Ta przykładowa architektura jest oparta na przykładowej architekturze podstawowej aplikacji internetowej i rozszerza ją w celu pokazania:
- Sprawdzone rozwiązania dotyczące zwiększania skalowalności i wydajności w aplikacji internetowej usługi aplikacja systemu Azure Service
- Jak uruchomić aplikację usługi aplikacja systemu Azure w wielu regionach, aby uzyskać wysoką dostępność
Architektura
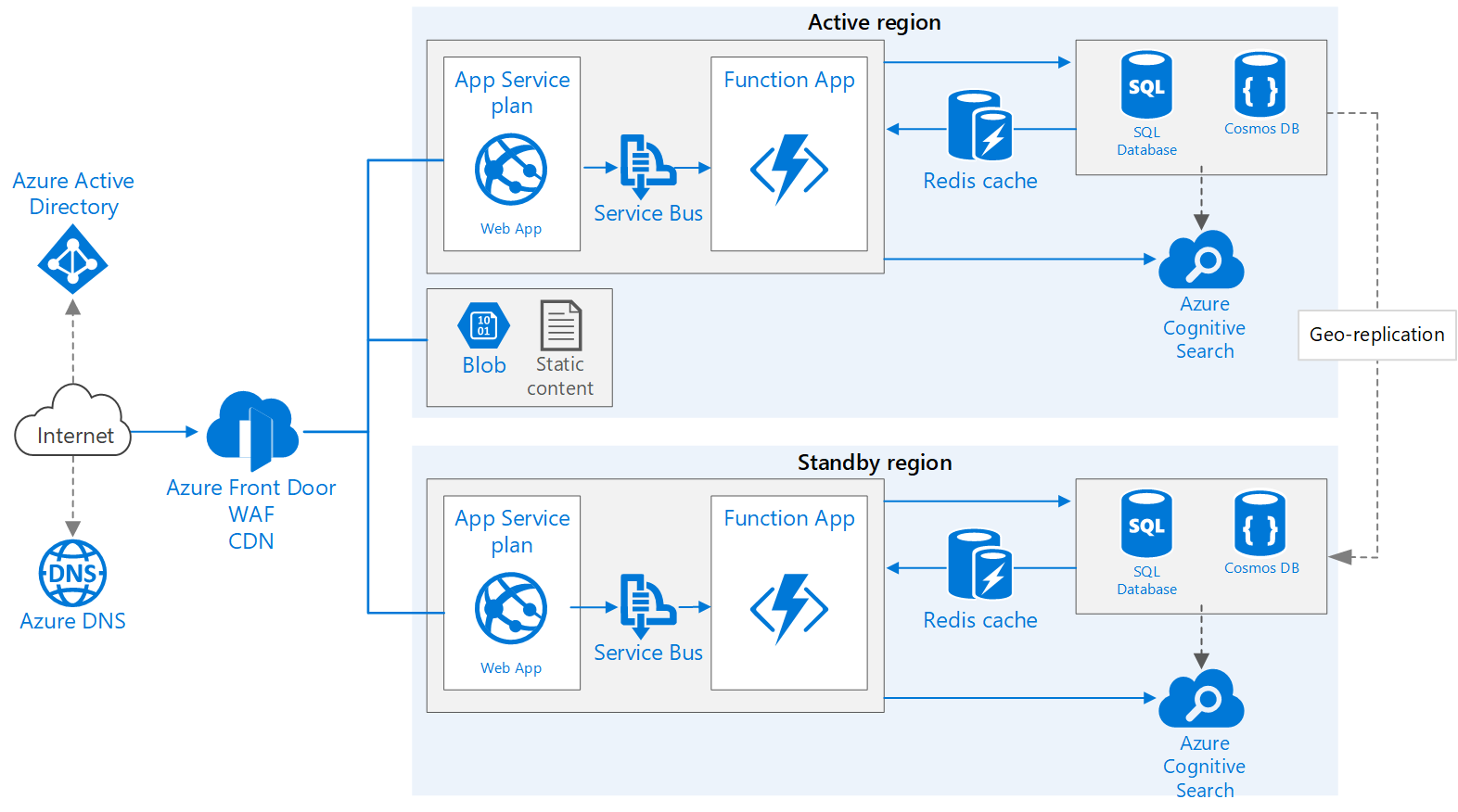
Pobierz plik programu Visio z tą architekturą.
Przepływ pracy
Ten przepływ pracy dotyczy aspektów architektury w wielu regionach i opiera się na podstawowej aplikacji internetowej.
- Region podstawowy i pomocniczy. W tej architekturze do osiągnięcia wyższej dostępności są używane dwa regiony. Aplikacja jest wdrażana w każdym regionie. Podczas wykonywania zwykłych operacji ruch sieciowy jest kierowany do regionu podstawowego. Jeśli region podstawowy staje się niedostępny, ruch jest kierowany do regionu pomocniczego.
- Front Door. Usługa Azure Front Door jest zalecanym modułem równoważenia obciążenia w przypadku implementacji obejmujących wiele regionów. Integruje się z zaporą aplikacji internetowej w celu ochrony przed typowymi programami wykorzystującymi luki w zabezpieczeniach i korzysta z natywnej funkcji buforowania zawartości usługi Front Door. W tej architekturze usługa Front Door jest skonfigurowana pod kątem routingu priorytetowego , który wysyła cały ruch do regionu podstawowego, chyba że stanie się niedostępny. Jeśli region podstawowy stanie się niedostępny, usługa Front Door kieruje cały ruch do regionu pomocniczego.
- Replikacja geograficzna kont magazynu, usługi SQL Database i/lub usługi Azure Cosmos DB.
Uwaga
Aby zapoznać się ze szczegółowym omówieniem korzystania z usługi Azure Front Door dla architektur obejmujących wiele regionów, w tym w konfiguracji zabezpieczonej przez sieć, zobacz Implementacja bezpiecznego ruchu przychodzącego sieci.
Składniki
Kluczowe technologie używane do implementowania tej architektury:
- Microsoft Entra ID to oparta na chmurze usługa zarządzania tożsamościami i dostępem, która umożliwia pracownikom dostęp do aplikacji w chmurze opracowanych dla organizacji.
- Azure DNS to usługa hostingowa przeznaczona dla domen DNS, która umożliwia rozpoznawanie nazw przy użyciu infrastruktury platformy Microsoft Azure. Dzięki hostowaniu swoich domen na platformie Azure możesz zarządzać rekordami DNS z zastosowaniem tych samych poświadczeń, interfejsów API, narzędzi i rozliczeń co w przypadku innych usług platformy Azure. Aby użyć niestandardowej nazwy domeny (takiej jak
contoso.com), utwórz rekordy DNS mapujące niestandardową nazwę domeny na adres IP. Aby uzyskać więcej informacji, zobacz Konfigurowanie niestandardowej nazwy domeny w usłudze Azure App Service. - Usługa Azure Content Delivery Network to globalne rozwiązanie do dostarczania zawartości o wysokiej przepustowości przez buforowanie jej w strategicznie umieszczonych węzłach fizycznych na całym świecie.
- Usługa Azure Front Door to moduł równoważenia obciążenia warstwy 7. W tej architekturze kieruje żądania HTTP do frontonu internetowego. Usługa Front Door udostępnia również zaporę aplikacji internetowej, która chroni aplikację przed typowymi lukami w zabezpieczeniach i lukami w zabezpieczeniach. Usługa Front Door jest również używana dla rozwiązania Content Delivery Network (CDN) w tym projekcie.
- aplikacja systemu Azure Service to w pełni zarządzana platforma do tworzenia i wdrażania aplikacji w chmurze. Umożliwia zdefiniowanie zestawu zasobów obliczeniowych dla aplikacji internetowej do uruchamiania, wdrażania aplikacji internetowych i konfigurowania miejsc wdrożenia.
- Aplikacje funkcji platformy Azure mogą służyć do uruchamiania zadań w tle. Funkcje są wywoływane przez wyzwalacz, taki jak zdarzenie czasomierza lub komunikat umieszczony w kolejce. W przypadku długotrwałych zadań stanowych należy użyć rozszerzenia Durable Functions.
- Azure Storage to rozwiązanie magazynu w chmurze dla nowoczesnych scenariuszy magazynowania danych, które oferuje wysoce dostępne, wysoce skalowalne, trwałe i bezpieczne magazyny dla różnych obiektów danych w chmurze.
- Azure Redis Cache to usługa buforowania o wysokiej wydajności, która zapewnia magazyn danych w pamięci umożliwiający szybsze pobieranie danych na podstawie implementacji pamięci podręcznej Redis Cache typu open source.
- Usługa Azure SQL Database to relacyjna baza danych jako usługa w chmurze. Usługa SQL Database współdzieli swój kod podstawowy z aparatem bazy danych programu Microsoft SQL Server.
- Azure Cosmos DB to globalnie rozproszona, w pełni zarządzana, mała opóźnienia, wielomodelowa, wielomodelowa baza danych interfejsu API do zarządzania danymi na dużą skalę.
- Usługa Azure Cognitive Search może służyć do dodawania funkcji wyszukiwania, takich jak sugestie wyszukiwania, wyszukiwanie rozmyte i wyszukiwanie specyficzne dla języka. Usługa Azure Search jest zwykle używana w połączeniu z innym magazynem danych, zwłaszcza gdy podstawowy magazyn danych wymaga ścisłej spójności. W tym podejściu autorytatywne dane są przechowywane w innym magazynie danych, a indeks wyszukiwania jest przechowywany w usłudze Azure Search. Usługa Azure Search pozwala też skonsolidować jeden indeks wyszukiwania z wielu magazynów danych.
Szczegóły scenariusza
Istnieje kilka ogólnych metod zapewniania wysokiej dostępności w różnych regionach:
Aktywne/pasywne z gorącą rezerwą: ruch przechodzi do jednego regionu, podczas gdy drugi czeka na gorącą rezerwę. Rezerwa gorąca oznacza, że usługa App Service w regionie pomocniczym jest przydzielana i zawsze działa.
Aktywny/pasywny z zimnym wstrzymaniem: ruch przechodzi do jednego regionu, podczas gdy drugi czeka na zimnym wstrzymaniu. Rezerwa na zimno oznacza, że usługa App Service w regionie pomocniczym nie zostanie przydzielona do czasu konieczności przejścia w tryb failover. Uruchomienie tej metody jest tańsze, ale na ogół przejście w tryb online po wystąpieniu awarii trwa dłużej.
Aktywne/aktywne: oba regiony są aktywne, a żądania są zrównoważone między nimi. Jeśli jeden region stanie się niedostępny, zostanie wycofany z rotacji.
Ta dokumentacja koncentruje się na aktywnych/pasywnych z rezerwą gorącą.
Potencjalne przypadki użycia
Te przypadki użycia mogą korzystać z wdrożenia w wielu regionach:
Projektowanie planu ciągłości działania i odzyskiwania po awarii dla aplikacji biznesowych.
Wdróż aplikacje o znaczeniu krytycznym, które działają w systemie Windows lub Linux.
Usprawnij środowisko użytkownika, zachowując dostępność aplikacji.
Zalecenia
Wymagania rzeczywiste mogą różnić się od dotyczących opisanej tu architektury. Użyj zaleceń w tej sekcji jako punktu wyjścia.
Parowanie regionalne
Każdy region platformy Azure jest powiązany z innym regionem w obrębie tego samego obszaru geograficznego. Na ogół regiony wybiera się z tej samej pary regionalnej (na przykład Wschodnie stany USA 2 i Środkowe stany USA). Takie postępowanie przynosi następujące korzyści:
- Jeśli wystąpi szeroka awaria, odzyskiwanie co najmniej jednego regionu z każdej pary jest priorytetem.
- Planowane aktualizacje systemu platformy Azure są wdrażane w powiązanych regionach po kolei, aby zminimalizować możliwe przestoje.
- W większości przypadków pary regionalne znajdują się w tej samej lokalizacji geograficznej, aby spełnić wymagania dotyczące rezydencji danych.
Jednak upewnij się, że oba regiony obsługują wszystkie usługi platformy Azure potrzebne dla aplikacji. Zobacz Usługi według regionów. Aby uzyskać więcej informacji na temat par regionalnych, zobacz Business continuity and disaster recovery (BCDR): Azure Paired Regions (Ciągłość działalności biznesowej i odzyskiwanie po awarii — BCDR: regiony sparowane platformy Azure).
Grupy zasobów
Rozważ umieszczenie regionu podstawowego, regionu pomocniczego i usługi Front Door w oddzielnych grupach zasobów. Ta alokacja umożliwia zarządzanie zasobami wdrożonym w każdym regionie jako pojedynczą kolekcją.
Aplikacje usługi App Service
Zaleca się utworzenie aplikacji internetowej i internetowego interfejsu API jako osobnych aplikacji usługi App Service. Taki projekt umożliwia uruchamianie ich w oddzielnych planach usługi App Service, dzięki czemu mogą być skalowane niezależnie. Jeśli początkowo nie potrzebujesz takiego poziomu skalowalności, możesz wdrożyć aplikacje w tym samym planie i później przenieść je do oddzielnych planów w razie potrzeby.
Uwaga
W przypadku planów Podstawowa, Standardowa, Premium i Izolowana opłaty są naliczane za wystąpienia maszyn wirtualnych w planie, a nie na aplikację. Zobacz Cennik usługi App Service
Konfiguracja usługi Front Door
Routing. Usługa Front Door obsługuje kilka mechanizmów routingu. W scenariuszu opisanym w tym artykule użyj routingu o priorytecie . Dzięki temu ustawieniu usługa Front Door wysyła wszystkie żądania do regionu podstawowego, chyba że punkt końcowy dla tego regionu stanie się niedostępny. W tym momencie automatycznie przechodzi w trybie failover do regionu pomocniczego. Ustaw pulę źródeł z różnymi wartościami priorytetu, 1 dla aktywnego regionu i 2 lub wyższe dla regionu rezerwowego lub pasywnego.
Sonda kondycji. Usługa Front Door używa sondy HTTPS do monitorowania dostępności każdego zaplecza. Sonda daje usłudze Front Door test powodzenia/niepowodzenia dla przejścia w tryb failover do regionu pomocniczego. Jej działanie polega na wysyłaniu żądania do określonej ścieżki URL. Jeśli przed upływem limitu czasu sonda uzyskuje odpowiedź inną niż 200, test kończy się niepowodzeniem. Można skonfigurować częstotliwość sondy kondycji, liczbę próbek wymaganych do oceny oraz liczbę pomyślnych próbek wymaganych do oznaczenia źródła jako w dobrej kondycji. Jeśli usługa Front Door oznaczy źródło jako obniżoną wydajność, przejdź w tryb failover do innego źródła. Aby uzyskać szczegółowe informacje, zobacz Sondy kondycji.
Najlepszym rozwiązaniem jest utworzenie ścieżki sondy kondycji w źródłach aplikacji, która zgłasza ogólną kondycję aplikacji. Ta sonda kondycji powinna sprawdzać krytyczne zależności, takie jak aplikacje usługi App Service, kolejka magazynu i usługa SQL Database. W przeciwnym razie sonda może zgłosić źródło dobrej kondycji, gdy krytyczne części aplikacji rzeczywiście kończą się niepowodzeniem. Z drugiej strony nie używaj sondy kondycji do sprawdzania usług o niższym priorytecie. Na przykład jeśli usługa poczty e-mail ulegnie awarii, aplikacja może przełączyć się na drugiego dostawcę lub po prostu wysłać wiadomości e-mail później. Aby uzyskać dalszą dyskusję na temat tego wzorca projektu, zobacz Wzorzec monitorowania punktu końcowego kondycji.
Zabezpieczanie źródeł z Internetu jest krytyczną częścią implementowania publicznie dostępnej aplikacji. Zapoznaj się z implementacją bezpiecznego ruchu przychodzącego sieci, aby dowiedzieć się więcej o zalecanych wzorcach projektowania i implementacji firmy Microsoft w celu zabezpieczenia komunikacji przychodzącej aplikacji z usługą Front Door.
Sieć CDN. Używanie natywnych funkcji cdN usługi Front Door do buforowania zawartości statycznej. Główną zaletą usługi CDN jest zmniejszenie opóźnień dla użytkowników, ponieważ zawartość jest buforowana na serwerze granicznym, który znajduje się blisko lokalizacji geograficznej użytkownika. Usługa CDN pomaga też zmniejszyć obciążenie aplikacji, ponieważ określony ruch nie jest obsługiwany przez aplikację. Usługa Front Door dodatkowo oferuje dynamiczne przyspieszanie witryn, co pozwala zapewnić lepsze ogólne środowisko użytkownika dla aplikacji internetowej, niż byłoby dostępne tylko przy użyciu buforowania zawartości statycznej.
Uwaga
Usługa CDN usługi Front Door nie jest przeznaczona do obsługi zawartości wymagającej uwierzytelniania.
SQL Database
Użyj aktywnej replikacji geograficznej i grup automatycznego trybu failover, aby zapewnić odporność baz danych. Aktywna replikacja geograficzna umożliwia replikowanie baz danych z regionu podstawowego do co najmniej jednego (do czterech) innych regionów. Grupy automatycznego trybu failover są oparte na aktywnej replikacji geograficznej, umożliwiając przejście w tryb failover do pomocniczej bazy danych bez żadnych zmian kodu w aplikacjach. Tryb failover można wykonać ręcznie lub automatycznie zgodnie z utworzonymi definicjami zasad. Aby użyć grup automatycznego trybu failover, należy skonfigurować parametry połączeń przy użyciu parametry połączenia trybu failover automatycznie utworzonego dla grupy trybu failover, a nie parametry połączenia poszczególnych baz danych.
Azure Cosmos DB
Usługa Azure Cosmos DB obsługuje replikację geograficzną między regionami we wzorcu aktywny-aktywny z wieloma regionami zapisu. Alternatywnie można wyznaczyć jeden region jako region zapisywalny, a inne jako repliki tylko do odczytu. Jeśli wystąpi awaria regionalna, możesz przejść w tryb failover, wybierając inny region jako region zapisu. Zestaw SDK klienta automatycznie wysyła żądania zapisu do bieżącego regionu zapisu, dlatego po przejściu w tryb failover nie musisz aktualizować konfiguracji klienta. Aby uzyskać więcej informacji, zobacz Globalna dystrybucja danych za pomocą usługi Azure Cosmos DB.
Storage
Na potrzeby usługi Azure Storage korzystaj z magazynu geograficznie nadmiarowego dostępnego do odczytu (RA-GRS). W przypadku magazynu RA-GRS dane są replikowane w regionie pomocniczym. Do danych w regionie pomocniczym masz dostęp tylko do odczytu za pośrednictwem oddzielnego punktu końcowego. Tryb failover inicjowany przez użytkownika do regionu pomocniczego jest obsługiwany w przypadku kont magazynu replikowanych geograficznie. Inicjowanie trybu failover konta magazynu automatycznie aktualizuje rekordy DNS w celu utworzenia pomocniczego konta magazynu nowego podstawowego konta magazynu. Tryb failover należy wykonać tylko wtedy, gdy uznasz, że jest to konieczne. To wymaganie jest definiowane przez plan odzyskiwania po awarii organizacji i należy wziąć pod uwagę implikacje zgodnie z opisem w sekcji Zagadnienia poniżej.
Jeśli wystąpi awaria regionalna lub awaria, zespół usługi Azure Storage może zdecydować się na przeprowadzenie geograficznego przejścia w tryb failover do regionu pomocniczego. W przypadku tych typów trybu failover nie jest wymagana żadna akcja klienta. Powrót po awarii do regionu podstawowego jest również zarządzany przez zespół usługi Azure Storage w tych przypadkach.
W niektórych przypadkach replikacja obiektów dla blokowych obiektów blob będzie wystarczającym rozwiązaniem replikacji dla obciążenia. Ta funkcja replikacji umożliwia kopiowanie pojedynczych blokowych obiektów blob z konta magazynu podstawowego do konta magazynu w regionie pomocniczym. Zalety tego podejścia to szczegółowa kontrola nad tym, jakie dane są replikowane. Zasady replikacji można zdefiniować w celu uzyskania bardziej szczegółowej kontroli typów replikowanych blokowych obiektów blob. Przykłady definicji zasad obejmują, ale nie są ograniczone do następujących elementów:
- Tylko blokowe obiekty blob dodane po utworzeniu zasad są replikowane
- Tylko blokowe obiekty blob dodane po danej dacie i godzinie są replikowane
- Replikowane są tylko blokowe obiekty blob pasujące do danego prefiksu.
W tym scenariuszu magazyn kolejek jest przywołyny jako alternatywna opcja obsługi komunikatów w usłudze Azure Service Bus. Jeśli jednak używasz magazynu kolejek dla rozwiązania do obsługi komunikatów, powyższe wskazówki dotyczące replikacji geograficznej mają zastosowanie, ponieważ magazyn kolejek znajduje się na kontach magazynu. Ważne jest jednak, aby zrozumieć, że komunikaty nie są replikowane do regionu pomocniczego, a ich stan jest niedostępny z regionu.
Azure Service Bus
Aby korzystać z najwyższej odporności oferowanej dla usługi Azure Service Bus, użyj warstwy Premium dla przestrzeni nazw. Warstwa Premium korzysta ze stref dostępności, co sprawia, że przestrzenie nazw są odporne na awarie centrum danych. Jeśli występuje powszechna awaria wpływająca na wiele centrów danych, funkcja odzyskiwania po awarii geograficznej dołączona do warstwy Premium może pomóc w odzyskaniu. Funkcja odzyskiwania po awarii geograficznej zapewnia, że cała konfiguracja przestrzeni nazw (kolejki, tematy, subskrypcje i filtry) jest stale replikowana z podstawowej przestrzeni nazw do pomocniczej przestrzeni nazw po połączeniu. Umożliwia to zainicjowanie jednorazowego przejścia w tryb failover z podstawowego do pomocniczego w dowolnym momencie. Przeniesienie trybu failover spowoduje ponowne wskazanie wybranej nazwy aliasu przestrzeni nazw do pomocniczej przestrzeni nazw, a następnie przerwanie parowania. Przejście w tryb failover jest niemal natychmiastowe po zainicjowaniu.
Azure Cognitive Search
W usłudze Cognitive Search dostępność jest osiągana za pośrednictwem wielu replik, podczas gdy ciągłość działania i odzyskiwanie po awarii (BCDR) są osiągane za pośrednictwem wielu usług wyszukiwania.
W usłudze Cognitive Search repliki są kopiami indeksu. Posiadanie wielu replik umożliwia usłudze Azure Cognitive Search ponowne uruchamianie maszyny i konserwację jednej repliki, podczas gdy wykonywanie zapytań jest kontynuowane w innych replikach. Aby uzyskać więcej informacji na temat dodawania replik, zobacz Dodawanie lub zmniejszanie replik i partycji.
Możesz użyć Strefy dostępności z usługą Azure Cognitive Search, dodając co najmniej dwie repliki do usługi wyszukiwania. Każda replika zostanie umieszczona w innej strefie dostępności w regionie.
Aby zapoznać się z zagadnieniami dotyczącymi bcDR, zapoznaj się z dokumentacją Wiele usług w oddzielnych regionach geograficznych .
Azure Cache for Redis
Mimo że wszystkie warstwy usługi Azure Cache for Redis oferują replikację w warstwie Standardowa w celu zapewnienia wysokiej dostępności, warstwa Premium lub Enterprise zaleca się zapewnienie wyższego poziomu odporności i możliwości odzyskiwania. Zapoznaj się z artykułem Wysoka dostępność i odzyskiwanie po awarii, aby uzyskać pełną listę funkcji odporności i możliwości odzyskiwania oraz opcji dla tych warstw. Wymagania biznesowe określają, która warstwa jest najlepsza dla infrastruktury.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Niezawodność
Niezawodność zapewnia, że aplikacja może spełnić zobowiązania podjęte przez klientów. Aby uzyskać więcej informacji, zobacz Omówienie filaru niezawodności. Podczas projektowania pod kątem wysokiej dostępności w różnych regionach należy wziąć pod uwagę te kwestie.
Azure Front Door
Usługa Azure Front Door automatycznie przełączy się w tryb failover, jeśli region podstawowy stanie się niedostępny. W przypadku przejścia usługi Front Door w tryb failover występuje okres czasu (zwykle około 20–60 sekund), gdy klienci nie mogą uzyskać dostępu do aplikacji. Na ten czas mają wpływ następujące czynniki:
- Częstotliwość sond kondycji. Częściej wysyłane są sondy kondycji, tym szybciej usługa Front Door może wykryć przestój lub źródło wracające w dobrej kondycji.
- Konfiguracja rozmiaru próbki. Ta konfiguracja określa, ile próbek jest wymaganych do sondy kondycji, aby wykryć, że źródło podstawowe stało się nieosiągalne. Jeśli ta wartość jest zbyt niska, możesz uzyskać wyniki fałszywie dodatnie z sporadycznych problemów.
Usługa Front Door jest punktem systemu, w którym mogą występować awarie. Jeśli usługa ulegnie awarii, klienci nie będą mogli uzyskać dostępu do aplikacji podczas przestoju. Zapoznaj się z dokumentem Front Door — umowa SLA i ustal, czy korzystanie z samej usługi Front Door spełnia Twoje wymagania biznesowe w zakresie wysokiej dostępności. Jeśli nie, rozważ dodanie kolejnego rozwiązania do zarządzania ruchem w ramach powrotu po awarii. W przypadku awarii usługi Front Door zmień rekordy nazwy kanonicznej (CNAME) w systemie DNS, aby wskazać inną usługę zarządzania ruchem. Ten krok musisz wykonać ręcznie, a aplikacja będzie niedostępna do czasu rozpropagowania zmian systemu DNS.
Usługa Azure Front Door w warstwie Standardowa i Premium łączy możliwości usługi Azure Front Door (wersja klasyczna), Azure CDN Standard from Microsoft (wersja klasyczna) i Azure WAF w jedną platformę. Korzystanie z usługi Azure Front Door Standard lub Premium zmniejsza punkty awarii i umożliwia lepszą kontrolę, monitorowanie i zabezpieczenia. Aby uzyskać więcej informacji, zobacz Omówienie warstwy usługi Azure Front Door.
SQL Database
Cel punktu odzyskiwania (RPO) i szacowany cel czasu odzyskiwania (RTO) dla usługi SQL Database są udokumentowane w temacie Overview of business continuity with Azure SQL Database (Omówienie ciągłości działania w usłudze Azure SQL Database).
Należy pamiętać, że aktywna replikacja geograficzna skutecznie podwaja koszt każdej replikowanej bazy danych. Bazy danych piaskownicy, testowania i programowania zwykle nie są zalecane do replikacji.
Azure Cosmos DB
Cel punktu odzyskiwania i cel czasu odzyskiwania (RTO) dla usługi Azure Cosmos DB można konfigurować za pośrednictwem używanych poziomów spójności, które zapewniają kompromis między dostępnością, trwałością danych i przepływnością. Usługa Azure Cosmos DB zapewnia minimalną wartość czasu odzyskiwania wynoszącą 0 dla złagodzonego poziomu spójności z wielowzorcowością lub cel punktu odzyskiwania wynoszący 0 w celu zapewnienia silnej spójności z pojedynczym wzorcem. Aby dowiedzieć się więcej na temat poziomów spójności usługi Azure Cosmos DB, zobacz Poziomy spójności i trwałość danych w usłudze Azure Cosmos DB.
Storage
Magazyn RA-GRS zapewnia trwały magazyn, ale należy wziąć pod uwagę następujące czynniki podczas rozważania przejścia w tryb failover:
Przewidywanie utraty danych: replikacja danych do regionu pomocniczego jest wykonywana asynchronicznie. W związku z tym w przypadku przejścia w tryb failover geograficznego należy przewidzieć utratę danych, jeśli zmiany na koncie podstawowym nie zostały w pełni zsynchronizowane z kontem pomocniczym. Możesz sprawdzić właściwość Czas ostatniej synchronizacji pomocniczego konta magazynu, aby zobaczyć, kiedy dane z regionu podstawowego zostały pomyślnie zapisane w regionie pomocniczym.
Zaplanuj cel czasu odzyskiwania (RTO) odpowiednio: przejście w tryb failover do regionu pomocniczego zwykle trwa około godziny, więc plan odzyskiwania po awarii powinien uwzględniać te informacje podczas obliczania parametrów celu czasu odzyskiwania.
Starannie zaplanuj powrót po awarii: ważne jest, aby zrozumieć, że gdy konto magazynu przełączy się w tryb failover, dane na oryginalnym koncie podstawowym zostaną utracone. Próba powrotu po awarii do regionu podstawowego bez starannego planowania jest ryzykowna. Po zakończeniu pracy w trybie failover nowy podstawowy — w regionie trybu failover — zostanie skonfigurowany dla magazynu lokalnie nadmiarowego (LRS). Należy ręcznie ponownie skonfigurować go jako magazyn replikowany geograficznie, aby zainicjować replikację do regionu podstawowego, a następnie dać wystarczający czas, aby umożliwić synchronizację kont.
Przejściowe błędy, takie jak awaria sieci, nie będą wyzwalać trybu failover magazynu. Zaprojektuj aplikację tak, aby była odporna na awarie przejściowe. Opcje ograniczania ryzyka obejmują:
- Odczytuj dane z regionu pomocniczego.
- Tymczasowo przełącz się na inne konto magazynu dla nowych operacji zapisu (na przykład w celu kolejkowania wiadomości).
- Skopiuj dane z regionu pomocniczego do innego konta magazynu.
- Zapewnij ograniczoną funkcjonalność do czasu powrotu systemu po awarii.
Aby uzyskać więcej informacji, zobacz Co zrobić po wystąpieniu awarii usługi Azure Storage.
Zapoznaj się z dokumentacją wymagań wstępnych i zastrzeżeń dotyczących replikacji obiektów, aby zapoznać się z zagadnieniami dotyczącymi używania replikacji obiektów dla blokowych obiektów blob.
Azure Service Bus
Ważne jest, aby zrozumieć, że funkcja odzyskiwania po awarii geograficznej w warstwie Premium usługi Azure Service Bus umożliwia natychmiastową ciągłość operacji z tą samą konfiguracją. Nie replikuje jednak komunikatów przechowywanych w kolejkach lub subskrypcjach tematu ani kolejkach utraconych komunikatów. W związku z tym wymagana jest strategia ograniczania ryzyka w celu zapewnienia bezproblemowego przejścia w tryb failover do regionu pomocniczego. Aby uzyskać szczegółowy opis innych zagadnień i strategii ograniczania ryzyka, zapoznaj się z ważnymi zagadnieniami, które należy wziąć pod uwagę i dokumentacji zagadnień dotyczących odzyskiwania po awarii .
Zabezpieczenia
Zabezpieczenia zapewniają ochronę przed celowymi atakami i nadużyciami cennych danych i systemów. Aby uzyskać więcej informacji, zobacz Omówienie filaru zabezpieczeń.
Ogranicz ruch przychodzący Skonfiguruj aplikację tak, aby akceptowała ruch tylko z usługi Front Door. Gwarantuje to, że cały ruch przechodzi przez zaporę aplikacji internetowej przed dotarciem do aplikacji. Aby uzyskać więcej informacji, zobacz Jak mogę zablokować dostęp do zaplecza tylko do usługi Azure Front Door?
Współużytkowanie zasobów między źródłami (CORS) Jeśli tworzysz witrynę internetową i internetowy interfejs API jako oddzielne aplikacje, witryna internetowa nie może wykonywać wywołań AJAX po stronie klienta do interfejsu API, chyba że włączysz mechanizm CORS.
Uwaga
Zabezpieczenia przeglądarki uniemożliwiają stronie internetowej wysyłanie żądań AJAX do innej domeny. To ograniczenie jest nazywane zasadami tego samego źródła i uniemożliwia złośliwej witrynie odczytywanie poufnych danych z innej witryny. CORS to standard W3C, dzięki któremu serwer może poluzować zasady tego samego źródła i zezwolić na niektóre żądania między źródłami, jednocześnie odrzucając inne.
Usługa App Service ma wbudowaną obsługę mechanizmu CORS — nie wymaga to pisania kodu aplikacji. Zobacz Korzystanie z aplikacji interfejsu API z poziomu języka JavaScript przy użyciu mechanizmu CORS. Dodaj witrynę internetową do listy dozwolonych źródeł dla interfejsu API.
Szyfrowanie usługi SQL Database używa funkcji Transparent Data Encryption, jeśli chcesz zaszyfrować dane magazynowane w bazie danych. Ta funkcja szyfruje i odszyfrowuje całą bazę danych w czasie rzeczywistym (w tym kopie zapasowe i pliki dzienników transakcji) oraz nie wymaga żadnych zmian w aplikacji. Szyfrowanie wprowadza pewne opóźnienie, więc warto umieścić dane, które muszą być bezpieczne, w osobnej bazie danych i włączyć szyfrowanie tylko dla tej bazy danych.
Tożsamość Podczas definiowania tożsamości dla składników tej architektury należy używać tożsamości zarządzanych przez system, jeśli to możliwe, aby zmniejszyć konieczność zarządzania poświadczeniami i ryzykiem związanym z zarządzaniem poświadczeniami. Jeśli nie można używać tożsamości zarządzanych przez system, upewnij się, że każda tożsamość zarządzana użytkownika istnieje tylko w jednym regionie i nigdy nie jest współdzielona przez granice regionów.
Zapory usług Podczas konfigurowania zapór usługi dla składników upewnij się, że tylko usługi lokalne w regionie mają dostęp do usług i że usługi zezwalają tylko na połączenia wychodzące, które są jawnie wymagane do replikacji i funkcjonalności aplikacji. Rozważ użycie usługi Azure Private Link w celu uzyskania dalszej rozszerzonej kontroli i segmentacji. Aby uzyskać więcej informacji na temat zabezpieczania aplikacji internetowych, zobacz Punkt odniesienia aplikacji internetowej o wysokiej dostępności strefowo nadmiarowej.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Buforowanie Użyj buforowania, aby zmniejszyć obciążenie serwerów obsługujących zawartość, która nie zmienia się często. Każdy cykl renderowania strony może mieć wpływ na koszty, ponieważ zużywa zasoby obliczeniowe, pamięć i przepustowość. Koszty te można znacznie zmniejszyć przy użyciu buforowania, zwłaszcza w przypadku statycznych usług zawartości, takich jak aplikacje jednostronicowe Języka JavaScript i zawartość przesyłania strumieniowego multimediów.
Jeśli aplikacja ma zawartość statyczną, użyj usługi CDN, aby zmniejszyć obciążenie serwerów frontonu. W przypadku danych, które nie zmieniają się często, użyj usługi Azure Cache for Redis.
Aplikacje bezstanowe skonfigurowane do skalowania automatycznego są bardziej ekonomiczne niż aplikacje stanowe. W przypadku aplikacji ASP.NET, która używa stanu sesji, zapisz ją w pamięci za pomocą usługi Azure Cache for Redis. Aby uzyskać więcej informacji, zobacz ASP.NET Dostawca stanu sesji dla usługi Azure Cache for Redis. Inną opcją jest użycie usługi Azure Cosmos DB jako magazynu stanu zaplecza za pośrednictwem dostawcy stanu sesji. Zobacz Use Azure Cosmos DB as an ASP.NET session state and caching provider (Używanie usługi Azure Cosmos DB jako dostawcy stanu sesji i buforowania).
Funkcje należy rozważyć umieszczenie aplikacji funkcji w dedykowanym planie usługi App Service, aby zadania w tle nie działały na tych samych wystąpieniach, które obsługują żądania HTTP. Jeśli zadania w tle są uruchamiane sporadycznie, rozważ użycie planu zużycia, który jest rozliczany na podstawie liczby użytych wykonań i zasobów, a nie godzinowo.
Aby uzyskać więcej informacji, zobacz sekcję kosztów w witrynie Microsoft Azure Well-Architected Framework.
Użyj kalkulatora cen, aby oszacować koszty. Te zalecenia w tej sekcji mogą pomóc w zmniejszeniu kosztów.
Azure Front Door
Rozliczenia usługi Azure Front Door mają trzy warstwy cenowe: transfery danych wychodzących, transfery danych przychodzących i reguły routingu. Aby uzyskać więcej informacji, zobacz Cennik usługi Azure Front Door. Wykres cenowy nie obejmuje kosztów uzyskiwania dostępu do danych z usług pochodzenia i transferu do usługi Front Door. Te koszty są rozliczane na podstawie opłat za transfer danych opisanych w temacie Szczegóły cennika przepustowości.
Azure Cosmos DB
Istnieją dwa czynniki określające cennik usługi Azure Cosmos DB:
Aprowizowana przepływność lub jednostki żądań na sekundę (RU/s).
Istnieją dwa typy przepływności, które można aprowizować w usłudze Azure Cosmos DB, w warstwie Standardowa i Autoskalowanie. Przepływność Standardowa przydziela zasoby wymagane do zagwarantowania określonej jednostki RU/s. W przypadku skalowania automatycznego aprowizujesz maksymalną przepływność, a usługa Azure Cosmos DB natychmiast skaluje się w górę lub w dół w zależności od obciążenia, co najmniej 10% maksymalnej przepływności skalowania automatycznego. Standardowa przepływność jest rozliczana za aprowizowaną przepływność co godzinę. Opłata za przepływność autoskalowania jest naliczana za maksymalną zużytą co godzinę przepływność.
Wykorzystany magazyn. Opłaty są naliczane w wysokości ryczałtowej za łączną ilość miejsca do magazynowania (GB) zużywaną dla danych i indeksów przez daną godzinę.
Aby uzyskać więcej informacji, zapoznaj się z sekcją kosztów w temacie Dobrze zaprojektowana struktura platformy Microsoft Azure.
Efektywność wydajności
Główną zaletą usługi Azure App Service jest możliwość skalowania aplikacji w zależności od obciążenia. Poniżej przedstawiono kilka kwestii, które należy wziąć pod uwagę, planując skalowanie aplikacji.
Aplikacja usługi App Service
Jeśli Twoje rozwiązanie zawiera kilka aplikacji usługi App Service, rozważ wdrożenie ich w oddzielnych planach tej usługi. Takie podejście umożliwia ich niezależne skalowanie, ponieważ są one uruchamiane w osobnych wystąpieniach.
SQL Database
Zwiększ skalowalność bazy danych SQL, dzieląc ją na fragmenty. Dzielenie na fragmenty dotyczy partycjonowania bazy danych w poziomie. Dzielenie na fragmenty umożliwia skalowanie bazy danych w poziomie przy użyciu narzędzi elastycznych baz danych. Potencjalne zalety dzielenia na fragmenty:
- Większa przepływność transakcji.
- Zapytania mogą działać szybciej na podzestawie danych.
Azure Front Door
Usługa Front Door może odciążać protokół SSL, a także zmniejsza łączną liczbę połączeń TCP z aplikacją internetową zaplecza. Zwiększa to skalowalność, ponieważ aplikacja internetowa zarządza mniejszą liczbą uzgadniań SSL i połączeń TCP. Te wzrosty wydajności mają zastosowanie nawet w przypadku przekazywania żądań do aplikacji internetowej jako protokołu HTTPS ze względu na wysoki poziom ponownego użycia połączenia.
Azure Search
Usługa Azure Search eliminuje narzut związany z przeprowadzaniem złożonych wyszukiwań danych z podstawowego magazynu danych oraz zapewnia skalowalność niezbędną do obsługi obciążenia. Zobacz Poziomy skalowania zasobów dla obciążeń związanych z zapytaniami i indeksowaniem w usłudze Azure Search.
Doskonałość operacyjna
Doskonałość operacyjna odnosi się do procesów operacyjnych, które wdrażają aplikację i działają w środowisku produkcyjnym, i stanowi rozszerzenie wytycznych dotyczących niezawodności dobrze zaprojektowanej struktury. Te wskazówki zawierają szczegółowy przegląd tworzenia architektury odporności w strukturze aplikacji w celu zapewnienia dostępności obciążeń i możliwości odzyskiwania po awariach w dowolnej skali. Podstawowym zestawem tego podejścia jest zaprojektowanie infrastruktury aplikacji pod kątem wysokiej dostępności, optymalnie w wielu regionach geograficznych, jak pokazano w tym projekcie.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Arvind Boggaram Pandurangaiah Setty | Starszy konsultant
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
Szczegółowe omówienie usługi Azure Front Door — metody routingu ruchu
Tworzenie sond kondycji, które raportują ogólną kondycję aplikacji na podstawie wzorców monitorowania punktów końcowych
Włączanie grup automatycznego trybu failover usługi Azure SQL
Powiązane zasoby
Aplikacja N-warstwowa w wielu regionach jest podobnym scenariuszem. Przedstawia ona aplikację N-warstwową działającą w wielu regionach świadczenia usługi Azure