W tym artykule przedstawiono drzewo decyzyjne i przykłady opcji wysokiej dostępności (HA) i odzyskiwania po awarii (DR) podczas wdrażania wielowarstwowych aplikacji infrastruktury jako usługi (IaaS) na platformie Azure.
Architektura
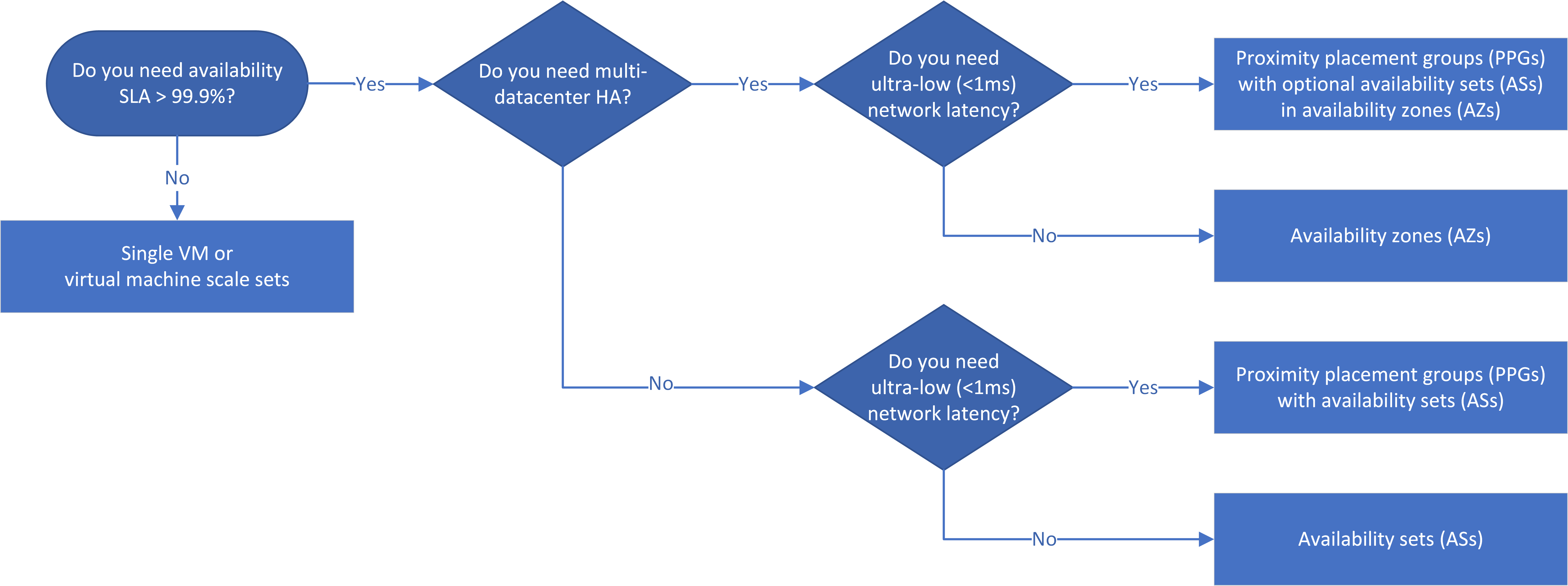
Przepływ pracy
Zestawy dostępności zapewniają nadmiarowość i dostępność maszyn wirtualnych w centrum danych przez dystrybucję maszyn wirtualnych w wielu izolowanych węzłach sprzętowych. Podzbiór maszyn wirtualnych działa podczas planowanych lub nieplanowanych przestojów, więc cała aplikacja pozostaje dostępna i operacyjna.
Strefy dostępności (AZ) to unikatowe lokalizacje fizyczne obejmujące centra danych w regionie świadczenia usługi Azure. Każdy moduł AZ uzyskuje dostęp do co najmniej jednego centrum danych, które mają niezależne zasilanie, chłodzenie i sieć, a każdy region platformy Azure z włączoną obsługą az ma co najmniej trzy oddzielne strefy dostępności. Fizyczne rozdzielenie stref dostępności w regionie chroni wdrożone maszyny wirtualne przed awarią centrum danych.
Schemat blokowy decyzji odzwierciedla zasadę, że aplikacje wysokiej dostępności powinny używać stref dostępności, jeśli to możliwe. Między strefami, a tym samym między centrami danych, wysoka dostępność zapewnia > umowę SLA na poziomie 99,99% ze względu na odporność na awarie centrum danych.
Usługi AS i AZ dla różnych warstw aplikacji nie mają gwarancji, że znajdują się w tych samych centrach danych. Jeśli opóźnienie aplikacji jest podstawowym problemem, należy kolokować usługi w jednym centrum danych przy użyciu grup umieszczania w pobliżu (PPG) z usługami AZ i ASs.
Składniki
Alternatywy
Alternatywą dla regionalnej odzyskiwania po awarii przy użyciu usługi Azure Site Recovery, jeśli aplikacja może replikować dane natywnie, możesz zaimplementować odzyskiwanie po awarii w wielu regionach przy użyciu serwerów rezerwowych gorąca/chłodna, takich jak klaster rozproszony tylko dla odzyskiwania po awarii. Ta alternatywa nie jest szczegółowo szczegółowo określona w przykładach, ale może zostać dodana do żadnego z rozwiązań. Należy pamiętać, że replikacja między regionami jest asynchroniczna, a oczekiwana jest utrata danych.
Alternatywnie, jeśli masz własną technologię replikacji danych, możesz użyć jej do utworzenia pomocniczej strefy w regionie na potrzeby odzyskiwania po awarii. W zależności od regionu obciążeń może być również możliwe użycie usługi Azure Site Recovery do replikowania elementów do alternatywnej strefy. Możesz sprawdzić dostępność regionalną i przeczytać więcej na temat tej funkcji w sekcji Włączanie odzyskiwania po awarii strefy do strefy dla maszyn wirtualnych platformy Azure.
Dostępność w wielu regionach jest możliwa, ale wymaga globalnego modułu równoważenia obciążenia, takiego jak usługa Front Door lub Traffic Manager. Aby uzyskać więcej informacji, zobacz Uruchamianie aplikacji N-warstwowej w wielu regionach świadczenia usługi Azure w celu zapewnienia wysokiej dostępności.
Szczegóły scenariusza
Architektury wielowarstwowe lub n-warstwowe są powszechne w tradycyjnych aplikacjach lokalnych, więc są naturalnym wyborem do migrowania aplikacji lokalnych do chmury lub podczas tworzenia aplikacji zarówno w środowisku lokalnym, jak i w chmurze. Architektury N-warstwowe są zwykle implementowane jako aplikacje IaaS podzielone na warstwy logiczne i warstwy fizyczne, z najwyższą warstwą internetową lub warstwą prezentacji, warstwą biznesową środkową i warstwą danych.
W aplikacji N-warstwowej IaaS każda warstwa jest uruchamiana na osobnym zestawie maszyn wirtualnych. Warstwy internetowe i biznesowe są bezstanowe, co oznacza, że każda maszyna wirtualna w warstwie może obsługiwać dowolne żądanie dla tej warstwy. Warstwa danych to replikowana baza danych, magazyn obiektów lub magazyn plików. Wiele maszyn wirtualnych w każdej warstwie zapewnia odporność, jeśli jedna maszyna wirtualna ulegnie awarii, a moduły równoważenia obciążenia dystrybuują żądania między maszynami wirtualnymi.
Warstwy można skalować w poziomie, dodając więcej maszyn wirtualnych do pul i używając zestawów skalowania maszyn wirtualnych, aby automatycznie skalować identyczne maszyny wirtualne. Ponieważ używasz modułów równoważenia obciążenia, możesz skalować warstwy w poziomie bez wpływu na czas działania aplikacji.
Jeśli umowa dotycząca poziomu usług (SLA) dla aplikacji IaaS wymaga > 99% dostępności, możesz umieścić maszyny wirtualne w zestawach dostępności, strefach dostępności i grupach umieszczania w pobliżu, aby skonfigurować wysoką dostępność aplikacji. Wybrane rozwiązania wysokiej dostępności i odzyskiwania po awarii zależą od wymaganej umowy SLA, zagadnień dotyczących opóźnień i regionalnych wymagań dotyczących odzyskiwania po awarii.
Potencjalne przypadki użycia
- Migrowanie aplikacji n-warstwowej ze środowiska lokalnego do chmury.
- Wdróż aplikację n-warstwową zarówno lokalną, jak i w chmurze.
- Konfigurowanie wysokiej dostępności i odzyskiwania po awarii dla aplikacji IaaS.
To rozwiązanie może być używane w dowolnej branży, w tym w następujących scenariuszach:
- Aplikacje sektora publicznego
- Bankowość (branża finansowa)
- Opieka zdrowotna
Kwestie wymagające rozważenia
Usługi AZ nie są dostępne we wszystkich regionach świadczenia usługi Azure.
Zdecyduj, której opcji wdrożenia chcesz użyć przed utworzeniem rozwiązania. Chociaż jest to możliwe, nie jest łatwe przejście z jednej opcji do innej po wdrożeniu. Należy usunąć maszyny wirtualne i utworzyć je ponownie z bazowych dysków zarządzanych, co jest procesem zaangażowanym.
Upewnij się, że możesz mapować aplikację na wybrane rozwiązanie. Wiele wzorców odporności i projektów warstw aplikacji wykracza poza zakres tego drzewa decyzyjnego.
Trzy scenariusze mogą prowadzić do ponownego uruchomienia maszyny wirtualnej platformy Azure: nieplanowana konserwacja sprzętu, nieoczekiwany przestój i planowana konserwacja. Aby uzyskać więcej informacji na temat tych zdarzeń i najlepszych rozwiązań dotyczących wysokiej dostępności w celu zmniejszenia ich wpływu, zobacz Omówienie ponownych uruchomień maszyn wirtualnych, konserwacji i przestojów.
Pojedyncze maszyny wirtualne
Jeśli aplikacja nie wymaga > dostępności 99,9%, nie musisz jej konfigurować pod kątem wysokiej dostępności i można wdrożyć pojedyncze maszyny wirtualne. Zestawy skalowania maszyn wirtualnych umożliwiają automatyczne skalowanie identycznych maszyn wirtualnych. Wdróż pojedyncze maszyny wirtualne bez określania strefy, aby były dystrybuowane w całym regionie. Te aplikacje mają umowę SLA na 99,9% w przypadku korzystania z dysków SSD w warstwie Premium platformy Azure.
Pojedyncze maszyny wirtualne używają domyślnej funkcji naprawiania usługi wbudowanej we wszystkie centra danych platformy Azure. W przypadku przewidywalnych awarii ta funkcja zwykle używa migracji na żywo, ale podczas nieprzewidywalnych zdarzeń maszyny wirtualne mogą być ponownie uruchamiane lub niedostępne.
Wysoka dostępność
Jeśli aplikacja wymaga umowy SLA > 99,9%, zaprojektuj aplikację pod kątem wysokiej dostępności. Jeśli to możliwe, użyj stref AZ, ponieważ zapewniają odporność na uszkodzenia centrum danych. Usługi ASs można używać zamiast stref AZ, ale użycie usług ASs zmniejsza dostępność z 99,99% do 99,95%, ponieważ usługi ASs nie mogą tolerować awarii centrum danych.
Systemy AZ są odpowiednie dla wielu scenariuszy aplikacji klastrowanych, w tym klastrów SQL AlwaysOn, przy użyciu aktywne-aktywne, aktywne-pasywne lub kombinacji obu poziomów wysokiej dostępności w każdej warstwie z szybkim trybem failover. Replikacja synchroniczna jest możliwa między dowolnymi węzłami systemu zarządzania bazami danych (DBMS) ze względu na małe opóźnienie sieci między strefami. Można również uruchomić konfigurację rozproszonego klastra w różnych strefach, która ma większe opóźnienie i obsługuje replikację asynchroniczną.
Jeśli chcesz użyć arbitera klastra opartego na maszynie wirtualnej, na przykład monitora udziału plików, umieść go w trzecim az, aby upewnić się, że kworum nie zostanie utracone w przypadku awarii jednej strefy. Alternatywnie możesz użyć monitora opartego na chmurze w innym regionie.
Wszystkie maszyny wirtualne w az znajdują się w jednej domenie błędów (FD) i domenie aktualizacji (UD), co oznacza, że współużytkują wspólne źródło zasilania i przełącznik sieciowy i wszystkie mogą być ponownie uruchamiane w tym samym czasie. Jeśli tworzysz maszyny wirtualne w różnych strefach dostępności, maszyny wirtualne są skutecznie dystrybuowane między różnymi identyfikatorami FD i UD, dzięki czemu nie wszystkie te maszyny nie zostaną uruchomione ponownie ani nie zostaną uruchomione ponownie w tym samym czasie. Jeśli chcesz mieć nadmiarowe maszyny wirtualne w strefie, a także maszyny wirtualne między strefami, należy umieścić maszyny wirtualne w strefie strefowej w usługach AS w grupach PPG, aby upewnić się, że nie wszystkie te maszyny zostaną uruchomione ponownie jednocześnie. Nawet w przypadku obciążeń maszyn wirtualnych z pojedynczym wystąpieniem, które nie są obecnie nadmiarowe, można nadal opcjonalnie używać usług AS w grupach zabezpieczeń, aby umożliwić przyszły wzrost i elastyczność.
W przypadku wdrażania zestawów skalowania maszyn wirtualnych w strefach AZ rozważ użycie trybu orkiestracji, obecnie w publicznej wersji zapoznawczej, co umożliwia łączenie dysków FD i stref AZ.
Strefy Zabezpieczeń ze strefą PPG umożliwiają jedno z najniższych opóźnień sieci na platformie Azure, a umowa SLA co najmniej 99,99% ze względu na odporność wielu centrów danych. W miarę możliwości używaj przyspieszonej sieci na maszynach wirtualnych.
To rozwiązanie może stanowić scenariusz, w którym usługa uruchomiona na maszynie wirtualnej w jednej strefie musi wchodzić w interakcje z usługą w innej strefie. Na przykład w różnych strefach może istnieć warstwa internetowa aktywna-aktywna i pasywna warstwa bazy danych. Niektóre żądania będą przekraczać strefy, co powoduje opóźnienie. Chociaż opóźnienie między strefami jest nadal bardzo niskie, jeśli musisz zapewnić najmniejsze możliwe opóźnienie, zachowaj całą komunikację sieciową między warstwami aplikacji w strefie.
Zagadnienia dotyczące opóźnień
Opóźnienie sieci zależy między innymi od odległości fizycznej między wdrożonymi maszynami wirtualnymi. Jeśli aplikacja wymaga bardzo małego opóźnienia między warstwami, możesz wdrożyć ją w jednym centrum danych przy użyciu grupy ppg z usługami AS dla każdej warstwy. Jeśli to możliwe, użyj przyspieszonej sieci na maszynach wirtualnych. Ten scenariusz pozwala na jedno z najniższych opóźnień sieci na platformie Azure oraz umowę SLA na poziomie 99,95%.
Poniższe narzędzia umożliwiają uzyskanie lepszego wglądu w warunki opóźnienia dla różnych scenariuszy:
- Aby przetestować opóźnienie między maszynami wirtualnymi, zobacz Testowanie opóźnienia sieci maszyn wirtualnych.
- Aby przetestować opóźnienie między strefami, użyj narzędzia AvZone-Latency-Test. Ten test może pomóc w ustaleniu, które strefy logiczne mają najmniejsze opóźnienie dla subskrypcji.
- Aby przetestować opóźnienie między regionami świadczenia usługi Azure, użyj polecenia http://www.azurespeed.com/. To regularnie aktualizowane narzędzie może być przydatne podczas rozważania replikacji asynchronicznej między regionami.
Odzyskiwanie po awarii
Zagadnienia dotyczące odzyskiwania po awarii obejmują dostępność, możliwość działania aplikacji w dobrej kondycji oraz trwałość danych, zachowywanie danych w przypadku awarii.
Tryb failover wysokiej dostępności powinien być szybki, bez utraty danych i ma bardzo ograniczony wpływ na usługę. Natomiast tradycyjny tryb failover odzyskiwania po awarii może mieć dłuższy skojarzony cel czasu odzyskiwania (RTO) i cel punktu odzyskiwania (RPO) i jest asynchroniczny z potencjalną utratą danych.
Strefy dostępności dla wysokiej dostępności i odzyskiwania po awarii można wykorzystać przy użyciu innej strefy dostępności dla rozwiązania odzyskiwania po awarii. Strefy dostępności są wystarczająco blisko, aby mieć połączenia o małych opóźnieniach z innymi strefami dostępności (opóźnienie rundy mniejsze niż 2 ms). Jednak są one wystarczająco daleko od siebie, aby zmniejszyć prawdopodobieństwo, że lokalne awarie lub pogoda mogą mieć wpływ na więcej niż jedną strefę dostępności. W przypadku obciążeń o znaczeniu krytycznym należy rozważyć rozwiązanie, które używa wielu regionów oprócz wielu stref dostępności.
Usługa Azure Site Recovery umożliwia replikowanie maszyn wirtualnych do innego regionu świadczenia usługi Azure na potrzeby regionalnego odzyskiwania po awarii i ciągłości działania. Usługa Azure Site Recovery umożliwia odzyskiwanie aplikacji w przypadku awarii w regionie źródłowym lub przeprowadzanie okresowych prób odzyskiwania po awarii w celu zapewnienia spełnienia wymagań dotyczących zgodności.
Jeśli twoja aplikacja obsługuje usługę Azure Site Recovery, możesz udostępnić regionalne rozwiązanie odzyskiwania po awarii w celu zwiększenia ochrony, jeśli wymaga tego krytyczność aplikacji. Jednak sama wysoka dostępność między strefami między centrami danych może być wystarczająca, ponieważ jeśli aplikacja jest w pełni odporna na awarie centrum danych, nie powinno być żadnych przestojów ani utraty danych.
Optymalizacja kosztów
Nie ma dodatkowych kosztów dla maszyn wirtualnych wdrożonych w systemach AZ. Mogą istnieć dodatkowe opłaty za transfer danych między maszynami wirtualnymi między modułami AZ. Aby uzyskać więcej informacji, zobacz stronę Cennik przepustowości.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Shaun Croucher | Starszy konsultant
Następne kroki
- Zestawy dostępności
- Strefy dostępności
- Zestawy skalowania maszyn wirtualnych
- Włączanie odzyskiwania po awarii między strefami dla maszyn wirtualnych platformy Azure
Powiązane zasoby
- Styl architektury N-warstwowej
- Wielowarstwowa aplikacja internetowa utworzona na potrzeby wysokiej dostępności i odzyskiwania po awarii na platformie Azure
- Uruchamianie strefowo nadmiarowej aplikacji internetowej w celu zapewnienia wysokiej dostępności
- Uruchamianie aplikacji internetowej w wielu regionach świadczenia usługi Azure w celu uzyskania wysokiej dostępności
- Uruchamianie aplikacji N-warstwowej w wielu regionach świadczenia usługi Azure w celu zapewnienia wysokiej dostępności