Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
W tym przewodniku Szybki start opisano sposób tworzenia Azure Data Factory przy użyciu programu PowerShell. Potok, który tworzysz w tej fabryce danych, kopiuje dane z jednego folderu do drugiego w magazynie obiektów blob Azure. Aby zapoznać się z samouczkiem dotyczącym przekształcania danych przy użyciu Azure Data Factory, zapoznaj się z Samouczek: Przekształcanie danych przy użyciu platformy Spark.
Uwaga
Ten artykuł nie zawiera szczegółowego wprowadzenia usługi Data Factory. Aby zapoznać się z usługą Azure Data Factory, zobacz Introduction to Azure Data Factory.
Wymagania wstępne
subskrypcja Azure
Jeśli nie masz subskrypcji Azure, przed rozpoczęciem utwórz konto free.
roli Azure
Aby utworzyć wystąpienia usługi Data Factory, konto użytkownika używane do logowania się do Azure musi być członkiem roli
Aby utworzyć i zarządzać zasobami podrzędnymi w usłudze Data Factory, w tym zestawami danych, połączonymi usługami, potokami, wyzwalaczami i środowiskami Integration Runtime, należy spełnić następujące wymagania:
- Aby utworzyć zasoby podrzędne i zarządzać nimi w portalu Azure, musisz należeć do roli współautora Data Factory na poziomie grupy zasobów lub wyższym.
- W przypadku tworzenia i zarządzania zasobami podrzędnymi za pomocą programu PowerShell lub zestawu SDK rola współpracownika na poziomie zasobów lub wyższym jest wystarczająca.
Aby uzyskać przykładowe instrukcje dotyczące dodawania użytkownika do roli, zobacz artykuł Add roles (Dodawanie ról).
Aby uzyskać więcej informacji, zobacz następujące artykuły:
konto Azure Storage
W tej sekcji typu Quickstart użyjesz konta magazynowego Azure ogólnego przeznaczenia (w szczególności usługi Blob Storage) jako źródło i miejsce docelowe magazynów danych. Jeśli nie masz konta Azure Storage do ogólnych zastosowań, zobacz Tworzenie konta magazynu, aby je utworzyć.
Pobierz nazwę konta magazynu
Potrzebujesz nazwy swojego konta Azure Storage na ten szybki start. Poniższa procedura zawiera kroki, aby uzyskać nazwę swojego konta magazynowego:
- W przeglądarce internetowej przejdź do portalu Azure i zaloguj się przy użyciu nazwy użytkownika i hasła Azure.
- W menu portalu Azure wybierz pozycję Wszystkie usługi a następnie wybierz pozycję Storage>Konto magazynu. Możesz również wyszukać i wybrać Konta magazynowe na dowolnej stronie.
- Na stronie Konta magazynu przefiltruj swoje konto magazynu (w razie potrzeby), a następnie wybierz swoje konto magazynu.
Możesz również wyszukać i wybrać Konta magazynowe na dowolnej stronie.
Utwórz kontener blob
W tej sekcji utworzysz kontener obiektów blob o nazwie adftutorial w usłudze Azure Blob Storage.
Na stronie konta magazynu wybierz Przegląd>Kontenery.
< > wybierz pozycję Kontener.
W oknie dialogowym Nowy kontener wprowadź jako nazwę adftutorial, a następnie wybierz przycisk OK. Stronę <Nazwa konta> - Kontenery zaktualizowano w celu uwzględnienia adftutorial na liście kontenerów.
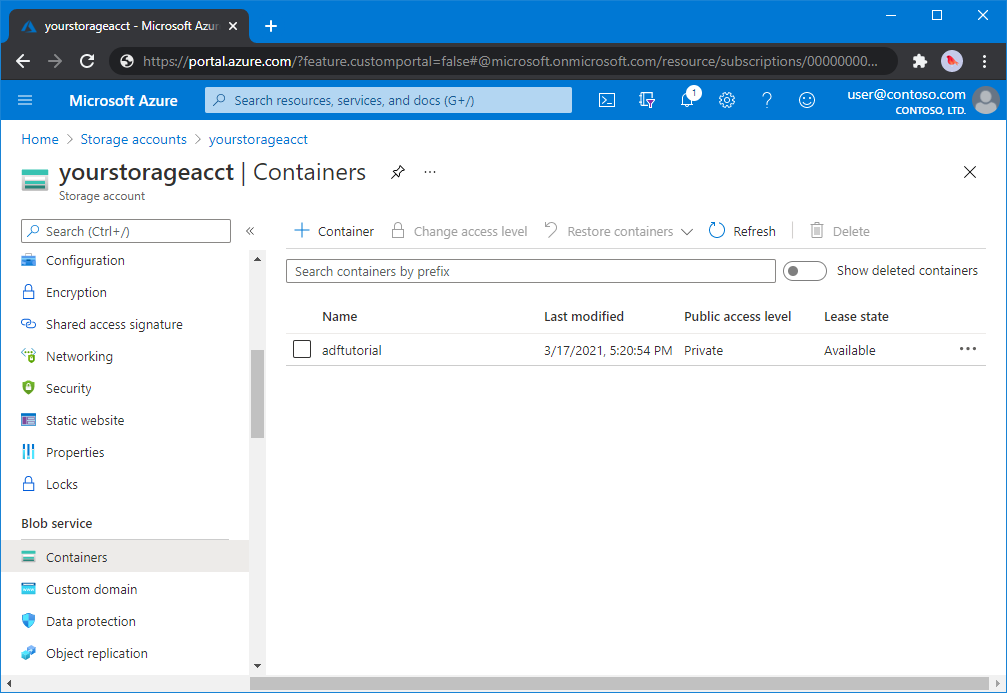
Dodaj folder wejściowy i plik dla kontenera blob
W tej sekcji utworzysz folder o nazwie input w utworzonym kontenerze, a następnie przekażesz przykładowy plik do folderu wejściowego. Przed rozpoczęciem otwórz edytor tekstów, taki jak Notatnik, i utwórz plik o nazwie emp.txt z następującą zawartością:
John, Doe
Jane, Doe
Zapisz plik w folderze C:\ADFv2QuickStartPSH . (Jeśli folder jeszcze nie istnieje, utwórz go). Następnie wróć do portalu Azure i wykonaj następujące kroki:
<Na stronie Nazwa konta> - Kontenery, na której skończyłeś, wybierz adftutorial ze zaktualizowanej listy kontenerów.
- Jeśli okno zostało zamknięte lub zostało otwarte na innej stronie, zaloguj się ponownie do portalu Azure.
- W menu portalu Azure wybierz pozycję Wszystkie usługi a następnie wybierz pozycję Storage>Konto magazynu. Możesz również wyszukać i wybrać Konta magazynowe na dowolnej stronie.
- Wybierz konto magazynu, a następnie wybierz Containers>adftutorial.
Na pasku narzędzi strony kontenera adftutorial wybierz pozycję Przekaż.
Na stronie Przekazywanie obiektu blob wybierz pole Pliki, a następnie przejdź do pliku emp.txt i go wybierz.
Rozszerz nagłówek Zaawansowane. Strona jest teraz wyświetlana w następujący sposób:
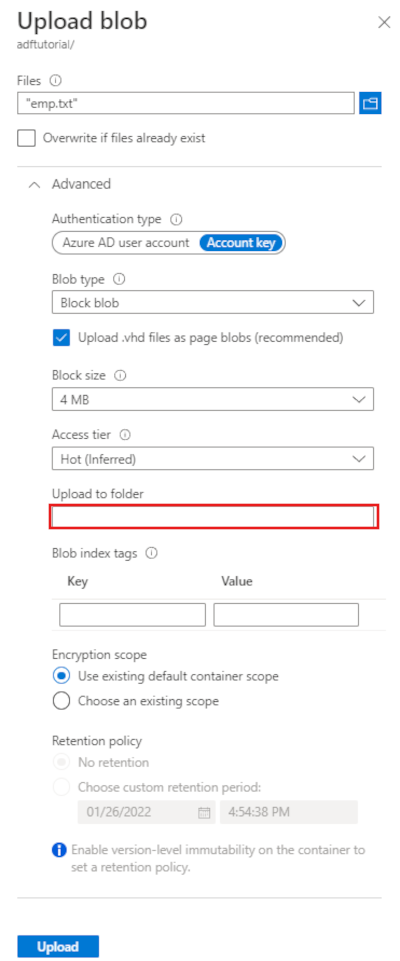
W polu Przekaż do folderu wprowadź dane wejściowe.
Wybierz przycisk Przekaż. Na liście powinien pojawić się plik emp.txt oraz stan przesyłania.
Wybierz ikonę Zamknij (znak X), aby zamknąć stronę Przekaż obiekt blob.
Pozostaw otwartą stronę kontenera adftutorial . Użyj tego do weryfikowania danych wyjściowych na końcu tego szybkiego startu.
Azure PowerShell
Uwaga
Zalecamy użycie modułu Azure Az programu PowerShell do interakcji z Azure. Aby rozpocząć, zobacz Install Azure PowerShell. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az programu PowerShell, zobacz Migrate Azure PowerShell z modułu AzureRM do modułu Az.
Zainstaluj najnowsze moduły Azure PowerShell, postępując zgodnie z instrukcjami w Jak zainstalować i skonfigurować Azure PowerShell.
Ostrzeżenie
Jeśli nie używasz najnowszych wersji modułu Programu PowerShell i usługi Data Factory, możesz napotkać błędy deserializacji podczas uruchamiania poleceń.
Logowanie się do programu PowerShell
Uruchom program PowerShell na maszynie. Nie zamykaj programu PowerShell aż do końca tego szybkiego startu. Jeśli go zamkniesz i otworzysz ponownie, musisz uruchomić te polecenia jeszcze raz.
Uruchom następujące polecenie i wprowadź tę samą Azure nazwę użytkownika i hasło, których używasz do logowania się w portalu Azure:
Connect-AzAccountUruchom poniższe polecenie, aby wyświetlić wszystkie subskrypcje dla tego konta:
Get-AzSubscriptionJeśli z kontem jest skojarzonych wiele subskrypcji, uruchom poniższe polecenie, aby wybrać subskrypcję, z którą chcesz pracować. Zastąp SubscriptionId identyfikatorem subskrypcji Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Tworzenie fabryki danych
Zdefiniuj zmienną nazwy grupy zasobów, której użyjesz później w poleceniach programu PowerShell. Skopiuj następujący tekst polecenia do programu PowerShell, określ nazwę grupy zasobów Azure w cudzysłowach podwójnych, a później uruchom polecenie. Na przykład:
"ADFQuickStartRG".$resourceGroupName = "ADFQuickStartRG";Jeśli grupa zasobów już istnieje, możesz nie chcieć jej zastąpić. Przypisz inną wartość do zmiennej
$ResourceGroupNamei ponownie uruchom polecenie.Aby utworzyć grupę zasobów Azure, uruchom następujące polecenie:
$ResGrp = New-AzResourceGroup $resourceGroupName -location 'East US'Jeśli grupa zasobów już istnieje, możesz nie chcieć jej zastąpić. Przypisz inną wartość do zmiennej
$ResourceGroupNamei ponownie uruchom polecenie.Zdefiniuj zmienną nazwy fabryki danych.
Ważne
Zaktualizuj nazwę fabryki danych, aby była unikatowa w skali globalnej, na przykład ADFTutorialFactorySP1127.
$dataFactoryName = "ADFQuickStartFactory";Aby utworzyć fabrykę danych, uruchom następujące polecenie cmdlet Set-AzDataFactoryV2 , używając właściwości Location i ResourceGroupName ze zmiennej $ResGrp:
$DataFactory = Set-AzDataFactoryV2 -ResourceGroupName $ResGrp.ResourceGroupName ` -Location $ResGrp.Location -Name $dataFactoryName
Należy uwzględnić następujące informacje:
Nazwa Azure Data Factory musi być globalnie unikatowa. Jeśli zostanie wyświetlony następujący błąd, zmień nazwę i spróbuj ponownie.
The specified Data Factory name 'ADFv2QuickStartDataFactory' is already in use. Data Factory names must be globally unique.Aby utworzyć wystąpienia usługi Data Factory, konto użytkownika używane do logowania się do Azure musi być członkiem contributor, właściciela roli lub administratorem subskrypcji Azure.
Aby uzyskać listę regionów Azure, w których usługa Data Factory jest obecnie dostępna, wybierz regiony, które Cię interesują na następującej stronie, a następnie rozwiń węzeł Analytics aby zlokalizować Data Factory: Products available by region. Magazyny danych (Azure Storage, Azure SQL Database itp.) i obliczenia (HDInsight itp.) używane przez fabrykę danych mogą znajdować się w innych regionach.
Tworzenie usługi połączonej
Utwórz połączone usługi w fabryce danych w celu połączenia swoich magazynów danych i usług obliczeniowych z fabryką danych. W tym przewodniku szybkiego startu utworzysz połączoną usługę Azure Storage używaną zarówno jako źródło, jak i ujście danych. Połączona usługa ma informacje o połączeniu, których usługa Data Factory używa w środowisku uruchomieniowym do nawiązywania z nią połączenia.
Napiwek
W tym przewodniku Szybki start użyjesz klucza konta jako typu uwierzytelniania dla magazynu danych, ale w razie potrzeby możesz wybrać inne obsługiwane metody uwierzytelniania: SAS URI, *tożsamość usługi i tożsamość zarządzana. Aby uzyskać szczegółowe informacje, zapoznaj się z odpowiednimi sekcjami w tym artykule . Aby bezpiecznie przechowywać sekrety magazynów danych, zaleca się korzystanie z Azure Key Vault. Zapoznaj się z tym artykułem, aby uzyskać szczegółowe ilustracje.
Utwórz plik JSON o nazwie AzureStorageLinkedService.json w folderze C:\ADFv2QuickStartPSH o następującej zawartości: (Utwórz folder ADFv2QuickStartPSH, jeśli jeszcze nie istnieje).
Ważne
Przed zapisaniem pliku zastąp <accountName> i <accountKey> nazwą i kluczem konta magazynu Azure.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }Jeśli używasz Notatnika, wybierz Wszystkie pliki jako typ pliku w oknie dialogowym Zapisz jako. W przeciwnym razie może dodać
.txtjako rozszerzenie pliku. Na przykładAzureStorageLinkedService.json.txt. Jeśli plik zostanie utworzony w Eksploratorze plików przed otwarciem go w Notatniku, rozszerzenie może nie być widoczne.txt, ponieważ opcja Ukryj rozszerzenia dla znanych typów plików jest domyślnie ustawiona. Przed przejściem do następnego kroku usuń rozszerzenie.txt.W programie PowerShell przejdź do folderu ADFv2QuickStartPSH.
Set-Location 'C:\ADFv2QuickStartPSH'Uruchom polecenie cmdlet Set-AzDataFactoryV2LinkedService, aby utworzyć połączoną usługę: AzureStorageLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "AzureStorageLinkedService" ` -DefinitionFile ".\AzureStorageLinkedService.json"Oto przykładowe dane wyjściowe:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedService
Tworzenie zestawów danych
W tej procedurze tworzone są dwa zestawy danych: InputDataset i OutputDataset. Te zestawy danych są typu Binary. Odwołują się one do połączonej usługi Azure Storage utworzonej w poprzedniej sekcji. Wejściowy zestaw danych reprezentuje dane źródłowe w folderze wejściowym. W definicji wejściowego zestawu danych określany jest kontener obiektów blob (adftutorial), folder (input) i plik (emp.txt), który zawiera dane źródłowe. Wyjściowy zestaw danych reprezentuje dane, które są kopiowane do lokalizacji docelowej. W definicji wyjściowego zestawu danych określany jest kontener obiektów blob (adftutorial), folder (output) i plik, do którego kopiowane są dane.
Utwórz plik JSON o nazwie InputDataset.json w folderze C:\ADFv2QuickStartPSH o następującej zawartości:
{ "name": "InputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "fileName": "emp.txt", "folderPath": "input", "container": "adftutorial" } } } }Aby utworzyć zestaw danych: InputDataset, uruchom polecenie cmdlet Set-AzDataFactoryV2Dataset .
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "InputDataset" ` -DefinitionFile ".\InputDataset.json"Oto przykładowe dane wyjściowe:
DatasetName : InputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDatasetPowtórz kroki, aby utworzyć wyjściowy zestaw danych. Utwórz plik JSON o nazwie OutputDataset.json w folderze C:\ADFv2QuickStartPSH o następującej zawartości:
{ "name": "OutputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "folderPath": "output", "container": "adftutorial" } } } }Uruchom cmdlet Set-AzDataFactoryV2Dataset, aby utworzyć OutDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "OutputDataset" ` -DefinitionFile ".\OutputDataset.json"Oto przykładowe dane wyjściowe:
DatasetName : OutputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDataset
Utwórz potok
W tej procedurze utworzysz potok z działaniem kopiowania danych, wykorzystującą wejściowe i wyjściowe zestawy danych. Działanie kopiowania służy do kopiowania danych z pliku określonego w ustawieniach wejściowego zestawu danych do pliku określonego w ustawieniach wyjściowego zestawu danych.
Utwórz plik JSON o nazwie Adfv2QuickStartPipeline.json w folderze C:\Adfv2QuickStartPSH o następującej zawartości:
{ "name": "Adfv2QuickStartPipeline", "properties": { "activities": [ { "name": "CopyFromBlobToBlob", "type": "Copy", "dependsOn": [], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false, "secureInput": false }, "userProperties": [], "typeProperties": { "source": { "type": "BinarySource", "storeSettings": { "type": "AzureBlobStorageReadSettings", "recursive": true } }, "sink": { "type": "BinarySink", "storeSettings": { "type": "AzureBlobStorageWriteSettings" } }, "enableStaging": false }, "inputs": [ { "referenceName": "InputDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "OutputDataset", "type": "DatasetReference" } ] } ], "annotations": [] } }Aby utworzyć przepływ: Adfv2QuickStartPipeline, uruchom cmdlet Set-AzDataFactoryV2Pipeline.
$DFPipeLine = Set-AzDataFactoryV2Pipeline ` -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName ` -Name "Adfv2QuickStartPipeline" ` -DefinitionFile ".\Adfv2QuickStartPipeline.json"
Utwórz przebieg potoku
W tym kroku utworzysz przebieg potoku.
Uruchom polecenie Invoke-AzDataFactoryV2Pipeline cmdlet, aby rozpocząć uruchomienie potoku. Polecenie cmdlet zwraca identyfikator uruchomienia potoku do przyszłego monitorowania.
$RunId = Invoke-AzDataFactoryV2Pipeline `
-DataFactoryName $DataFactory.DataFactoryName `
-ResourceGroupName $ResGrp.ResourceGroupName `
-PipelineName $DFPipeLine.Name
Monitorowanie przebiegu potoku
Uruchom następujący skrypt programu PowerShell, aby ciągle sprawdzać stan działania potoku do momentu zakończenia kopiowania danych. Skopiuj/wklej poniższy skrypt w oknie programu PowerShell i naciśnij klawisz ENTER.
while ($True) { $Run = Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $ResGrp.ResourceGroupName ` -DataFactoryName $DataFactory.DataFactoryName ` -PipelineRunId $RunId if ($Run) { if ( ($Run.Status -ne "InProgress") -and ($Run.Status -ne "Queued") ) { Write-Output ("Pipeline run finished. The status is: " + $Run.Status) $Run break } Write-Output ("Pipeline is running...status: " + $Run.Status) } Start-Sleep -Seconds 10 }Oto przykładowe dane wyjściowe przebiegu potoku:
Pipeline is running...status: InProgress Pipeline run finished. The status is: Succeeded ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory RunId : 00000000-0000-0000-0000-0000000000000 PipelineName : Adfv2QuickStartPipeline LastUpdated : 8/27/2019 7:23:07 AM Parameters : {} RunStart : 8/27/2019 7:22:56 AM RunEnd : 8/27/2019 7:23:07 AM DurationInMs : 11324 Status : Succeeded Message :Uruchom następujący skrypt, aby pobrać szczegóły uruchomienia działania kopiowania, na przykład rozmiar odczytanych/zapisanych danych.
Write-Output "Activity run details:" $Result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $DataFactory.DataFactoryName -ResourceGroupName $ResGrp.ResourceGroupName -PipelineRunId $RunId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) $Result Write-Output "Activity 'Output' section:" $Result.Output -join "`r`n" Write-Output "Activity 'Error' section:" $Result.Error -join "`r`n"Upewnij się, że wyświetlone dane wyjściowe są podobne do następujących przykładowych danych wyjściowych uruchomienia działania:
ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory ActivityRunId : 00000000-0000-0000-0000-000000000000 ActivityName : CopyFromBlobToBlob PipelineRunId : 00000000-0000-0000-0000-000000000000 PipelineName : Adfv2QuickStartPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesRead, filesWritten...} LinkedServiceName : ActivityRunStart : 8/27/2019 7:22:58 AM ActivityRunEnd : 8/27/2019 7:23:05 AM DurationInMs : 6828 Status : Succeeded Error : {errorCode, message, failureType, target} Activity 'Output' section: "dataRead": 20 "dataWritten": 20 "filesRead": 1 "filesWritten": 1 "sourcePeakConnections": 1 "sinkPeakConnections": 1 "copyDuration": 4 "throughput": 0.01 "errors": [] "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (Central US)" "usedDataIntegrationUnits": 4 "usedParallelCopies": 1 "executionDetails": [ { "source": { "type": "AzureBlobStorage" }, "sink": { "type": "AzureBlobStorage" }, "status": "Succeeded", "start": "2019-08-27T07:22:59.1045645Z", "duration": 4, "usedDataIntegrationUnits": 4, "usedParallelCopies": 1, "detailedDurations": { "queuingDuration": 3, "transferDuration": 1 } } ] Activity 'Error' section: "errorCode": "" "message": "" "failureType": "" "target": "CopyFromBlobToBlob"
Przeglądanie wdrożonych zasobów
Potok danych automatycznie tworzy folder wyjściowy w kontenerze blob adftutorial. Następnie kopiuje plik emp.txt z folderu wejściowego do folderu wyjściowego.
W portalu Azure na stronie kontenera adftutorial wybierz pozycję Refresh aby wyświetlić folder wyjściowy.
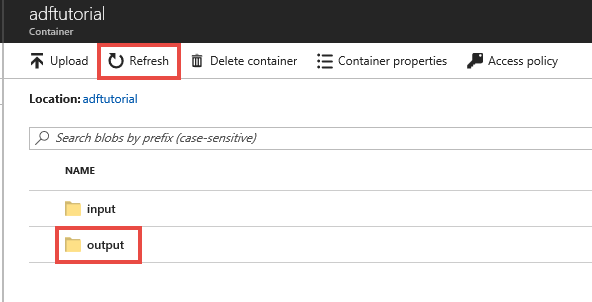
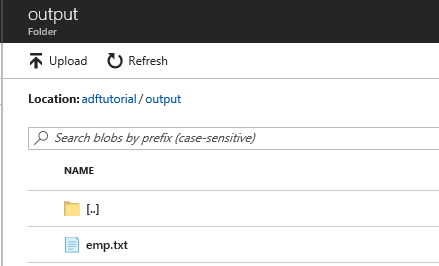
Wybierz output na liście folderów.
Upewnij się, że plik emp.txt jest kopiowany do folderu wyjściowego.
Czyszczenie zasobów
Zasoby utworzone w ramach Quickstart można wyczyścić na dwa sposoby. Możesz usunąć grupę zasobów Azure, która zawiera wszystkie zasoby w grupie zasobów. Jeśli chcesz zachować inne zasoby bez zmian, usuń tylko tę fabrykę danych, którą utworzyłeś w tym samouczku.
Usunięcie grupy zasobów powoduje usunięcie wszystkich zasobów łącznie z fabrykami danych w nich zawartymi. Uruchom poniższe polecenie, aby usunąć całą grupę zasobów:
Remove-AzResourceGroup -ResourceGroupName $resourcegroupname
Uwaga
Usunięcie grupy zasobów może zająć trochę czasu. Prosimy o cierpliwość
Jeśli chcesz usunąć tylko fabrykę danych, a nie całą grupę zasobów, uruchom następujące polecenie:
Remove-AzDataFactoryV2 -Name $dataFactoryName -ResourceGroupName $resourceGroupName
Powiązana zawartość
Przepływ pracy w tym przykładzie kopiuje dane z jednej lokalizacji do drugiej w magazynie obiektów blob Azure. Zapoznaj się z samouczkami, aby dowiedzieć się więcej o korzystaniu z usługi Data Factory w dalszych scenariuszach.