Ta architektura referencyjna przedstawia zestaw sprawdzonych rozwiązań dotyczących uruchamiania aplikacji n-warstwowej w wielu regionach platformy Azure w celu uzyskania dostępności i niezawodnej infrastruktury odzyskiwania po awarii.
Architektura
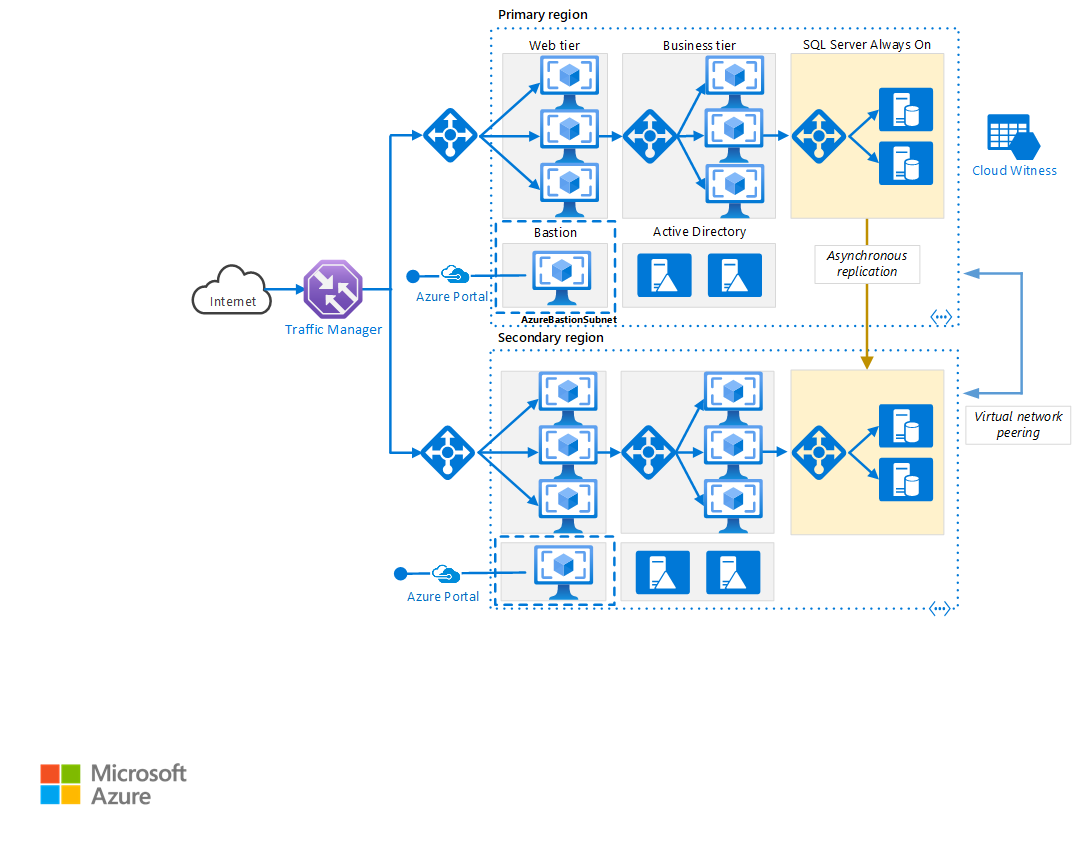
Pobierz plik programu Visio z tą architekturą.
Przepływ pracy
Region podstawowy i pomocniczy. Aby osiągnąć wyższą dostępność, użyj dwóch regionów. Jeden jest regionem podstawowym. Drugi region jest przeznaczony dla trybu failover.
Azure Traffic Manager. Usługa Traffic Manager kieruje żądania przychodzące do jednego z regionów. Podczas wykonywania zwykłych operacji kieruje żądania do regionu podstawowego. Jeśli ten region staje się niedostępny, usługa Traffic Manager przechodzi w trybie failover do regionu pomocniczego. Aby uzyskać więcej informacji, zobacz sekcję Konfiguracja usługi Traffic Manager.
Grupy zasobów. Utwórz oddzielne grupy zasobów dla regionu podstawowego, regionu pomocniczego i usługi Traffic Manager. Ta metoda zapewnia elastyczność zarządzania poszczególnymi regionami jako pojedynczą kolekcją zasobów. Na przykład możesz ponownie wdrożyć jeden region, bez konieczności wyłączania drugiego. Połącz grupy zasobów, aby umożliwić uruchamianie zapytania wyświetlającego listę wszystkich zasobów dotyczących aplikacji.
Sieci wirtualne. Utwórz oddzielną sieć wirtualną dla każdego regionu. Upewnij się, że przestrzenie adresowe nie nakładają się na siebie.
Zawsze włączona grupa dostępności programu SQL Server. Jeśli używasz programu SQL Server, zalecamy zawsze włączone grupy dostępności SQL w celu zapewnienia wysokiej dostępności. Utwórz pojedynczą grupę dostępności zawierającą wystąpienia programu SQL Server w obu regionach.
Uwaga
Weź pod uwagę także usługę Azure SQL Database, która oferuje relacyjną bazę danych jako usługę w chmurze. Korzystając z usługi SQL Database, nie musisz konfigurować grupy dostępności ani zarządzać trybem failover.
Komunikacja równorzędna sieci wirtualnych. Za pomocą komunikacji równorzędnej dwie sieci wirtualne umożliwiają replikację danych z regionu podstawowego do regionu pomocniczego. Aby uzyskać więcej informacji, zobacz Komunikacja równorzędna sieci wirtualnych.
Składniki
- Zestawy dostępności zapewniają rozproszenie maszyn wirtualnych wdrożonych na platformie Azure pomiędzy wieloma izolowanymi węzłami sprzętowymi w klastrze. Jeśli na platformie Azure wystąpi awaria sprzętu lub oprogramowania, dotyczy to tylko podzbioru maszyn wirtualnych, a całe rozwiązanie pozostaje dostępne i operacyjne.
- Strefy dostępności chronią aplikacje i dane przed awariami centrum danych. Strefy dostępności są oddzielnymi lokalizacjami fizycznymi w regionie świadczenia usługi Azure. Każda strefa składa się z co najmniej jednego centrum danych wyposażonego w niezależne zasilanie, chłodzenie i sieć.
- Usługa Azure Traffic Manager to oparty na systemie DNS moduł równoważenia obciążenia ruchu, który optymalnie dystrybuuje ruch. Zapewnia ona usługi w globalnych regionach świadczenia usługi Azure z wysoką dostępnością i czasem reakcji.
- Usługa Azure Load Balancer dystrybuuje ruch przychodzący zgodnie ze zdefiniowanymi regułami i sondami kondycji. Moduł równoważenia obciążenia zapewnia małe opóźnienia i wysoką przepływność, skalując do milionów przepływów dla wszystkich aplikacji TCP i UDP. Publiczny moduł równoważenia obciążenia jest używany w tym scenariuszu do dystrybucji przychodzącego ruchu klienta do warstwy internetowej. Wewnętrzny moduł równoważenia obciążenia jest używany w tym scenariuszu do dystrybucji ruchu z warstwy biznesowej do klastra programu SQL Server zaplecza.
- Usługa Azure Bastion zapewnia bezpieczną łączność RDP i SSH ze wszystkimi maszynami wirtualnymi w sieci wirtualnej, w której jest aprowizowana. Użyj usługi Azure Bastion, aby chronić maszyny wirtualne przed uwidacznianie portów RDP/SSH na zewnątrz, jednocześnie zapewniając bezpieczny dostęp przy użyciu protokołu RDP/SSH.
Zalecenia
Architektura obejmująca wiele regionów może zapewnić większą dostępność niż wdrożenie w pojedynczym regionie. W przypadku wystąpienia regionalnej awarii, która będzie miała wpływ na region podstawowy, korzystając z usługi Traffic Manager, możesz przejść w trybie failover do regionu pomocniczego. Ta architektura może również pomóc w przypadku awarii poszczególnych podsystemów aplikacji.
Istnieje kilka ogólnych metod umożliwiających osiągnięcie wysokiej dostępności we wszystkich regionach:
- Aktywny/pasywny z rezerwą dynamiczną. Ruch jest przesyłany do jednego regionu, a drugi w tym czasie czeka w trybie rezerwy dynamicznej. Rezerwa gorąca oznacza, że maszyny wirtualne w regionie pomocniczym są przydzielane i zawsze działają.
- Aktywny/pasywny z rezerwą w stanie zimnym. Ruch jest przesyłany do jednego regionu, a drugi w tym czasie czeka w trybie rezerwy w stanie zimnym. Rezerwa na zimno oznacza, że maszyny wirtualne w regionie pomocniczym nie zostaną przydzielone do czasu potrzebnego do przejścia w tryb failover. Uruchomienie tej metody jest tańsze, ale na ogół przejście w tryb online po wystąpieniu awarii trwa dłużej.
- Aktywny/aktywny. Oba regiony są aktywne, a obciążenie żądaniami jest równomiernie rozkładane między nimi. Jeśli jeden region stanie się niedostępny, zostanie wycofany z rotacji.
W tej architekturze referencyjnej skoncentrowano się na metodzie „aktywny/pasywny z rezerwą dynamiczną”, a tryb failover korzysta z usługi Traffic Manager. W razie potrzeby można wdrożyć kilka maszyn wirtualnych na potrzeby rezerwy dynamicznej, a następnie skalować w poziomie.
Parowanie regionalne
Każdy region platformy Azure jest powiązany z innym regionem w obrębie tego samego obszaru geograficznego. Na ogół regiony wybiera się z tej samej pary regionalnej (na przykład Wschodnie stany USA 2 i Środkowe stany USA). Takie postępowanie przynosi następujące korzyści:
- Jeśli wystąpi szeroka awaria, odzyskiwanie co najmniej jednego regionu z każdej pary jest priorytetem.
- Planowane aktualizacje systemu platformy Azure są wdrażane w powiązanych regionach po kolei, aby zminimalizować możliwe przestoje.
- Pary znajdują się w tej samej lokalizacji geograficznej, aby spełnić wymagania dotyczące rezydencji danych.
Jednak upewnij się, że oba regiony obsługują wszystkie usługi platformy Azure potrzebne dla aplikacji (zobacz Usługi według regionów). Aby uzyskać więcej informacji na temat par regionalnych, zobacz Business continuity and disaster recovery (BCDR): Azure Paired Regions (Ciągłość działalności biznesowej i odzyskiwanie po awarii — BCDR: regiony sparowane platformy Azure).
Konfiguracja usługi Traffic Manager
Podczas konfigurowania usługi Traffic Manager weź pod uwagę następujące kwestie:
- Routing. Usługa Traffic Manager obsługuje kilka algorytmów routingu. Na potrzeby scenariusza opisanego w tym artykule zastosuj routing oparty na priorytecie (nazywany wcześniej routingiem dla trybu failover). Przy tym ustawieniu usługa Traffic Manager wysyła wszystkie żądania do regionu podstawowego, chyba że region podstawowy staje się niedostępny. W tym momencie automatycznie przechodzi w trybie failover do regionu pomocniczego. Zobacz Konfigurowanie metody routingu dla trybu failover.
- Sonda kondycji. Usługa Traffic Manager monitoruje dostępność każdego regionu za pomocą sondy HTTP (lub HTTPS). Sonda sprawdza odpowiedź HTTP 200 dla określonej ścieżki URL. Najlepszym rozwiązaniem jest utworzenie punktu końcowego, który będzie zgłaszał ogólną kondycję aplikacji, i używanie tego punktu końcowego na potrzeby sondy kondycji. W przeciwnym razie sonda może zgłaszać, że punkt końcowy jest w dobrej kondycji, podczas gdy krytyczne części aplikacji faktycznie nie działają prawidłowo. Aby uzyskać więcej informacji, zobacz Wzorzec monitorowania punktu końcowego kondycji.
W przypadku pracy w trybie failover usługi Traffic Manager występuje okres, w którym klienci nie mogą uzyskać dostępu do aplikacji. Na ten czas mają wpływ następujące czynniki:
- Sonda kondycji musi wykryć, że region podstawowy stał się niedostępny.
- Serwery DNS muszą zaktualizować rekordy DNS adresu IP w pamięci podręcznej, co zależy od czasu wygaśnięcia (TTL) DNS. Domyślny czas wygaśnięcia wynosi 300 sekund (5 minut), ale możesz skonfigurować tę wartość podczas tworzenia profilu usługi Traffic Manager.
Aby uzyskać szczegółowe informacje, zobacz About Traffic Manager Monitoring (Informacje dotyczące monitorowania usługi Traffic Manager).
W przypadku przejścia usługi Traffic Manager w tryb failover zalecamy przeprowadzenie ręcznego powrotu po awarii, zamiast implementowania automatycznego powrotu po awarii. W przeciwnym razie może powstać sytuacja, w której aplikacja będzie przełączała się tam i z powrotem między regionami. Przed powrotem po awarii sprawdź, czy wszystkie podsystemy aplikacji są w dobrej kondycji.
Usługa Traffic Manager automatycznie wraca domyślnie po awarii. Aby zapobiec temu problemowi, ręcznie obniż priorytet regionu podstawowego po zdarzeniu trybu failover. Na przykład załóżmy, że region podstawowy ma priorytet 1, a pomocniczy — 2. Po przejściu w tryb failover ustaw dla regionu podstawowego priorytet 3, aby uniknąć automatycznego powrotu po awarii. Gdy wszystko będzie gotowe do przełączenia z powrotem, zaktualizuj priorytet na 1.
Następujące polecenie interfejsu wiersza polecenia platformy Azure powoduje zaktualizowanie priorytetu:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
Innym podejściem jest tymczasowe wyłączenie punktu końcowego do momentu, gdy wszystko będzie gotowe do powrotu po awarii:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
W zależności od przyczyny przejścia w tryb failover może być konieczne ponowne wdrożenie zasobów w obrębie regionu. Przed powrotem po awarii wykonaj test gotowości do działania. Test powinien sprawdzić m.in., czy:
- Maszyny wirtualne są poprawnie skonfigurowane. (Całe wymagane oprogramowanie jest zainstalowane, usługi IIS działają itd.).
- Podsystemy aplikacji są w dobrej kondycji.
- Aplikacja jest funkcjonalna. (Na przykład warstwa bazy danych jest dostępna z warstwy internetowej).
Konfigurowanie zawsze włączonych grup dostępności programu SQL Server
W systemach starszych niż Windows Server 2016 zawsze włączone grupy dostępności programu SQL Server wymagają kontrolera domeny, a wszystkie węzły w grupie dostępności muszą znajdować się w tej samej domenie usługi Active Directory (AD).
Aby skonfigurować grupę dostępności:
Umieść co najmniej dwa kontrolery domeny w każdym regionie.
Do każdego kontrolera domeny przypisz statyczny adres IP.
Komunikacja równorzędna między dwiema sieciami wirtualnymi umożliwia komunikację między nimi.
Dla każdej sieci wirtualnej dodaj adresy IP kontrolerów domeny (z obu regionów) do listy serwerów DNS. Możesz użyć poniższego polecenia interfejsu wiersza polecenia. Aby uzyskać więcej informacji, zobacz Zmienianie serwerów DNS.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Utwórz klaster usługi Windows Server Failover Clustering (WSFC) zawierający wystąpienia programu SQL Server w obu regionach.
Utwórz zawsze włączoną grupę dostępności programu SQL Server zawierającą wystąpienia programu SQL Server zarówno w regionie podstawowym, jak i pomocniczym. Aby uzyskać instrukcje, zobacz Extending Always On Availability Group to Remote Azure Datacenter (PowerShell) (Rozszerzanie zawsze włączonej grupy dostępności na zdalne centrum danych platformy Azure (PowerShell)).
Umieść replikę podstawową w regionie podstawowym.
Umieść co najmniej jedną replikę pomocniczą w regionie podstawowym. Skonfiguruj te repliki do używania zatwierdzania synchronicznego z automatycznym trybem failover.
Umieść co najmniej jedną replikę pomocniczą w regionie pomocniczym. Skonfiguruj te repliki do używania zatwierdzenia asynchronicznego ze względów wydajności. (W przeciwnym razie wszystkie transakcje T-SQL będą musiały czekać na komunikację dwustronną z regionem pomocniczym za pośrednictwem sieci).
Uwaga
Repliki zatwierdzeń asynchronicznych nie obsługują automatycznego trybu failover.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Dostępność
W przypadku złożonej aplikacji n-warstwowej replikacja całej aplikacji w regionie pomocniczym może nie być potrzebna. Zamiast tego możesz replikować tylko krytyczny podsystem, który jest potrzebny do obsługi ciągłości prowadzenia działalności biznesowej.
Usługa Traffic Manager jest punktem systemu, w którym mogą występować awarie. Jeśli usługa Traffic Manager zakończy się niepowodzeniem, klienci nie będą mogli uzyskać dostępu do aplikacji podczas przestoju. Zapoznaj się z dokumentem Traffic Manager — umowa SLA i ustal, czy korzystanie z samej usługi Traffic Manager spełnia Twoje wymagania biznesowe w zakresie wysokiej dostępności. Jeśli nie, rozważ dodanie kolejnego rozwiązania do zarządzania ruchem w ramach powrotu po awarii. W przypadku awarii usługi Azure Traffic Manager zmień rekordy CNAME w systemie DNS, aby wskazać inną usługę zarządzania ruchem. (Ten krok musisz wykonać ręcznie, a aplikacja będzie niedostępna do czasu rozpropagowania zmian systemu DNS).
W przypadku klastra SQL Server trzeba rozważyć dwa scenariusze trybu failover:
Wszystkie repliki bazy danych programu SQL Server w regionie podstawowym nie działają. Na przykład ten błąd może wystąpić podczas awarii regionalnej. W takim przypadku musisz ręcznie przełączyć grupę dostępności w tryb failover, mimo że usługa Traffic Manager automatycznie przechodzi w ten tryb na frontonie. Wykonaj kroki podane w artykule Perform a Forced Manual Failover of a SQL Server Availability Group (Wykonywanie wymuszonego, ręcznego przejścia grupy dostępności programu SQL Server w tryb failover), w którym opisano sposób wykonywania wymuszonego przejścia w tryb failover przy użyciu programu SQL Server Management Studio, Transact-SQL lub powłoki PowerShell w programie SQL Server 2016.
Ostrzeżenie
W przypadku wymuszonego przejścia w tryb failover istnieje ryzyko utraty danych. Po powrocie regionu podstawowego do trybu online wykonaj migawkę bazy danych i użyj narzędzia tablediff, aby znaleźć różnice.
Program Traffic Manager awaryjnie przechodzi w tryb awaryjny do regionu pomocniczego, ale podstawowa replika bazy danych programu SQL Server jest nadal dostępna. Na przykład warstwa frontonu może ulec awarii bez wpływu na maszyny wirtualne programu SQL Server. W takim przypadku ruch internetowy jest kierowany do regionu pomocniczego, który nadal może łączyć się z repliką podstawową. Jednak powoduje to zwiększenie opóźnienia, ponieważ program SQL Server nawiązuje połączenia między regionami. W takiej sytuacji wykonaj ręczne przejście do trybu failover w następujący sposób:
- Tymczasowo przełącz replikę bazy danych programu SQL Server w regionie pomocniczym na zatwierdzanie synchroniczne. Ten krok gwarantuje, że podczas pracy w trybie failover nie będzie utraty danych.
- Przełącz tę replikę w tryb failover.
- Gdy wrócisz po awarii do regionu podstawowego, przywróć ustawienie zatwierdzania asynchronicznego.
Możliwości zarządzania
Po zaktualizowaniu wdrożenia aktualizuj regiony pojedynczo, aby zmniejszyć możliwość wystąpienia błędu globalnego wynikającego z niepoprawnej konfiguracji lub błędu w aplikacji.
Przetestuj odporność systemu na awarie. Poniżej przedstawiono kilka typowych scenariuszy awarii do testowania:
- Wyłączenie wystąpień maszyn wirtualnych.
- Wykorzystanie zasobów, takich jak procesor CPU i pamięć.
- Odłączenie/opóźnienie sieci.
- Awarie procesów.
- Wygasłe certyfikaty.
- Symulacja awarii sprzętu.
- Wyłączenie usługi DNS na kontrolerach domeny.
Zmierz czasy odzyskiwania i sprawdź, czy spełniają wymagania biznesowe. Przetestuj również kombinacje trybów awarii.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Użyj kalkulatora cen platformy Azure, aby oszacować koszty. Oto kilka innych zagadnień.
Virtual Machine Scale Sets
Zestawy skalowania maszyn wirtualnych są dostępne we wszystkich rozmiarach maszyn wirtualnych z systemem Windows. Opłaty są naliczane tylko za wdrożone maszyny wirtualne platformy Azure i wszelkie dodane zasoby infrastruktury, które są używane, takie jak magazyn i sieć. W usłudze Virtual Machine Scale Sets nie są naliczane opłaty przyrostowe.
Aby uzyskać informacje o opcjach cenowych pojedynczych maszyn wirtualnych, zobacz Cennik maszyn wirtualnych z systemem Windows.
SQL Server
Jeśli wybierzesz usługę Azure SQL DBaas, możesz zaoszczędzić na kosztach, ponieważ nie trzeba konfigurować zawsze włączonej grupy dostępności i maszyn kontrolera domeny. Istnieje kilka opcji wdrażania, począwszy od pojedynczej bazy danych do wystąpienia zarządzanego lub pul elastycznych. Aby uzyskać więcej informacji, zobacz Cennik usługi Azure SQL.
Aby uzyskać informacje o opcjach cen maszyn wirtualnych programu SQL Server, zobacz Cennik maszyn wirtualnych SQL.
Moduły równoważenia obciążenia
Opłaty są naliczane tylko za liczbę skonfigurowanych reguł równoważenia obciążenia i ruchu wychodzącego. Reguły NAT dla ruchu przychodzącego są bezpłatne. Nie są naliczane opłaty godzinowe za usługa Load Balancer w warstwie Standardowa, gdy nie skonfigurowano żadnych reguł.
Cennik usługi Traffic Manager
Opłaty za usługę Traffic Manager są naliczane na podstawie liczby odebranych zapytań DNS, przy czym dla usług odbierających ponad miliard zapytań miesięcznie przewidziany jest rabat. Opłaty są również naliczane za każdy monitorowany punkt końcowy.
Aby uzyskać więcej informacji, zapoznaj się z sekcją kosztów w temacie Dobrze zaprojektowana struktura platformy Microsoft Azure.
Cennik komunikacji równorzędnej sieci wirtualnych
Wdrożenie o wysokiej dostępności korzystające z wielu regionów platformy Azure będzie korzystać z komunikacji równorzędnej sieci wirtualnych. Istnieją różne opłaty za komunikację równorzędną sieci wirtualnych w tym samym regionie i globalną komunikację równorzędną sieci wirtualnych.
Aby uzyskać więcej informacji, zobacz Cennik sieci wirtualnej.
DevOps
Użyj jednego szablonu usługi Azure Resource Manager do aprowizowania zasobów platformy Azure i jej zależności. Użyj tego samego szablonu, aby wdrożyć zasoby w regionach podstawowych i pomocniczych. Uwzględnij wszystkie zasoby w tej samej sieci wirtualnej, aby były odizolowane w tym samym obciążeniu podstawowym. Dzięki włączeniu wszystkich zasobów łatwiej jest skojarzyć określone zasoby obciążenia z zespołem DevOps, dzięki czemu zespół może niezależnie zarządzać wszystkimi aspektami tych zasobów. Ta izolacja umożliwia zespołom i usługom DevOps wykonywanie ciągłej integracji i ciągłego dostarczania (CI/CD).
Ponadto możesz użyć różnych szablonów usługi Azure Resource Manager i zintegrować je z usługą Azure DevOps Services , aby aprowizować różne środowiska w ciągu kilku minut, na przykład w celu replikowania środowisk produkcyjnych, takich jak scenariusze lub środowiska testowania obciążenia tylko wtedy, gdy jest to konieczne, oszczędzając koszty.
Rozważ użycie usługi Azure Monitor w celu analizowania i optymalizowania wydajności infrastruktury oraz monitorowania i diagnozowania problemów z siecią bez konieczności logowania się do maszyn wirtualnych. Usługa Application Insights jest faktycznie jednym ze składników usługi Azure Monitor, który zapewnia zaawansowane metryki i dzienniki w celu zweryfikowania stanu kompletnego krajobrazu platformy Azure. Usługa Azure Monitor pomoże Ci śledzić stan infrastruktury.
Pamiętaj, aby nie tylko monitorować elementy obliczeniowe obsługujące kod aplikacji, ale także platformę danych, w szczególności bazy danych, ponieważ niska wydajność warstwy danych aplikacji może mieć poważne konsekwencje.
Aby przetestować środowisko platformy Azure, w którym są uruchomione aplikacje, powinno być kontrolowane wersją i wdrażane za pomocą tych samych mechanizmów co kod aplikacji, można je również przetestować i zweryfikować przy użyciu paradygmatów testowania DevOps.
Aby uzyskać więcej informacji, zobacz sekcję Doskonałość operacyjną w witrynie Microsoft Azure Well-Architected Framework.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Donnie Trumpower | Starszy architekt rozwiązań w chmurze
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
Powiązane zasoby
Poniższa architektura korzysta z niektórych tych samych technologii: