Aktywna replikacja geograficzna
Dotyczy: ![]() Azure SQL Database
Azure SQL Database
Aktywna replikacja geograficzna to funkcja, która umożliwia contiunously replikowanie danych z podstawowej bazy danych do pomocniczej bazy danych z możliwością odczytu. Możliwa do odczytu pomocnicza baza danych może się znajdować w tym samym regionie świadczenia platformy Azure co podstawowa ale częściej jest w innym regionie. Ta pomocnicza baza danych jest również znana jako pomocnicza lub geograficzna replika geograficzna.
Aktywna replikacja geograficzna jest skonfigurowana na bazę danych i obsługuje tylko ręczne przejście w tryb failover. Aby przejąć grupę baz danych w tryb failover lub jeśli aplikacja wymaga stabilnego punktu końcowego połączenia, rozważ zamiast tego grupy trybu failover.
Możesz również użyć usługi Migrate SQL Database z aktywną replikacją geograficzną.
Omówienie
Aktywna replikacja geograficzna jest zaprojektowana jako rozwiązanie zapewniające ciągłość działania. Aktywna replikacja geograficzna umożliwia szybkie odzyskiwanie po awarii poszczególnych baz danych, jeśli wystąpi awaria regionalna lub awaria na dużą skalę. Po skonfigurowaniu replikacji geograficznej można zainicjować przejście geograficzne w tryb failover do pomocniczego obszaru geograficznego w innym regionie świadczenia usługi Azure. Tryb failover geograficznie jest inicjowany programowo przez aplikację lub ręcznie przez użytkownika.
Na poniższym diagramie przedstawiono typową konfigurację aplikacji w chmurze geograficznie nadmiarowej przy użyciu aktywnej replikacji geograficznej.
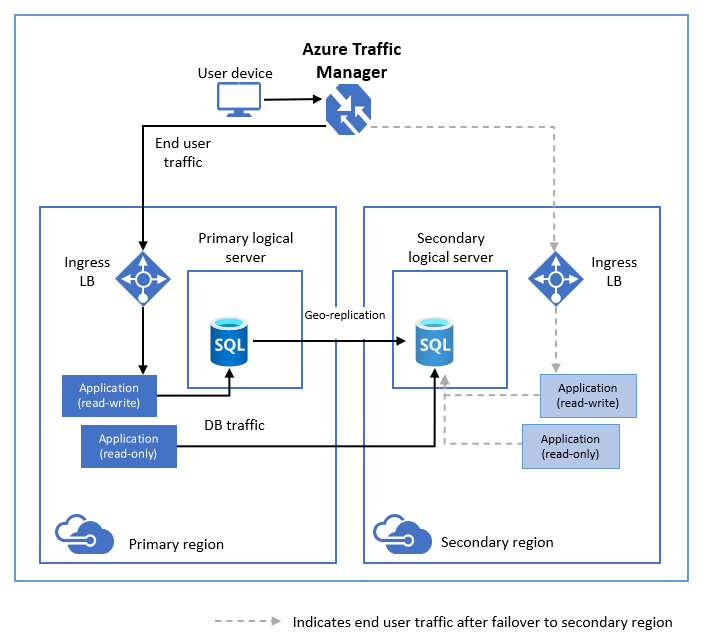
Jeśli z jakiegokolwiek powodu podstawowa baza danych ulegnie awarii, możesz zainicjować tryb failover geograficznego do dowolnej pomocniczej bazy danych. Po podwyższeniu poziomu pomocniczego do roli podstawowej wszystkie inne pomocnicze pliki pomocnicze są automatycznie połączone z nowym elementem podstawowym.
Możesz zarządzać replikacją geograficzną i inicjować tryb failover geograficznie przy użyciu dowolnej z następujących metod:
- Azure Portal
- PowerShell: pojedyncza baza danych
- PowerShell: elastyczna pula
- Transact-SQL: pojedyncza baza danych lub elastyczna pula
- Interfejs API REST: pojedyncza baza danych
Aktywna replikacja geograficzna używa technologii zawsze włączonej grupy dostępności do asynchronicznego replikowania dziennika transakcji wygenerowanego w repliki podstawowej do wszystkich replik geograficznych. I chociaż pomocnicza baza danych może być zawsze nieco w tyle za podstawową bazą danych, dane w pomocniczej bazie danych mają gwarancję spójności na poziomie transakcji. Innymi słowy, zmiany wprowadzone przez niezatwierdzone transakcje nie są widoczne.
Uwaga
Aktywna replikacja geograficzna replikuje zmiany przez przesyłanie strumieniowe dziennika transakcji bazy danych z repliki podstawowej do replik pomocniczych. Nie jest on związany z replikacją transakcyjną, która replikuje zmiany, wykonując polecenia DML (INSERT, UPDATE, DELETE) dla subskrybentów.
Replikacja geograficzna zapewnia nadmiarowość regionalną. Nadmiarowość regionalna umożliwia aplikacjom szybkie odzyskiwanie po trwałej utracie całego regionu platformy Azure lub części regionu spowodowanego klęskami żywiołowymi, katastrofalnymi błędami ludzkimi lub złośliwymi działaniami. Cel punktu odzyskiwania replikacji geograficznej można znaleźć w temacie Omówienie ciągłości działania.
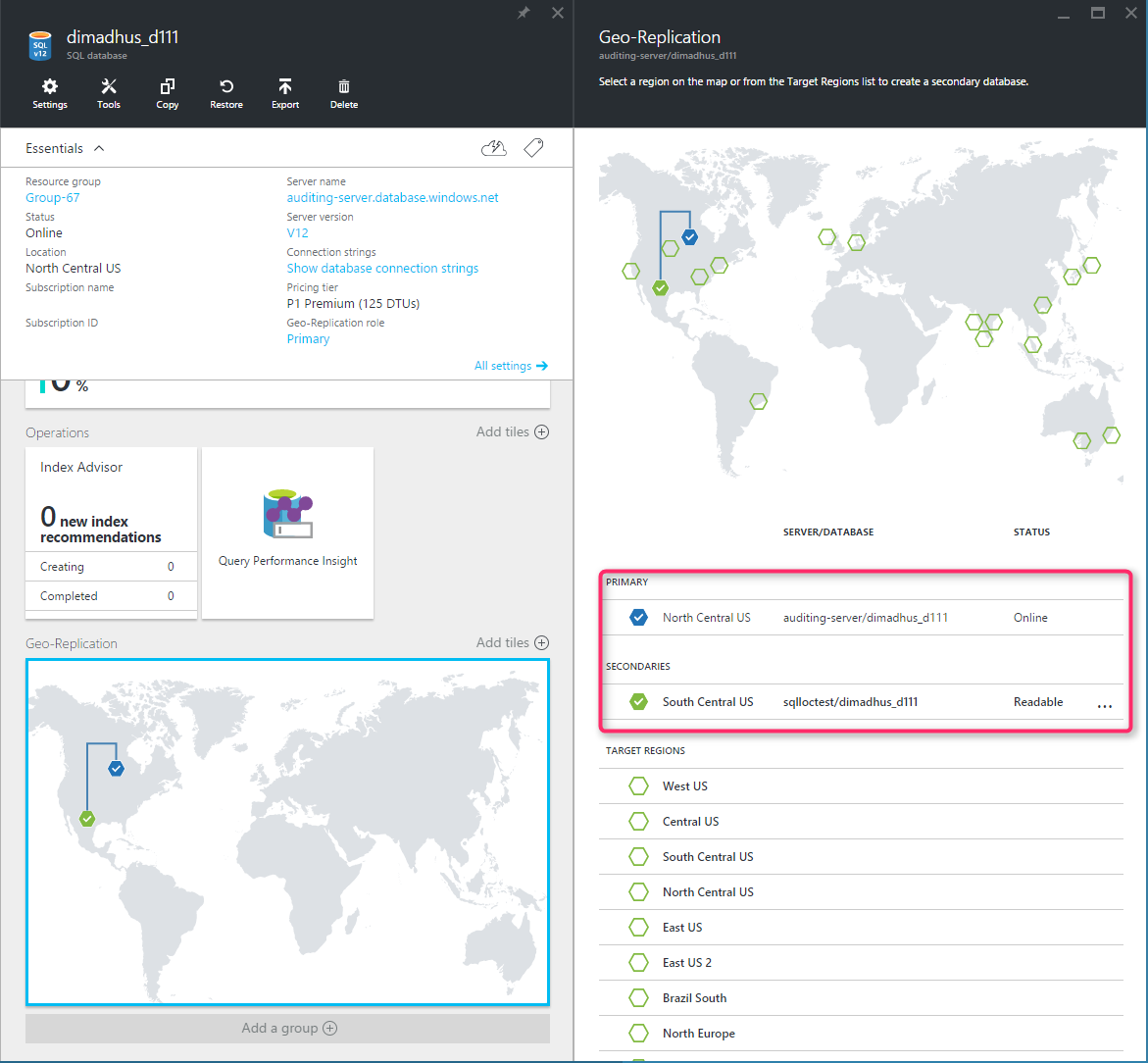
Na poniższej ilustracji przedstawiono przykład aktywnej replikacji geograficznej skonfigurowanej z podstawowym regionem Zachodnie stany USA 2 i pomocniczym obszarem geograficznym w regionie Wschodnie stany USA.
Oprócz odzyskiwania po awarii aktywna replikacja geograficzna może być używana w następujących scenariuszach:
- Migracja bazy danych: możesz użyć aktywnej replikacji geograficznej, aby przeprowadzić migrację bazy danych z jednego serwera do innego z minimalnym przestojem.
- Uaktualnienia aplikacji: możesz utworzyć dodatkową pomocniczą jako kopię powrotną po awarii podczas uaktualniania aplikacji.
Aby zapewnić pełną ciągłość działania, dodanie nadmiarowości regionalnej bazy danych jest tylko częścią rozwiązania. Odzyskiwanie kompleksowej aplikacji (usługi) po katastrofalnym niepowodzeniu wymaga odzyskania wszystkich składników, które stanowią usługę i wszelkie usługi zależne. Przykłady tych składników obejmują oprogramowanie klienckie (na przykład przeglądarkę z niestandardowym kodem JavaScript), frontony internetowe, magazyn i system DNS. Ważne jest, aby wszystkie składniki były odporne na te same awarie i stały się dostępne w ramach celu czasu odzyskiwania (RTO) aplikacji. W związku z tym należy zidentyfikować wszystkie usługi zależne i zrozumieć oferowane przez nich gwarancje i możliwości. Następnie należy podjąć odpowiednie kroki, aby upewnić się, że funkcje usługi podczas pracy w trybie failover usług, od których zależy. Aby uzyskać więcej informacji na temat projektowania rozwiązań do odzyskiwania po awarii, zobacz Projektowanie rozwiązań w chmurze na potrzeby odzyskiwania po awarii przy użyciu aktywnej replikacji geograficznej.
Aktywna terminologia i możliwości replikacji geograficznej
Automatyczna replikacja asynchroniczna
Możesz utworzyć tylko pomocniczą geograficzną bazę danych dla istniejącej bazy danych. Pomocniczy obszar geograficzny można utworzyć na dowolnym serwerze logicznym, innym niż serwer z podstawową bazą danych. Po utworzeniu replika pomocnicza geograficzna jest wypełniana danymi podstawowej bazy danych. Ten proces jest znany jako rozmieszczanie. Po utworzeniu i zainicjowaniu pomocniczego obszaru geograficznego aktualizacje podstawowej bazy danych są automatycznie i asynchronicznie replikowane do repliki pomocniczej geograficznej. Replikacja asynchroniczna oznacza, że transakcje są zatwierdzane w podstawowej bazie danych przed ich replikacją.
Repliki pomocnicze z możliwością odczytu
Aplikacja może uzyskać dostęp do repliki pomocniczej geograficznej w celu wykonywania zapytań tylko do odczytu przy użyciu tych samych lub różnych podmiotów zabezpieczeń używanych do uzyskiwania dostępu do podstawowej bazy danych. Aby uzyskać więcej informacji, zobacz Używanie replik tylko do odczytu do odciążania obciążeń zapytań tylko do odczytu.
Ważne
Replikacja geograficzna umożliwia tworzenie replik pomocniczych w tym samym regionie co podstawowy. Tych pomocniczych można użyć do spełnienia scenariuszy skalowania odczytu w poziomie w tym samym regionie. Jednak replika pomocnicza w tym samym regionie nie zapewnia dodatkowej odporności na katastrofalne awarie lub awarie na dużą skalę, a zatem nie jest odpowiednim celem trybu failover na potrzeby odzyskiwania po awarii. Nie gwarantuje również izolacji strefy dostępności. Użyj konfiguracji strefowo nadmiarowej warstwy usług Krytyczne dla działania firmy lub Warstwy usług Premium lub konfiguracji strefowo nadmiarowej warstwy usługi ogólnego przeznaczenia, aby uzyskać izolację strefy dostępności.
Tryb failover (brak utraty danych)
Tryb failover przełącza role podstawowych i pomocniczych baz danych geograficznych po zakończeniu pełnej synchronizacji danych, dzięki czemu nie ma utraty danych. Czas trwania przejścia w tryb failover zależy od rozmiaru dziennika transakcji na serwerze podstawowym, który należy zsynchronizować z pomocniczym obszarem geograficznym. Tryb failover jest przeznaczony dla następujących scenariuszy:
- Wykonywanie próbnych odzyskiwania po awarii w środowisku produkcyjnym, gdy utrata danych nie jest akceptowalna
- Przenoszenie bazy danych do innego regionu
- Zwróć bazę danych do regionu podstawowego po ograniczeniu awarii (znanej jako powrót po awarii).
Wymuszone przejście w tryb failover (potencjalna utrata danych)
Wymuszone przejście w tryb failover natychmiast przełącza pomocnicze geograficznie do roli podstawowej bez oczekiwania na synchronizację z podstawowym. Wszystkie transakcje zatwierdzone na serwerze podstawowym, ale nie zostały jeszcze zreplikowane do pomocniczej, zostaną utracone. Ta operacja jest zaprojektowana jako metoda odzyskiwania podczas przestojów, gdy podstawowa baza danych nie jest dostępna, ale dostępność bazy danych musi zostać szybko przywrócona. Gdy oryginalny element podstawowy jest z powrotem w trybie online, jest automatycznie ponownie połączony, ponownie połączony przy użyciu bieżących danych z bazy podstawowej i staje się nowym pomocniczym obszarem geograficznym.
Ważne
Po przejściu w tryb failover lub wymuszonym przejściu w tryb failover punkt końcowy połączenia dla nowych zmian podstawowych, ponieważ nowy serwer podstawowy znajduje się teraz na innym serwerze logicznym.
Wiele czytelnych danych geograficznych
Dla elementu podstawowego można utworzyć maksymalnie cztery sekundy geograficzne. Jeśli jest tylko jedna pomocnicza i kończy się niepowodzeniem, aplikacja jest narażona na większe ryzyko, dopóki nie zostanie utworzona nowa pomocnicza. Jeśli istnieje wiele pomocniczych, aplikacja pozostaje chroniona, nawet jeśli jeden z drugiego nie powiedzie się. Dodatkowe pomocnicze mogą również służyć do skalowania obciążeń tylko do odczytu w poziomie.
Napiwek
Jeśli używasz aktywnej replikacji geograficznej do tworzenia globalnie rozproszonej aplikacji i musisz zapewnić dostęp tylko do odczytu do danych w więcej niż czterech regionach, możesz utworzyć pomocniczą pomocniczą pomocniczą (proces znany jako łączenie łańcuchowe), aby utworzyć dodatkowe repliki geograficzne. Opóźnienie replikacji w łańcuchowych replikach geograficznych może być wyższe niż w przypadku replik geograficznych połączonych bezpośrednio z replikami podstawowymi. Konfigurowanie topologii replikacji geograficznej jest obsługiwane tylko programowo, a nie z witryny Azure Portal.
Replikacja geograficzna baz danych w elastycznej puli
Każda pomocnicza lokalizacja geograficzna może być pojedynczą bazą danych lub bazą danych w elastycznej puli. Wybór elastycznej puli dla każdej pomocniczej bazy danych geograficznej jest oddzielny i nie zależy od konfiguracji żadnej innej repliki w topologii (podstawowej lub pomocniczej). Każda elastyczna pula jest zawarta na jednym serwerze logicznym. Ponieważ nazwy baz danych na serwerze logicznym muszą być unikatowe, wiele serwerów geograficznych tego samego podstawowego nigdy nie może współużytkować elastycznej puli.
Sterowane przez użytkownika geograficzne przejście w tryb failover i powrót po awarii
Pomocnicze środowisko geograficzne, które zakończyło wstępne rozmieszczanie, można jawnie przełączyć na rolę podstawową (przełączenie w tryb failover) w dowolnym momencie przez aplikację lub użytkownika. W przypadku awarii, w której podstawowy jest niedostępny, można użyć tylko wymuszonego przejścia w tryb failover, co natychmiast powoduje podwyższenie poziomu pomocniczego obszaru geograficznego jako nowego podstawowego. Gdy awaria zostanie złagodzone, system automatycznie wykona odzyskaną podstawową pomocniczą lokalizację geograficzną i wyświetli ją na bieżąco z nowym podstawowym. Ze względu na asynchroniczny charakter replikacji geograficznej ostatnie transakcje mogą zostać utracone podczas wymuszonych przełączeń w tryb failover, jeśli podstawowe operacje kończą się niepowodzeniem, zanim te transakcje zostaną zreplikowane do pomocniczego obszaru geograficznego. W przypadku przełączenia w tryb failover serwera podstawowego z wieloma sekundami geograficznymi system automatycznie ponownie konfiguruje relacje replikacji i łączy pozostałe sekundy geograficzne z nowo promowanymi elementami podstawowymi bez konieczności interwencji użytkownika. Po ograniczeniu awarii, która spowodowała przejście w tryb failover geograficznie, może być pożądane zwrócenie podstawowego do oryginalnego regionu. W tym celu wykonaj ręczne przejście w tryb failover.
Replika rezerwowa
Jeśli replika pomocnicza jest używana tylko do odzyskiwania po awarii i nie ma żadnych obciążeń odczytu lub zapisu, możesz wyznaczyć replikę jako rezerwę , aby zaoszczędzić na kosztach licencjonowania.
Przygotowanie do przejścia w tryb failover geograficznie
Aby upewnić się, że aplikacja może natychmiast uzyskać dostęp do nowego podstawowego po przejściu w tryb failover geograficznie, sprawdź, czy uwierzytelnianie i dostęp sieciowy dla serwera pomocniczego są prawidłowo skonfigurowane. Aby uzyskać szczegółowe informacje, zobacz Zabezpieczenia usługi SQL Database po odzyskiwaniu po awarii. Sprawdź również, czy zasady przechowywania kopii zapasowych w pomocniczej bazie danych są zgodne z zasadami przechowywania kopii zapasowych w podstawowej bazie danych. To ustawienie nie jest częścią bazy danych i nie jest replikowane z bazy danych podstawowej. Domyślnie pomocnicza lokalizacja geograficzna jest konfigurowana z domyślnym okresem przechowywania pitr w ciągu siedmiu dni. Aby uzyskać szczegółowe informacje, zobacz Automatyczne kopie zapasowe usługi SQL Database.
Ważne
Jeśli baza danych jest członkiem grupy trybu failover, nie można zainicjować jej trybu failover przy użyciu polecenia trybu failover replikacji geograficznej. Użyj polecenia trybu failover dla grupy. Jeśli musisz przejść w tryb failover dla pojedynczej bazy danych, musisz najpierw usunąć ją z grupy trybu failover. Aby uzyskać szczegółowe informacje, zobacz Grupy trybu failover.
Konfigurowanie pomocniczego obszaru geograficznego
Zarówno podstawowa, jak i pomocnicza geograficzna muszą mieć tę samą warstwę usługi. Zdecydowanie zaleca się również skonfigurowanie pomocniczego obszaru geograficznego z tą samą nadmiarowością magazynu kopii zapasowych, warstwą obliczeniową (aprowizowaną lub bezserwerową) oraz rozmiarem obliczeniowym (jednostki DTU lub rdzeniami wirtualnymi) jako podstawową. Jeśli w podstawowym obciążeniu zapisu występuje duże obciążenie, pomocnicza lokalizacja geograficzna o niższym rozmiarze obliczeniowym może nie być w stanie nadążyć. Powoduje to opóźnienie replikacji w pomocniczym obszarze geograficznym i może w końcu spowodować niedostępność pomocniczego obszaru geograficznego. Aby ograniczyć te zagrożenia, aktywna replikacja geograficzna zmniejsza (ogranicza) szybkość rejestrowania transakcji podstawowego, jeśli jest to konieczne, aby umożliwić jego pomocniczym nadrobienie zaległości.
Kolejną konsekwencją niezrównoważonych konfiguracji pomocniczej geograficznej jest to, że po przejściu w tryb failover wydajność aplikacji może cierpieć z powodu niewystarczającej pojemności obliczeniowej nowego podstawowego. W takim przypadku konieczne jest skalowanie bazy danych w górę, aby mieć wystarczające zasoby, co może zająć dużo czasu i wymaga przejścia w tryb failover o wysokiej dostępności na końcu procesu skalowania w górę, co może przerwać obciążenia aplikacji.
Jeśli zdecydujesz się utworzyć pomocniczą lokalizację geograficzną z inną konfiguracją, należy monitorować szybkość operacji we/wy dziennika na podstawie czasu podstawowego. Pozwoli to oszacować minimalny rozmiar obliczeniowy pomocniczej lokalizacji geograficznej wymagany do utrzymania obciążenia replikacji. Jeśli na przykład podstawowa baza danych to P6 (1000 DTU), a operacje we/wy dziennika są utrzymywane na poziomie 50%, pomocnicze geograficznie musi być co najmniej P4 (500 DTU). Aby pobrać dane we/wy dziennika historycznego , użyj widoku sys.resource_stats . Aby pobrać najnowsze dane we/wy dziennika z wyższym stopniem szczegółowości, które lepiej odzwierciedlają krótkoterminowe skoki, użyj widoku sys.dm_db_resource_stats .
Napiwek
Ograniczanie operacji we/wy dziennika transakcji na serwerze podstawowym z powodu mniejszego rozmiaru obliczeniowego w pomocniczej lokalizacji geograficznej jest zgłaszane przy użyciu typu oczekiwania HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO widocznego w widokach bazy danych sys.dm_exec_requests i sys.dm_os_wait_stats .
We/Wy dziennika transakcji na podstawowym serwerze podstawowym mogą być ograniczane z powodów niepowiązanych z niższym rozmiarem obliczeniowym w pomocniczej lokalizacji geograficznej. Ten rodzaj ograniczania może wystąpić nawet wtedy, gdy pomocniczy obszar geograficzny ma taki sam lub wyższy rozmiar obliczeniowy niż podstawowy. Aby uzyskać szczegółowe informacje, w tym typy oczekiwania dla różnych rodzajów ograniczania operacji we/wy dziennika, zobacz Zarządzanie szybkością transakcji.
Domyślnie nadmiarowość magazynu kopii zapasowych pomocniczego obszaru geograficznego jest taka sama jak w przypadku podstawowej bazy danych. Możesz skonfigurować pomocniczy obszar geograficzny z inną nadmiarowością magazynu kopii zapasowych. Kopie zapasowe są zawsze wykonywane w podstawowej bazie danych. Jeśli pomocnicza jest skonfigurowana z inną nadmiarowością magazynu kopii zapasowych, po przejściu w tryb failover geograficznym, po podwyższeniu poziomu geograficznego pomocniczego do podstawowego, nowe kopie zapasowe będą przechowywane i rozliczane zgodnie z typem magazynu (RA-GRS, ZRS, LRS) wybranym w nowym podstawowym (poprzednim pomocniczym).
Oszczędzanie na kosztach dzięki repliki rezerwowej
Jeśli replika pomocnicza jest używana tylko do odzyskiwania po awarii (DR) i nie ma żadnych obciążeń odczytu lub zapisu, możesz zaoszczędzić na kosztach licencjonowania, określając bazę danych na potrzeby rezerwowania podczas konfigurowania nowej aktywnej relacji replikacji geograficznej.
Aby dowiedzieć się więcej, zapoznaj się z bezpłatną repliką rezerwową bez licencji .
Replikacja geograficzna między subskrypcjami
Użyj języka Transact-SQL (T-SQL) lub interfejsu API REST Tworzenia lub aktualizowania baz danych, aby utworzyć pomocniczy obszar geograficzny w subskrypcji innej niż subskrypcja podstawowa (niezależnie od tego, czy jest to ta sama dzierżawa identyfikatora Entra firmy Microsoft (dawniej Azure Active Directory), czy nie). Aby dowiedzieć się więcej, zobacz Konfigurowanie aktywnej replikacji geograficznej.
Zachowaj synchronizację poświadczeń i reguł zapory
W przypadku korzystania z dostępu do sieci publicznej do nawiązywania połączenia z bazą danych zalecamy używanie reguł zapory adresów IP na poziomie bazy danych dla baz danych replikowanych geograficznie. Te reguły są replikowane z bazą danych, co gwarantuje, że wszystkie pomocnicze lokalizacje geograficzne mają te same reguły zapory IP co podstawowa. Takie podejście eliminuje konieczność ręcznego konfigurowania i obsługi reguł zapory na serwerach hostujących podstawowe i pomocnicze bazy danych. Podobnie użycie użytkowników zawartej bazy danych w celu uzyskania dostępu do danych zapewnia, że zarówno podstawowe, jak i pomocnicze bazy danych zawsze mają te same poświadczenia uwierzytelniania. W ten sposób po przejściu w tryb failover geograficznie nie ma żadnych zakłóceń z powodu niezgodności poświadczeń uwierzytelniania. Jeśli używasz identyfikatorów logowania i użytkowników (a nie zawartych użytkowników), musisz wykonać dodatkowe kroki, aby upewnić się, że te same identyfikatory logowania istnieją dla pomocniczej bazy danych. Aby uzyskać szczegółowe informacje o konfiguracji, zobacz Jak skonfigurować identyfikatory logowania i użytkowników.
Skalowanie podstawowej bazy danych
Podstawową bazę danych można skalować w górę lub w dół do innego rozmiaru obliczeniowego (w tej samej warstwie usługi) bez odłączania żadnych serwerów geograficznych. Podczas skalowania w górę zalecamy najpierw skalowanie w górę pomocniczego, a następnie podstawowego obszaru geograficznego. Odwróć tę kolejność podczas skalowania w dół: najpierw przeprowadź skalowanie w dół podstawowego, a następnie pomocniczego obszaru geograficznego.
Uwaga
W przypadku utworzenia pomocniczego obszaru geograficznego w ramach konfiguracji grupy trybu failover nie zaleca się skalowania go w dół. Ma to na celu zapewnienie, że warstwa danych będzie mieć wystarczającą pojemność do przetworzenia normalnego obciążenia po przejściu do trybu failover ze zmianą obszaru geograficznego.
Ważne
Podstawowa baza danych w grupie trybu failover nie może być skalowana do wyższej warstwy usługi (wersja), chyba że pomocnicza baza danych zostanie najpierw przeskalowana do wyższej warstwy. Jeśli na przykład chcesz skalować w górę podstawową z warstwy Ogólnego przeznaczenia do Krytyczne dla działania firmy, musisz najpierw skalować pomocnicze geograficznie do Krytyczne dla działania firmy. Jeśli spróbujesz skalować podstawową lub pomocniczą geograficzną w sposób naruszający tę regułę, zostanie wyświetlony następujący błąd:
The source database 'Primaryserver.DBName' cannot have higher edition than the target database 'Secondaryserver.DBName'. Upgrade the edition on the target before upgrading the source.
Zapobieganie utracie krytycznych danych
Ze względu na duże opóźnienie sieci rozległe replikacja geograficzna używa mechanizmu replikacji asynchronicznej. Replikacja asynchroniczna sprawia, że utrata danych jest nieunikniona w przypadku awarii podstawowej. Aby chronić krytyczne transakcje przed utratą danych, deweloper aplikacji może wywołać procedurę składowaną sp_wait_for_database_copy_sync natychmiast po zatwierdzeniu transakcji. Wywołanie sp_wait_for_database_copy_sync blokuje wątek wywołujący do czasu przesyłania ostatniej zatwierdzonej transakcji i wzmacniania zabezpieczeń w dzienniku transakcji pomocniczej bazy danych. Jednak nie czeka na ponowne odtworzenie przesyłanych transakcji (redone) na pomocniczym. sp_wait_for_database_copy_sync jest ograniczona do określonego łącza replikacji geograficznej. Każdy użytkownik z prawami połączenia do podstawowej bazy danych może wywołać tę procedurę.
Uwaga
sp_wait_for_database_copy_sync zapobiega utracie danych po przejściu w tryb failover geograficznym dla określonych transakcji, ale nie gwarantuje pełnej synchronizacji w celu uzyskania dostępu do odczytu. Opóźnienie spowodowane sp_wait_for_database_copy_sync wywołaniem procedury może być znaczące i zależy od rozmiaru dziennika transakcji, który nie został jeszcze przesłany na serwerze podstawowym w momencie wywołania.
Monitorowanie opóźnienia replikacji geograficznej
Aby monitorować opóźnienie w stosunku do celu czasu odzyskiwania (RTO), użyj kolumny replication_lag_sec sys.dm_geo_replication_link_status w podstawowej bazie danych. Pokazuje opóźnienie w sekundach między transakcjami zatwierdzonymi w podstawowym obszarze geograficznym i utrwalonymi w dzienniku transakcji w pomocniczym obszarze geograficznym. Jeśli na przykład opóźnienie wynosi jedną sekundę, oznacza to, że jeśli w tej chwili wystąpi awaria, a nastąpi zainicjowanie geograficznego przejścia w tryb failover, transakcje zatwierdzone w ciągu ostatniej sekundy zostaną utracone.
Aby zmierzyć opóźnienie w odniesieniu do zmian w podstawowej bazie danych, które zostały wzmocnione w pomocniczym obszarze geograficznym, porównaj last_commit czasu w pomocniczym obszarze geograficznym z tą samą wartością w podstawowej bazie danych.
Napiwek
Jeśli replication_lag_sec na serwerze podstawowym ma wartość NULL, oznacza to, że podstawowa nie wie obecnie, jak daleko jest za pomocniczym obszarem geograficznym. Zwykle dzieje się tak po ponownym uruchomieniu procesu i powinien być stanem przejściowym. Rozważ wysłanie alertu, jeśli replication_lag_sec zwróci wartość NULL przez dłuższy czas. Może to wskazywać, że pomocnicza lokalizacja geograficzna nie może komunikować się z elementem podstawowym z powodu awarii łączności.
Istnieją również warunki, które mogą spowodować różnicę między last_commit czasem pomocniczym geograficznym a podstawowym, aby stały się duże. Jeśli na przykład zatwierdzenie zostanie wprowadzone na serwerze podstawowym po długim okresie bez zmian, różnica wzrośnie do dużej wartości, zanim szybko powróci do zera. Rozważ wysłanie alertu, jeśli różnica między tymi dwiema wartościami pozostaje duża przez długi czas.
Programowe zarządzanie aktywną replikacją geograficzną
Jak wspomniano wcześniej, aktywna replikacja geograficzna może być również zarządzana programowo przy użyciu języka T-SQL, programu Azure PowerShell i interfejsu API REST. W poniższych tabelach opisano zestaw dostępnych poleceń. Aktywna replikacja geograficzna obejmuje zestaw interfejsów API usługi Azure Resource Manager do zarządzania, w tym interfejs API REST usługi Azure SQL Database i polecenia cmdlet programu Azure PowerShell. Te interfejsy API obsługują kontrolę dostępu opartą na rolach platformy Azure (Azure RBAC). Aby uzyskać więcej informacji na temat implementowania ról dostępu, zobacz Kontrola dostępu oparta na rolach (RBAC) platformy Azure.
T-SQL: Zarządzanie trybem geograficznym trybu failover dla pojedynczych baz danych i baz danych w puli
Ważne
Te polecenia języka T-SQL dotyczą tylko aktywnej replikacji geograficznej i nie mają zastosowania do grup trybu failover. W związku z tym nie mają one również zastosowania do usługi SQL Managed Instance, która obsługuje tylko grupy trybu failover.
| Polecenie | opis |
|---|---|
| ALTER DATABASE | Użyj argumentu ADD SECONDARY ON SERVER , aby utworzyć pomocniczą bazę danych dla istniejącej bazy danych i uruchomić replikację danych |
| ALTER DATABASE | Użyj trybu failover lub FORCE_FAILOVER_ALLOW_DATA_LOSS , aby przełączyć pomocniczą bazę danych na podstawową, aby zainicjować tryb failover |
| ALTER DATABASE | Użyj funkcji REMOVE SECONDARY ON SERVER , aby zakończyć replikację danych między bazą danych SQL Database a określoną pomocniczą bazą danych. |
| sys.geo_replication_links | Zwraca informacje o wszystkich istniejących linkach replikacji dla każdej bazy danych na serwerze. |
| sys.dm_geo_replication_link_status | Pobiera czas ostatniej replikacji, opóźnienie ostatniej replikacji i inne informacje o linku replikacji dla danej bazy danych. |
| sys.dm_operation_status | Pokazuje stan wszystkich operacji bazy danych, w tym zmiany linków replikacji. |
| sys.sp_wait_for_database_copy_sync | Powoduje, że aplikacja czeka, aż wszystkie zatwierdzone transakcje zostaną wzmocnione do dziennika transakcji pomocniczego geograficznego. |
PowerShell: zarządzanie trybem failover geograficznym dla pojedynczych baz danych i baz danych w puli
Uwaga
W tym artykule użyto modułu Azure Az programu PowerShell, który jest zalecanym modułem programu PowerShell do interakcji z platformą Azure. Aby rozpocząć pracę z modułem Azure PowerShell, zobacz Instalowanie programu Azure PowerShell. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
Ważne
Moduł Azure Resource Manager programu PowerShell jest nadal obsługiwany przez usługę Azure SQL Database, ale wszystkie przyszłe programowanie dotyczy modułu Az.Sql. Aby uzyskać te polecenia cmdlet, zobacz AzureRM.Sql. Argumenty poleceń w module Az i modułach AzureRm są zasadniczo identyczne.
| Polecenia cmdlet | opis |
|---|---|
| Get-AzSqlDatabase | Pobiera co najmniej jedną bazę danych. |
| New-AzSqlDatabaseSecondary | Tworzy pomocniczą bazę danych dla istniejącej bazy danych i rozpoczyna replikację danych. |
| Set-AzSqlDatabaseSecondary | Przełącza pomocniczą bazę danych jako główną w celu zainicjowania trybu failover. |
| Remove-AzSqlDatabaseSecondary | Przerywa replikację danych między bazą danych SQL Database i wybraną pomocniczą bazą danych. |
| Get-AzSqlDatabaseReplicationLink | Pobiera łącza replikacji geograficznej dla bazy danych. |
Napiwek
Aby uzyskać przykładowe skrypty, zobacz Konfigurowanie i przechodzenie w tryb failover pojedynczej bazy danych przy użyciu aktywnej replikacji geograficznej oraz Konfigurowanie i przełączanie bazy danych w tryb failover w puli przy użyciu aktywnej replikacji geograficznej.
Interfejs API REST: zarządzanie trybem failover geograficznym dla pojedynczych baz danych i baz danych w puli
| Interfejs API | opis |
|---|---|
| Tworzenie lub aktualizowanie bazy danych (createMode=Restore) | Tworzy, aktualizuje lub przywraca podstawową lub pomocniczą bazę danych. |
| Uzyskiwanie stanu tworzenia lub aktualizowania bazy danych | Zwraca stan podczas operacji tworzenia. |
| Ustawianie pomocniczej bazy danych jako podstawowej (planowana praca w trybie failover) | Ustawia, która pomocnicza baza danych jest podstawowa, przechodząc w tryb failover z bieżącej podstawowej bazy danych. Ta opcja nie jest obsługiwana w przypadku usługi SQL Managed Instance. |
| Ustaw pomocniczą bazę danych jako podstawową (nieplanowany tryb failover) | Ustawia, która pomocnicza baza danych jest podstawowa, przechodząc w tryb failover z bieżącej podstawowej bazy danych. Ta operacja może spowodować utratę danych. Ta opcja nie jest obsługiwana w przypadku usługi SQL Managed Instance. |
| Pobieranie linku replikacji | Pobiera określony link replikacji dla danej bazy danych w partnerstwie replikacji geograficznej. Pobiera informacje widoczne w widoku katalogu sys.geo_replication_links. Ta opcja nie jest obsługiwana w przypadku usługi SQL Managed Instance. |
| Łącza replikacji — lista według bazy danych | Pobiera wszystkie łącza replikacji dla danej bazy danych w powiązaniu replikacji geograficznej. Pobiera informacje widoczne w widoku katalogu sys.geo_replication_links. |
| Usuń łącze replikacji | Usuwa link replikacji bazy danych. Nie można wykonać pracy w trybie failover. |
Następne kroki
- Aby uzyskać przykładowe skrypty, zobacz:
- Usługa SQL Database obsługuje również grupy trybu failover. Aby uzyskać więcej informacji, zobacz Używanie grup trybu failover.
- Aby zapoznać się z omówieniem i scenariuszami ciągłości działania, zobacz Omówienie ciągłości działania.
- Oszczędzaj na kosztach licencjonowania, wyznaczając pomocniczą replikę odzyskiwania po awarii na potrzeby rezerwowania.
- Aby dowiedzieć się więcej na temat hiperskala repliki geograficznej usługi Azure SQL Database, zobacz Hiperskala Replika geograficzna
- Aby dowiedzieć się więcej na temat automatycznych kopii zapasowych usługi Azure SQL Database, zobacz Automatyczne kopie zapasowe usługi SQL Database.
- Aby dowiedzieć się więcej na temat używania automatycznych kopii zapasowych na potrzeby odzyskiwania, zobacz Przywracanie bazy danych z kopii zapasowych zainicjowanych przez usługę.
- Aby dowiedzieć się więcej o wymaganiach dotyczących uwierzytelniania dla nowego serwera podstawowego i bazy danych, zobacz Zabezpieczenia usługi SQL Database po odzyskiwaniu po awarii.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla