Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure Cosmos DB
Azure Event Hubs
Azure Monitor
Azure Stream Analytics
Ta architektura referencyjna przedstawia pełny potok przetwarzania strumienia. Potok przetwarza dane z dwóch źródeł, koreluje rekordy w dwóch strumieniach i oblicza średnią ruchomą dla przedziału czasowego. Wyniki są przechowywane do dalszej analizy.
Architektura

Pobierz plik programu Visio z tą architekturą.
Workflow
Niniejsza architektura zawiera następujące składniki:
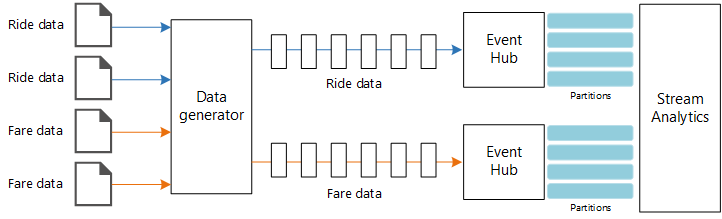
Źródła danych. W tej architekturze istnieją dwa źródła danych, które generują strumienie danych w czasie rzeczywistym. Pierwszy strumień zawiera informacje o przejazdach, a drugi zawiera informacje o taryfie. Architektura referencyjna zawiera symulowany generator danych, który odczytuje z zestawu plików statycznych i wypycha dane do usługi Event Hubs. W rzeczywistej aplikacji źródła danych będą urządzeniami zainstalowanymi w taksówkach.
Azure Event Hubs. Event Hubs to usługa przesyłania i odbierania zdarzeń. Ta architektura używa dwóch wystąpień Event Hub, po jednym dla każdego źródła danych. Każde źródło danych wysyła strumień danych do skojarzonego centrum zdarzeń.
Azure Stream Analytics. Stream Analytics to aparat przetwarzania zdarzeń. Zadanie usługi Stream Analytics odczytuje strumienie danych z dwóch centrów zdarzeń i wykonuje przetwarzanie danych strumieniowych.
Azure Cosmos DB. Dane wyjściowe zadania usługi Stream Analytics to seria rekordów, które są zapisywane jako dokumenty JSON w bazie danych dokumentów usługi Azure Cosmos DB.
Usługa Microsoft Power BI. Usługa Power BI to zestaw narzędzi do analizy biznesowej do analizowania danych pod kątem analiz biznesowych. W tej architekturze ładuje dane z usługi Azure Cosmos DB. Dzięki temu użytkownicy mogą analizować kompletny zestaw zebranych danych historycznych. Możesz również przesyłać strumieniowo wyniki bezpośrednio z usługi Stream Analytics do usługi Power BI w celu uzyskania widoku danych w czasie rzeczywistym. Aby uzyskać więcej informacji, zobacz Przesyłanie strumieniowe w czasie rzeczywistym w usłudze Power BI.
Azure Monitor. Usługa Azure Monitor zbiera metryki wydajności dotyczące usług platformy Azure wdrożonych w rozwiązaniu. Wizualizując je na pulpicie nawigacyjnym, możesz uzyskać wgląd w kondycję rozwiązania.
Szczegóły scenariusza
Scenariusz: Firma taksówkarska zbiera dane dotyczące każdej podróży taksówką. W tym scenariuszu przyjęto założenie, że istnieją dwa oddzielne urządzenia wysyłające dane. Taksówka ma miernik, który wysyła informacje o poszczególnych przejazdach — czas trwania, odległość oraz miejsca odbioru i upuszczania. Oddzielne urządzenie akceptuje płatności od klientów i wysyła dane dotyczące taryf. Firma taksówkarska chce obliczyć średni napiwek na milę w czasie rzeczywistym, aby wykryć trendy.
Potencjalne przypadki użycia
To rozwiązanie jest zoptymalizowane pod kątem scenariusza sprzedaży detalicznej.
Pozyskiwanie danych
Aby zasymulować źródło danych, ta architektura referencyjna korzysta z zestawu danych danych taksówek w Nowym Jorku[1]. Ten zestaw danych zawiera dane dotyczące przejazdów taksówką w Nowym Jorku w okresie czterech lat (2010–2013). Zawiera dwa typy rekordów: dane przejazdu i dane taryfy. Dane przejazdu obejmują czas trwania przejazdu, odległość przejazdu oraz lokalizację odbioru i wysiadania. Dane taryfy obejmują opłaty, podatki i kwoty napiwków. Typowe pola w obu typach rekordów obejmują numer medalionu, licencję hack i identyfikator dostawcy. Razem te trzy pola jednoznacznie identyfikują taksówkę i kierowcę. Dane są przechowywane w formacie CSV.
[1] Donovan, Brian; Work, Dan (2016): New York City Taxi Trip Data (2010-2013). Uniwersytet Illinois w Urbana-Champaign. https://doi.org/10.13012/J8PN93H8
Generator danych to aplikacja .NET, która odczytuje rekordy i wysyła je do Azure Event Hubs. Generator wysyła dane przejazdu w formacie JSON i taryfy w formacie CSV.
Usługa Event Hubs używa partycji do segmentowania danych. Partycje umożliwiają użytkownikowi równoległe odczytywanie każdej partycji. Podczas wysyłania danych do usługi Event Hubs można jawnie określić klucz partycji. W przeciwnym razie rekordy są przypisywane do partycji w sposób okrężny.
W tym konkretnym scenariuszu dane dotyczące przejazdów i taryf powinny zawierać ten sam identyfikator partycji dla danej taksówki. Dzięki temu usługa Stream Analytics może zastosować stopień równoległości, gdy skoreluje te dwa strumienie. Rekord w partycji n danych przejazdu będzie pasował do rekordu w partycji n danych taryfy.
W generatorze danych wspólny model danych dla obu typów rekordów ma PartitionKey właściwość, która jest łączeniem Medallion, HackLicensei VendorId.
public abstract class TaxiData
{
public TaxiData()
{
}
[JsonProperty]
public long Medallion { get; set; }
[JsonProperty]
public long HackLicense { get; set; }
[JsonProperty]
public string VendorId { get; set; }
[JsonProperty]
public DateTimeOffset PickupTime { get; set; }
[JsonIgnore]
public string PartitionKey
{
get => $"{Medallion}_{HackLicense}_{VendorId}";
}
Ta właściwość służy do udostępniania jawnego klucza partycji podczas wysyłania do usługi Event Hubs:
using (var client = pool.GetObject())
{
return client.Value.SendAsync(new EventData(Encoding.UTF8.GetBytes(
t.GetData(dataFormat))), t.PartitionKey);
}
Przetwarzanie strumieniowe
Zadanie przetwarzania strumienia jest definiowane przy użyciu zapytania SQL z kilkoma odrębnymi krokami. Pierwsze dwa kroki wybierają rekordy z dwóch strumieni wejściowych.
WITH
Step1 AS (
SELECT PartitionId,
TRY_CAST(Medallion AS nvarchar(max)) AS Medallion,
TRY_CAST(HackLicense AS nvarchar(max)) AS HackLicense,
VendorId,
TRY_CAST(PickupTime AS datetime) AS PickupTime,
TripDistanceInMiles
FROM [TaxiRide] PARTITION BY PartitionId
),
Step2 AS (
SELECT PartitionId,
medallion AS Medallion,
hack_license AS HackLicense,
vendor_id AS VendorId,
TRY_CAST(pickup_datetime AS datetime) AS PickupTime,
tip_amount AS TipAmount
FROM [TaxiFare] PARTITION BY PartitionId
),
Następny krok łączy dwa strumienie wejściowe, aby wybrać pasujące rekordy z każdego strumienia.
Step3 AS (
SELECT tr.TripDistanceInMiles,
tf.TipAmount
FROM [Step1] tr
PARTITION BY PartitionId
JOIN [Step2] tf PARTITION BY PartitionId
ON tr.PartitionId = tf.PartitionId
AND tr.PickupTime = tf.PickupTime
AND DATEDIFF(minute, tr, tf) BETWEEN 0 AND 15
)
To zapytanie łączy rekordy w zestawie pól, które jednoznacznie identyfikują pasujące rekordy (PartitionId i PickupTime).
Uwaga
Chcemy, aby strumienie TaxiRide i TaxiFare zostały połączone unikatową kombinacją Medallion, HackLicense, VendorId i PickupTime. W tym przypadku PartitionId obejmuje pola Medallion, HackLicense i VendorId, ale nie należy tego traktować jako ogólną zasadę.
W usłudze Stream Analytics sprzężenia są czasowe, co oznacza, że rekordy są łączone w określonym przedziale czasu. W przeciwnym razie zadanie może wymagać oczekiwania na dopasowanie na czas nieokreślony. Funkcja DATEDIFF określa, jak daleko w czasie można oddzielić dwa dopasowane rekordy.
Ostatni krok w zadaniu oblicza średnią wskazówkę na milę, pogrupowaną według przedziału pięciu minut.
SELECT System.Timestamp AS WindowTime,
SUM(tr.TipAmount) / SUM(tr.TripDistanceInMiles) AS AverageTipPerMile
INTO [TaxiDrain]
FROM [Step3] tr
GROUP BY HoppingWindow(Duration(minute, 5), Hop(minute, 1))
Usługa Stream Analytics udostępnia kilka funkcji okienkowych. W tym przypadku jednominutowe okno przeskoku przesuwa się do przodu w czasie przez określony okres. Wynikiem jest obliczenie średniej ruchomej w ciągu ostatnich pięciu minut.
W przedstawionej tutaj architekturze tylko wyniki zadania usługi Stream Analytics są zapisywane w usłudze Azure Cosmos DB. W przypadku scenariusza danych big data rozważ również użycie Event Hubs Capture w celu zapisania nieprzetworzonych danych zdarzeń w usłudze Azure Blob Storage. Przechowywanie danych pierwotnych umożliwi uruchamianie zapytań wsadowych na danych historycznych w późniejszym czasie w celu uzyskania nowych szczegółowych informacji na podstawie danych.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Lista kontrolna przeglądu projektu dlaoptymalizacji kosztów.
Koszty możesz szacować za pomocą kalkulatora cen platformy Azure. Poniżej przedstawiono niektóre zagadnienia dotyczące usług używanych w tej architekturze referencyjnej.
Azure Stream Analytics
Usługa Azure Stream Analytics jest wyceniana według liczby jednostek przesyłania strumieniowego (0,11 USD/godzinę) wymaganych do przetwarzania danych w usłudze.
Usługa Stream Analytics może być kosztowna, jeśli nie przetwarzasz danych w czasie rzeczywistym ani w małych ilościach danych. W tych przypadkach użycia rozważ użycie usługi Azure Functions lub Logic Apps w celu przeniesienia danych z usługi Azure Event Hubs do magazynu danych.
Azure Event Hubs i Azure Cosmos DB
Aby zapoznać się z zagadnieniami dotyczącymi kosztów usług Azure Event Hubs i Azure Cosmos DB, zobacz architekturę referencyjną przetwarzania strumieniowego za pomocą usługi Azure Databricks .
Doskonałość operacyjna
Doskonałość operacyjna obejmuje procesy operacyjne, które wdrażają aplikację i utrzymują jej działanie w środowisku produkcyjnym. Aby uzyskać więcej informacji, zobacz Lista kontrolna przeglądu projektu dotycząca doskonałości operacyjnej.
Monitorowanie
W przypadku dowolnego rozwiązania do przetwarzania strumieniowego ważne jest monitorowanie wydajności i kondycji systemu. Usługa Azure Monitor zbiera metryki i dzienniki diagnostyczne dla usług platformy Azure używanych w architekturze. Usługa Azure Monitor jest wbudowana w platformę Azure i nie wymaga żadnego dodatkowego kodu w aplikacji.
Każdy z następujących sygnałów ostrzegawczych wskazuje, że należy skalować odpowiedni zasób platformy Azure w poziomie:
- Usługa Event Hubs ogranicza żądania lub zbliża się do dziennego limitu komunikatów.
- Zadanie usługi Stream Analytics stale używa ponad 80% przydzielonych jednostek przesyłania strumieniowego (SU).
- Usługa Azure Cosmos DB zaczyna ograniczać żądania.
Architektura referencyjna zawiera niestandardowy pulpit nawigacyjny, który jest wdrażany w witrynie Azure Portal. Po wdrożeniu architektury możesz wyświetlić pulpit nawigacyjny, otwierając witrynę Azure Portal i wybierając TaxiRidesDashboard z listy pulpitów nawigacyjnych. Aby uzyskać więcej informacji na temat tworzenia i wdrażania niestandardowych pulpitów nawigacyjnych w witrynie Azure Portal, zobacz Programowe tworzenie pulpitów nawigacyjnych platformy Azure.
Na poniższym obrazku przedstawiono panel sterowania po uruchomieniu zadania Stream Analytics, które trwało około godzinę.
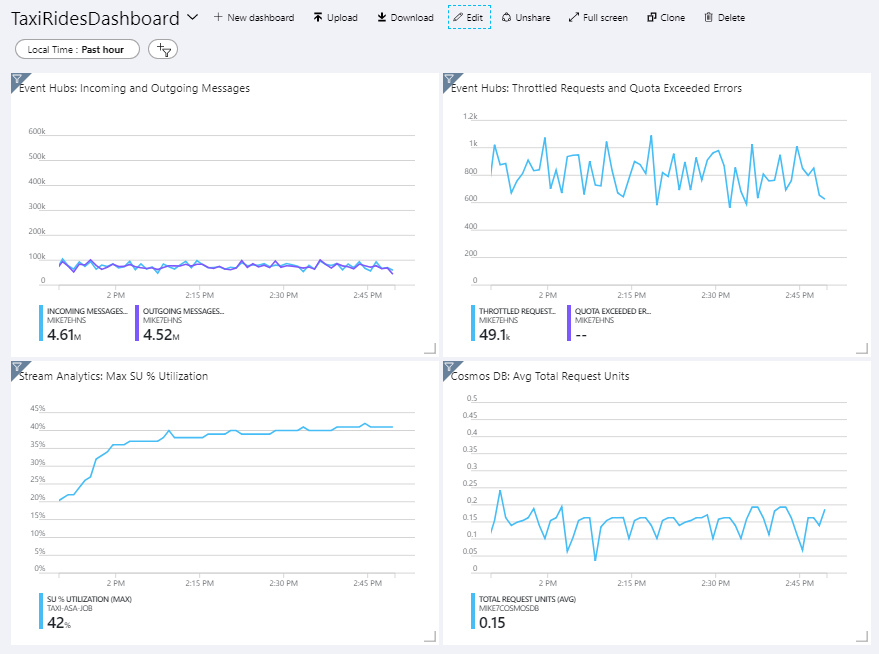
Panel w lewym dolnym rogu pokazuje, że zużycie jednostek strumieniowych (SU) dla zadania Stream Analytics wzrasta w ciągu pierwszych 15 minut, a następnie się stabilizuje. Jest to typowy wzorzec, ponieważ zadanie osiąga stały stan.
Zwróć uwagę, że usługa Event Hubs ogranicza żądania wyświetlane w prawym górnym panelu. Sporadyczne żądanie ograniczone przez przepustowość nie jest problemem, ponieważ SDK klienta Event Hubs automatycznie ponawia próbę, gdy otrzyma błąd ograniczenia. Jeśli jednak wystąpią spójne błędy ograniczania przepustowości, oznacza to, że centrum zdarzeń wymaga większej liczby jednostek przepływności. Poniższy wykres przedstawia przebieg testu przy użyciu funkcji automatycznego rozszerzania usługi Event Hubs, która automatycznie skaluje jednostki przepływności zgodnie z potrzebami.
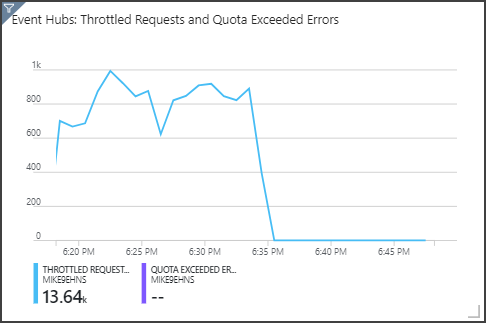
Automatyczne rozszerzanie zostało włączone około punktu 06:35. Możesz zobaczyć spadek wartości p w ograniczonych żądaniach, ponieważ usługa Event Hubs automatycznie skalowała się do 3 jednostek przepustowości.
Co ciekawe, miało to wpływ uboczny na zwiększenie wykorzystania jednostek obliczeniowych SU w zadaniu Stream Analytics. Poprzez ograniczanie usługa Event Hubs sztucznie zmniejszała szybkość przesyłania zadania Stream Analytics. Często zdarza się, że rozwiązanie jednego wąskiego gardła wydajności odsłania inne. W tym przypadku przydzielanie dodatkowej jednostki organizacyjnej dla zadania usługi Stream Analytics rozwiązało problem.
DevOps
Utwórz oddzielne grupy zasobów dla środowisk produkcyjnych, programistycznych i testowych. Oddzielne grupy zasobów ułatwiają zarządzanie wdrożeniami, usuwanie wdrożeń testowych i przypisywanie praw dostępu.
Użyj szablonu usługi Azure Resource Manager, aby wdrożyć zasoby platformy Azure zgodnie z procesem infrastruktury jako kodu (IaC). Dzięki szablonom automatyzacja wdrożeń przy użyciu usług Azure DevOps Services lub innych rozwiązań CI/CD staje się prostsza.
Umieść każde obciążenie w osobnym szablonie wdrożenia i zapisz zasoby w systemach kontroli źródła. Szablony można wdrażać razem lub indywidualnie w ramach procesu ciągłej integracji i wdrażania, co ułatwia automatyzację.
W tej architekturze usługi Azure Event Hubs, Log Analytics i Azure Cosmos DB są identyfikowane jako pojedyncze obciążenie. Te zasoby są uwzględniane w pojedynczym szablonie ARM.
Rozważ etapowanie obciążeń. Wdrażaj na różnych etapach i uruchamiaj testy weryfikacyjne na każdym z nich przed przejściem do kolejnego. Dzięki temu można wypychać aktualizacje do środowisk produkcyjnych w sposób wysoce kontrolowany i zminimalizować nieprzewidziane problemy z wdrażaniem.
Rozważ użycie usługi Azure Monitor w celu analizy wydajności potoku przetwarzania strumienia.
Aby uzyskać więcej informacji, zobacz filar doskonałości operacyjnej w Microsoft Azure Well-Architected Framework.
Wydajność
Wydajność to możliwość skalowania obciążenia w celu spełnienia wymagań, które są na nim nakładane przez użytkowników w wydajny sposób. Aby uzyskać więcej informacji, zobacz Lista kontrolna przeglądu projektu pod kątem wydajności.
Centra zdarzeń
Pojemność przepływności usługi Event Hubs jest mierzona w jednostkach przepływności. Możesz automatycznie skalować centrum zdarzeń, włączając automatyczne rozszerzanie, które automatycznie skaluje jednostki przepływności na podstawie ruchu, do skonfigurowanej maksymalnej wartości.
analiza strumienia
W przypadku usługi Stream Analytics zasoby obliczeniowe przydzielone do zadania są mierzone w jednostkach przesyłania strumieniowego. Zadania usługi Stream Analytics najlepiej się skalują, jeśli można je zrównoleglać. Dzięki temu usługa Stream Analytics może dystrybuować zadanie między wiele węzłów obliczeniowych.
W przypadku danych wejściowych usługi Event Hubs użyj słowa kluczowego PARTITION BY do partycjonowania zadania usługi Stream Analytics. Dane zostaną podzielone na podzestawy na podstawie partycji usługi Event Hubs.
Funkcje okna i sprzężenia czasowe wymagają dodatkowej jednostki SU. Jeśli to możliwe, użyj polecenia PARTITION BY , aby każda partycja jest przetwarzana oddzielnie. Aby uzyskać więcej informacji, zobacz Omówienie i dostosowywanie jednostek przesyłania strumieniowego.
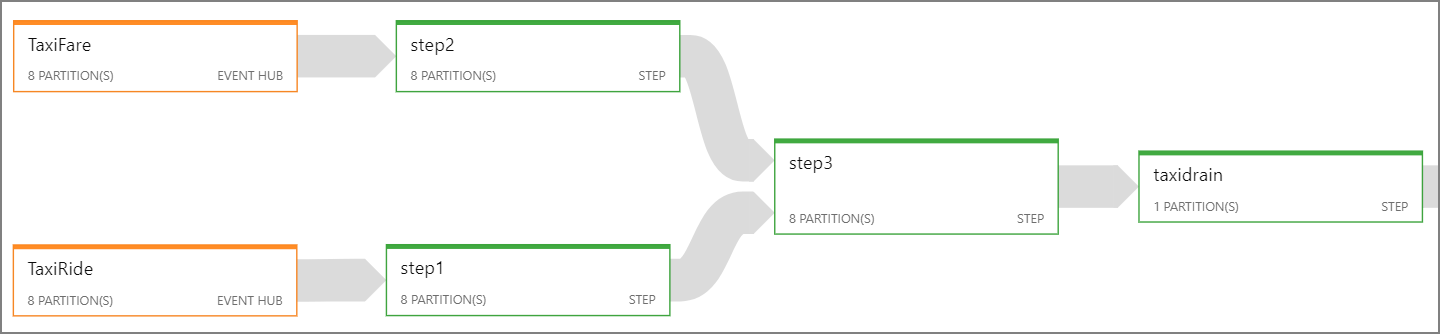
Jeśli nie można zrównoleglić całego zadania usługi Stream Analytics, spróbuj podzielić zadanie na wiele kroków, zaczynając od co najmniej jednego kroku równoległego. W ten sposób pierwsze kroki można uruchomić równolegle. Na przykład w tej architekturze referencyjnej:
- Kroki 1 i 2 to
SELECTinstrukcje, które wybierają rekordy w ramach jednej partycji. - Krok 3 wykonuje partycjonowane sprzężenia między dwoma strumieniami wejściowymi. Ten krok korzysta z faktu, że pasujące rekordy współużytkują ten sam klucz partycji, dlatego gwarantowane jest posiadanie tego samego identyfikatora partycji w każdym strumieniu wejściowym.
- Krok 4 agreguje wszystkie partycje. Nie można zrównoleglać tego kroku.
Użyj diagramu zadań usługi Stream Analytics, aby zobaczyć, ile partycji jest przypisanych do każdego kroku zadania. Na poniższym diagramie przedstawiono diagram zadań dla tej architektury referencyjnej:
Azure Cosmos DB
Pojemność przepływności dla usługi Azure Cosmos DB jest mierzona w jednostkach żądań (RU). Każdy kontener Azure Cosmos DB wymaga klucza partition a każdy dokument musi zawierać ten klucz. Pojedyncza partycja fizyczna obsługuje do 10 000 RU/s, dlatego Azure Cosmos DB dystrybuuje dane między wieloma partycjami fizycznymi na podstawie klucza partycji, aby skalować poza ten limit. Wybierz klucz partycji, który równomiernie rozkłada zarówno dane, jak i liczbę żądań, aby uniknąć nadmiernie obciążonych partycji.
W tej architekturze referencyjnej nowe dokumenty są tworzone tylko raz na minutę (interwał okna skokowego), więc wymagania dotyczące wydajności są niewielkie. Mimo to wybierz klucz partycji, który obsługuje oczekiwane wzorce zapytań i wzrost.
Powiązane zasoby
- przetwarzanie strumienia za pomocą usługi Azure Databricks