Filtrowanie zawartości w usłudze Azure AI Studio
Ważne
Niektóre funkcje opisane w tym artykule mogą być dostępne tylko w wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Usługa Azure AI Studio zawiera system filtrowania zawartości, który działa wraz z podstawowymi modelami i modelami generowania obrazów DALL-E.
Ważne
System filtrowania zawartości nie jest stosowany do monitów i uzupełniania przetworzonych przez model Whisper w usłudze Azure OpenAI Service. Dowiedz się więcej o modelu Whisper w usłudze Azure OpenAI.
Jak to działa
Ten system filtrowania zawartości jest obsługiwany przez bezpieczeństwo zawartości sztucznej inteligencji platformy Azure i działa przez uruchomienie zarówno danych wejściowych monitów, jak i danych wyjściowych uzupełniania przez zespół modeli klasyfikacji mających na celu wykrywanie i zapobieganie wyjściu szkodliwej zawartości. Zmiany w konfiguracjach interfejsu API i projekcie aplikacji mogą mieć wpływ na ukończenie, a tym samym zachowanie filtrowania.
W przypadku wdrożeń modelu usługi Azure OpenAI można użyć domyślnego filtru zawartości lub utworzyć własny filtr zawartości (opisany w dalszej części). Domyślny filtr zawartości jest również dostępny dla innych modeli tekstowych wyselekcjonowanych przez usługę Azure AI w wykazie modeli, ale niestandardowe filtry zawartości nie są jeszcze dostępne dla tych modeli. Modele dostępne za pośrednictwem modelu jako usługi mają domyślnie włączone filtrowanie zawartości i nie można ich skonfigurować.
Obsługa języków
Modele filtrowania zawartości zostały przeszkolone i przetestowane w następujących językach: angielski, niemiecki, japoński, hiszpański, francuski, włoski, portugalski i chiński. Jednak usługa może działać w wielu innych językach, ale jakość może się różnić. We wszystkich przypadkach należy przeprowadzić własne testy, aby upewnić się, że działa ona w danym zastosowaniu.
Tworzenie filtru zawartości
W przypadku dowolnego wdrożenia modelu w usłudze Azure AI Studio możesz bezpośrednio użyć domyślnego filtru zawartości, ale możesz chcieć mieć większą kontrolę. Można na przykład zwiększyć lub bardziej łagodny filtr albo włączyć bardziej zaawansowane funkcje, takie jak osłony monitów i wykrywanie materiałów chronionych.
Wykonaj następujące kroki, aby utworzyć filtr zawartości:
Przejdź do programu AI Studio i przejdź do centrum. Następnie wybierz kartę Filtry zawartości na lewym pasku nawigacyjnym i wybierz przycisk Utwórz filtr zawartości.
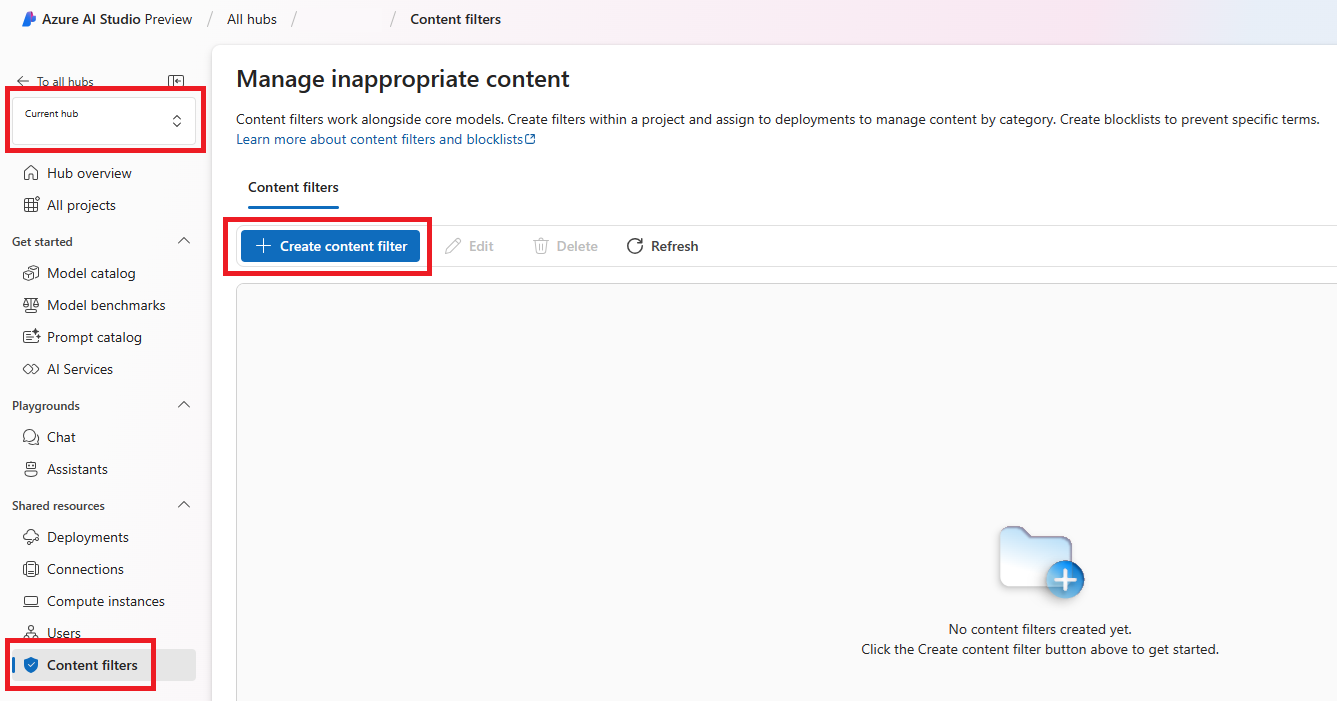
Na stronie Informacje podstawowe wprowadź nazwę filtru zawartości. Wybierz połączenie, które ma być skojarzone z filtrem zawartości. Następnie kliknij przycisk Dalej.
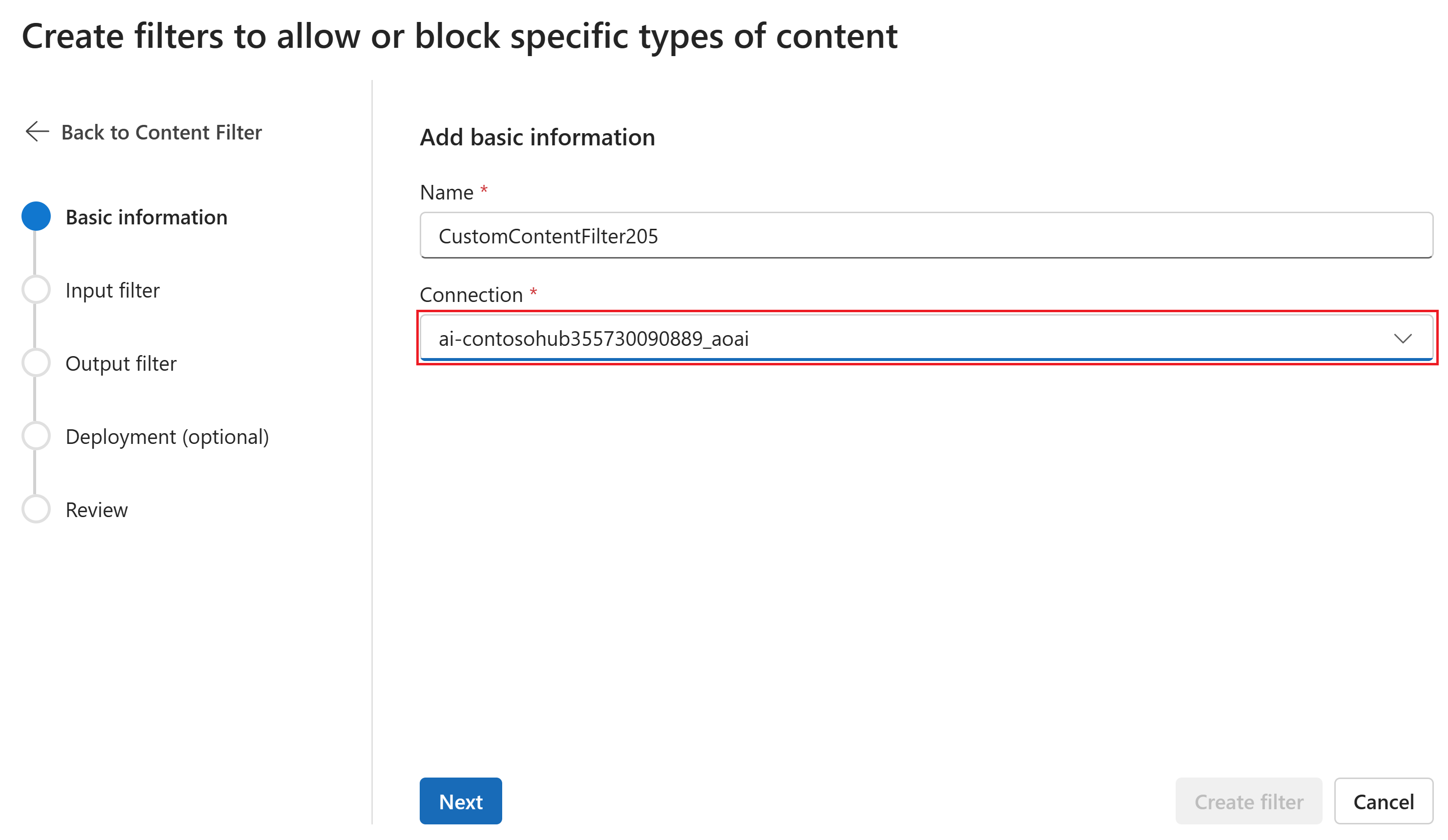
Na stronie Filtry wejściowe można ustawić filtr monitu wejściowego. Ustaw próg akcji i poziomu ważności dla każdego typu filtru. Na tej stronie skonfigurujesz zarówno domyślne filtry, jak i inne filtry (takie jak Monituj osłony na potrzeby ataków zabezpieczeń systemu) na tej stronie. Następnie kliknij przycisk Dalej.
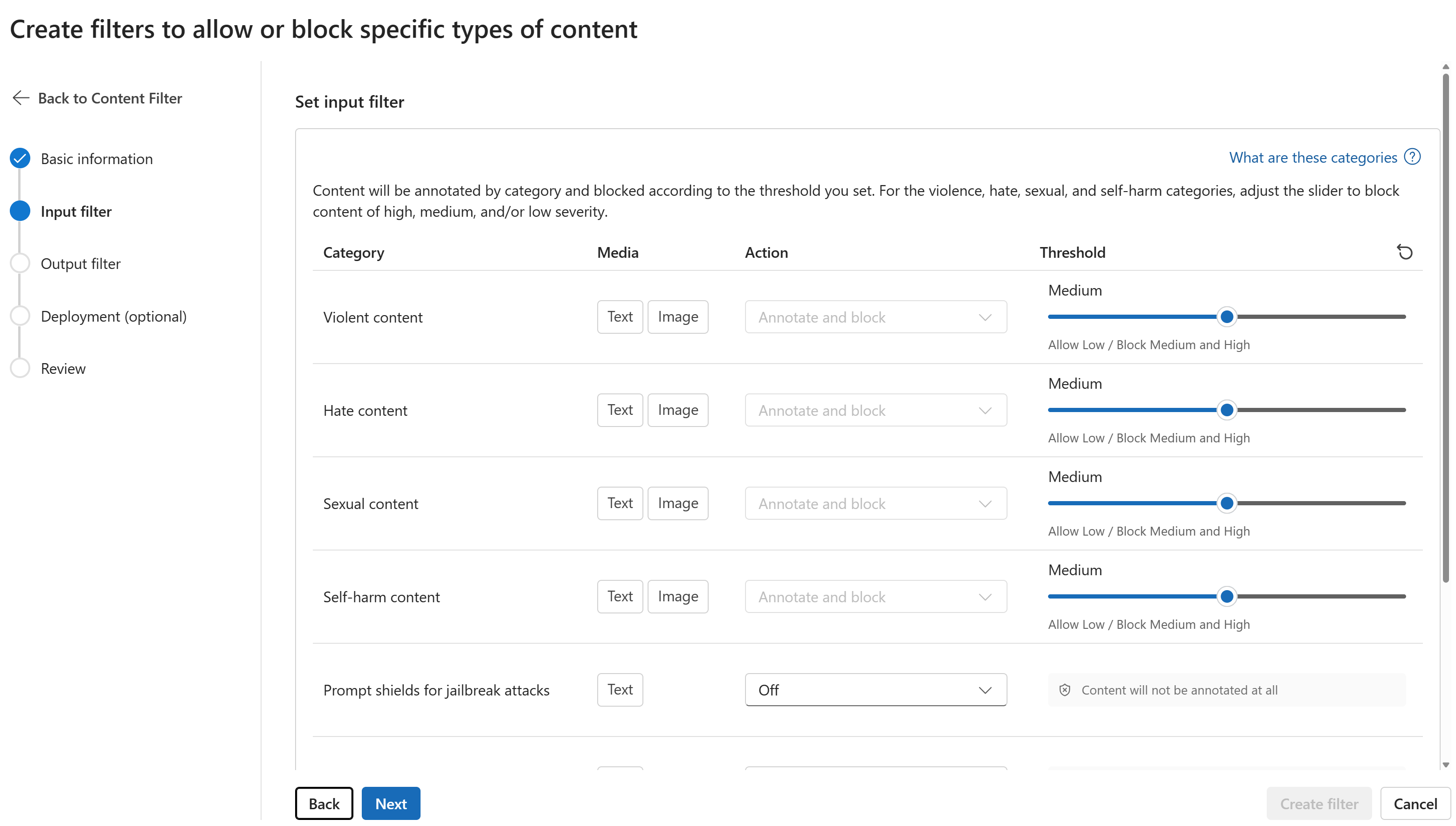
Zawartość zostanie oznaczona adnotacją według kategorii i zablokowana zgodnie z ustawionym progiem. W przypadku kategorii przemocy, nienawiści, seksualnej i samookaleczenia dostosuj suwak, aby zablokować zawartość o wysokiej, średniej lub niskiej ważności.
Na stronie Filtry wyjściowe można skonfigurować filtr wyjściowy, który zostanie zastosowany do całej zawartości wyjściowej wygenerowanej przez model. Skonfiguruj poszczególne filtry tak jak poprzednio. Ta strona zawiera również opcję Tryb przesyłania strumieniowego, która umożliwia filtrowanie zawartości niemal w czasie rzeczywistym w miarę generowania przez model, co zmniejsza opóźnienie. Po zakończeniu wybierz pozycję Dalej.
Zawartość zostanie oznaczona adnotacjami dla każdej kategorii i zablokowana zgodnie z progiem. W przypadku treści brutalnych, treści z nienawiści, treści seksualnych i kategorii treści samookaleczenia dostosuj próg, aby zablokować szkodliwą zawartość z równym lub wyższym poziomem ważności.
Opcjonalnie na stronie Wdrożenie można skojarzyć filtr zawartości z wdrożeniem. Jeśli wybrane wdrożenie ma już dołączony filtr, musisz potwierdzić, że chcesz go zamienić. Filtr zawartości można również skojarzyć z wdrożeniem później. Wybierz pozycję Utwórz.
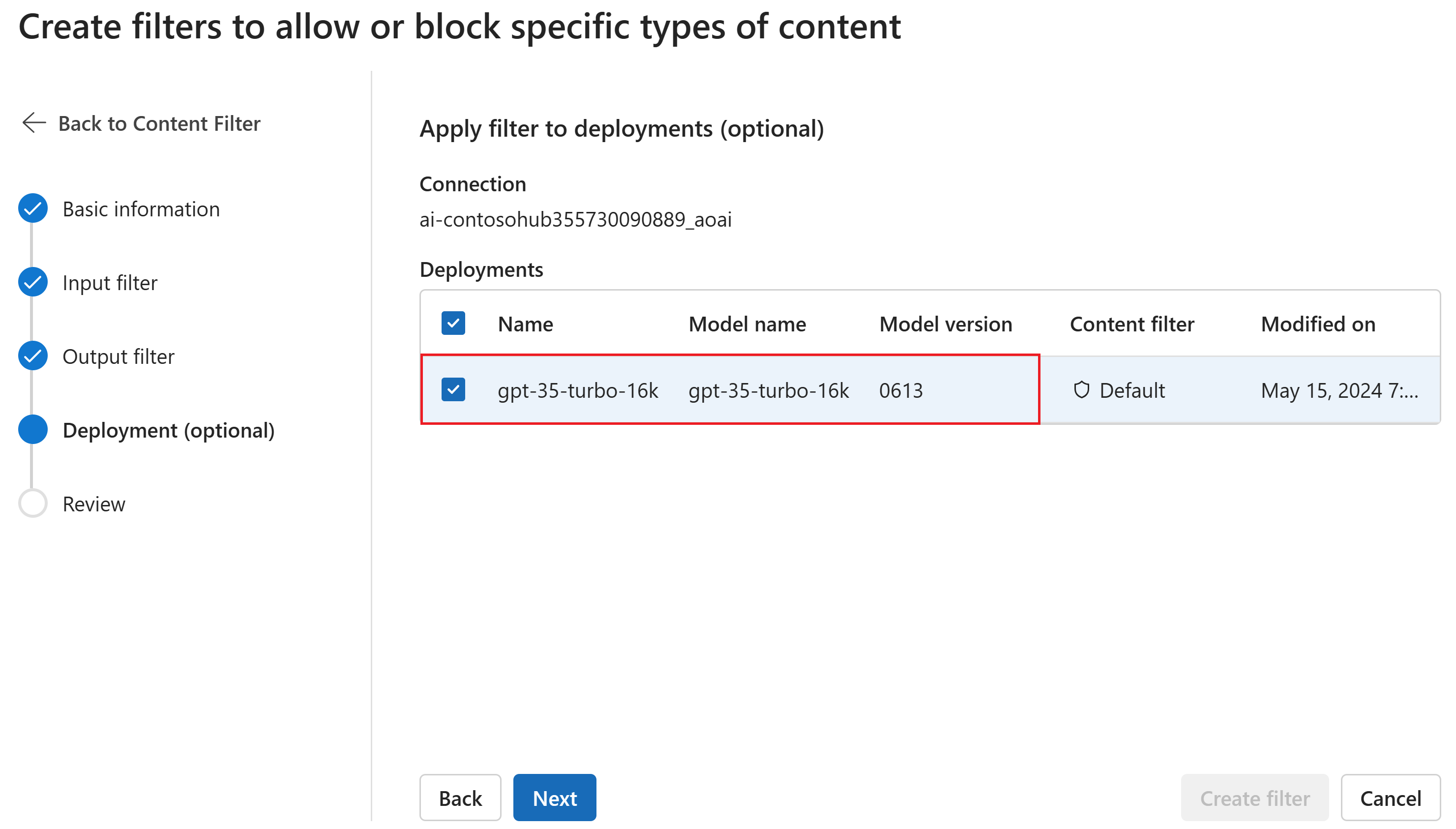
Konfiguracje filtrowania zawartości są tworzone na poziomie centrum w programie AI Studio. Dowiedz się więcej na temat możliwości konfigurowania w dokumentacji usługi Azure OpenAI.
Na stronie Przegląd przejrzyj ustawienia, a następnie wybierz pozycję Utwórz filtr.




Używanie listy bloków jako filtru
Listę bloków można zastosować jako filtr wejściowy lub wyjściowy albo oba te elementy. Włącz opcję Lista bloków na stronie Filtr danych wejściowych i/lub Filtr danych wyjściowych. Wybierz co najmniej jedną listę zablokowanych z listy rozwijanej lub użyj wbudowanej listy bloków wulgaryzmów. Można połączyć wiele list zablokowanych w ten sam filtr.
Stosowanie filtru zawartości
Proces tworzenia filtru umożliwia zastosowanie filtru do żądanych wdrożeń. Możesz również w dowolnym momencie zmieniać lub usuwać filtry zawartości z wdrożeń.
Wykonaj następujące kroki, aby zastosować filtr zawartości do wdrożenia:
Przejdź do programu AI Studio i wybierz projekt.
Wybierz pozycję Wdrożenia i wybierz jedno z wdrożeń, a następnie wybierz pozycję Edytuj.
W oknie Wdrażanie aktualizacji wybierz filtr zawartości, który chcesz zastosować do wdrożenia.



Teraz możesz przejść do placu zabaw, aby sprawdzić, czy filtr zawartości działa zgodnie z oczekiwaniami.
Kategorie
| Kategoria | opis |
|---|---|
| Nienawiść | Kategoria nienawiści opisuje ataki językowe lub zastosowania, które obejmują język pejoracyjny lub dyskryminacyjny z odniesieniem do osoby lub grupy tożsamości w oparciu o pewne atrybuty różnicowe tych grup, w tym rasę, pochodzenie etniczne, narodowość, tożsamość płci i wyrażenie, orientację seksualną, religię, status imigracji, status zdolności, wygląd osobisty i rozmiar ciała. |
| Seksualny | Kategoria seksualna opisuje język związany z anatomicznymi narządami i genitaliami, romantycznymi relacjami, aktami erotycznymi lub pieszczotliwymi, fizycznymi aktami seksualnymi, w tym tymi, które są przedstawiane jako napaść lub wymuszony akt przemocy seksualnej przeciwko woli, prostytucji, pornografii i nadużyć. |
| Przemoc | Kategoria przemocy opisuje język związany z działaniami fizycznymi mającymi na celu zranienie, uszkodzenie, uszkodzenie lub zabicie kogoś lub coś; opisuje broń itp. |
| Samookaleczenia | Kategoria samookaleczenia opisuje język związany z działaniami fizycznymi, które mają celowo zaszkodzić, ranić lub uszkodzić ciało lub zabić siebie. |
Poziomy ważności
| Kategoria | opis |
|---|---|
| Safe | Treści mogą być związane z przemocą, samookaleczenia, seksem lub nienawiści kategorii, ale terminy są używane ogólnie, dziennikarzy, naukowych, medycznych i podobnych kontekstów zawodowych, które są odpowiednie dla większości odbiorców. |
| Niski | Treści, które wyrażają uprzedzone, osądzone lub opinionowane poglądy, obejmują obraźliwe użycie języka, stereotypów, przypadków użycia eksplorujących fikcyjny świat (na przykład gry, literaturę) i obrazy o niskiej intensywności. |
| Śred. | Treści korzystające z obraźliwych, obraźliwych, szyderczych, zastraszających lub poniżających języka w określonych grupach tożsamości, obejmują przedstawienia poszukiwania i wykonywania szkodliwych instrukcji, fantazji, gloryfikacji, promocji szkody w średniej intensywności. |
| Wys. | Zawartość, która wyświetla jawne i poważne szkodliwe instrukcje, działania, szkody lub nadużycie; obejmuje poparcie, gloryfikację lub promowanie poważnych szkodliwych czynów, skrajnych lub nielegalnych form szkody, radykalizacji lub bezsensownej wymiany władzy lub nadużyć. |
Możliwość konfigurowania (wersja zapoznawcza)
Domyślna konfiguracja filtrowania zawartości dla serii modeli GPT jest ustawiona na filtrowanie według średniej ważności progowej dla wszystkich czterech kategorii szkody dla zawartości (nienawiści, przemocy, seksualnej i samookaleczenia) oraz ma zastosowanie do obu monitów (tekst, tekst, wielomodalny tekst/obraz) i uzupełnianie (tekst). Oznacza to, że zawartość wykryta na średnim lub wysokim poziomie ważności jest filtrowana, podczas gdy zawartość wykryta na niskim poziomie ważności nie jest filtrowana przez filtry zawartości. W przypadku języka DALL-E domyślny próg ważności jest niski dla monitów (tekstu) i uzupełniania (obrazów), więc zawartość wykryta na niskim poziomie ważności, średnim lub wysokim jest filtrowana.
Funkcja konfigurowania umożliwia klientom dostosowywanie ustawień, oddzielnie w celu wyświetlania monitów i uzupełniania, filtrowania zawartości dla każdej kategorii zawartości na różnych poziomach ważności, jak opisano w poniższej tabeli:
| Odfiltrowana ważność | Konfigurowalny pod kątem monitów | Możliwość konfigurowania pod kątem uzupełniania | Opisy |
|---|---|---|---|
| Niski, średni, wysoki | Tak | Tak | Najostrzejsza konfiguracja filtrowania. Zawartość wykryta na niskich, średnich i wysokich poziomach ważności jest filtrowana. |
| Średni, wysoki | Tak | Tak | Zawartość wykryta na niskim poziomie ważności nie jest filtrowana, zawartość w średnim i wysokim poziomie jest filtrowana. |
| Wys. | Tak | Tak | Zawartość wykryta na niskich i średnich poziomach ważności nie jest filtrowana. Filtrowana jest tylko zawartość na wysokim poziomie ważności. Wymaga zatwierdzenia1. |
| Brak filtrów | Jeśli zatwierdzono1 | Jeśli zatwierdzono1 | Żadna zawartość nie jest filtrowana niezależnie od wykrytego poziomu ważności. Wymaga zatwierdzenia1. |
1 W przypadku modeli usługi Azure OpenAI tylko klienci, którzy zostali zatwierdzeni do zmodyfikowanego filtrowania zawartości, mają pełną kontrolę filtrowania zawartości, w tym konfigurowanie filtrów zawartości na wysokim poziomie ważności lub wyłączanie filtrów zawartości. Zastosuj do zmodyfikowanych filtrów zawartości za pośrednictwem tego formularza: Przegląd ograniczonego dostępu usługi Azure OpenAI: zmodyfikowane filtry zawartości i monitorowanie nadużyć (microsoft.com)
Klienci są odpowiedzialni za zapewnienie, że aplikacje integrujące usługę Azure OpenAI są zgodne z kodeksem postępowania.
Inne filtry wejściowe
Możesz również włączyć specjalne filtry dla scenariuszy generowania sztucznej inteligencji:
- Ataki zabezpieczeń systemu: Ataki zabezpieczeń systemu są monitami użytkowników zaprojektowanymi w celu wywołania modelu generowania sztucznej inteligencji w celu wykazywania zachowań, które zostały wytrenowane w celu uniknięcia lub przerwania reguł ustawionych w komunikacie systemowym.
- Ataki pośrednie: ataki pośrednie, nazywane również atakami pośrednimi monitami lub atakami polegającymi na wstrzyknięciu monitów między domenami, są potencjalną luką w zabezpieczeniach, w której inne firmy umieszczają złośliwe instrukcje wewnątrz dokumentów, do których system generowania sztucznej inteligencji może uzyskiwać dostęp i przetwarzać.
Inne filtry wyjściowe
Można również włączyć następujące specjalne filtry wyjściowe:
- Materiał chroniony dla tekstu: tekst chroniony materiałowy opisuje znaną zawartość tekstową (na przykład teksty piosenek, artykuły, przepisy i wybraną zawartość internetową), którą można uzyskać w dużych modelach językowych.
- Materiał chroniony dla kodu: Kod chroniony materiału opisuje kod źródłowy zgodny z zestawem kodu źródłowego z repozytoriów publicznych, które mogą być wyprowadzane przez duże modele językowe bez odpowiedniego cytowania repozytoriów źródłowych.
- Uziemienie: filtr wykrywania uziemienia wykrywa, czy odpowiedzi tekstowe dużych modeli językowych (LLM) są uziemione w materiałach źródłowych dostarczonych przez użytkowników.
Następne kroki
- Dowiedz się więcej o modelach bazowych, które zasilają usługę Azure OpenAI.
- Filtrowanie zawartości usługi Azure AI Studio jest obsługiwane przez bezpieczeństwo zawartości usługi Azure AI.
- Dowiedz się więcej o zrozumieniu i ograniczaniu ryzyka związanego z aplikacją: Omówienie praktyk dotyczących odpowiedzialnej sztucznej inteligencji dla modeli Azure OpenAI.