Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
W tym samouczku użyjesz Azure PowerShell do utworzenia pipeline przetwarzania danych w Azure Data Factory, który kopiuje dane z bazy danych SQL Server do Azure Blob Storage. Utworzyłeś i używasz samodzielnie hostowanego środowiska Integration Runtime, które służy do przenoszenia danych między lokalnymi magazynami danych a magazynami danych w chmurze.
Uwaga
Ten artykuł nie zawiera szczegółowego wprowadzenia do usługi Data Factory. Aby uzyskać więcej informacji, zobacz Introduction to Azure Data Factory.
Ten samouczek obejmuje wykonanie następujących kroków:
- Tworzenie fabryki danych.
- Utwórz samodzielnie hostowane środowisko Integration Runtime.
- Utwórz połączone usługi SQL Server i Azure Storage.
- Utwórz zestawy danych dla SQL Server i Azure Blob.
- Utwórz potok z operacją kopiowania do przenoszenia danych.
- Uruchom potok.
- Monitoruj przebieg potoku.
Wymagania wstępne
subskrypcja Azure
Jeśli nie masz jeszcze subskrypcji Azure, utwórz bezpłatne konto.
roli Azure
Aby utworzyć wystąpienia fabryki danych, konto użytkownika używane do logowania się do Azure musi mieć przypisaną rolę Contributor lub Owner lub musi być administratorem subskrypcji Azure.
Aby wyświetlić uprawnienia, które masz w subskrypcji, przejdź do portalu Azure, wybierz swoją nazwę użytkownika w prawym górnym rogu, a następnie wybierz pozycję Permissions. Jeśli masz dostęp do wielu subskrypcji, wybierz odpowiednią subskrypcję. Aby uzyskać przykładowe instrukcje dotyczące dodawania użytkownika do roli, zobacz artykuł Przypisania ról Azure przy użyciu portalu Azure.
SQL Server 2014, 2016 i 2017
W tym samouczku użyjesz bazy danych SQL Server jako magazynu danych source. Potok danych w fabryce danych utworzony w tym samouczku kopiuje dane z bazy danych SQL Server (źródło) do platformy Azure Blob Storage (ujście). Następnie utworzysz tabelę o nazwie emp w bazie danych SQL Server i wstawisz kilka przykładowych wpisów do tabeli.
Uruchom SQL Server Management Studio. Jeśli program nie jest jeszcze zainstalowany na Twoim komputerze, przejdź do Pobierz SQL Server Management Studio.
Połącz się z wystąpieniem SQL Server przy użyciu poświadczeń.
Utwórz przykładową bazę danych. W widoku drzewa kliknij prawym przyciskiem myszy pozycję Bazy danych, a następnie wybierz pozycję Nowa baza danych.
W oknie Nowa baza danych wprowadź nazwę bazy danych, a następnie wybierz przycisk OK.
Aby utworzyć tabelę emp i wstawić do niej przykładowe dane, uruchom następujący skrypt zapytania w bazie danych. W widoku drzewa kliknij prawym przyciskiem myszy utworzoną bazę danych, a następnie wybierz pozycję Nowe zapytanie.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
konto Azure Storage
W tym samouczku użyjesz uniwersalnego konta magazynu Azure (w szczególności Azure Blob Storage) jako magazynu danych docelowego/przeznaczenia. Jeśli nie masz konta magazynu ogólnego przeznaczenia Azure, zobacz Tworzenie konta magazynu. Potok w fabryce danych, który tworzysz w tym samouczku, kopiuje dane z bazy danych SQL Server (źródło) do Azure Blob Storage (ujście).
Pobieranie nazwy konta i klucza konta magazynu
W tym samouczku użyjesz nazwy i klucza Twojego konta magazynowego Azure. Pobierz nazwę i klucz konta usługi Storage, wykonując następujące czynności:
Zaloguj się do portalu Azure przy użyciu nazwy użytkownika i hasła Azure.
W okienku po lewej stronie wybierz pozycję Więcej usług, zastosuj filtrowanie według słowa kluczowego magazyn, a następnie wybierz pozycję Konta magazynu.
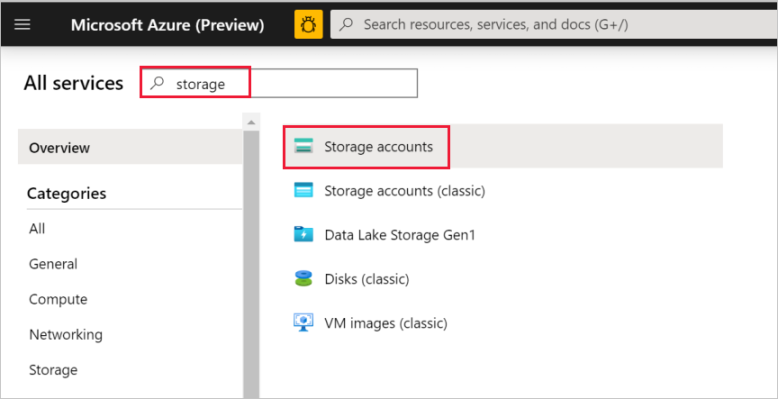
Na liście kont magazynu, w razie potrzeby, użyj filtrowania, aby znaleźć swoje konto magazynu, a następnie je wybierz.
W oknie Konto magazynu wybierz pozycję Klucze dostępu.
Skopiuj wartości z pól Nazwa konta magazynu i klucz1 i wklej je do Notatnika lub innego edytora do późniejszego użycia z tym samouczkiem.
Tworzenie kontenera adftutorial
W tej sekcji utworzysz kontener obiektów blob o nazwie adftutorial w magazynie obiektów blob Azure.
W oknie Konto magazynu przełącz się do widoku Przegląd, a następnie wybierz pozycję Obiekty blob.
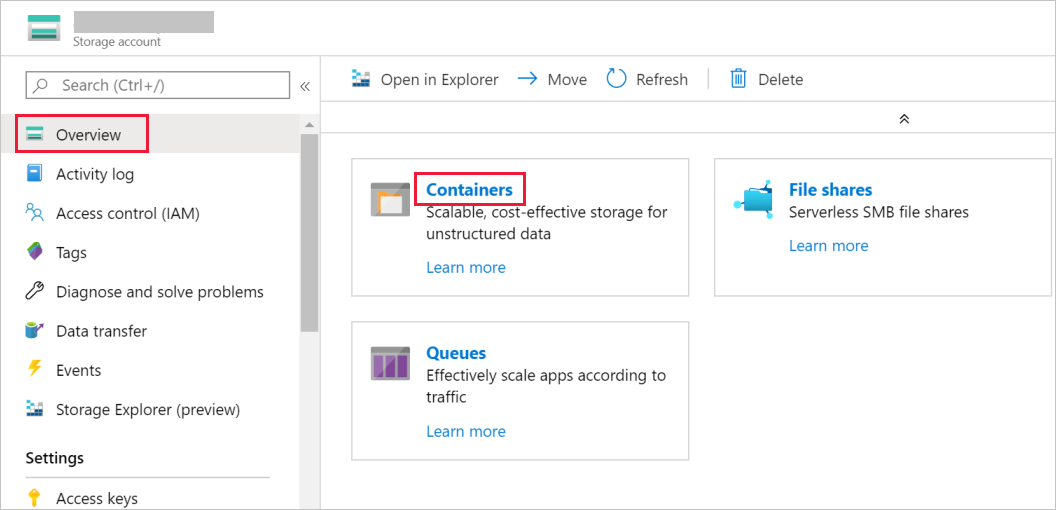
W oknie Blob Service wybierz opcję Kontener.
W oknie Nowy kontener w polu Nazwa wpisz nazwę adftutorial, a następnie wybierz pozycję OK.
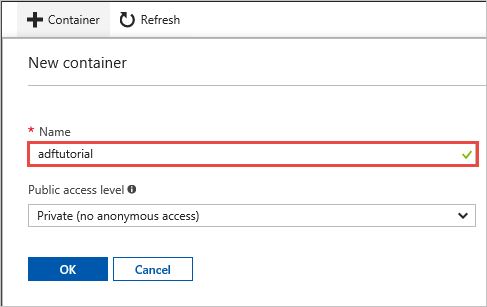
Kliknij pozycję adftutorial na liście kontenerów.
Pozostaw otwarte okno kontenera dla adftutorial. Używasz jej do weryfikacji danych wyjściowych na końcu tego samouczka. Usługa Data Factory automatycznie tworzy folder wyjściowy w tym kontenerze, więc Ty nie musisz go tworzyć.
Windows PowerShell
Instalowanie Azure PowerShell
Uwaga
Zalecamy użycie modułu Azure Az programu PowerShell do interakcji z Azure. Aby rozpocząć, zobacz Install Azure PowerShell. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az programu PowerShell, zobacz Migrate Azure PowerShell z modułu AzureRM do modułu Az.
Zainstaluj najnowszą wersję Azure PowerShell, jeśli nie masz jej jeszcze na maszynie. Aby uzyskać szczegółowe instrukcje, zobacz Jak zainstalować i skonfigurować Azure PowerShell.
Logowanie do programu PowerShell
Uruchom program PowerShell na maszynie i pozostaw ten program otwarty aż do zakończenia pracy z tym samouczkiem Szybki start. Jeśli go zamkniesz i otworzysz ponownie, musisz uruchomić te polecenia jeszcze raz.
Uruchom następujące polecenie, a następnie wprowadź nazwę użytkownika i hasło Azure używane do logowania się w portalu Azure:
Connect-AzAccountJeśli masz wiele subskrypcji Azure, uruchom następujące polecenie, aby wybrać subskrypcję, z którą chcesz pracować. Zastąp SubscriptionId identyfikatorem subskrypcji Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Tworzenie fabryki danych
Zdefiniuj zmienną nazwy grupy zasobów, której użyjesz później w poleceniach programu PowerShell. Skopiuj następujące polecenie do programu PowerShell, określ nazwę grupy zasobów Azure (ujętą w podwójny cudzysłów, na przykład
"adfrg"), a następnie uruchom polecenie.$resourceGroupName = "ADFTutorialResourceGroup"Aby utworzyć grupę zasobów Azure, uruchom następujące polecenie:
New-AzResourceGroup $resourceGroupName -location 'East US'Jeśli grupa zasobów już istnieje, możesz zrezygnować z jej zastąpienia. Przypisz inną wartość do zmiennej
$resourceGroupNamei ponownie uruchom polecenie.Zdefiniuj zmienną nazwy fabryki danych, której możesz użyć później w poleceniach programu PowerShell. Nazwa musi zaczynać się od litery lub cyfry i może zawierać tylko litery, cyfry i znak łącznika (-).
Ważne
Zaktualizuj nazwę fabryki danych, nadając jej globalnie unikatową nazwę. Na przykład: ADFTutorialFactorySP1127.
$dataFactoryName = "ADFTutorialFactory"Zdefiniuj zmienną lokalizacji fabryki danych:
$location = "East US"Aby utworzyć fabrykę danych, uruchom następujące polecenie cmdlet
Set-AzDataFactoryV2:Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Uwaga
- Nazwa fabryki danych musi być globalnie unikatowa. Jeśli zostanie wyświetlony następujący błąd, zmień nazwę i spróbuj ponownie.
The specified data factory name 'ADFv2TutorialDataFactory' is already in use. Data factory names must be globally unique. - Aby utworzyć wystąpienia fabryki danych, konto użytkownika używane do logowania się do Azure musi mieć przypisaną rolę contributor lub owner albo być administratorem subskrypcji Azure.
- Aby uzyskać listę regionów Azure, w których usługa Data Factory jest obecnie dostępna, wybierz regiony, które Cię interesują na następującej stronie, a następnie rozwiń węzeł Analytics aby zlokalizować Data Factory: Products available by region. Magazyny danych (Azure Storage, Azure SQL Database itd.) i obliczenia (Azure HDInsight itd.) używane przez fabrykę danych mogą znajdować się w innych regionach.
Tworzenie własnego, lokalnie hostowanego środowiska uruchomieniowego интеграции
W tej sekcji utworzysz własne środowisko Integration Runtime i skojarzysz je z maszyną lokalną z bazą danych SQL Server. Lokalnie hostowane środowisko Integration Runtime to składnik, który kopiuje dane z bazy danych SQL Server na twojej maszynie do usługi Azure Blob Storage.
Utwórz zmienną dla nazwy środowiska Integration Runtime. Użyj unikatowej nazwy i zanotuj ją. Będziesz jej używać w dalszej części tego samouczka.
$integrationRuntimeName = "ADFTutorialIR"Utwórz samodzielnie hostowane środowisko Integration Runtime.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $integrationRuntimeName -Type SelfHosted -Description "selfhosted IR description"Oto przykładowe dane wyjściowe:
Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Uruchom następujące polecenie, aby pobrać stan utworzonego środowiska Integration Runtime:
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusOto przykładowe dane wyjściowe:
State : NeedRegistration Version : CreateTime : 9/10/2019 3:24:09 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Uruchom następujące polecenie, aby pobrać klucze uwierzytelniania do zarejestrowania własnego środowiska Integration Runtime z usługą Data Factory w chmurze. Skopiuj jeden z kluczy (pomijając cudzysłowy) na potrzeby rejestracji własnego środowiska Integration Runtime, które zainstalujesz na swojej maszynie w następnym kroku.
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonOto przykładowe dane wyjściowe:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }
Instalowanie środowiska Integration Runtime
Pobierz Azure Data Factory Integration Runtime na lokalnym komputerze Windows, a następnie uruchom instalację.
W kreatorze Welcome do Microsoft Integration Runtime Setup wybierz Next.
W oknie Umowa Licencyjna Użytkownika Oprogramowania zaakceptuj warunki i umowę licencyjną, a następnie wybierz przycisk Dalej.
W oknie Folder docelowy wybierz przycisk Dalej.
W oknie Gotowy do zainstalowania Microsoft Integration Runtime wybierz pozycję Zainstaluj.
W kreatorze Completed Microsoft Integration Runtime Setup wybierz Finish.
W oknie Register Integration Runtime (self-hosted) wklej klucz zapisany w poprzedniej sekcji, a następnie wybierz pozycję Register.
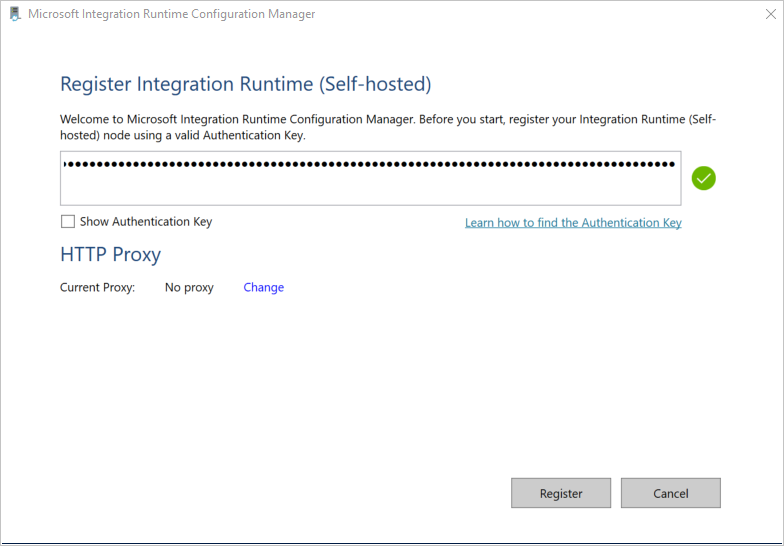
W oknie Nowa Integration Runtime (samodzielnie hostowana) Node wybierz opcję Zakończ.
Kiedy samodzielnie hostowane środowisko Integration Runtime zostanie pomyślnie zarejestrowane, wyświetli się następujący komunikat:
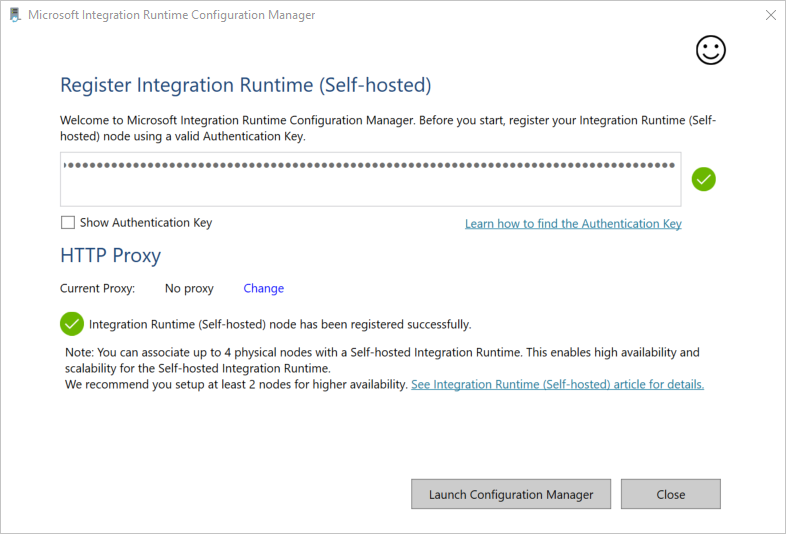
W oknie Register Integration Runtime (self-hosted) wybierz pozycję Uruchom Configuration Manager.
Gdy węzeł zostanie połączony z usługą w chmurze, zostanie wyświetlony następujący komunikat:
Przetestuj łączność z bazą danych SQL Server, wykonując następujące czynności:
a. W oknie Configuration Manager przejdź do karty Diagnostics.
b. W polu Typ źródła danych wybierz pozycję SqlServer.
c. Wprowadź nazwę serwera.
d. Wprowadź nazwę bazy danych.
e. Wybierz tryb uwierzytelniania.
f. Wprowadź nazwę użytkownika.
g. Wprowadź hasło powiązane z tą nazwą użytkownika.
h. Aby upewnić się, że środowisko Integration Runtime może nawiązać połączenie z SQL Server, wybierz pozycję Test.
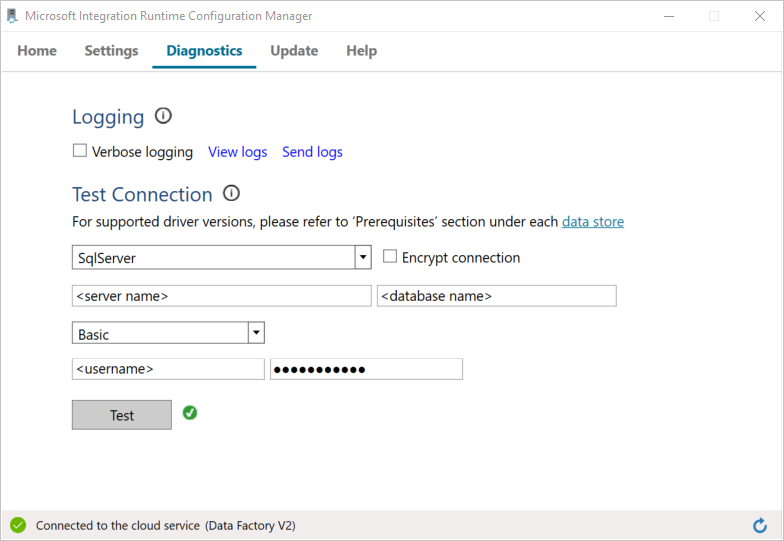
Jeśli połączenie zostanie pomyślnie nawiązane, zostanie wyświetlona zielona ikona haczyka. Jeśli nie, zostanie wyświetlony komunikat o błędzie. Rozwiąż wszelkie problemy i upewnij się, że środowisko wykonawcze integracji może nawiązać połączenie z wystąpieniem SQL Server.
Zanotuj wszystkie powyższe wartości do późniejszego użycia z tym samouczkiem.
Tworzenie połączonych usług
Utwórz połączone usługi w fabryce danych w celu połączenia swoich magazynów danych i usług obliczeniowych z fabryką danych. W tym samouczku połączysz swoje konto magazynu Azure i wystąpienie SQL Server z magazynem danych. Połączone usługi mają informacje o połączeniu, których usługa Data Factory używa w środowisku uruchomieniowym do łączenia się z nimi.
Tworzenie połączonej usługi Azure Storage (miejsce docelowe/ujście)
W tym kroku połączysz konto magazynu Azure z fabryką danych.
W folderze C:\ADFv2Tutorial utwórz plik JSON o nazwie AzureStorageLinkedService.json, używając poniższego kodu. Jeśli folder ADFv2Tutorial jeszcze nie istnieje, utwórz go.
Ważne
Przed zapisaniem pliku zastąp <accountName> i <accountKey> nazwą i kluczem konta magazynu Azure. Zanotowałeś je w sekcji Wymagania wstępne.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }W programie PowerShell przejdź do folderu C:\ADFv2Tutorial.
Set-Location 'C:\ADFv2Tutorial'Aby utworzyć połączoną usługę o nazwie AzureStorageLinkedService, uruchom następujące polecenie cmdlet
Set-AzDataFactoryV2LinkedService:Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Oto przykładowe dane wyjściowe:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedServiceJeśli zostanie zwrócony błąd „nie znaleziono pliku”, sprawdź, czy plik istnieje, uruchamiając polecenie
dir. Jeśli nazwa pliku ma rozszerzenie txt (na przykład AzureStorageLinkedService.json.txt), usuń je, a następnie ponownie uruchom polecenie programu PowerShell.
Tworzenie i szyfrowanie połączonej usługi SQL Server (źródło)
W tym kroku połączysz wystąpienie SQL Server z fabryką danych.
W folderze C:\ADFv2Tutorial utwórz plik JSON o nazwie SqlServerLinkedService.json, używając następującego kodu:
Ważne
Wybierz sekcję opartą na uwierzytelnianiu używanym do nawiązywania połączenia z SQL Server.
Użycie uwierzytelniania SQL (sa):
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<serverName>;initial catalog=<databaseName>;user id=<userName>;password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name> ", "type":"IntegrationRuntimeReference" } } }Korzystanie z uwierzytelniania Windows:
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<serverName>;initial catalog=<databaseName>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Ważne
- Wybierz sekcję opartą na uwierzytelnianiu używanym do nawiązywania połączenia z wystąpieniem SQL Server.
- Zastąp <nazwę Integration Runtime> nazwą swojego Integration Runtime.
- Przed zapisaniem pliku zastąp <servername>, <databasename>, <username> i <password> z wartościami wystąpienia SQL Server.
- Jeśli musisz użyć ukośnika odwrotnego (\) w nazwie konta użytkownika lub serwera, poprzedź go znakiem ucieczki (\). Na przykład użyj mydomain \\myuser.
Aby zaszyfrować dane poufne (nazwę użytkownika, hasło itp.), uruchom polecenie cmdlet
New-AzDataFactoryV2LinkedServiceEncryptedCredential.
To zapewnia szyfrowanie poświadczeń za pomocą interfejsu API ochrony danych (DPAPI). Zaszyfrowane poświadczenia są przechowywane lokalnie na węźle lokalnego środowiska integracyjnego (self-hosted) (maszyna lokalna). Ładunek danych wyjściowych może zostać przekierowany do innego pliku JSON (w tym przypadku encryptedLinkedService.json), który zawiera zaszyfrowane poświadczenia.New-AzDataFactoryV2LinkedServiceEncryptedCredential -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -IntegrationRuntimeName $integrationRuntimeName -File ".\SQLServerLinkedService.json" > encryptedSQLServerLinkedService.jsonUruchom następujące polecenie, aby utworzyć element EncryptedSqlServerLinkedService:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "EncryptedSqlServerLinkedService" -File ".\encryptedSqlServerLinkedService.json"
Tworzenie zestawów danych
W tym kroku utworzysz zestawy danych wejściowych i wyjściowych. Reprezentują one dane wejściowe i wyjściowe dla operacji kopiowania, która kopiuje dane z bazy danych SQL Server do usługi Azure Blob Storage.
Tworzenie zestawu danych dla źródłowej bazy danych SQL Server
W tym kroku zdefiniujesz zestaw danych reprezentujący dane w wystąpieniu bazy danych SQL Server. Typ zestawu danych to SqlServerTable. Odwołuje się on do połączonej usługi SQL Server utworzonej w poprzednim kroku. Połączona usługa zawiera informacje o połączeniu, które usługa Data Factory wykorzystuje do łączenia się z instancją SQL Server w czasie wykonywania. Ten zestaw danych określa tabelę SQL w bazie danych, która zawiera dane. W tym samouczku tabela emp zawiera dane źródłowe.
Utwórz plik JSON o nazwie SqlServerDataset.json w folderze C:\ADFv2Tutorial, używając następującego kodu:
{ "name":"SqlServerDataset", "properties":{ "linkedServiceName":{ "referenceName":"EncryptedSqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ], "typeProperties":{ "schema":"dbo", "table":"emp" } } }Aby utworzyć zestaw danych SqlServerDataset, uruchom polecenie cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerDataset" -File ".\SqlServerDataset.json"Oto przykładowe dane wyjściowe:
DatasetName : SqlServerDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Tworzenie zestawu danych dla usługi Azure Blob Storage (ujście)
W tym kroku zdefiniujesz zestaw danych reprezentujący dane, które zostaną skopiowane do usługi Azure Blob Storage. Typ tego zestawu danych to AzureBlob. Odwołuje się on do połączonej usługi Azure Storage utworzonej wcześniej w tym samouczku.
Usługa łączona zawiera informacje o połączeniu, które Data Factory wykorzystuje podczas wykonywania, aby połączyć się z Twoim kontem magazynu Azure. Ten zestaw danych określa folder w magazynie Azure, do którego dane są kopiowane z bazy danych SQL Server. W tym samouczku folderem jest adftutorial/fromonprem, gdzie adftutorial to kontener blob, a fromonprem to folder.
Utwórz plik JSON o nazwie AzureBlobDataset.json w folderze C:\ADFv2Tutorial, używając następującego kodu:
{ "name":"AzureBlobDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureStorageLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"DelimitedText", "typeProperties":{ "location":{ "type":"AzureBlobStorageLocation", "folderPath":"fromonprem", "container":"adftutorial" }, "columnDelimiter":",", "escapeChar":"\\", "quoteChar":"\"" }, "schema":[ ] }, "type":"Microsoft.DataFactory/factories/datasets" }Aby utworzyć zestaw danych AzureBlobDataset, uruchom polecenie cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureBlobDataset" -File ".\AzureBlobDataset.json"Oto przykładowe dane wyjściowe:
DatasetName : AzureBlobDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.DelimitedTextDataset
Stwórz pipeline
W tym samouczku tworzysz potok z użyciem aktywności kopiowania. Działanie kopiowania używa zestawu danych SqlServerDataset jako wejściowego zestawu danych oraz zestawu danych AzureBlobDataset jako wyjściowego zestawu danych. Typ źródła jest ustawiony na wartość SqlSource, a typ ujścia — na wartość BlobSink.
Utwórz plik JSON o nazwie SqlServerToBlobPipeline.json w folderze C:\ADFv2Tutorial, używając następującego kodu:
{ "name":"SqlServerToBlobPipeline", "properties":{ "activities":[ { "name":"CopySqlServerToAzureBlobActivity", "type":"Copy", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource" }, "sink":{ "type":"DelimitedTextSink", "storeSettings":{ "type":"AzureBlobStorageWriteSettings" }, "formatSettings":{ "type":"DelimitedTextWriteSettings", "quoteAllText":true, "fileExtension":".txt" } }, "enableStaging":false }, "inputs":[ { "referenceName":"SqlServerDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"AzureBlobDataset", "type":"DatasetReference" } ] } ], "annotations":[ ] } }Aby utworzyć potok SQLServerToBlobPipeline, uruchom polecenie cmdlet
Set-AzDataFactoryV2Pipeline.Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SQLServerToBlobPipeline" -File ".\SQLServerToBlobPipeline.json"Oto przykładowe dane wyjściowe:
PipelineName : SQLServerToBlobPipeline ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Activities : {CopySqlServerToAzureBlobActivity} Parameters :
Uruchom potok
Uruchom uruchomienie potoku dla potoku SQLServerToBlobPipeline i zapisz identyfikator uruchomienia potoku w celu przyszłego monitorowania.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName 'SQLServerToBlobPipeline'
Monitorowanie działania potoku
Aby stale sprawdzać stan działania potoku SQLServerToBlobPipeline, uruchom następujący skrypt w programie PowerShell, a następnie wydrukuj wynik końcowy:
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" Start-Sleep -Seconds 30 } else { Write-Host "Pipeline 'SQLServerToBlobPipeline' run finished. Result:" -foregroundcolor "Yellow" $result break } }Oto wynik przykładowego uruchomienia:
ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> ActivityRunId : 24af7cf6-efca-4a95-931d-067c5c921c25 ActivityName : CopySqlServerToAzureBlobActivity ActivityType : Copy PipelineRunId : 7b538846-fd4e-409c-99ef-2475329f5729 PipelineName : SQLServerToBlobPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesWritten, sourcePeakConnections...} LinkedServiceName : ActivityRunStart : 9/11/2019 7:10:37 AM ActivityRunEnd : 9/11/2019 7:10:58 AM DurationInMs : 21094 Status : Succeeded Error : {errorCode, message, failureType, target} AdditionalProperties : {[retryAttempt, ], [iterationHash, ], [userProperties, {}], [recoveryStatus, None]...}Aby uzyskać identyfikator działania potoku SQLServerToBlobPipeline i sprawdzić szczegółowe wyniki uruchomienia działania, uruchom następujące polecenie:
Write-Host "Pipeline 'SQLServerToBlobPipeline' run result:" -foregroundcolor "Yellow" ($result | Where-Object {$_.ActivityName -eq "CopySqlServerToAzureBlobActivity"}).Output.ToString()Oto wynik przykładowego uruchomienia:
{ "dataRead":36, "dataWritten":32, "filesWritten":1, "sourcePeakConnections":1, "sinkPeakConnections":1, "rowsRead":2, "rowsCopied":2, "copyDuration":18, "throughput":0.01, "errors":[ ], "effectiveIntegrationRuntime":"ADFTutorialIR", "usedParallelCopies":1, "executionDetails":[ { "source":{ "type":"SqlServer" }, "sink":{ "type":"AzureBlobStorage", "region":"CentralUS" }, "status":"Succeeded", "start":"2019-09-11T07:10:38.2342905Z", "duration":18, "usedParallelCopies":1, "detailedDurations":{ "queuingDuration":6, "timeToFirstByte":0, "transferDuration":5 } } ] }
Sprawdzanie danych wyjściowych
Potok automatycznie tworzy folder wyjściowy o nazwie fromonprem w kontenerze Blob adftutorial. Upewnij się, że plik dbo.emp.txt jest widoczny w folderze wyjściowym.
W portalu Azure w oknie kontenera adftutorial wybierz pozycję Refresh aby wyświetlić folder wyjściowy.
Wybierz pozycję
fromonpremna liście folderów.Upewnij się, że jest wyświetlany plik o nazwie
dbo.emp.txt.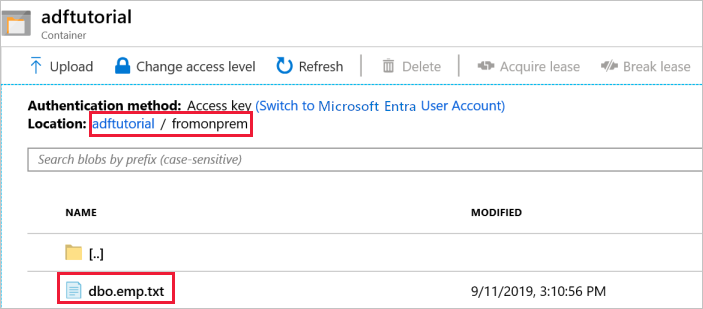
Powiązana zawartość
W tym przykładzie pipeline kopiuje dane z jednej lokalizacji do innej w usłudze Azure Blob Storage. Nauczyłeś się jak:
- Tworzenie fabryki danych.
- Utwórz samodzielnie hostowane środowisko Integration Runtime.
- Utwórz połączone usługi SQL Server i Azure Storage.
- Utwórz zestawy danych dla SQL Server i Azure Blob.
- Utwórz potok z operacją kopiowania do przenoszenia danych.
- Uruchom potok.
- Monitoruj przebieg potoku.
Lista magazynów danych obsługiwanych przez usługę Data Factory znajduje się w artykule dotyczącym obsługiwanych magazynów danych.
Przejdź do poniższego samouczka, aby dowiedzieć się o zbiorczym kopiowaniu danych z lokalizacji źródłowej do docelowej: