Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dzięki usłudze Custom Speech można ocenić i poprawić dokładność rozpoznawania mowy dla aplikacji i produktów. Niestandardowy model mowy może służyć do zamiany mowy w czasie rzeczywistym na tekst, tłumaczenie mowy i transkrypcję wsadową.
Funkcja rozpoznawania mowy korzysta z modelu uniwersalnego języka jako modelu podstawowego, który jest trenowany przy użyciu danych należących do firmy Microsoft i odzwierciedla powszechnie używany język mówiony. Model podstawowy jest wstępnie trenowany za pomocą dialektów i fonetyki reprezentujących różne typowe domeny. Podczas tworzenia żądania rozpoznawania mowy najnowszy model podstawowy dla każdego obsługiwanego języka jest używany domyślnie. Model podstawowy działa dobrze w większości scenariuszy rozpoznawania mowy.
Model niestandardowy może służyć do rozszerzania modelu podstawowego w celu poprawy rozpoznawania słownictwa specyficznego dla domeny specyficznego dla aplikacji, dostarczając dane tekstowe do trenowania modelu. Może również służyć do ulepszania rozpoznawania na podstawie określonych warunków dźwiękowych aplikacji, dostarczając dane audio z transkrypcjami referencyjnymi.
Model można również wytrenować przy użyciu tekstu strukturalnego, gdy dane są zgodne ze wzorcem, aby określić niestandardową wymowę, oraz dostosować formatowanie tekstu wyświetlanego przy użyciu niestandardowej normalizacji tekstu odwrotnego, niestandardowego ponownego zapisywania i niestandardowego filtrowania wulgaryzmów.
Jak to działa?
Za pomocą mowy niestandardowej możesz przekazać własne dane, przetestować i wytrenować model niestandardowy, porównać dokładność między modelami i wdrożyć model w niestandardowym punkcie końcowym.
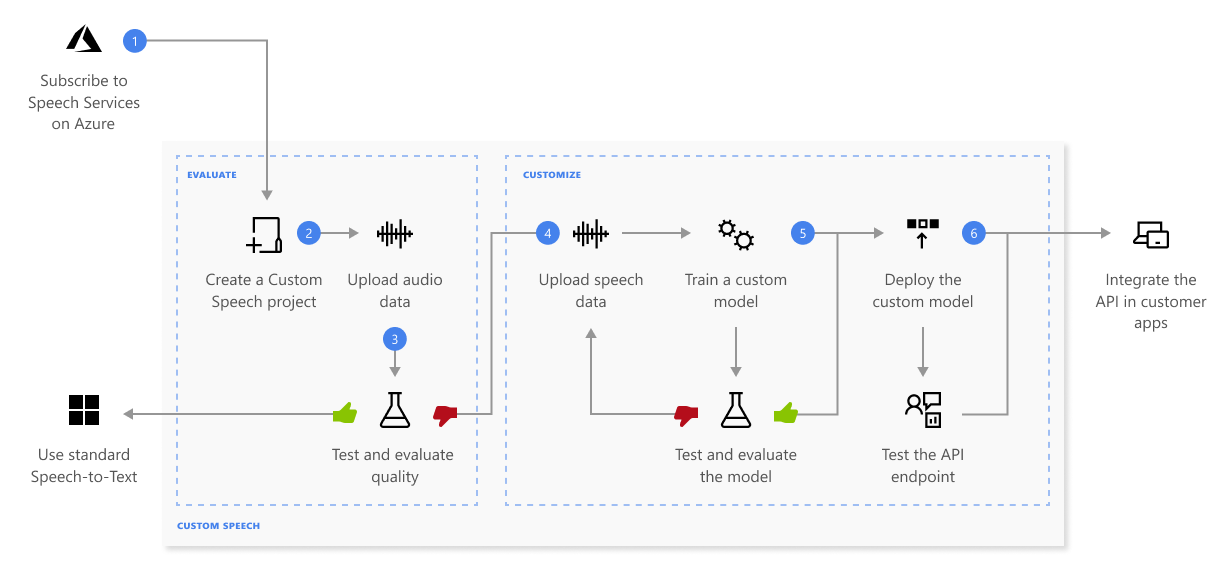
Poniżej przedstawiono więcej informacji na temat sekwencji kroków pokazanych na poprzednim diagramie:
Utwórz projekt i wybierz model. Użyj zasobu typu "Create an AI Foundry dla mowy", który tworzysz w portalu Azure. W przypadku trenowania modelu niestandardowego przy użyciu danych audio wybierz zasób usługi w regionie z dedykowanym sprzętem do trenowania danych audio. Aby uzyskać więcej informacji, zobacz przypisy dolne w tabeli regionów .
Przekazywanie danych testowych. Przekaż dane testowe, aby ocenić ofertę zamiany mowy na tekst dla aplikacji, narzędzi i produktów.
Trenowanie modelu. Podaj zapisane transkrypcje i powiązany tekst wraz z odpowiednimi danymi audio. Testowanie modelu przed trenowaniem i po nim jest opcjonalne, ale zalecane.
Uwaga
Płacisz za użycie niestandardowego modelu mowy i hostowanie punktów końcowych. Opłaty będą również naliczane za trenowanie niestandardowego modelu mowy, jeśli model podstawowy został utworzony 1 października 2023 r. i nowsze. Nie są naliczane opłaty za trenowanie, jeśli model podstawowy został utworzony przed październikiem 2023 r. Aby uzyskać więcej informacji, zobacz Cennik usługi Azure AI Speech i sekcję Opłaty za adaptację w przewodniku migracji zamiany mowy na tekst 3.2.
Jakość rozpoznawania testów. Użyj programu Speech Studio, aby odtworzyć przekazany dźwięk i sprawdzić jakość rozpoznawania mowy danych testowych.
Model testowy ilościowo. Ocenianie i poprawianie dokładności modelu zamiany mowy na tekst. Usługa mowa udostępnia ilościową szybkość błędów słów (WER), której można użyć do określenia, czy wymagane jest więcej trenowania.
Wdrażanie modelu. Gdy wyniki testu będą zadowalające, wdróż model w niestandardowym punkcie końcowym. Z wyjątkiem transkrypcji wsadowej należy wdrożyć niestandardowy punkt końcowy, aby użyć niestandardowego modelu mowy.
Wybieranie modelu
Istnieje kilka podejść do używania niestandardowych modeli mowy:
- Model podstawowy zapewnia dokładne rozpoznawanie mowy poza ramką dla wielu scenariuszy. Modele podstawowe są okresowo aktualizowane w celu zwiększenia dokładności i jakości. Zalecamy, aby w przypadku korzystania z modeli podstawowych używać najnowszych domyślnych modeli bazowych. Jeśli wymagana możliwość dostosowywania jest dostępna tylko w przypadku starszego modelu, możesz wybrać starszy model podstawowy.
- Model niestandardowy rozszerza model podstawowy w celu uwzględnienia słownictwa specyficznego dla domeny współużytkowanego we wszystkich obszarach domeny niestandardowej.
- Wiele modeli niestandardowych może być używanych, gdy domena niestandardowa ma wiele obszarów, z których każdy ma określone słownictwo.
Zalecanym sposobem sprawdzenia, czy wystarczy model podstawowy, jest przeanalizowanie transkrypcji utworzonej na podstawie modelu podstawowego i porównanie jej z transkrypcją wygenerowaną przez człowieka dla tego samego dźwięku. Możesz porównać transkrypcje i uzyskać wynik współczynnika błędów słów (WER ). Jeśli wynik WER jest wysoki, zaleca się trenowanie modelu niestandardowego w celu rozpoznawania niepoprawnie zidentyfikowanych wyrazów.
Zalecane jest wiele modeli, jeśli słownictwo różni się w różnych obszarach domeny. Na przykład komentatorzy olimpijni zgłaszają różne wydarzenia, z których każda jest skojarzona z własną vernacular. Ponieważ każde słownictwo wydarzeń olimpijskich różni się znacząco od innych, tworzenie niestandardowego modelu specyficznego dla zdarzenia zwiększa dokładność, ograniczając dane wypowiedzi względem tego konkretnego wydarzenia. W związku z tym model nie musi przesiewać niepowiązanych danych w celu dopasowania. Niezależnie od tego, szkolenie nadal wymaga przyzwoitej różnorodności danych treningowych. Uwzględnij dźwięk od różnych komentatorów, którzy mają różne akcenty, płeć, wiek itp.
Stabilność i cykl życia modelu
Model podstawowy lub model niestandardowy wdrożony w punkcie końcowym przy użyciu mowy niestandardowej jest stały do momentu, gdy zdecydujesz się go zaktualizować. Dokładność i jakość rozpoznawania mowy pozostają spójne, nawet w przypadku wydania nowego modelu podstawowego. Dzięki temu można zablokować zachowanie określonego modelu, dopóki nie zdecydujesz się na użycie nowszego modelu.
Niezależnie od tego, czy trenujesz własny model, czy używasz migawki modelu podstawowego, możesz użyć modelu przez ograniczony czas. Aby uzyskać więcej informacji, zobacz Cykl życia modelu i punktu końcowego.
Odpowiedzialne AI
System sztucznej inteligencji obejmuje nie tylko technologię, ale także osoby, które go używają, osoby, których to dotyczy, oraz środowisko, w którym jest wdrażane. Zapoznaj się z uwagami dotyczącymi przejrzystości, aby dowiedzieć się więcej na temat odpowiedzialnego używania sztucznej inteligencji i wdrażania w systemach.
- Notatka dotycząca przezroczystości i przypadki użycia
- Cechy i ograniczenia
- Integracja i odpowiedzialne użycie
- Dane, prywatność i bezpieczeństwo