Strategie odzyskiwania po awarii dla aplikacji korzystających z elastycznych pul usługi Azure SQL Database
Dotyczy: ![]() Azure SQL Database
Azure SQL Database
Usługa Azure SQL Database oferuje kilka funkcji zapewniających ciągłość działania aplikacji w przypadku wystąpienia katastroficznych zdarzeń. Elastyczne pule i pojedyncze bazy danych obsługują takie same możliwości odzyskiwania po awarii. W tym artykule opisano kilka strategii odzyskiwania po awarii dla elastycznych pul korzystających z tych funkcji ciągłości działania usługi Azure SQL Database.
W tym artykule użyto następującego kanonicznego wzorca aplikacji niezależnego dostawcy oprogramowania SaaS:
Nowoczesna aplikacja internetowa oparta na chmurze aprowizuje jedną bazę danych dla każdego użytkownika końcowego. IsV ma wielu klientów i dlatego używa wielu baz danych, znanych jako bazy danych dzierżawy. Ponieważ bazy danych dzierżawy zwykle mają nieprzewidywalne wzorce działań, niezależnego dostawcy oprogramowania używa elastycznej puli, aby koszt bazy danych był bardzo przewidywalny w dłuższych okresach czasu. Elastyczna pula upraszcza również zarządzanie wydajnością, gdy aktywność użytkownika wzrośnie. Oprócz baz danych dzierżawy aplikacja używa również kilku baz danych do zarządzania profilami użytkowników, zabezpieczeniami, zbieraniem wzorców użycia itp. Dostępność poszczególnych dzierżaw nie ma wpływu na dostępność aplikacji jako całości. Jednak dostępność i wydajność baz danych zarządzania ma kluczowe znaczenie dla funkcji aplikacji i jeśli bazy danych zarządzania są w trybie offline, cała aplikacja jest w trybie offline.
W tym artykule omówiono strategie odzyskiwania po awarii obejmujące szereg scenariuszy, od wrażliwych na koszty aplikacji startowych do tych z rygorystycznymi wymaganiami dotyczącymi dostępności.
Uwaga
Jeśli używasz baz danych w warstwie Premium lub Krytyczne dla działania firmy i elastycznych pul, możesz uczynić je odpornymi na awarie regionalne, konwertując je na konfigurację wdrożenia strefowo nadmiarowego. Zobacz Bazy danych strefowo nadmiarowe.
Scenariusz 1. Uruchamianie wrażliwe na koszty
Jestem firmą startupową i jestem bardzo wrażliwy na koszty. Chcę uprościć wdrażanie aplikacji i zarządzanie nią, a ja mogę mieć ograniczoną umowę SLA dla poszczególnych klientów. Chcę jednak upewnić się, że aplikacja jako całość nigdy nie jest w trybie offline.
Aby spełnić wymagania dotyczące uproszczenia, należy wdrożyć wszystkie bazy danych dzierżawy w jednej elastycznej puli w wybranym regionie świadczenia usługi Azure i wdrożyć bazy danych zarządzania jako pojedyncze bazy danych replikowane geograficznie. W przypadku odzyskiwania po awarii dzierżaw należy użyć przywracania geograficznego, które nie wiąże się z dodatkowymi kosztami. Aby zapewnić dostępność baz danych zarządzania, zreplikuj je geograficznie do innego regionu przy użyciu grupy trybu failover (krok 1). Bieżący koszt konfiguracji odzyskiwania po awarii w tym scenariuszu jest równy łącznym kosztom pomocniczych baz danych. Ta konfiguracja jest pokazana na następnym diagramie.
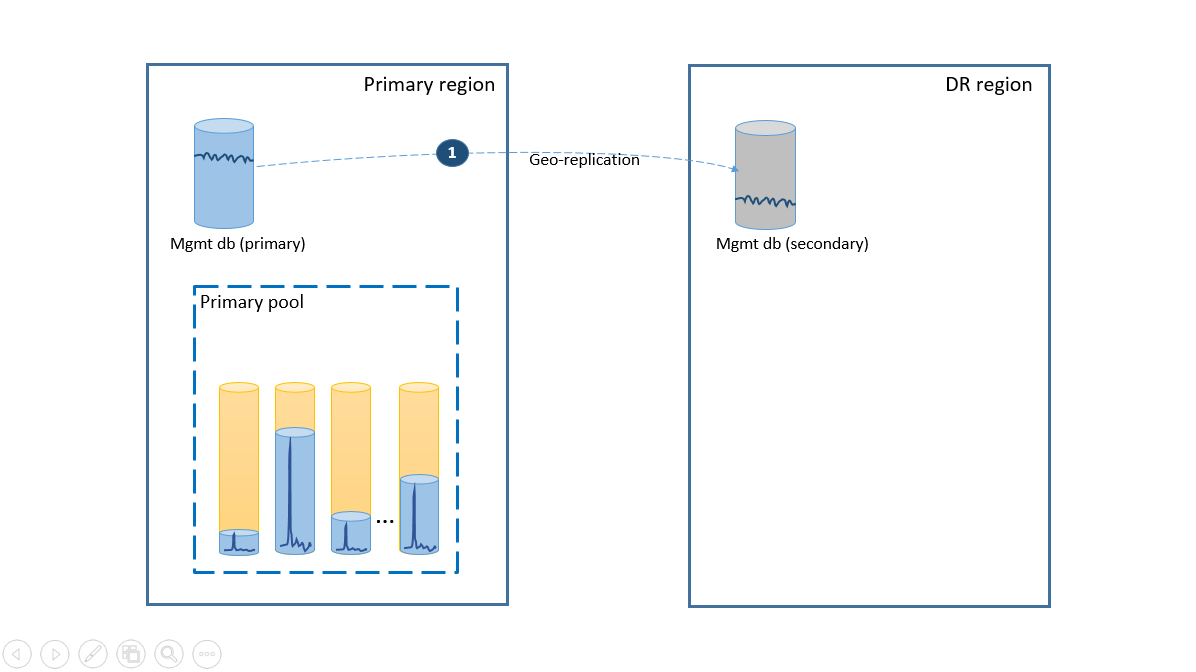
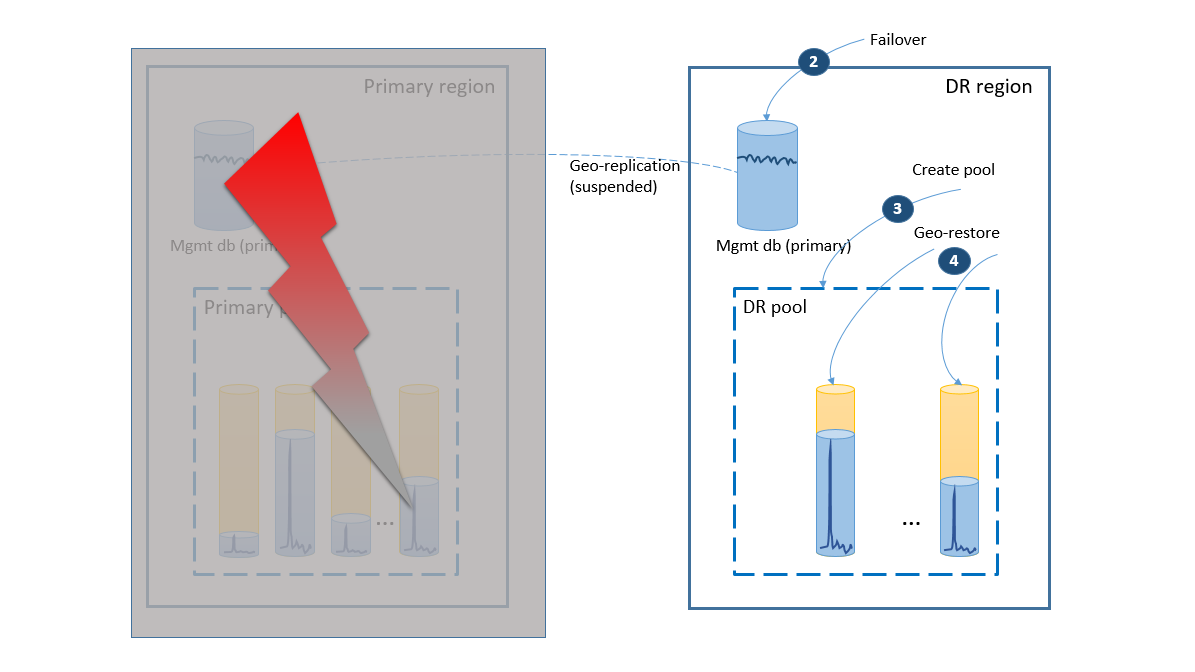
Jeśli w regionie podstawowym wystąpi awaria, kroki odzyskiwania umożliwiające przełączenie aplikacji w tryb online są zilustrowane przez następny diagram.
- Grupa trybu failover inicjuje automatyczne przejście bazy danych zarządzania w tryb failover do regionu odzyskiwania po awarii. Aplikacja jest automatycznie ponownie połączona z nowym podstawowym, a wszystkie nowe konta i bazy danych dzierżawy są tworzone w regionie odzyskiwania po awarii. Istniejący klienci widzą swoje dane tymczasowo niedostępne.
- Utwórz pulę elastyczną z taką samą konfiguracją jak oryginalna pula (2).
- Użyj przywracania geograficznego, aby utworzyć kopie baz danych dzierżawy (3). Można rozważyć wyzwolenie poszczególnych przywracania przez połączenia użytkownika końcowego lub użyć innego schematu priorytetu specyficznego dla aplikacji.
W tym momencie aplikacja wraca do trybu online w regionie odzyskiwania po awarii, ale niektórzy klienci napotykają opóźnienie podczas uzyskiwania dostępu do danych.
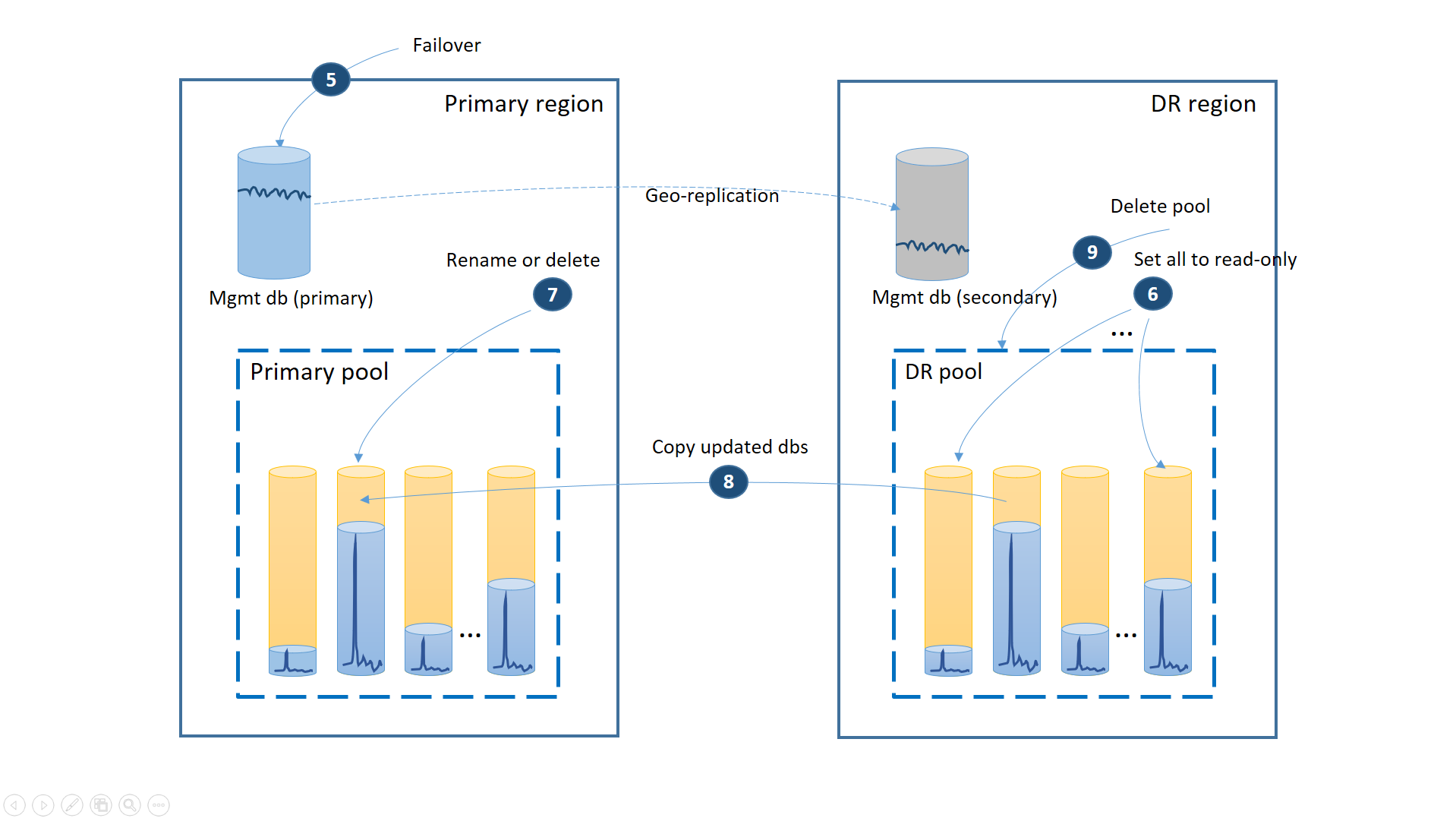
Jeśli awaria była tymczasowa, możliwe, że region podstawowy zostanie odzyskany przez platformę Azure, zanim wszystkie operacje przywracania bazy danych zostaną ukończone w regionie odzyskiwania po awarii. W takim przypadku zaaranżuj przeniesienie aplikacji z powrotem do regionu podstawowego. Proces wykonuje kroki przedstawione na następnym diagramie.
- Anuluj wszystkie zaległe żądania przywracania geograficznego.
- Przełącz bazy danych zarządzania w tryb failover do regionu podstawowego (5). Po odzyskaniu regionu stare prawybory automatycznie stają się drugimi. Teraz ponownie przełączają role.
- Zmień parametry połączenia aplikacji, aby wskazywała region podstawowy. Teraz wszystkie nowe konta i bazy danych dzierżawy są tworzone w regionie podstawowym. Niektórzy istniejący klienci widzą swoje dane tymczasowo niedostępne.
- Ustaw wszystkie bazy danych w puli odzyskiwania po awarii na tylko do odczytu, aby upewnić się, że nie można ich modyfikować w regionie odzyskiwania po awarii (6).
- Dla każdej bazy danych w puli odzyskiwania po awarii, która uległa zmianie od czasu odzyskiwania, zmień nazwę lub usuń odpowiednie bazy danych w puli podstawowej (7).
- Skopiuj zaktualizowane bazy danych z puli odzyskiwania po awarii do puli podstawowej (8).
- Usuwanie puli odzyskiwania po awarii (9)
W tym momencie aplikacja znajduje się w trybie online w regionie podstawowym ze wszystkimi bazami danych dzierżawy dostępnymi w puli podstawowej.
Korzyści
Kluczową zaletą tej strategii jest niski koszt nadmiarowości warstwy danych. Usługa Azure SQL Database automatycznie wykonuje kopie zapasowe baz danych bez ponownego zapisywania aplikacji bez dodatkowych kosztów. Koszt jest naliczany tylko po przywróceniu elastycznych baz danych.
Kompromis
Kompromis polega na tym, że całkowite odzyskiwanie wszystkich baz danych dzierżawy zajmuje dużo czasu. Czas zależy od całkowitej liczby operacji przywracania inicjowanych w regionie odzyskiwania po awarii i ogólnego rozmiaru baz danych dzierżawy. Nawet jeśli określisz priorytety przywracania niektórych dzierżaw nad innymi, konkurujesz ze wszystkimi innymi przywracaniemi zainicjowanymi w tym samym regionie co arbitry usługi i ograniczenia, aby zminimalizować ogólny wpływ na bazy danych istniejących klientów. Ponadto odzyskiwanie baz danych dzierżawy nie może rozpocząć się do momentu utworzenia nowej elastycznej puli w regionie odzyskiwania po awarii.
Scenariusz 2. Dojrzała aplikacja z usługą warstwową
Jestem dojrzałą aplikacją SaaS z ofertami usług warstwowych i różnymi umowami SLA dla klientów w wersji próbnej i płacącymi klientami. Dla klientów korzystających z wersji próbnej muszę jak najwięcej obniżyć koszty. Klienci wersji próbnej mogą przestój, ale chcę zmniejszyć prawdopodobieństwo. W przypadku płatnych klientów wszelkie przestoje są ryzykiem lotu. Chcę więc upewnić się, że płacący klienci zawsze mogą uzyskiwać dostęp do swoich danych.
Aby zapewnić obsługę tego scenariusza, należy oddzielić dzierżawy wersji próbnej od płatnych dzierżaw, umieszczając je w oddzielnych pulach elastycznych. Klienci wersji próbnej mają niższą wartość eDTU lub rdzeni wirtualnych na dzierżawę i niższą umowę SLA z dłuższym czasem odzyskiwania. Płacący klienci znajdują się w puli z wyższymi liczbami eDTU lub rdzeniami wirtualnymi na dzierżawę i wyższą umową SLA. Aby zagwarantować najniższy czas odzyskiwania, płatne bazy danych dzierżawy klientów są replikowane geograficznie. Ta konfiguracja jest pokazana na następnym diagramie.
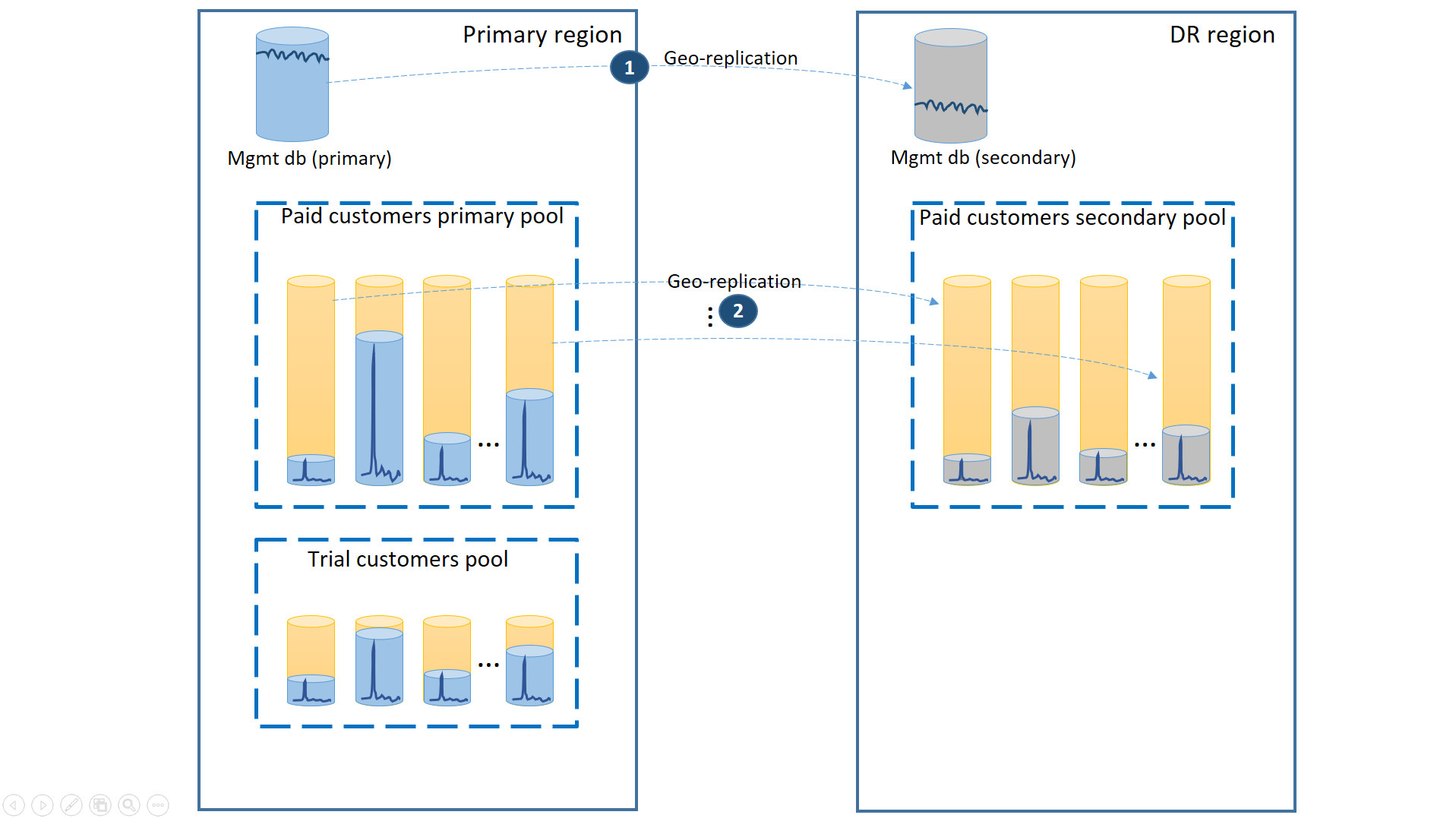
Podobnie jak w pierwszym scenariuszu bazy danych zarządzania są dość aktywne, więc używasz dla niej pojedynczej bazy danych replikowanej geograficznie (1). Zapewnia to przewidywalną wydajność nowych subskrypcji klientów, aktualizacji profilów i innych operacji zarządzania. Region, w którym znajdują się prawybory baz danych zarządzania, jest regionem podstawowym, a regionem, w którym znajdują się drugie bazy danych zarządzania, jest region odzyskiwania po awarii.
Płatne bazy danych dzierżawy mają aktywne bazy danych w płatnej puli aprowizowanej w regionie podstawowym. Aprowizuj pulę pomocniczą o tej samej nazwie w regionie odzyskiwania po awarii. Każda dzierżawa jest replikowana geograficznie do puli pomocniczej (2). Umożliwia to szybkie odzyskiwanie wszystkich baz danych dzierżaw przy użyciu trybu failover.
Jeśli w regionie podstawowym wystąpi awaria, kroki odzyskiwania umożliwiające przełączenie aplikacji w tryb online są przedstawione na następnym diagramie:
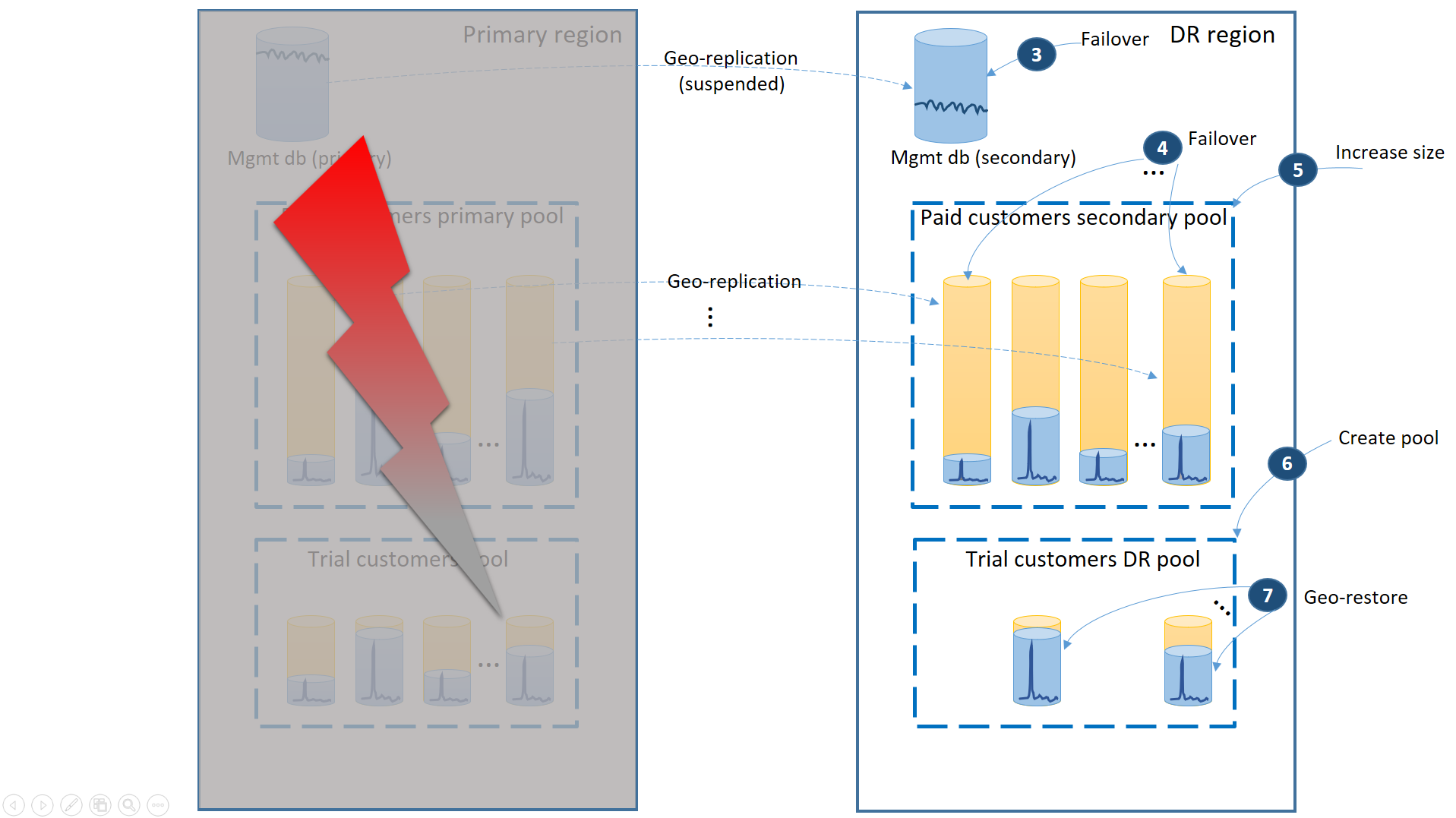
- Natychmiast przełącz bazy danych zarządzania w tryb failover do regionu odzyskiwania po awarii (3).
- Zmień parametry połączenia aplikacji, aby wskazywała region odzyskiwania po awarii. Teraz wszystkie nowe konta i bazy danych dzierżawy są tworzone w regionie odzyskiwania po awarii. Istniejący klienci wersji próbnej widzą swoje dane tymczasowo niedostępne.
- Przełącz bazy danych płatnej dzierżawy w tryb failover do puli w regionie odzyskiwania po awarii, aby natychmiast przywrócić ich dostępność (4). Ponieważ tryb failover to szybka zmiana na poziomie metadanych, rozważ optymalizację, w której poszczególne tryby failover są wyzwalane na żądanie przez połączenia użytkowników końcowych.
- Jeśli rozmiar eDTU puli pomocniczej lub wartość rdzeni wirtualnych była niższa niż podstawowa, ponieważ pomocnicze bazy danych wymagały tylko pojemności do przetwarzania dzienników zmian, podczas gdy były to pomocnicze, natychmiast zwiększ pojemność puli, aby obsłużyć pełne obciążenie wszystkich dzierżaw (5).
- Utwórz nową elastyczną pulę o takiej samej nazwie i tej samej konfiguracji w regionie odzyskiwania po awarii dla baz danych klientów wersji próbnej (6).
- Po utworzeniu puli klientów wersji próbnej użyj funkcji przywracania geograficznego, aby przywrócić pojedyncze bazy danych dzierżawy wersji próbnej do nowej puli (7). Rozważ wyzwolenie poszczególnych przywracania przez połączenia użytkownika końcowego lub użycie innego schematu priorytetu specyficznego dla aplikacji.
W tym momencie aplikacja wraca do trybu online w regionie odzyskiwania po awarii. Wszyscy płacący klienci mają dostęp do swoich danych, podczas gdy klienci wersji próbnej napotykają opóźnienie podczas uzyskiwania dostępu do danych.
Gdy region podstawowy zostanie odzyskany przez platformę Azure po przywróceniu aplikacji w regionie odzyskiwania po awarii, możesz kontynuować uruchamianie aplikacji w tym regionie lub podjąć decyzję o powrocie po awarii do regionu podstawowego. Jeśli region podstawowy zostanie odzyskany przed zakończeniem procesu trybu failover, rozważ powrót po awarii od razu. Powrót po awarii wykonuje kroki przedstawione na następnym diagramie:
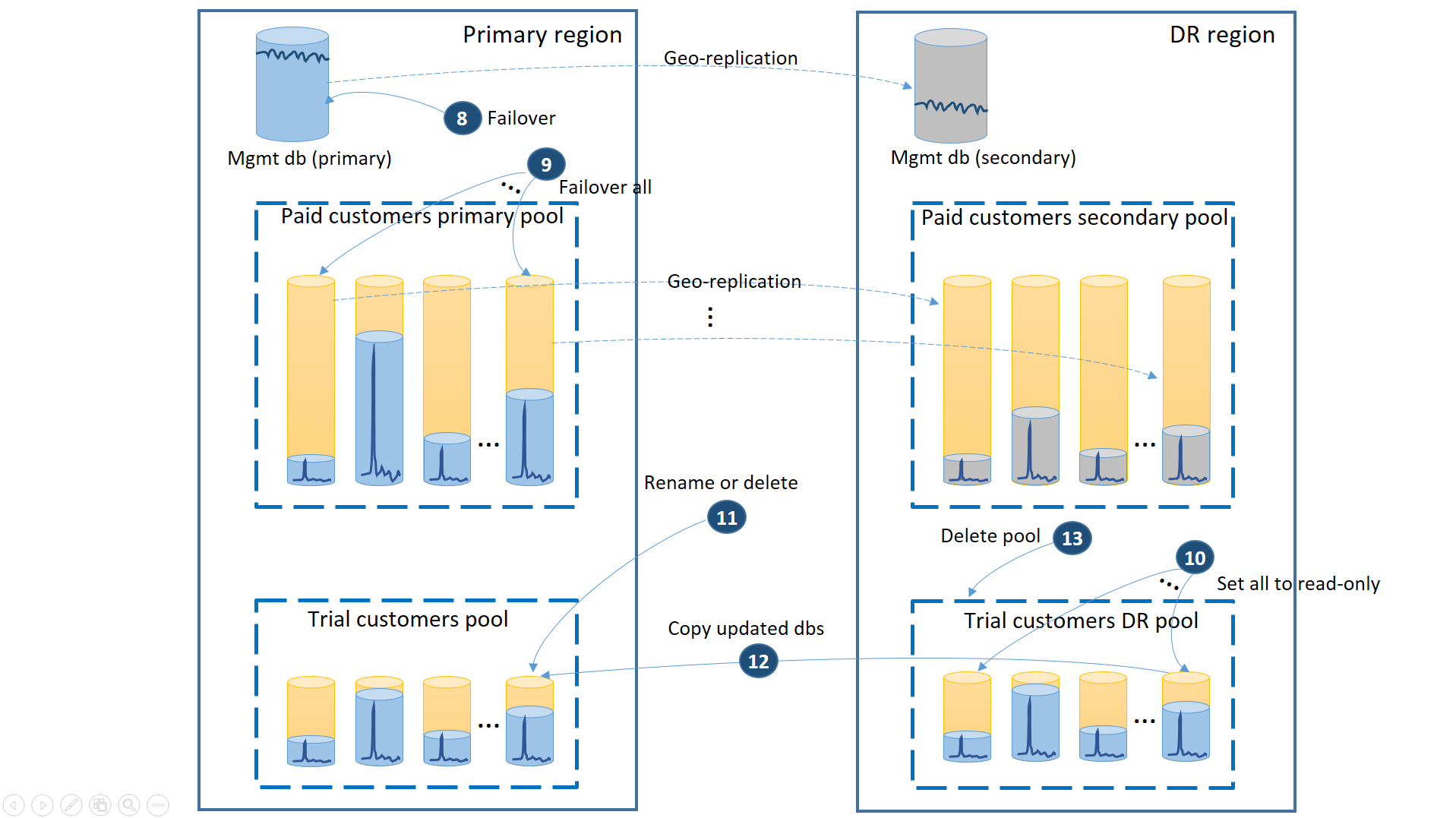
- Anuluj wszystkie zaległe żądania przywracania geograficznego.
- Przełączanie baz danych zarządzania w tryb failover (8). Po odzyskaniu regionu stary podstawowy automatycznie staje się pomocniczym. Teraz staje się ponownie podstawowym.
- Przełącz w tryb failover płatne bazy danych dzierżawy (9). Podobnie, po odzyskaniu regionu stare prawybory automatycznie stają się drugimi. Teraz znowu stają się prawyborami.
- Ustaw przywrócone bazy danych wersji próbnej, które uległy zmianie w regionie odzyskiwania po awarii, na tylko do odczytu (10).
- Dla każdej bazy danych w puli próbnej odzyskiwania po awarii, która zmieniła się od czasu odzyskiwania, zmień nazwę lub usuń odpowiednią bazę danych w puli podstawowej klientów wersji próbnej (11).
- Skopiuj zaktualizowane bazy danych z puli odzyskiwania po awarii do puli podstawowej (12).
- Usuń pulę odzyskiwania po awarii (13).
Uwaga
Operacja trybu failover jest asynchroniczna. Aby zminimalizować czas odzyskiwania, należy wykonać polecenie trybu failover baz danych dzierżawy w partiach co najmniej 20 baz danych.
Korzyści
Kluczową zaletą tej strategii jest zapewnienie najwyższej umowy SLA dla płacących klientów. Gwarantuje również, że nowe próby zostaną odblokowane natychmiast po utworzeniu puli próbnej odzyskiwania po awarii.
Kompromis
Kompromis polega na tym, że ta konfiguracja zwiększa całkowity koszt baz danych dzierżawy przez koszt pomocniczej puli odzyskiwania po awarii dla płatnych klientów. Ponadto, jeśli pula pomocnicza ma inny rozmiar, płacący klienci doświadczają niższej wydajności po przejściu w tryb failover do momentu ukończenia uaktualnienia puli w regionie odzyskiwania po awarii.
Scenariusz 3. Geograficznie rozproszona aplikacja z usługą warstwową
Mam dojrzałą aplikację SaaS z ofertami usług warstwowych. Chcę zaoferować bardzo agresywną umowę SLA dla moich płatnych klientów i zminimalizować ryzyko wystąpienia awarii, ponieważ nawet krótka przerwa może spowodować niezadowolenie klientów. Ważne jest, aby płaccy klienci zawsze mogli uzyskiwać dostęp do swoich danych. Wersje próbne są bezpłatne i umowa SLA nie jest oferowana w okresie próbnym.
Aby obsłużyć ten scenariusz, użyj trzech oddzielnych elastycznych pul. Aprowizuj dwie pule o równym rozmiarze z wysokimi jednostkami eDTU lub rdzeniami wirtualnymi na bazę danych w dwóch różnych regionach, aby zawierały płatne bazy danych dzierżawy klientów. Trzecia pula zawierająca dzierżawy wersji próbnej może mieć niższe liczby jednostek eDTU lub rdzeni wirtualnych na bazę danych i aprowizować je w jednym z dwóch regionów.
Aby zagwarantować najniższy czas odzyskiwania podczas przestojów, płacące bazy danych dzierżawy klientów są replikowane geograficznie z 50% podstawowych baz danych w każdym z dwóch regionów. Podobnie każdy region ma 50% pomocniczych baz danych. W ten sposób, jeśli region jest w trybie offline, dotyczy to tylko 50% płatnych baz danych klientów i musi przejść w tryb failover. Pozostałe bazy danych pozostają nienaruszone. Ta konfiguracja jest pokazana na poniższym diagramie:
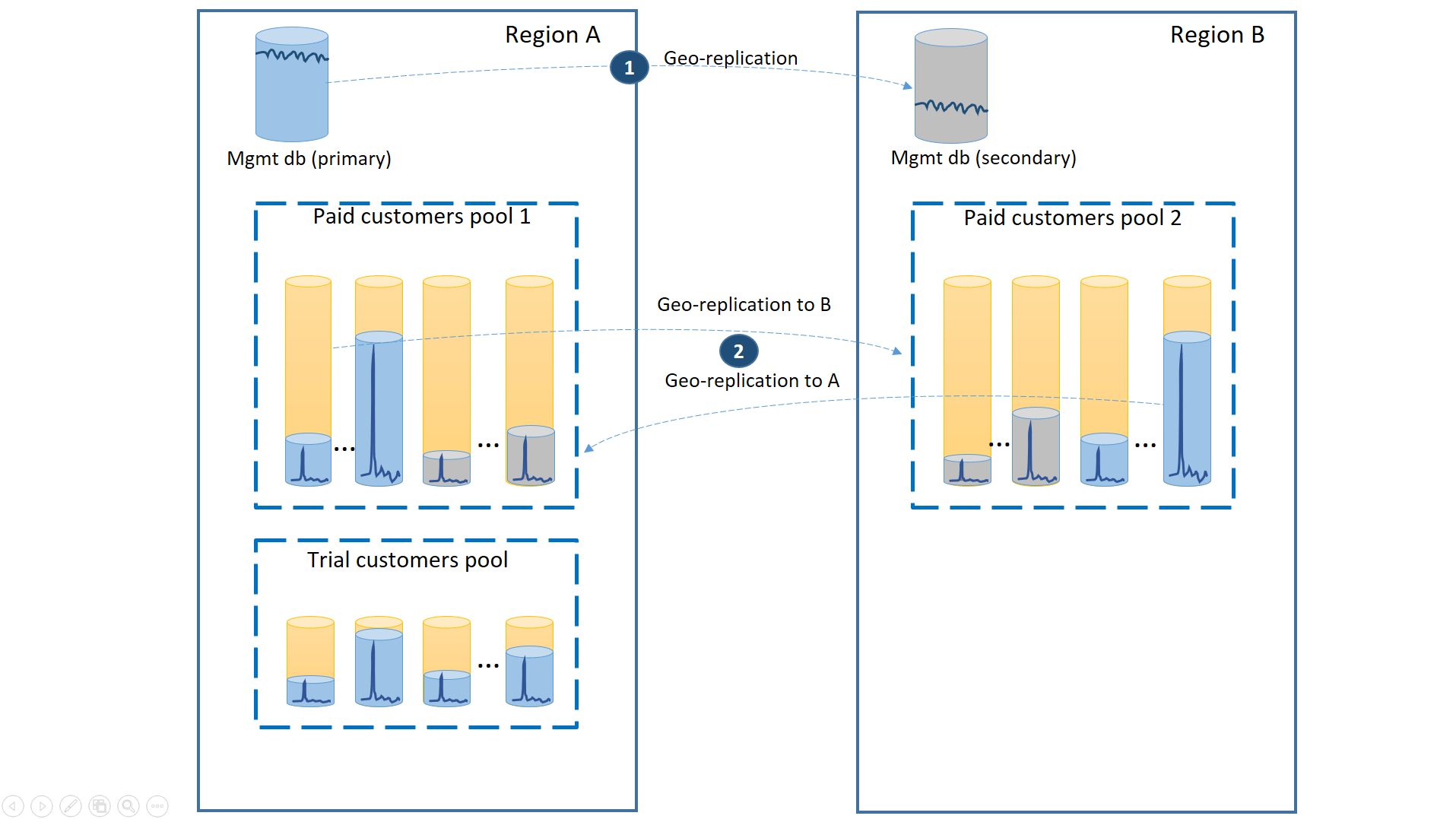
Podobnie jak w poprzednich scenariuszach bazy danych zarządzania są dość aktywne, więc skonfiguruj je jako pojedyncze bazy danych replikowane geograficznie (1). Zapewnia to przewidywalną wydajność nowych subskrypcji klientów, aktualizacji profilu i innych operacji zarządzania. Region A jest regionem podstawowym baz danych zarządzania, a region B jest używany do odzyskiwania baz danych zarządzania.
Płatne bazy danych dzierżawy klientów są również replikowane geograficznie, ale z prawyborami i sekundami podzielonymi między region A i region B (2). Dzięki temu podstawowe bazy danych dzierżawy, których dotyczy awaria, mogą przejść w tryb failover do innego regionu i stać się dostępne. Na drugą połowę baz danych dzierżawy nie ma wpływu.
Na następnym diagramie przedstawiono kroki odzyskiwania, które należy wykonać w przypadku wystąpienia awarii w regionie A.
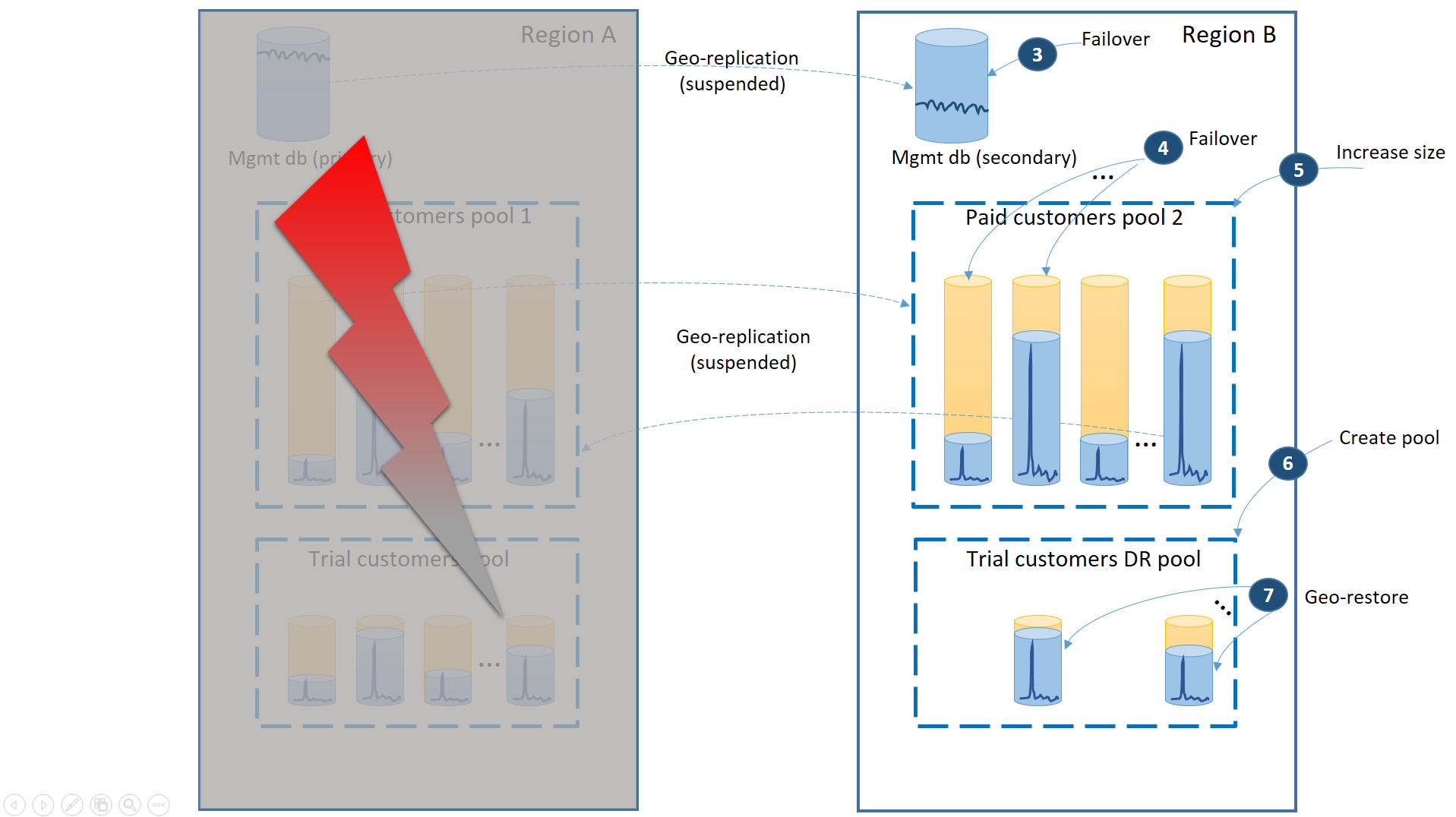
- Natychmiast przełącz bazy danych zarządzania w tryb failover do regionu B (3).
- Zmień parametry połączenia aplikacji, aby wskazywała bazy danych zarządzania w regionie B. Zmodyfikuj bazy danych zarządzania, aby upewnić się, że nowe konta i bazy danych dzierżaw zostały utworzone w regionie B, a istniejące bazy danych dzierżawy również zostały tam znalezione. Istniejący klienci wersji próbnej widzą swoje dane tymczasowo niedostępne.
- Przełącz bazy danych płatnej dzierżawy w tryb failover do puli 2 w regionie B, aby natychmiast przywrócić ich dostępność (4). Ponieważ tryb failover to szybka zmiana na poziomie metadanych, możesz rozważyć optymalizację, w której poszczególne przejścia w tryb failover są wyzwalane na żądanie przez połączenia użytkowników końcowych.
- Ponieważ obecnie pula 2 zawiera tylko podstawowe bazy danych, łączne obciążenie w puli wzrasta i może natychmiast zwiększyć rozmiar eDTU (5) lub liczbę rdzeni wirtualnych.
- Utwórz nową elastyczną pulę o tej samej nazwie i tej samej konfiguracji w regionie B dla baz danych klientów wersji próbnej (6).
- Po utworzeniu puli użyj przywracania geograficznego, aby przywrócić pojedynczą wersję próbną bazy danych dzierżawy do puli (7). Można rozważyć wyzwolenie poszczególnych przywracania przez połączenia użytkownika końcowego lub użyć innego schematu priorytetu specyficznego dla aplikacji.
Uwaga
Operacja trybu failover jest asynchroniczna. Aby zminimalizować czas odzyskiwania, ważne jest, aby wykonać polecenie trybu failover baz danych dzierżawy w partiach co najmniej 20 baz danych.
W tym momencie aplikacja wraca do trybu online w regionie B. Wszyscy płacący klienci mają dostęp do swoich danych, podczas gdy klienci wersji próbnej napotykają opóźnienie podczas uzyskiwania dostępu do danych.
Gdy region A zostanie odzyskany, musisz zdecydować, czy chcesz użyć regionu B dla klientów wersji próbnej lub powrotu po awarii do korzystania z puli klientów wersji próbnej w regionie A. Jednym z kryteriów może być procent baz danych dzierżawy wersji próbnej zmodyfikowanych od czasu odzyskiwania. Niezależnie od tej decyzji należy ponownie zrównoważyć płatne dzierżawy między dwiema pulami. Następny diagram ilustruje proces, gdy próbne bazy danych dzierżawy kończą się niepowodzeniem w regionie A.
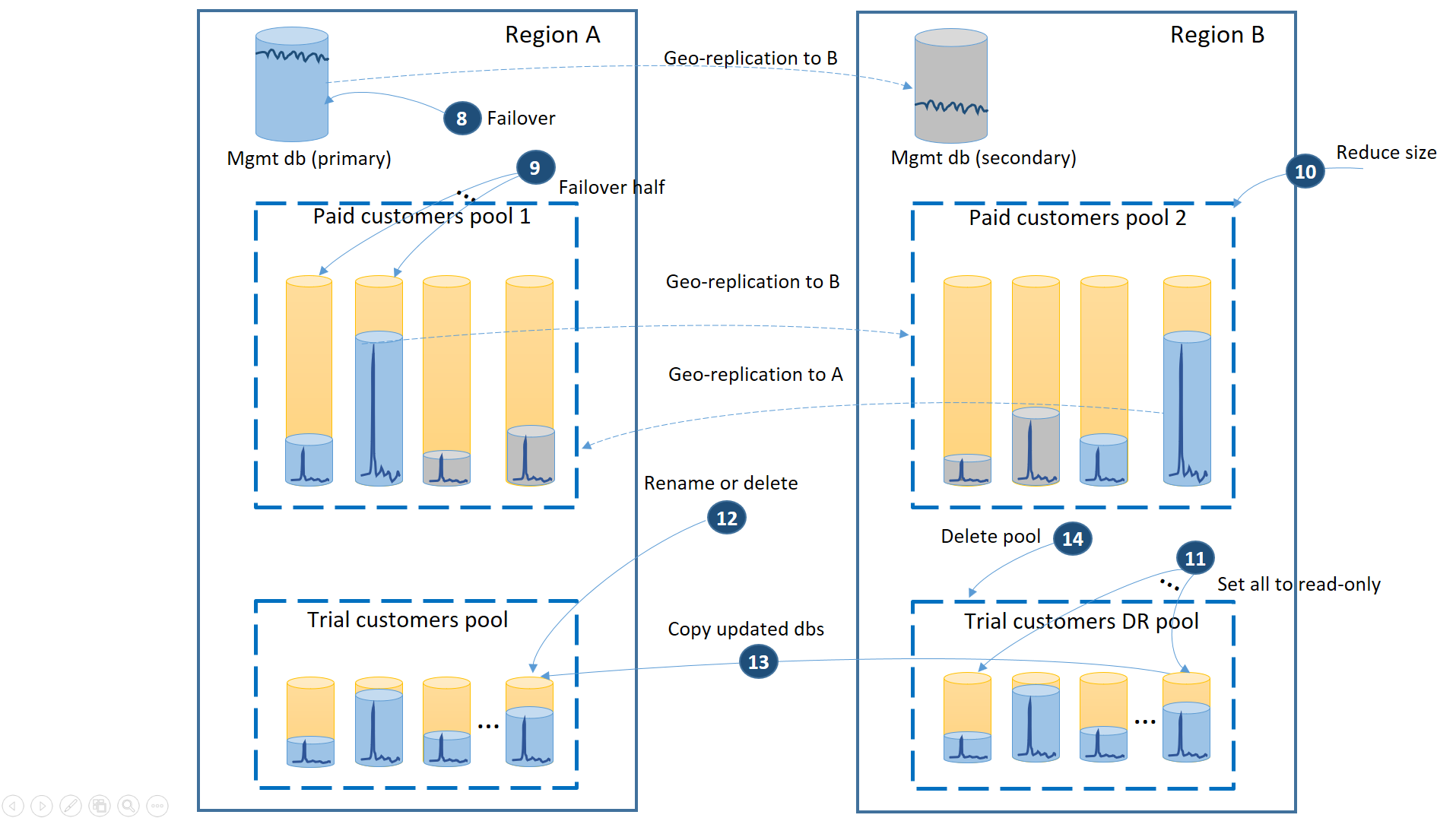
- Anuluj wszystkie zaległe żądania przywracania geograficznego do puli próbnej odzyskiwania po awarii.
- Przełącz bazę danych zarządzania w tryb failover (8). Po odzyskaniu regionu stary podstawowy automatycznie stał się pomocniczym. Teraz staje się ponownie podstawowym.
- Wybierz, które płatne bazy danych dzierżawy kończą się niepowodzeniem z powrotem do puli 1, i zainicjuj przejście w tryb failover do ich pomocniczych (9). Po odzyskaniu regionu wszystkie bazy danych w puli 1 automatycznie stały się elementami pomocniczymi. Teraz 50% z nich ponownie staje się prawyborami.
- Zmniejsz rozmiar puli 2 do oryginalnej liczby jednostek eDTU (10) lub liczby rdzeni wirtualnych.
- Ustaw wszystkie przywrócone bazy danych wersji próbnej w regionie B na tylko do odczytu (11).
- Dla każdej bazy danych w puli próbnej odzyskiwania po awarii, która uległa zmianie od czasu odzyskiwania, zmień nazwę lub usuń odpowiednią bazę danych w puli podstawowej wersji próbnej (12).
- Skopiuj zaktualizowane bazy danych z puli odzyskiwania po awarii do puli podstawowej (13).
- Usuń pulę odzyskiwania po awarii (14).
Korzyści
Najważniejsze korzyści wynikające z tej strategii to:
- Obsługuje ona najbardziej agresywną umowę SLA dla płacących klientów, ponieważ gwarantuje, że awaria nie może mieć wpływu na ponad 50% baz danych dzierżawy.
- Gwarantuje to, że nowe próby zostaną odblokowane natychmiast po utworzeniu puli odzyskiwania po awarii szlaku podczas odzyskiwania.
- Pozwala to wydajniej korzystać z pojemności puli, ponieważ 50% pomocniczych baz danych w puli 1 i pula 2 ma gwarancję, że będzie mniej aktywna niż podstawowe bazy danych.
Kompromisy
Główne kompromisy to:
- Operacje CRUD względem baz danych zarządzania mają mniejsze opóźnienie dla użytkowników końcowych połączonych z regionem A niż dla użytkowników końcowych połączonych z regionem B, ponieważ są wykonywane względem podstawowej bazy danych zarządzania.
- Wymaga bardziej złożonego projektu bazy danych zarządzania. Na przykład każdy rekord dzierżawy ma tag lokalizacji, który należy zmienić podczas pracy w trybie failover i powrotu po awarii.
- Płacący klienci mogą mieć niższą wydajność niż zwykle do momentu ukończenia uaktualnienia puli w regionie B.
Podsumowanie
Ten artykuł koncentruje się na strategiach odzyskiwania po awarii dla warstwy bazy danych używanej przez wielodostępną aplikację SaaS ISV. Wybrana strategia jest oparta na potrzebach aplikacji, takich jak model biznesowy, umowa SLA, którą chcesz zaoferować klientom, ograniczenie budżetu itp. Każda opisana strategia przedstawia korzyści i kompromis, dzięki czemu można podjąć świadomą decyzję. Ponadto konkretna aplikacja prawdopodobnie zawiera inne składniki platformy Azure. Dlatego zapoznasz się ze wskazówkami dotyczącymi ciągłości działalności biznesowej i zaaranżujesz ich odzyskiwanie warstwy bazy danych. Aby dowiedzieć się więcej na temat zarządzania odzyskiwaniem aplikacji bazy danych na platformie Azure, zobacz Projektowanie rozwiązań w chmurze na potrzeby odzyskiwania po awarii.
Następne kroki
- Aby dowiedzieć się więcej na temat automatycznych kopii zapasowych usługi Azure SQL Database, zobacz Automatyczne kopie zapasowe usługi Azure SQL Database.
- Aby zapoznać się z omówieniem i scenariuszami ciągłości działania, zobacz Omówienie ciągłości działania.
- Aby dowiedzieć się więcej na temat używania automatycznych kopii zapasowych na potrzeby odzyskiwania, zobacz przywracanie bazy danych z kopii zapasowych zainicjowanych przez usługę.
- Aby dowiedzieć się więcej o szybszych opcjach odzyskiwania, zobacz Aktywne replikacje geograficzne i grupy trybu failover.
- Aby dowiedzieć się więcej na temat używania automatycznych kopii zapasowych do archiwizowania, zobacz kopiowanie bazy danych.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla