Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: ![]() NoSQL
NoSQL
Ważne
To nie jest najnowsze Java SDK dla usługi Azure Cosmos DB! Należy uaktualnić projekt do zestawu Java SDK usługi Azure Cosmos DB w wersji 4, a następnie przeczytać przewodnik porady dotyczące wydajności zestawu Java SDK usługi Azure Cosmos DB w wersji 4. Postępuj zgodnie z instrukcjami w przewodniku Migrate to Azure Cosmos DB Java SDK v4 (Migrowanie do zestawu Java SDK usługi Azure Cosmos DB w wersji 4 ) i przewodniku Reactor vs RxJava w celu uaktualnienia.
Te porady dotyczące wydajności dotyczą tylko zestawu Java SDK synchronizacji usługi Azure Cosmos DB w wersji 2. Aby uzyskać więcej informacji, zobacz repozytorium Maven.
Ważne
29 lutego 2024 r. zestaw Java SDK synchronizacji usługi Azure Cosmos DB w wersji 2.x zostanie wycofany; zestaw SDK i wszystkie aplikacje korzystające z zestawu SDK będą nadal działać; Usługa Azure Cosmos DB po prostu przestanie zapewniać dalszą konserwację i obsługę tego zestawu SDK. Zalecamy wykonanie powyższych instrukcji, aby przeprowadzić migrację do zestawu Java SDK usługi Azure Cosmos DB w wersji 4.
Azure Cosmos DB to szybka i elastyczna rozproszona baza danych, która bezproblemowo skaluje się z gwarantowanym opóźnieniem i przepływnością. Nie musisz wprowadzać istotnych zmian architektury ani pisać złożonego kodu w celu skalowania bazy danych za pomocą usługi Azure Cosmos DB. Skalowanie w górę i w dół jest tak proste, jak wykonanie jednego wywołania interfejsu API. Aby dowiedzieć się więcej, zobacz jak aprowizować przepływność kontenera lub jak aprowizować przepływność bazy danych. Jednak ze względu na to, że usługa Azure Cosmos DB jest dostępna za pośrednictwem wywołań sieciowych, można dokonać optymalizacji po stronie klienta, aby osiągnąć szczytową wydajność podczas korzystania z zestawu Java SDK synchronizacji usługi Azure Cosmos DB w wersji 2.
Jeśli więc zadajesz pytanie "Jak mogę poprawić wydajność bazy danych?", rozważ następujące opcje:
Sieciowanie
Tryb połączenia: Użyj funkcji DirectHttps
Sposób, w jaki klient nawiązuje połączenie z usługą Azure Cosmos DB, ma istotny wpływ na wydajność, szczególnie jeśli chodzi o zaobserwowane opóźnienie po stronie klienta. Istnieje jedno kluczowe ustawienie konfiguracji, służące do konfigurowania polityki połączenia klienta ConnectionPolicy – ConnectionMode. Dostępne tryby połączenia to:
-
Tryb bramy jest obsługiwany na wszystkich platformach zestawu SDK i jest skonfigurowanym ustawieniem domyślnym. Jeśli aplikacja działa w sieci firmowej z rygorystycznymi ograniczeniami zapory, brama sieciowa jest najlepszym wyborem, ponieważ używa standardowego portu HTTPS i pojedynczego punktu końcowego komunikacji. Kompromis wydajności polega jednak na tym, że tryb bramy obejmuje dodatkowy przeskok sieciowy za każdym razem, gdy dane są odczytywane lub zapisywane w usłudze Azure Cosmos DB. W związku z tym tryb DirectHttps oferuje lepszą wydajność z powodu mniejszej liczby przeskoków sieciowych.
Zestaw Java SDK synchronizacji usługi Azure Cosmos DB w wersji 2 używa protokołu HTTPS jako protokołu transportowego. Protokół HTTPS używa protokołu TLS do początkowego uwierzytelniania i szyfrowania ruchu. W przypadku korzystania z zestawu Java SDK synchronizacji usługi Azure Cosmos DB w wersji 2 należy otworzyć tylko port HTTPS 443.
Parametr ConnectionMode jest konfigurowany w trakcie tworzenia wystąpienia DocumentClient za pomocą parametru ConnectionPolicy.
Synchronizowanie zestawu Java SDK w wersji 2 (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);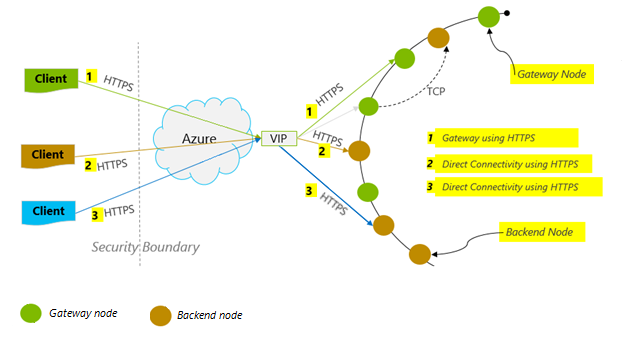
Sortowanie klientów w tym samym regionie świadczenia usługi Azure pod kątem wydajności
Jeśli to możliwe, umieść wszystkie aplikacje wywołujące usługę Azure Cosmos DB w tym samym regionie co baza danych usługi Azure Cosmos DB. Aby uzyskać przybliżone porównanie, wywołania usługi Azure Cosmos DB w tym samym regionie są kompletne w ciągu 1–2 ms, ale opóźnienie między zachodnim i wschodnim wybrzeżem STANÓW Zjednoczonych wynosi >50 ms. To opóźnienie może się różnić w zależności od konkretnego żądania, w zależności od trasy, którą żądanie pokonuje od klienta do granicy centrum danych platformy Azure. Najmniejsze możliwe opóźnienie jest osiągane przez zapewnienie, że aplikacja wywołująca znajduje się w tym samym regionie świadczenia usługi Azure, co aprowizowany punkt końcowy usługi Azure Cosmos DB. Aby uzyskać listę dostępnych regionów, zobacz Regiony świadczenia usługi Azure.
Użycie zestawu SDK
Instalowanie najnowszego zestawu SDK
Zestawy SDK usługi Azure Cosmos DB są stale ulepszane, aby zapewnić najlepszą wydajność. Aby określić najnowsze ulepszenia zestawu SDK, odwiedź stronę zestawu SDK usługi Azure Cosmos DB.
Używanie pojedynczego klienta usługi Azure Cosmos DB przez cały okres istnienia aplikacji
Każde wystąpienie DocumentClient jest bezpieczne wątkowo i wykonuje wydajne zarządzanie połączeniami oraz buforowanie adresów podczas pracy w trybie bezpośrednim. Aby umożliwić wydajne zarządzanie połączeniami i osiągnąć lepszą wydajność za pomocą DocumentClient, zaleca się użycie pojedynczej instancji DocumentClient dla domeny aplikacji AppDomain na cały czas życia aplikacji.
Zwiększ wartość MaxPoolSize na hosta podczas korzystania z trybu bramy
Żądania usługi Azure Cosmos DB są wysyłane za pośrednictwem protokołu HTTPS/REST w przypadku korzystania z trybu bramy i podlegają domyślnemu limitowi połączenia na nazwę hosta lub adres IP. Może być konieczne ustawienie parametru MaxPoolSize na wyższą wartość (200–1000), aby biblioteka kliencka mogła korzystać z wielu równoczesnych połączeń z usługą Azure Cosmos DB. W pakiecie Java SDK synchronizacji usługi Azure Cosmos DB w wersji 2 wartość domyślna parametru ConnectionPolicy.getMaxPoolSize wynosi 100. Użyj setMaxPoolSize, aby zmienić wartość.
Optymalizacja zapytań równoległych dla kolekcji partycjonowanych
Zestaw Java SDK synchronizacji usługi Azure Cosmos DB w wersji 1.9.0 lub nowszej obsługuje zapytania równoległe, które umożliwiają równoległe wykonywanie zapytań dotyczących kolekcji partycjonowanej. Aby uzyskać więcej informacji, zobacz przykłady kodu związane z pracą z zestawami SDK. Zapytania równoległe zostały zaprojektowane w celu zwiększenia opóźnienia zapytań i przepływności w porównaniu z ich odpowiednikami seryjnymi.
(a) Dostosowywanie setMaxDegreeOfParallelism: Zapytania równoległe działają poprzez jednoczesne zapytywanie wielu partycji. Jednak dane z pojedynczej kolekcji partycjonowanej są pobierane szeregowo w odniesieniu do zapytania. Dlatego należy użyć setMaxDegreeOfParallelism , aby ustawić liczbę partycji, które mają maksymalną szansę osiągnięcia najbardziej wydajnego zapytania, pod warunkiem, że wszystkie inne warunki systemowe pozostają takie same. Jeśli nie znasz liczby partycji, możesz użyć funkcji setMaxDegreeOfParallelism, aby ustawić dużą liczbę, a system wybierze minimalną (liczbę partycji, podaną przez użytkownika dane wejściowe) jako maksymalny stopień równoległości.
Należy pamiętać, że zapytania równoległe dają najlepsze korzyści, jeśli dane są równomiernie dystrybuowane we wszystkich partycjach w odniesieniu do zapytania. Jeśli kolekcja partycjonowana jest w taki sposób, że wszystkie lub większość danych zwracanych przez zapytanie jest skoncentrowana w kilku partycjach (jedna partycja w najgorszym wypadku), wydajność zapytania mogłaby być ograniczona przez te partycje.
(b) Konfiguracja setMaxBufferedItemCount: Zapytanie równoległe jest przeznaczone do wstępnego pobierania wyników, podczas gdy bieżąca partia wyników jest przetwarzana przez klienta. Wstępne pobieranie pomaga w ogólnym ulepszaniu opóźnienia zapytania. setMaxBufferedItemCount ogranicza liczbę wstępnie pobranych wyników. Ustawiając parametr setMaxBufferedItemCount na oczekiwaną liczbę zwróconych wyników (lub wyższą liczbę), dzięki temu zapytanie może uzyskać maksymalną korzyść z pobierania wstępnego.
Wstępne pobieranie działa tak samo niezależnie od maxDegreeOfParallelism i istnieje jeden bufor dla danych ze wszystkich partycji.
Implementowanie wycofywania w interwałach getRetryAfterInMilliseconds
Podczas testowania wydajnościowego należy zwiększyć obciążenie, dopóki nie zostanie ograniczona niewielka liczba żądań. Jeśli zostanie ograniczona, aplikacja kliencka powinna wycofać się z ograniczenia dla określonego przez serwer interwału ponawiania prób. Przestrzeganie pauzy gwarantuje, że spędzasz jak najmniej czasu oczekując między ponawianiem prób. Obsługa zasad ponawiania prób jest uwzględniona w wersji 1.8.0 lub nowszej zestawu SDK języka Java synchronizacji usługi Azure Cosmos DB. Aby uzyskać więcej informacji, zobacz getRetryAfterInMilliseconds.
Skalowanie w poziomie obciążenia klienta
Jeśli testujesz na wysokich poziomach przepływności (>50 000 RU/s), aplikacja kliencka może stać się wąskim gardłem spowodowanym ograniczeniem użycia procesora CPU lub sieci. Jeśli osiągniesz ten punkt, możesz kontynuować wypychanie konta usługi Azure Cosmos DB, skalując aplikacje klienckie na wielu serwerach.
Używanie adresowania opartego na nazwach
Użyj adresowania opartego na nazwach, gdzie linki mają format
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, a nie SelfLinks (_self), które mają formatdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>, aby uniknąć pobierania identyfikatorów ResourceId wszystkich zasobów używanych do konstruowania łącza. Ponadto, ponieważ te zasoby są tworzone ponownie (prawdopodobnie o tej samej nazwie), buforowanie tych zasobów może nie pomóc.Dostrajanie rozmiaru strony dla zapytań/kanałów informacyjnych odczytu w celu uzyskania lepszej wydajności
Podczas wykonywania zbiorczego odczytu dokumentów przy użyciu funkcji źródła danych odczytu (na przykład readDocuments) lub podczas wystawiania zapytania SQL wyniki są zwracane w sposób segmentowany, jeśli zestaw wyników jest zbyt duży. Domyślnie wyniki są zwracane we fragmentach 100 elementów lub 1 MB, w zależności od tego, który limit zostanie osiągnięty jako pierwszy.
Aby zmniejszyć liczbę rund sieci wymaganych do pobrania wszystkich odpowiednich wyników, można zwiększyć rozmiar strony przy użyciu nagłówka żądania x-ms-max-item-count do 1000. W przypadkach, gdy trzeba wyświetlić tylko kilka wyników, na przykład jeśli interfejs użytkownika lub interfejs API aplikacji zwróci tylko 10 wyników naraz, możesz również zmniejszyć rozmiar strony do 10, aby zmniejszyć przepływność zużywaną dla operacji odczytu i zapytań.
Rozmiar strony można również ustawić przy użyciu metody setPageSize.
Zasady indeksowania
Wyklucz nieużywane ścieżki z indeksowania w celu przyspieszenia operacji zapisu
Zasady indeksowania usługi Azure Cosmos DB umożliwiają określenie ścieżek dokumentów do uwzględnienia lub wykluczenia z indeksowania przy użyciu ścieżek indeksowania (setIncludedPaths i setExcludedPaths). Użycie ścieżek indeksowania może oferować lepszą wydajność zapisu i niższy magazyn indeksów w scenariuszach, w których wzorce zapytań są znane wcześniej, ponieważ koszty indeksowania są bezpośrednio skorelowane z liczbą indeksowanych unikatowych ścieżek. Na przykład poniższy kod pokazuje, jak wykluczyć całą sekcję (poddrzewo) dokumentów z indeksowania przy użyciu symbolu wieloznakowego "*".
Synchronizowanie zestawu Java SDK w wersji 2 (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Aby uzyskać więcej informacji, zobacz Zasady indeksowania usługi Azure Cosmos DB.
Produktywność
Monitorowanie i dostrajanie dla niższego zużycia jednostek żądaniowych na sekundę
Usługa Azure Cosmos DB oferuje bogaty zestaw operacji bazy danych, w tym zapytania relacyjne i hierarchiczne z funkcjami zdefiniowanymi przez użytkownika, procedurami składowanymi i wyzwalaczami — wszystkie operacje na dokumentach w kolekcji bazy danych. Koszt związany z każdą z tych operacji zależy od mocy obliczeniowej CPU, operacji wejścia/wyjścia i pamięci wymaganej do wykonania operacji. Zamiast myśleć o zasobach sprzętowych i zarządzaniu nimi, możesz traktować jednostkę żądania (RU) jako pojedynczą miarę dla zasobów wymaganych do wykonywania różnych operacji bazy danych i obsługi żądania aplikacji.
Przepustowość jest przydzielana na podstawie liczby jednostek żądań, które są ustawione dla każdego kontenera. Konsumpcja jednostek żądania jest oceniana jako wskaźnik na sekundę. Aplikacje, które przekraczają przydzieloną jednostkę żądań dla swojego kontenera, są ograniczone, dopóki szybkość nie spadnie poniżej przydzielonego poziomu dla kontenera. Jeśli aplikacja wymaga wyższego poziomu przepływności, możesz zwiększyć przepływność, aprowizując dodatkowe jednostki żądań.
Złożoność zapytania ma wpływ na liczbę jednostek żądania używanych dla operacji. Liczba predykatów, charakter predykatów, liczba funkcji zdefiniowanych przez użytkownika i rozmiar zestawu danych źródłowych wpływają na koszt operacji zapytań.
Aby zmierzyć obciążenie dowolnej operacji (tworzenie, aktualizowanie lub usuwanie), sprawdź nagłówek x-ms-request-charge (lub równoważną właściwość RequestCharge w ResourceResponse<T> lub FeedResponse<T> w celu zmierzenia liczby jednostek żądania zużywanych przez te operacje.
Synchronizowanie zestawu Java SDK w wersji 2 (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();Opłata za zapytanie zwrócona w tym nagłówku jest ułamkiem przydzielonej przepustowości. Jeśli na przykład masz aprowizowane 2000 RU/s, a poprzednie zapytanie zwróci 1000 dokumentów o rozmiarze 1 KB, koszt operacji wynosi 1000. W związku z tym w ciągu jednej sekundy serwer honoruje tylko dwa takie żądania przed ograniczeniem liczby kolejnych żądań. Aby uzyskać więcej informacji, zobacz Request units and the request unit calculator (Jednostki żądań i kalkulator jednostek żądania).
Obsługa ograniczania szybkości/szybkości żądań jest zbyt duża
Gdy klient próbuje przekroczyć zarezerwowaną przepływność dla konta, nie ma spadku wydajności na serwerze i nie ma użycia pojemności przepływności poza poziomem zarezerwowanym. Serwer zakończy żądanie z wyprzedzeniem z błędem RequestRateTooLarge (kod stanu HTTP 429) i zwróci nagłówek x-ms-retry-after-ms, wskazujący ilość czasu w milisekundach, przez jaki użytkownik musi czekać przed ponownym wysłaniem żądania.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100SDKi niejawnie przechwytują tę odpowiedź, przestrzegają nagłówka określającego czas ponowienia ustalonego przez serwer i ponawiają żądanie. Jeśli twoje konto nie jest używane współbieżnie przez wielu klientów, następne ponowienie próby powiedzie się.
Jeśli masz więcej niż jednego klienta działającego stale powyżej szybkości żądań, domyślna liczba ponownych prób ustawiona wewnętrznie na 9 przez klienta może nie wystarczyć; w takim przypadku klient wyrzuca wyjątek DocumentClientException z kodem stanu 429 do aplikacji. Domyślną liczbę ponownych prób można zmienić przy użyciu polecenia setRetryOptions w wystąpieniu ConnectionPolicy . Domyślnie wyjątek DocumentClientException z kodem stanu 429 jest zwracany po skumulowanym czasie oczekiwania wynoszącym 30 sekund, jeśli żądanie nadal działa powyżej szybkości żądania. Dzieje się tak nawet wtedy, gdy bieżąca liczba ponownych prób jest mniejsza niż maksymalna liczba ponownych prób, może to być wartość domyślna 9 lub wartość zdefiniowana przez użytkownika.
Chociaż automatyczne zachowanie ponawiania prób pomaga zwiększyć odporność i użyteczność dla większości aplikacji, może to być sprzeczne podczas wykonywania testów porównawczych wydajności, zwłaszcza podczas mierzenia opóźnienia. Obserwowane przez klienta opóźnienie wzrośnie, jeśli eksperyment osiągnie ograniczenie przepustowości serwera i spowoduje, że zestaw SDK klienta ponawia próbę w trybie dyskretnym. Aby uniknąć skoków opóźnienia podczas eksperymentów wydajności, zmierz ładunek zwrócony przez każdą operację i upewnij się, że żądania działają poniżej zarezerwowanej szybkości żądań. Aby uzyskać więcej informacji, zobacz Request units (Jednostki żądań).
Projektowanie mniejszych dokumentów dla większej wydajności
Opłata za żądanie (koszt przetwarzania żądań) danej operacji jest bezpośrednio skorelowana z rozmiarem dokumentu. Operacje na dużych dokumentach kosztują więcej niż operacje dla małych dokumentów.
Następne kroki
Aby dowiedzieć się więcej na temat projektowania aplikacji pod kątem skalowania i wysokiej wydajności, zobacz Partycjonowanie i skalowanie w usłudze Azure Cosmos DB.