Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
W tym artykule opisano funkcje optymalizacji wydajności procesu kopiowania, które można wykorzystać w potokach Azure Data Factory i Synapse.
Konfigurowanie funkcji wydajności za pomocą interfejsu użytkownika
Po wybraniu działanie Kopiuj na kanwie edytora potoków i wybraniu karty Ustawienia w obszarze konfiguracji działania poniżej kanwy zostaną wyświetlone opcje konfigurowania wszystkich funkcji wydajności opisanych poniżej.
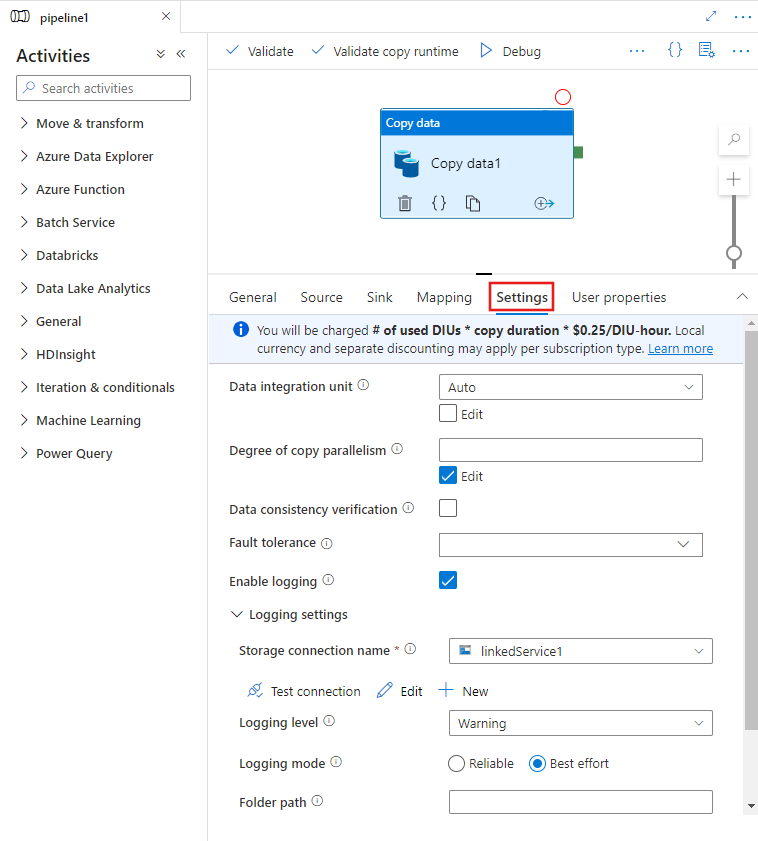
Jednostki integracji danych
Jednostka Integracji Danych to miara, która reprezentuje moc (kombinację zasobów procesora CPU, pamięci i alokacji zasobów sieciowych) pojedynczej jednostki w usłudze. Jednostka integracji danych dotyczy tylko środowiska Azure Integration Runtime, ale nie self-hosted Integration Runtime.
Dozwolone jednostki DIU do uruchomienia zadania kopiowania wynoszą od 4 do 256. Jeśli nie zostanie określone lub wybierzesz opcję "Automatycznie" w interfejsie użytkownika, usługa dynamicznie stosuje optymalne ustawienie DIU na podstawie pary źródło-ujście i schematu danych. W poniższej tabeli wymieniono obsługiwane zakresy jednostek DIU i domyślne zachowanie w różnych scenariuszach kopiowania:
| Scenariusz kopiowania | Obsługiwany zakres jednostek DIU | Domyślne DIU określone przez usługę |
|---|---|---|
| Między magazynami plików |
-
Skopiuj z lub do pojedynczego pliku: 4 - Kopiuj z i do wielu plików: 4–256 w zależności od liczby i rozmiaru plików Jeśli na przykład skopiujesz dane z folderu zawierającego 4 duże pliki i zdecydujesz się utrzymać hierarchię, maksymalna efektywna jednostka DIU wynosi 16; jeśli zdecydujesz się scalić pliki, maksymalna efektywna jednostka DIU wynosi 4. |
Od 4 do 32 w zależności od liczby i rozmiaru plików |
| Z magazynu plików do magazynu bez plików |
-
Kopiowanie z pojedynczego pliku: 4 - Kopiowanie z wielu plików: 4–256 w zależności od liczby i rozmiaru plików Jeśli na przykład skopiujesz dane z folderu z 4 dużymi plikami, maksymalna efektywna diu wynosi 16. |
-
Copy do Azure SQL Database lub Azure Cosmos DB: od 4 do 16 w zależności od progu ujścia (DTU/RU) i wzorca pliku źródłowego - Copy do Azure Synapse Analytics za pomocą instrukcji PolyBase lub COPY: 2 - Inny scenariusz: 4 |
| Z magazynu niezwiązanego z plikami do magazynu plików |
-
Kopia z partycjonowanych repozytoriów danych (w tym Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server i Teradata): 4–256 przy zapisie do folderu i 4 przy zapisie do jednego pliku. Uwaga: Każda partycja danych źródłowych może używać maksymalnie 4 DIU. - Inne scenariusze: 4 |
-
Kopiowanie z interfejsu REST lub HTTP: 1 - Kopiowanie z usługi Amazon Redshift przy użyciu funkcji UNLOAD: 4 - Inny scenariusz: 4 |
| Między magazynami bezplikowymi |
-
Kopia z partycjonowanych repozytoriów danych (w tym Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server i Teradata): 4–256 przy zapisie do folderu i 4 przy zapisie do jednego pliku. Uwaga: Każda partycja danych źródłowych może używać maksymalnie 4 DIU. - Inne scenariusze: 4 |
-
Kopiowanie z interfejsu REST lub HTTP: 1 - Inny scenariusz: 4 |
Jednostki DIU używane dla każdego kopiowania są widoczne w widoku monitorowania działania kopiowania lub wyniku działania. Aby uzyskać więcej informacji, zobacz działanie Kopiuj monitoring. Aby zastąpić tę wartość domyślną, określ wartość właściwości dataIntegrationUnits w następujący sposób. Rzeczywista liczba jednostek DIU używanych przez operację kopiowania w czasie wykonywania jest równa lub mniejsza niż skonfigurowana wartość w zależności od wzorca danych.
Zostaniesz obciążony opłatą za liczbę używanych jednostek DIU * czas trwania kopiowania w godzinach * cena jednostkowa/DIU-godzina. Zobacz bieżące ceny tutaj. Lokalna waluta i oddzielne rabaty mogą być stosowane na typ subskrypcji.
Przykład:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Skalowalność samodzielnie hostowanego środowiska uruchomieniowego integracji
Jeśli chcesz uzyskać większą przepływność, możesz skalować w górę lub w poziomie własne środowisko Self-hosted IR.
- Jeśli CPU i dostępna pamięć w węźle Własnego środowiska IR nie są w pełni wykorzystywane, ale wykonywanie współbieżnych zadań osiąga limit, należy zwiększyć skalę przez zwiększenie liczby współbieżnych zadań, które można uruchomić w węźle. Aby uzyskać instrukcje, zobacz tutaj .
- Jeśli natomiast procesor CPU jest przeciążony na węźle Samodzielnie Hostowanego IR lub dostępna pamięć jest niska, możesz dodać nowy węzeł, aby skuteczniej rozłożyć obciążenie między wieloma węzłami. Aby uzyskać instrukcje, zobacz tutaj .
Pamiętaj, że w następujących scenariuszach jedna operacja kopiowania może korzystać z wielu samodzielnie hostowanych węzłów IR.
- Skopiuj dane z repozytoriów opartych na plikach, zależnie od liczby i rozmiarów plików.
- Kopiowanie danych z magazynu danych z włączoną opcją partycji (w tym Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server i Teradata), w zależności od liczby partycji danych.
Kopiowanie równoległe
Możesz ustawić kopię równoległą (właściwość parallelCopies w definicji JSON zadania kopiowania lub ustawienie Degree of parallelism na karcie Ustawienia właściwości zadania kopiowania w interfejsie użytkownika) dla zadania kopiowania, aby określić równoległość, jakiej chcesz użyć. Jakość tę można traktować jako maksymalną liczbę wątków w aktywności kopiowania, które odczytują ze źródła lub zapisują w magazynach docelowych równolegle.
Kopia równoległa jest ortogonalna do jednostek integracji danych lub samodzielnie hostowanych węzłów IR. Jest on liowany we wszystkich węzłach jednostki DIU lub własnego środowiska IR.
Dla każdej operacji kopiowania usługa domyślnie dynamicznie stosuje optymalne ustawienie kopiowania równoległego na podstawie pary źródło-ujście i schematu danych.
Wskazówka
Domyślne zachowanie kopiowania równoległego zwykle zapewnia najlepszą przepływność, która jest automatycznie określana przez usługę na podstawie pary ujścia źródła, wzorca danych i liczby jednostek DIU lub liczby procesorów CPU/pamięci/węzła własnego środowiska IR. Zapoznaj się z artykułem Rozwiązywanie problemów z wydajnością operacji kopiowania o tym, kiedy dostosować kopiowanie równoległe.
W poniższej tabeli wymieniono zachowanie kopiowania równoległego:
| Scenariusz kopiowania | Zachowanie kopiowania równoległego |
|---|---|
| Między magazynami plików |
parallelCopies określa równoległość na poziomie pliku. Fragmentowanie w każdym pliku odbywa się automatycznie i w sposób przezroczysty. Zaprojektowano go tak, aby używać najlepszego odpowiedniego rozmiaru fragmentu dla danego typu magazynu danych w celu równoległego ładowania danych. Rzeczywista liczba równoległych kopii używanych w czasie wykonywania kopiowania wynosi nie więcej niż liczba posiadanych plików. Jeśli zachowanie kopiowania to mergeFile do ujścia pliku, działanie kopiowania nie może korzystać z równoległości na poziomie plików. |
| Z magazynu plików do magazynu bez plików | — Podczas kopiowania danych do Azure SQL Database lub Azure Cosmos DB, domyślna kopia równoległa również zależy od poziomu docelowego (liczby jednostek DTU/RU). — Podczas kopiowania danych do tabeli Azure domyślna kopia równoległa to 4. |
| Z magazynu niezwiązanego z plikami do magazynu plików | — Podczas kopiowania danych z magazynu danych z włączoną opcją partycji (w tym Azure SQL Database, Azure SQL Managed InstanceAzure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server and Teradata), domyślna kopia równoległa to 4. Rzeczywista liczba równoległych kopii używanych w czasie wykonywania kopiowania wynosi nie więcej niż liczba posiadanych partycji danych. W przypadku korzystania z hostowanego lokalnie środowiska uruchomieniowego Integration Runtime i kopiowania danych do usługi Azure Blob/ADLS Gen2, należy pamiętać, że maksymalna efektywna liczba równoległych kopii wynosi 4 lub 5 na węzeł IR. — W przypadku innych scenariuszy kopiowanie równoległe nie działa. Nawet jeśli jest określona równoległość, nie jest stosowana. |
| Między magazynami bezplikowymi | — Podczas kopiowania danych do Azure SQL Database lub Azure Cosmos DB, domyślna kopia równoległa również zależy od poziomu docelowego (liczby jednostek DTU/RU). — Podczas kopiowania danych z magazynu danych z włączoną opcją partycji (w tym Azure SQL Database, Azure SQL Managed InstanceAzure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server and Teradata), domyślna kopia równoległa to 4. — Podczas kopiowania danych do tabeli Azure domyślna kopia równoległa to 4. |
Aby kontrolować obciążenie maszyn hostujących magazyny danych lub dostosować wydajność kopiowania, możesz zastąpić wartość domyślną i określić wartość właściwości parallelCopies . Wartość musi być liczbą całkowitą większą lub równą 1. W czasie wykonywania w celu uzyskania najlepszej wydajności działanie kopiowania używa wartości mniejszej niż lub równej ustawionej wartości.
Kiedy określasz wartość właściwości parallelCopies, weź pod uwagę wzrost obciążenia na repozytoria wejściowych i wyjściowych danych. Należy również rozważyć zwiększenie obciążenia samodzielnie hostowanego środowiska Integration Runtime, jeśli działanie kopiowania jest nim zasilane. Ten wzrost obciążenia występuje szczególnie w przypadku wielu działań lub współbieżnych uruchomień tych samych działań, które są uruchamiane względem tego samego magazynu danych. Jeśli zauważysz, że magazyn danych lub własne środowisko Integration Runtime jest przeciążone obciążeniem, zmniejsz parallelCopies wartość, aby zmniejszyć obciążenie.
Przykład:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
Kopiowanie etapowe
Podczas kopiowania danych ze źródłowego magazynu danych do docelowego magazynu danych możesz wybrać użycie usługi Azure Blob Storage lub Azure Data Lake Storage Gen2 jako magazynu tymczasowego. Środowisko przejściowe jest szczególnie przydatne w następujących przypadkach:
- Chcesz pozyskiwać dane z różnych magazynów danych do Azure Synapse Analytics za pośrednictwem technologii PolyBase, kopiować dane z/do usługi Snowflake lub pozyskiwać dane z usługi Amazon Redshift/HDFS wydajnie. Dowiedz się więcej na stronie:
- Nie chcesz otwierać portów innych niż port 80 i port 443 w zaporze ze względu na firmowe zasady IT. Na przykład podczas kopiowania danych z lokalnego magazynu danych do Azure SQL Database lub Azure Synapse Analytics należy aktywować komunikację wychodzącą TCP na porcie 1433 zarówno dla zapory Windows, jak i zapory firmowej. W tym scenariuszu kopiowanie etapowe może korzystać z lokalnego środowiska uruchomieniowego integracji, aby najpierw skopiować dane do magazynu przejściowego za pośrednictwem protokołu HTTP lub HTTPS na porcie 443, a następnie załadować dane z magazynu przejściowego do usługi SQL Database lub Azure Synapse Analytics. W tym przepływie nie trzeba włączać portu 1433.
- Czasami wykonanie hybrydowego przenoszenia danych (czyli skopiowanie z lokalnego repozytorium danych do repozytorium danych w chmurze) za pośrednictwem powolnego połączenia sieciowego. Aby zwiększyć wydajność, można użyć kopiowania etapowego w celu skompresowania danych lokalnych, dzięki czemu przeniesienie danych do przejściowego magazynu danych w chmurze zajmuje mniej czasu. Następnie można dekompresować dane w magazynie przejściowym przed załadowaniem do docelowego magazynu danych.
Jak działa kopiowanie etapowe
Po aktywowaniu funkcji inscenizacji dane są najpierw kopiowane z magazynu danych źródłowych do przechowalni inscenizacyjnej (możesz użyć własnego Azure Blob lub Azure Data Lake Storage Gen2). Następnie dane są kopiowane z magazynu pośredniego do docelowego magazynu danych. Operacja kopiowania automatycznie zarządza przepływem dwuetapowym i czyści tymczasowe dane z magazynu przejściowego po zakończeniu transferu danych.

Musisz przyznać uprawnienia do usuwania dla Azure Data Factory w swoim magazynie przejściowym, aby tymczasowe dane mogły zostać usunięte po wykonaniu działania kopiowania.
Kiedy aktywujesz przenoszenie danych za pomocą magazynu przejściowego, możesz określić, czy dane mają być skompresowane przed przeniesieniem ze źródłowego magazynu danych do magazynu przejściowego, a następnie zdekompresowane przed przeniesieniem danych z magazynu tymczasowego lub przejściowego do docelowego magazynu danych.
Obecnie nie można kopiować danych między dwoma magazynami danych połączonymi za pomocą różnych własnych integratorów IR, ani z kopią etapową, ani bez niej. W takim scenariuszu można skonfigurować dwa wyraźnie łańcuchowe zadania kopiowania w celu skopiowania ze źródła do magazynu pośredniego, a następnie z magazynu pośredniego do miejsca docelowego.
Konfigurowanie
Skonfiguruj ustawienie enableStaging w działaniu kopiowania, aby określić, czy dane mają być przygotowane w magazynie przed załadowaniem ich do docelowego magazynu danych. Po ustawieniu enableStaging na wartość TRUE, określasz dodatkowe właściwości wymienione w poniższej tabeli.
| Właściwości | Opis | Domyślna wartość | Wymagane |
|---|---|---|---|
| enableStaging | Określ, czy chcesz skopiować dane za pośrednictwem przechowywania pośredniego tymczasowego. | Fałsz | Nie. |
| linkedServiceName | Określ nazwę Azure Blob Storage lub Azure Data Lake Storage Gen2 połączonej usługi, która odnosi się do wystąpienia magazynu używanego jako tymczasowy magazyn przejściowy. | Nie dotyczy | Tak, gdy enableStaging jest ustawione na TRUE |
| ścieżka | Określ ścieżkę, która ma zawierać dane etapowe. Jeśli nie podasz ścieżki, usługa utworzy kontener do przechowywania danych tymczasowych. | Nie dotyczy | Nie (Tak, gdy określono łącznik storageIntegration w Snowflake) |
| włączKompresję | Określa, czy dane mają być skompresowane przed skopiowanie ich do miejsca docelowego. To ustawienie zmniejsza ilość przesyłanych danych. | Fałsz | Nie. |
Uwaga
Jeśli używasz kopiowania etapowego z włączoną kompresją, uwierzytelnianie tożsamości usługi lub MSI dla usługi połączenia obiektów blob dla etapu przejściowego nie jest obsługiwane.
Oto przykładowa definicja działania kopiowania z właściwościami opisanymi w poprzedniej tabeli:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Wpływ na rozliczenia przy kopiowaniu etapowym
Opłaty są naliczane na podstawie dwóch kroków: czasu trwania kopiowania i typu kopiowania.
- Podczas używania stagingu podczas kopiowania w chmurze, kopiującego dane z magazynu danych w chmurze do innego magazynu danych w chmurze, oba etapy obsługiwane przez środowisko uruchomieniowe Azure Integration są rozliczane na podstawie [łącznego czasu trwania kopiowania dla kroku 1 i kroku 2] x [ceny jednostkowej kopiowania w chmurze].
- pl-PL: W przypadku korzystania z etapowania podczas kopiowania hybrydowego, czyli kopiowanie danych z lokalnego magazynu danych do magazynu danych w chmurze, jeden etap z wykorzystaniem własnego Integration Runtime, naliczana jest opłata za [czas trwania kopiowania hybrydowego] x [cena jednostkowa kopiowania hybrydowego] + [czas trwania kopiowania w chmurze] x [cena jednostkowa kopiowania w chmurze].
Powiązana zawartość
Zobacz inne artykuły dotyczące działań kopiowania:
- Omówienie działania kopiowania
- Przewodnik dotyczący wydajności i skalowalności dla aktywności kopiowania
- Rozwiązywanie problemów z wydajnością operacji kopiowania
- Użyj Azure Data Factory, aby przeprowadzić migrację danych z jeziora danych lub hurtowni danych do Azure
- Migracja danych z usługi Amazon S3 do Azure Storage