Dane nierelacyjne i NoSQL
Nierelacyjna baza danych to baza danych , która nie korzysta ze schematu tabelarycznego wierszy i kolumn znalezionych w większości tradycyjnych systemów baz danych. Zamiast tego nierelacyjne bazy danych używają modelu magazynu zoptymalizowanego pod kątem określonych wymagań dotyczących typu przechowywanych danych. Na przykład dane mogą być przechowywane jako proste pary klucz/wartość, jako dokumenty JSON lub jako graf składający się z krawędzi i wierzchołków.
Wszystkie te magazyny danych są wspólne, to to, że nie korzystają z modelu relacyjnego. Ponadto zwykle są bardziej szczegółowe w typie danych, które obsługują i w jaki sposób można wykonywać zapytania dotyczące danych. Na przykład magazyny danych szeregów czasowych są zoptymalizowane pod kątem zapytań w sekwencjach danych opartych na czasie. Magazyny danych grafu są jednak zoptymalizowane pod kątem eksplorowania relacji ważonych między jednostkami. Żaden format nie uogólniłby zadania zarządzania danymi transakcyjnymi.
Termin NoSQL odnosi się do magazynów danych, które nie używają języka SQL do wykonywania zapytań. Zamiast tego magazyny danych używają innych języków programowania i konstrukcji do wykonywania zapytań dotyczących danych. W praktyce "NoSQL" oznacza "nierelacyjną bazę danych", mimo że wiele z tych baz danych obsługuje zapytania zgodne z językiem SQL. Jednak podstawowa strategia wykonywania zapytań jest zwykle bardzo różna od sposobu, w jaki tradycyjny system zarządzania relacyjnymi bazami danych (RDBMS) wykonuje to samo zapytanie SQL.
Istnieją różnice w implementacjach i specjalizacjach baz danych NoSQL, takich jak różnice w możliwościach relacyjnych baz danych. Te odmiany zapewniają każdej implementacji własne podstawowe mocne strony i są dostarczane z własną krzywą uczenia się i zaleceniami dotyczącymi użycia. W poniższych sekcjach opisano główne kategorie nierelacyjnej lub bazy danych NoSQL.
Magazyny danych dokumentów
Magazyn danych dokumentów zarządza zestawem nazwanych pól ciągów i wartości danych obiektu w jednostce nazywanej dokumentem. Te magazyny danych zwykle przechowują dane w postaci dokumentów JSON. Każda wartość pola może być elementem skalarnym, takim jak liczba, lub element złożony, taki jak lista lub kolekcja nadrzędny-podrzędny. Dane w polach dokumentu mogą być kodowane na różne sposoby, w tym XML, YAML, JSON, binarne dane JSON (BSON), a nawet przechowywane jako zwykły tekst. Pola w dokumentach są uwidocznione w systemie zarządzania magazynem, umożliwiając aplikacji wykonywanie zapytań o dane i filtrowanie ich przy użyciu wartości w tych polach.
Zazwyczaj dokument zawiera wszystkie dane dotyczące danej jednostki. Elementy, które składają się na jednostkę, są specyficzne dla danej aplikacji. Na przykład jednostka może zawierać dane dotyczące klienta, zamówienia lub kombinację obu tych elementów. Pojedynczy dokument może zawierać informacje, które byłyby rozmieszczone w kilku tabelach relacyjnych w systemie zarządzania relacyjnymi bazami danych (RDBMS). Magazyn dokumentów nie wymaga, aby wszystkie dokumenty miały taką samą strukturę. Takie swobodne podejście zapewnia dużą elastyczność. Na przykład aplikacje mogą przechowywać różne dane w dokumentach w odpowiedzi na zmiany wymagań biznesowych.
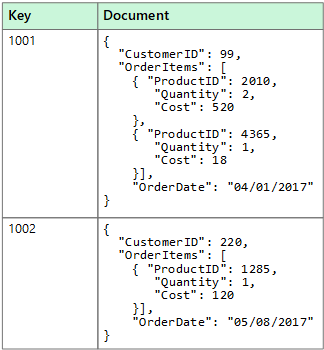
Aplikacja można pobierać dokumenty za pomocą klucza dokumentu. Klucz jest unikatowym identyfikatorem dokumentu, który jest często skrótem, aby ułatwić równomierne dystrybuowanie danych. Niektóre bazy danych dokumentów tworzą klucz dokumentu automatycznie. Inne umożliwiają określenie atrybutu dokumentu, który będzie używany jako klucz. Aplikacja może również wykonywać zapytania dotyczące dokumentów na podstawie wartości jednego lub kilku pól. Niektóre bazy danych dokumentów obsługują indeksowanie w celu ułatwienia szybkiego wyszukiwania dokumentów na podstawie jednego lub większej liczby indeksowanych pól.
Wiele baz danych dokumentów obsługuje aktualizacje „w miejscu”, umożliwiając aplikacji zmodyfikowanie wartości określonych pól w dokumencie bez konieczności ponownego zapisu całego dokumentu. Operacje odczytu i zapisu w wielu polach w jednym dokumencie są zwykle niepodzielne.
Odpowiednie usługi Azure:
Magazyny danych kolumnowych
Magazyn danych kolumnowy lub kolumnowy organizuje dane w kolumnach i wierszach. W najprostszej formie magazyn danych rodziny kolumn może wyglądać bardzo podobnie do relacyjnej bazy danych, przynajmniej koncepcyjnie. Prawdziwa siła bazy danych rodziny kolumn leży w jej zdenormalizowanym podejściu do struktury danych rozrzedzonego, co wynika z podejścia zorientowanego na kolumny do przechowywania danych.
Magazyn danych rodziny kolumn można traktować jako przechowywanie danych tabelarycznych z wierszami i kolumnami, ale kolumny są podzielone na grupy znane jako rodziny kolumn. Każda rodzina kolumn zawiera zestaw kolumn, które są logicznie powiązane i są zwykle pobierane lub manipulowane jako jednostka. Inne dane, które są dostępne oddzielnie, mogą być przechowywane w oddzielnych rodzinach kolumn. W obrębie rodziny kolumn nowe kolumny mogą być dodawane dynamicznie, a wiersze mogą być rozrzedzone (to znaczy, że wiersz nie musi mieć wartości dla każdej kolumny).
Na poniższym diagramie przedstawiono przykład z dwiema rodzinami kolumn: Identity i Contact Info. Dane dla pojedynczej jednostki mają ten sam klucz wiersza w każdej rodzinie kolumn. Ta struktura, w której wiersze dla dowolnego obiektu w rodzinie kolumn mogą się różnić dynamicznie, jest ważną zaletą podejścia rodziny kolumn, dzięki czemu ta forma magazynu danych jest bardzo odpowiednia do przechowywania danych z różnych schematów.

W przeciwieństwie do magazynu kluczy/wartości lub bazy danych dokumentów większość baz danych rodziny kolumn fizycznie przechowuje dane w kolejności kluczy, a nie przez obliczenie skrótu. Klucz wiersza jest traktowany jako indeks podstawowy i umożliwia dostęp oparty na kluczach za pośrednictwem określonego klucza lub zakresu kluczy. Niektóre implementacje umożliwiają tworzenie indeksów pomocniczych dla określonych kolumn w rodzinie kolumn. Indeksy pomocnicze umożliwiają pobieranie danych według wartości kolumn, a nie klucza wiersza.
Na dysku wszystkie kolumny w rodzinie kolumn są przechowywane razem w tym samym pliku, z określoną liczbą wierszy w każdym pliku. W przypadku dużych zestawów danych takie podejście zapewnia korzyść w zakresie wydajności dzięki zmniejszeniu ilości danych, które muszą być odczytywane z dysku, gdy tylko kilka kolumn jest jednocześnie odpytywanych jednocześnie.
Operacje odczytu i zapisu dla wiersza są zwykle niepodzielne w obrębie rodziny pojedynczej kolumny, chociaż niektóre implementacje zapewniają niepodzielność w całym wierszu, obejmujące wiele rodzin kolumn.
Odpowiednie usługi Azure:
Magazyny danych klucz/wartość
Magazyn klucz/wartość jest zasadniczo dużą tablicą skrótów. Należy powiązać wszystkie wartości danych z unikatowym kluczem, a magazyn klucz/wartość użyje tego klucza do przechowywania danych za pomocą odpowiedniego algorytmu wyznaczania wartości skrótu. Algorytm wyznaczania wartości skrótu jest wybrany w celu zapewnienia równomiernej dystrybucji skrótów kluczy w magazynie danych.
Większość magazynów klucz/wartość obsługuje wyłącznie proste operacje zapytania, wstawiania i usuwania. Aby zmodyfikować wartość (częściowo lub całkowicie), aplikacja musi zastąpić istniejące dane dla całej wartości. W większości implementacji odczyt lub zapis pojedynczej wartości jest operacją niepodzielną. Jeśli wartość jest duża, zapisywanie może trochę potrwać.
Aplikacja może przechowywać dowolne dane jako zbiór wartości, mimo że niektóre magazyny klucz/wartość nakładają ograniczenia dotyczące maksymalnego rozmiaru wartości. Przechowywane wartości są nieprzezroczyste dla oprogramowania systemu przechowywania. Każda informacja o schemacie musi być podana i zinterpretowana przez aplikację. Zasadniczo wartości są obiektami blob, a magazyn klucz/wartość po prostu pobiera lub przechowuje wartość według klucza.
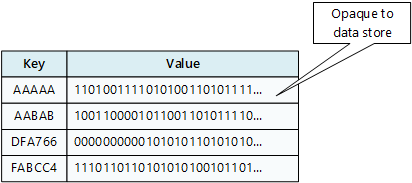
Magazyny klucz/wartość są wysoce zoptymalizowane pod kątem aplikacji wykonujących proste wyszukiwania przy użyciu wartości klucza lub przez zakres kluczy, ale są mniej odpowiednie dla systemów, które muszą wykonywać zapytania o dane w różnych tabelach kluczy/wartości, takich jak łączenie danych między wieloma tabelami.
Magazyny klucz/wartość nie są również zoptymalizowane pod kątem scenariuszy, w których wykonywanie zapytań lub filtrowanie według wartości innych niż kluczowe jest ważne, a nie wykonywanie odnośników tylko na podstawie kluczy. Na przykład w przypadku relacyjnej bazy danych można znaleźć rekord przy użyciu klauzuli WHERE, aby filtrować kolumny inne niż kluczowe, ale magazyny kluczy/wartości zwykle nie mają tego typu funkcji wyszukiwania dla wartości lub jeśli tak, wymaga to powolnego skanowania wszystkich wartości.
Pojedynczy magazyn klucz/wartość może być wysoce skalowalny, ponieważ magazyn danych może z łatwością rozpowszechniać dane w wielu węzłach na oddzielnych komputerach.
Odpowiednie usługi Azure:
Magazyny danych programu Graph
Magazyn danych grafu zarządza dwoma typami informacji, węzłami i krawędziami. Węzły reprezentują jednostki, a krawędzie określają relacje między tymi jednostkami. Zarówno węzły, jak i krawędzie mogą mieć właściwości, które dostarczają informacje na temat tego węzła lub krawędzi, podobnie jak kolumny w tabeli. Krawędzie mogą także mieć kierunek wskazujący rodzaj relacji.
Celem magazynu danych grafu jest umożliwienie aplikacji wydajnego wykonywania zapytań przechodzących przez sieć węzłów i krawędzi oraz analizowanie relacji między jednostkami. Na poniższym diagramie przedstawiono dane personelu organizacji ustrukturyzowane jako graf. Jednostkami są pracownicy i działy, a krawędzie wskazują relacje dotyczące składania raportów oraz działy, w których pracuje dany pracownik. Na tym grafie strzałki wskazują kierunek relacji.
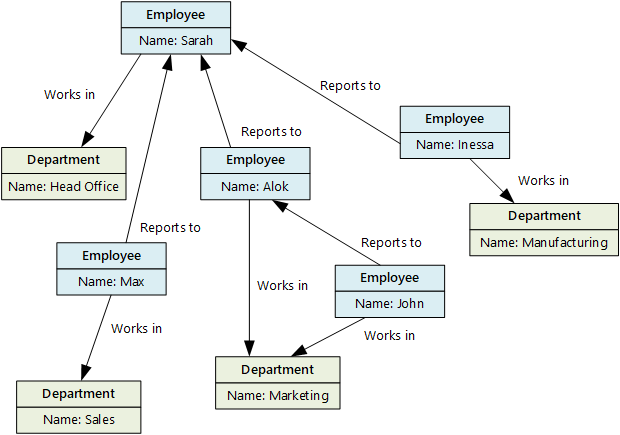
Ta struktura ułatwia wykonywanie zapytań, takich jak "Znajdź wszystkich pracowników, którzy zgłaszają się bezpośrednio lub pośrednio do Sarah" lub "Kto pracuje w tym samym dziale co Jan?" W przypadku dużych grafów z dużą częścią jednostek i relacji można szybko wykonywać złożone analizy. Wiele baz danych wykresu dostarcza język zapytania, który umożliwia wydajne przechodzenie przez sieć relacji.
Odpowiednie usługi Azure:
Magazyny danych szeregów czasowych
Dane szeregów czasowych to zestaw wartości zorganizowanych według czasu, a magazyn danych szeregów czasowych jest zoptymalizowany pod kątem tego typu danych. Magazyny danych szeregów czasowych muszą obsługiwać bardzo dużą liczbę zapisów, ponieważ zwykle zbierają duże ilości danych w czasie rzeczywistym z dużej liczby źródeł. Magazyny danych szeregów czasowych są zoptymalizowane pod kątem przechowywania danych telemetrycznych. Scenariusze obejmują czujniki IoT lub liczniki systemu/aplikacji. Aktualizacje są rzadkie, a usuwanie jest realizowane często jako operacje zbiorcze.
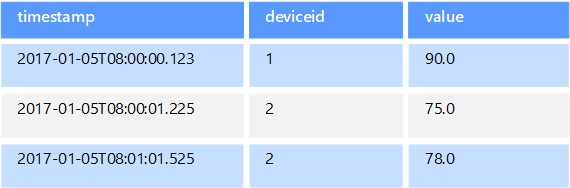
Mimo że rekordy zapisywane do bazy danych szeregów czasowych zwykle są małe, są często bardzo liczne, przez co całkowity rozmiar danych szybko rośnie. Magazyny danych szeregów czasowych obsługują również dane nieaktualne i opóźnione, automatyczne indeksowanie punktów danych i optymalizacje zapytań opisanych pod względem czasu. Ta ostatnia funkcja umożliwia szybkie uruchamianie zapytań w milionach punktów danych i wielu strumieni danych w celu obsługi wizualizacji szeregów czasowych, co jest typowym sposobem korzystania z danych szeregów czasowych.
Odpowiednie usługi Azure:
Magazyny danych obiektów
Magazyny danych obiektów są zoptymalizowane pod kątem przechowywania i pobierania dużych obiektów binarnych lub obiektów blob, takich jak obrazy, pliki tekstowe, strumienie wideo i audio, obiekty danych i dokumenty dużych aplikacji oraz obrazy dysków maszyny wirtualnej. Obiekt składa się z przechowywanych danych, niektórych metadanych i unikatowego identyfikatora na potrzeby uzyskiwania dostępu do obiektu. Magazyny obiektów są przeznaczone do obsługi plików, które są indywidualnie bardzo duże, a także zapewniają duże ilości całkowitego miejsca do zarządzania wszystkimi plikami.
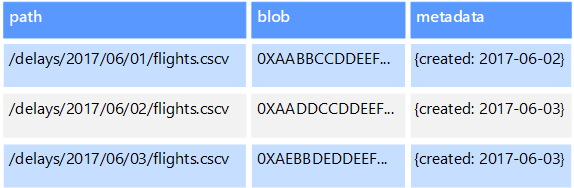
Niektóre magazyny danych obiektów replikują dany obiekt blob w wielu węzłach serwera, co umożliwia szybkie operacje odczytu równoległego. Z kolei ten proces umożliwia skalowanie w poziomie zapytań dotyczących danych zawartych w dużych plikach, ponieważ wiele procesów, zwykle uruchomionych na różnych serwerach, może jednocześnie wykonywać zapytania dotyczące dużego pliku danych.
Jednym ze specjalnych przypadków magazynów danych obiektów jest sieciowy udział plików. Korzystanie z udziałów plików umożliwia uzyskiwanie dostępu do plików w sieci przy użyciu standardowych protokołów sieciowych, takich jak blok komunikatów serwera (SMB). Biorąc pod uwagę odpowiednie mechanizmy zabezpieczeń i współbieżnej kontroli dostępu, udostępnianie danych w ten sposób może umożliwić rozproszonym usługom zapewnienie wysoce skalowalnego dostępu do danych dla podstawowych operacji niskiego poziomu, takich jak proste żądania odczytu i zapisu.
Odpowiednie usługi Azure:
Zewnętrzne magazyny danych indeksu
Zewnętrzne magazyny danych indeksu umożliwiają wyszukiwanie informacji przechowywanych w innych magazynach danych i usługach. Indeks zewnętrzny działa jako indeks pomocniczy dla dowolnego magazynu danych i może służyć do indeksowania ogromnych ilości danych i zapewnia niemal w czasie rzeczywistym dostęp do tych indeksów.
Na przykład pliki tekstowe mogą być przechowywane w systemie plików. Znalezienie pliku według ścieżki pliku jest szybkie, ale wyszukiwanie na podstawie zawartości pliku wymagałoby skanowania wszystkich plików, co jest powolne. Indeks zewnętrzny umożliwia tworzenie pomocniczych indeksów wyszukiwania, a następnie szybkie znajdowanie ścieżki do plików spełniających kryteria. Innym przykładem zastosowania indeksu zewnętrznego jest magazyn klucz/wartość, który indeksuje tylko według klucza. Indeks pomocniczy można utworzyć na podstawie wartości w danych i szybko wyszukać klucz, który jednoznacznie identyfikuje każdy dopasowany element.
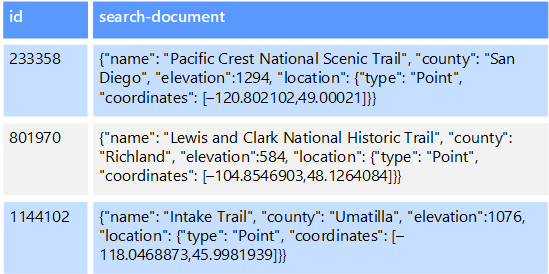
Indeksy są tworzone przez uruchomienie procesu indeksowania. Można to wykonać przy użyciu modelu ściągania, wyzwalanego przez magazyn danych lub modelu wypychania zainicjowanego przez kod aplikacji. Indeksy mogą być wielowymiarowe i mogą obsługiwać wyszukiwania bez tekstu w dużych ilościach danych tekstowych.
Zewnętrzne magazyny danych indeksów są często używane do obsługi wyszukiwania pełnotekstowego i internetowego. W takich przypadkach wyszukiwanie może być dokładne lub rozmyte. Wyszukiwanie rozmyte znajduje dokumenty zgodne z zestawem warunków i oblicza, w jakim stopniu są zgodne z wyszukiwaniem. Niektóre indeksy zewnętrzne obsługują również analizę językową, która może zwracać dopasowania w oparciu o synonimy, rozszerzenia gatunku (na przykład dopasowywanie "psy" do "zwierząt domowych") i stemming (na przykład wyszukiwanie "run" również pasuje do "ran" i "running").
Odpowiednie usługi Azure:
Typowe wymagania
Magazyny danych nierelacyjnych często używają innej architektury magazynu niż używana przez relacyjne bazy danych. W szczególności mają tendencję do braku stałego schematu. Ponadto zwykle nie obsługują one transakcji ani nie ograniczają zakresu transakcji i zazwyczaj nie zawierają indeksów pomocniczych ze względu na skalowalność.
W porównaniu z wieloma tradycyjnymi relacyjnymi bazami danych, bazy danych NoSQL często oferują pożądany poziom elastyczności schematu i skalowalności platformy, ale czasami te korzyści kosztują słabszą spójność. Mimo że możesz elastycznie przechowywać dane, nadal musisz identyfikować i analizować wzorce dostępu do danych, a następnie zaprojektować odpowiedni schemat danych, w przeciwnym razie baza danych NoSQL może mieć duże obciążenie lub nieoczekiwane wzorce użycia.
Poniżej przedstawiono porównanie wymagań dla każdego z magazynów danych nierelacyjnych:
| Wymaganie | Dane dokumentu | Dane rodziny kolumn | Dane klucza/wartości | Dane grafu |
|---|---|---|---|---|
| Normalizacja | Nieznormalizowane | Nieznormalizowane | Nieznormalizowane | Znormalizowana |
| Schemat | Schemat podczas odczytywania | Rodziny kolumn zdefiniowane na podstawie zapisu, schematu kolumn podczas odczytu | Schemat podczas odczytywania | Schemat podczas odczytywania |
| Spójność (między transakcjami współbieżnych) | Spójność z możliwością dostosowania, gwarancje na poziomie dokumentu | Gwarancje na poziomie rodziny kolumn | Gwarancje na poziomie klucza | Gwarancje na poziomie grafu |
| Niepodzielność (zakres transakcji) | Kolekcja | Tabela | Tabela | Wykres |
| Strategia blokowania | Optymistyczne (blokada bezpłatna) | Pesymistyczne (blokady wierszy) | Optymistyczne (tag jednostki (ETag)) | |
| Wzorzec dostępu | Dostęp losowy | Agregacje na danych wysokich/szerokich | Dostęp losowy | Dostęp losowy |
| Indeksowanie | Indeksy podstawowe i pomocnicze | Indeksy podstawowe i pomocnicze | Tylko indeks podstawowy | Indeksy podstawowe i pomocnicze |
| Kształt danych | Dokument | Tabelaryczny z rodzinami kolumn zawierającymi kolumny | Klucz i wartość | Wykres zawierający krawędzie i wierzchołki |
| Rozrzedzone | Tak | Tak | Tak | Nie. |
| Szeroki (wiele kolumn/atrybutów) | Tak | Tak | Nie. | Nie. |
| Rozmiar dat | Małe (KB) do średniej (niskie mb/s) | Średnie (mb/s) do dużych (niska liczba gb) | Małe (KB) | Małe (KB) |
| Ogólna maksymalna skala | Bardzo duże (PB) | Bardzo duże (PB) | Bardzo duże (PB) | Duże (TB) |
| Wymaganie | Dane szeregu czasowego | Dane obiektu | Dane indeksu zewnętrznego |
|---|---|---|---|
| Normalizacja | Znormalizowana | Nieznormalizowane | Nieznormalizowane |
| Schemat | Schemat podczas odczytywania | Schemat podczas odczytywania | Schemat zapisu |
| Spójność (między transakcjami współbieżnych) | Brak | Brak | Brak |
| Niepodzielność (zakres transakcji) | Brak | Objekt | Brak |
| Strategia blokowania | Brak | Pesymistyczne (blokady obiektów blob) | Brak |
| Wzorzec dostępu | Dostęp losowy i agregacja | Dostęp sekwencyjny | Dostęp losowy |
| Indeksowanie | Indeksy podstawowe i pomocnicze | Tylko indeks podstawowy | Brak |
| Kształt danych | Tabelaryczny | Obiekt blob i metadane | Dokument |
| Rozrzedzone | Nie. | Brak | Nie. |
| Szeroki (wiele kolumn/atrybutów) | Nie. | Tak | Tak |
| Rozmiar dat | Małe (KB) | Duże (GBs) do bardzo dużych (TB) | Małe (KB) |
| Ogólna maksymalna skala | Duże (niskie TB) | Bardzo duże (PB) | Duże (niskie TB) |
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Zoiner Tejada | Dyrektor generalny i architekt
Następne kroki
- Dane relacyjne a NoSQL
- Omówienie rozproszonych baz danych NoSQL
- Podstawy danych platformy Microsoft Azure: eksplorowanie danych nierelacyjnych na platformie Azure
- Implementowanie modelu danych nierelacyjnych