączący się z usługą Web PubSub, a aplikacja korzysta z tego kroku negocjacji w celu przełączenia klientów w tryb failover do innych usług pomocniczych w dobrej kondycji. Szczegółowe kroki, jak pokazano poniżej:
- Gdy klient negocjuje z serwerem aplikacji, serwer aplikacji powinien zwracać tylko podstawowe punkty końcowe usługi PubSub, więc w normalnym przypadku klienci łączą się tylko z podstawowymi punktami końcowymi.
- Gdy wystąpienie podstawowe nie działa, negocjacja POWINNA zwrócić pomocniczy punkt końcowy w dobrej kondycji, aby klient nadal mógł nawiązać połączenia, a klient łączy się z pomocniczym punktem końcowym.
- Gdy wystąpienie podstawowe jest uruchomione, negocjacja POWINNA zwrócić podstawowy punkt końcowy w dobrej kondycji, aby klienci mogli teraz nawiązać połączenie z podstawowym punktem końcowym
- Gdy serwer aplikacji rozgłaszakomunikaty, powinien emitować komunikaty do wszystkich punktów końcowych w dobrej kondycji , w tym zarówno podstawowych , jak i pomocniczych.
- Serwer aplikacji może zamknąć połączenia połączone z pomocniczymi punktami końcowymi, aby wymusić ponowne nawiązanie połączenia z podstawowym punktem końcowym w dobrej kondycji.
Dzięki tej topologii komunikat z jednego serwera może być nadal dostarczany do wszystkich klientów, ponieważ wszystkie serwery aplikacji i wystąpienia usługi Web PubSub są połączone.
Nie zintegrowaliśmy jeszcze strategii z zestawem SDK, więc na razie aplikacja musi zaimplementować tę strategię samodzielnie.
Podsumowując, co strona aplikacji musi zaimplementować:
- Kontrola kondycji. Aplikacja może sprawdzić, czy usługa jest w dobrej kondycji, korzystając z interfejsu API sprawdzania kondycji usługi okresowo w tle lub na żądanie dla każdego wywołania negocjowanego .
- Logika negocjowania. Aplikacja domyślnie zwraca podstawowy punkt końcowy w dobrej kondycji. Gdy podstawowy punkt końcowy nie działa, aplikacja zwraca pomocniczy punkt końcowy w dobrej kondycji.
- Logika emisji. Gdy komunikaty są wysyłane do wielu klientów, aplikacja musi upewnić się, że emituje komunikaty do wszystkich punktów końcowych w dobrej kondycji.
Poniżej przedstawiono diagram, który ilustruje taką topologię:
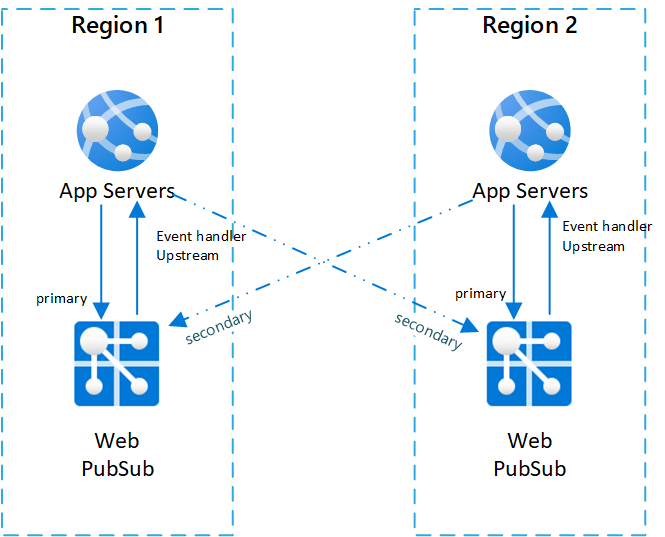
Sekwencja trybu failover i najlepsze rozwiązania
Teraz masz skonfigurowaną właściwą topologię systemu. Za każdym razem, gdy jedno wystąpienie usługi Web PubSub nie działa, ruch online będzie kierowany do innych wystąpień. Oto, co dzieje się w przypadku wyłączenia wystąpienia podstawowego (i jego odzyskania po pewnym czasie):
- Wystąpienie usługi podstawowej nie działa, wszyscy klienci połączeni z tym wystąpieniem zostaną porzuceni.
- Nowi klienci lub ponownie łączą klienta negocjowanego z serwerem aplikacji
- Serwer aplikacji wykrywa, że wystąpienie usługi podstawowej nie działa, a negocjacja zatrzymuje zwracanie tego punktu końcowego i rozpoczyna zwracanie pomocniczego punktu końcowego w dobrej kondycji.
- Klienci łączą się z wystąpieniem pomocniczym.
- Teraz wystąpienie pomocnicze obsługuje cały ruch w trybie online. Wszystkie komunikaty wysyłane przez serwer do klientów nadal mogą być dostarczane, ponieważ wystąpienie pomocnicze jest połączone ze wszystkimi serwerami aplikacji. Jednak komunikaty o zdarzeniach klienta na serwerze są wysyłane tylko do nadrzędnego serwera aplikacji w tym samym regionie.
- Po odzyskaniu wystąpienia podstawowego i powrocie do trybu online serwer aplikacji wykrywa, że wystąpienie podstawowe jest w dobrej kondycji. Negocjacje będą teraz zwracać podstawowy punkt końcowy i nowi klienci będą z powrotem łączyć się z nim. Jednak istniejący klienci nie zostaną porzuceni i będą nadal łączyć się z usługą pomocniczą, dopóki nie rozłączą się.
Na poniższych diagramach pokazano, jak odbywa się tryb failover:
Rys.1 Przed przejściem w tryb failover 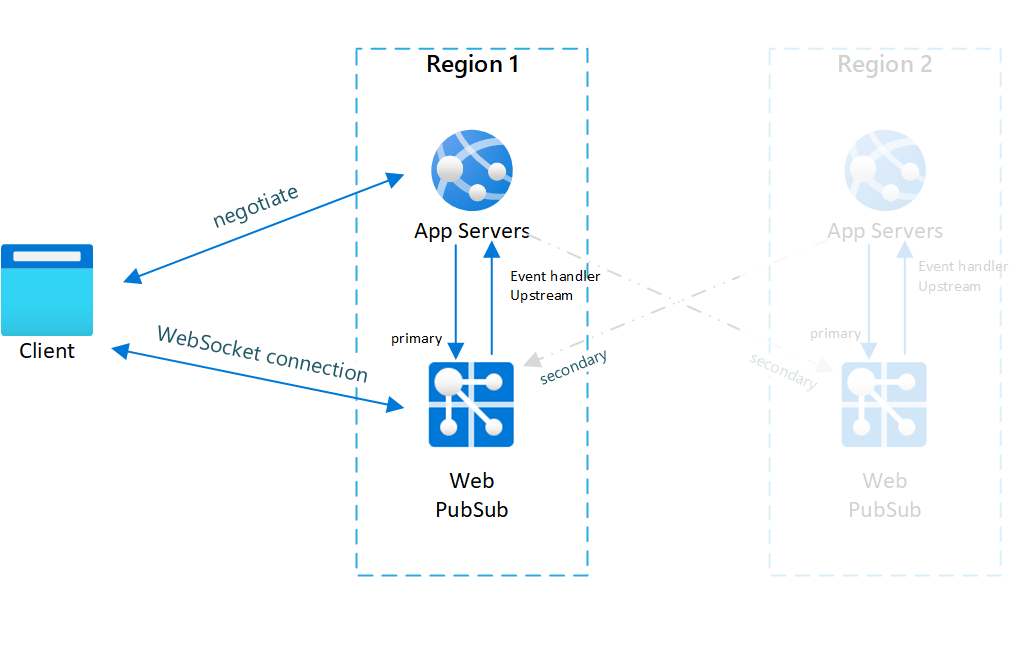
Rysunek 2 po przejściu w tryb failover 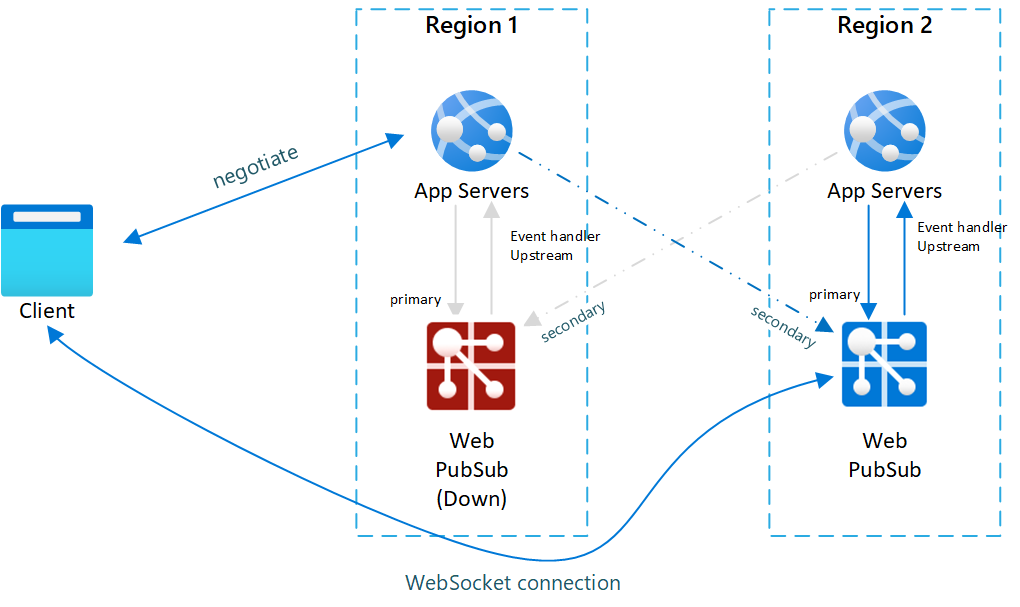
Rys.3 Krótki czas po odzyskaniu podstawowego 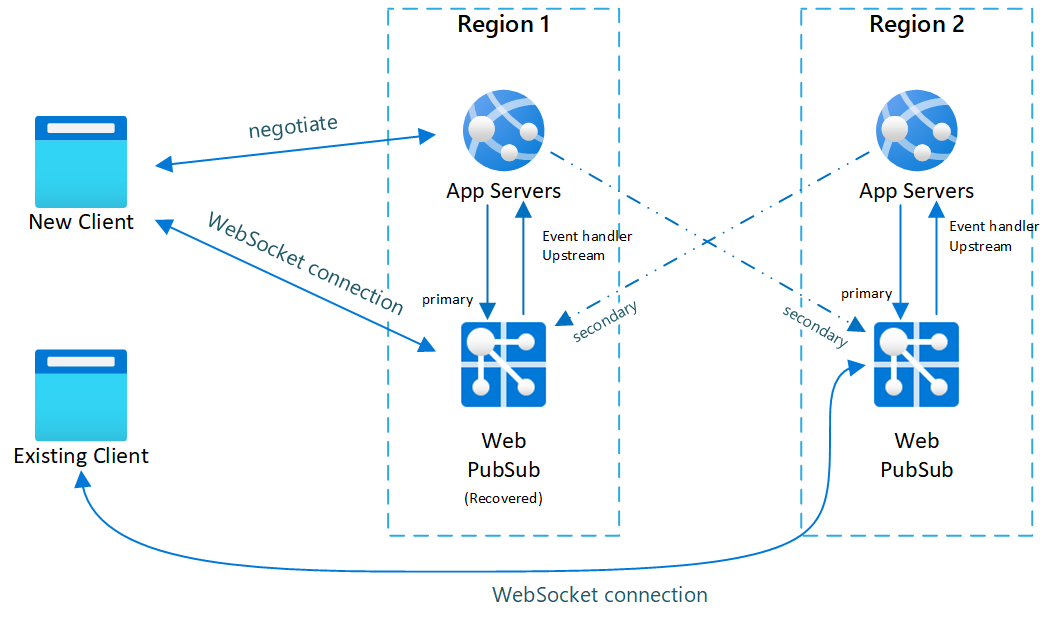
W normalnym przypadku tylko podstawowy serwer aplikacji i usługa Web PubSub mają ruch online (na niebiesko).
Po przejściu w tryb failover pomocniczy serwer aplikacji i usługa Web PubSub również stają się aktywne. Po powrocie podstawowej usługi Web PubSub do trybu online nowi klienci będą łączyć się z podstawowymi usługami Web PubSub. Lecz istniejący klienci nadal będą łączyć się z wystąpieniem pomocniczym, więc oba wystąpienia będą obsługiwać ruch.
Gdy wszyscy istniejący klienci rozłączą się, system wróci do normalnego stanu (Rys. 1).
Architekturę wysokiej dostępności z wieloma regionami można zaimplementować za pomocą dwóch głównych wzorców:
- Pierwszym z nich jest posiadanie pary serwera aplikacji i wystąpienia usługi Web PubSub biorącego cały ruch online i mieć inną parę jako kopię zapasową (nazywaną aktywną/pasywną, zilustrowaną na rysunku 1).
- Drugi z nich ma mieć dwie (lub więcej) pary serwerów aplikacji i wystąpień usługi Web PubSub, z których każdy bierze udział w ruchu online i służy jako kopia zapasowa dla innych par (nazywanych aktywnym/aktywnym, podobnym do Fig.3).
Usługa Web PubSub może obsługiwać oba wzorce. Główną różnicą jest sposób implementowania serwerów aplikacji. Jeśli serwery aplikacji są aktywne/pasywne, usługa Web PubSub będzie również aktywna/pasywna (ponieważ podstawowy serwer aplikacji zwraca tylko jego podstawowe wystąpienie usługi Web PubSub). Jeśli serwery aplikacji są aktywne/aktywne, usługa Web PubSub będzie również aktywna/aktywna (ponieważ wszystkie serwery aplikacji zwracają własne podstawowe wystąpienia usługi Web PubSub, więc wszystkie z nich mogą uzyskać ruch).
Należy zauważyć, że niezależnie od tego, które wzorce należy użyć, musisz połączyć każde wystąpienie usługi PubSub z serwerem aplikacji jako główną rolą.
Ponadto ze względu na charakter połączenia protokołu WebSocket (jest to długie połączenie), klienci będą doświadczać przerywania połączeń w przypadku awarii i przejścia w tryb failover. Takie przypadki należy obsługiwać po stronie klienta, aby były przezroczyste dla użytkowników końcowych. Na przykład należy nawiązać ponownie połączenie po zamknięciu połączenia.
Architektura o wysokiej dostępności dla wzorca klient-klient
W przypadku wzorca klient-klient obecnie nie jest jeszcze możliwe obsługę odzyskiwania po awarii bez awarii przy użyciu wielu wystąpień. Jeśli masz wymagania dotyczące wysokiej dostępności, rozważ użycie replikacji geograficznej.
Jak przetestować tryb failover
Wykonaj kroki, aby wyzwolić tryb failover:
- Na karcie Sieć zasobu podstawowego w portalu wyłącz dostęp do sieci publicznej. Jeśli zasób ma włączoną sieć prywatną, użyj reguł kontroli dostępu, aby odmówić całego ruchu.
- Uruchom ponownie zasób podstawowy.
Następne kroki
W tym artykule przedstawiono sposób konfigurowania aplikacji w celu uzyskania odporności usługi Web PubSub.
Użyj tych zasobów, aby rozpocząć tworzenie własnej aplikacji: