Porady dotyczące wydajności zestawu SDK języka Python usługi Azure Cosmos DB
DOTYCZY: ![]() NoSQL
NoSQL
Ważne
Porady dotyczące wydajności w tym artykule dotyczą tylko zestawu SDK języka Python usługi Azure Cosmos DB. Aby uzyskać więcej informacji, zapoznaj się z informacjami o wersji zestawu Python SDK usługi Azure Cosmos DB, pakietem (PyPI), pakietem (Conda) i przewodnikiem rozwiązywania problemów.
Azure Cosmos DB to szybka i elastyczna rozproszona baza danych, która bezproblemowo skaluje się z gwarantowanym opóźnieniem i przepływnością. Nie musisz wprowadzać istotnych zmian architektury ani pisać złożonego kodu w celu skalowania bazy danych za pomocą usługi Azure Cosmos DB. Skalowanie w górę i w dół jest tak proste, jak tworzenie pojedynczego wywołania interfejsu API lub wywołania metody zestawu SDK. Jednak ze względu na to, że usługa Azure Cosmos DB jest dostępna za pośrednictwem wywołań sieciowych, można dokonać optymalizacji po stronie klienta, aby osiągnąć szczytową wydajność podczas korzystania z zestawu SDK języka Python usługi Azure Cosmos DB.
Jeśli więc zadajesz pytanie "Jak mogę poprawić wydajność bazy danych?", rozważ następujące opcje:
Sieć
- Sortowanie klientów w tym samym regionie świadczenia usługi Azure pod kątem wydajności
Jeśli to możliwe, umieść wszystkie aplikacje wywołujące usługę Azure Cosmos DB w tym samym regionie co baza danych usługi Azure Cosmos DB. Aby uzyskać przybliżone porównanie, wywołania usługi Azure Cosmos DB w tym samym regionie są kompletne w ciągu 1–2 ms, ale opóźnienie między zachodnim i wschodnim wybrzeżem STANÓW Zjednoczonych wynosi >50 ms. To opóźnienie może się różnić w zależności od trasy podjętej przez żądanie w zależności od trasy, która przechodzi od klienta do granicy centrum danych platformy Azure. Najmniejsze możliwe opóźnienie jest osiągane przez zapewnienie, że aplikacja wywołująca znajduje się w tym samym regionie świadczenia usługi Azure, co aprowizowany punkt końcowy usługi Azure Cosmos DB. Aby uzyskać listę dostępnych regionów, zobacz Regiony świadczenia usługi Azure.
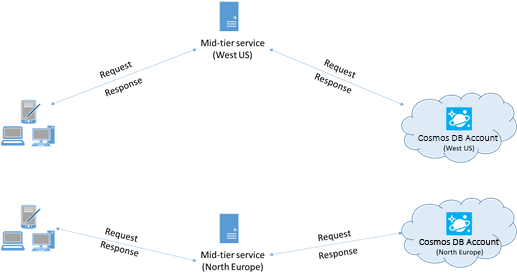
Aplikacja, która współdziała z kontem usługi Azure Cosmos DB w wielu regionach, musi skonfigurować preferowane lokalizacje , aby upewnić się, że żądania będą kierowane do kolokowanego regionu.
Włączanie przyspieszonej sieci w celu zmniejszenia opóźnienia i zakłócenia procesora CPU
Zaleca się wykonanie instrukcji dotyczących włączania przyspieszonej sieci w systemie Windows (wybierz, aby uzyskać instrukcje) lub Linux (wybierz, aby uzyskać instrukcje) maszyny wirtualnej platformy Azure, aby zmaksymalizować wydajność (zmniejszyć opóźnienia i zakłócenia procesora CPU).
Bez przyspieszonej sieci we/wy przesyłane między maszyną wirtualną platformy Azure i innymi zasobami platformy Azure mogą być niepotrzebnie kierowane przez hosta i przełącznik wirtualny znajdujący się między maszyną wirtualną a jej kartą sieciową. Posiadanie wbudowanego hosta i przełącznika wirtualnego w ścieżce danych nie tylko zwiększa opóźnienie i zakłócenia w kanale komunikacyjnym, ale także kradnie cykle procesora CPU z maszyny wirtualnej. W przypadku przyspieszonej sieci interfejsy maszyn wirtualnych bezpośrednio z kartą sieciową bez pośredników; wszystkie szczegóły zasad sieci, które były obsługiwane przez hosta i przełącznik wirtualny, są teraz obsługiwane w sprzęcie na karcie sieciowej; hosta i przełącznika wirtualnego są pomijane. Ogólnie rzecz biorąc, można oczekiwać mniejszego opóźnienia i większej przepływności, a także bardziej spójnego opóźnienia i mniejszego wykorzystania procesora CPU po włączeniu przyspieszonej sieci.
Ograniczenia: przyspieszona sieć musi być obsługiwana w systemie operacyjnym maszyny wirtualnej i może być włączona tylko wtedy, gdy maszyna wirtualna zostanie zatrzymana i cofnięto przydział. Nie można wdrożyć maszyny wirtualnej za pomocą usługi Azure Resource Manager. Usługa App Service nie ma włączonej przyspieszonej sieci.
Aby uzyskać więcej informacji, zobacz instrukcje dotyczące systemów Windows i Linux .
SDK usage (Użycie zestawu SDK)
- Instalowanie najnowszego zestawu SDK
Zestawy SDK usługi Azure Cosmos DB są stale ulepszane, aby zapewnić najlepszą wydajność. Zapoznaj się z informacjami o wersji zestawu SDK usługi Azure Cosmos DB, aby określić najnowszy zestaw SDK i zapoznać się z ulepszeniami.
- Używanie pojedynczego klienta usługi Azure Cosmos DB przez cały okres istnienia aplikacji
Każde wystąpienie klienta usługi Azure Cosmos DB jest bezpieczne wątkowo i wykonuje wydajne zarządzanie połączeniami i buforowanie adresów. Aby umożliwić wydajne zarządzanie połączeniami i lepszą wydajność przez klienta usługi Azure Cosmos DB, zaleca się użycie pojedynczego wystąpienia klienta usługi Azure Cosmos DB przez okres istnienia aplikacji.
- Dostrajanie limitu czasu i ponownych prób konfiguracji
Konfiguracje limitu czasu i zasady ponawiania prób można dostosować w zależności od potrzeb aplikacji. Zapoznaj się z dokumentem konfiguracji limitu czasu i ponownych prób, aby uzyskać pełną listę konfiguracji, które można dostosować.
- Użyj najniższego poziomu spójności wymaganego dla aplikacji
Podczas tworzenia elementu CosmosClient spójność na poziomie konta jest używana, jeśli podczas tworzenia klienta nie określono żadnej. Aby uzyskać więcej informacji na temat poziomów spójności, zobacz dokument dotyczący poziomów spójności.
- Skalowanie w poziomie obciążenia klienta
Jeśli testujesz na wysokim poziomie przepływności, aplikacja kliencka może stać się wąskim gardłem spowodowanym ograniczeniem użycia procesora CPU lub sieci przez maszynę. Jeśli osiągniesz ten punkt, możesz kontynuować wypychanie konta usługi Azure Cosmos DB, skalując aplikacje klienckie na wielu serwerach.
Dobrą regułą kciuka nie jest przekroczenie >50% wykorzystania procesora CPU na dowolnym serwerze, aby zachować małe opóźnienie.
- Limit zasobów otwartych plików systemu operacyjnego
Niektóre systemy Linux (takie jak Red Hat) mają górny limit liczby otwartych plików, więc łączna liczba połączeń. Uruchom następujące polecenie, aby wyświetlić bieżące limity:
ulimit -a
Liczba otwartych plików (nofile) musi być wystarczająco duża, aby mieć wystarczającą ilość miejsca dla skonfigurowanego rozmiaru puli połączeń i innych otwartych plików przez system operacyjny. Można go zmodyfikować, aby umożliwić większy rozmiar puli połączeń.
Otwórz plik limits.conf:
vim /etc/security/limits.conf
Dodaj/zmodyfikuj następujące wiersze:
* - nofile 100000
Operacje zapytań
Aby uzyskać informacje o operacjach zapytań, zobacz porady dotyczące wydajności zapytań.
Zasady indeksowania
- Wyklucz nieużywane ścieżki z indeksowania w celu przyspieszenia operacji zapisu
Zasady indeksowania usługi Azure Cosmos DB umożliwiają określenie ścieżek dokumentów do uwzględnienia lub wykluczenia z indeksowania przy użyciu ścieżek indeksowania (setIncludedPaths i setExcludedPaths). Użycie ścieżek indeksowania może oferować lepszą wydajność zapisu i niższy magazyn indeksów w scenariuszach, w których wzorce zapytań są znane wcześniej, ponieważ koszty indeksowania są bezpośrednio skorelowane z liczbą indeksowanych unikatowych ścieżek. Na przykład poniższy kod przedstawia sposób dołączania i wykluczania całych sekcji dokumentów (nazywanych również poddrzewem) z indeksowania przy użyciu symbolu wieloznakowego "*".
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Aby uzyskać więcej informacji, zobacz Zasady indeksowania usługi Azure Cosmos DB.
Produktywność
- Mierzenie i dostrajanie do niższych jednostek żądania/drugiego użycia
Usługa Azure Cosmos DB oferuje bogaty zestaw operacji bazy danych, w tym zapytania relacyjne i hierarchiczne z funkcjami zdefiniowanymi przez użytkownika, procedurami składowanymi i wyzwalaczami — wszystkie operacje na dokumentach w kolekcji bazy danych. Koszt związany z każdą z tych operacji zależy od procesora, danych We/Wy i pamięci wymaganej do wykonania danej operacji. Zamiast myśleć o zasobach sprzętowych i zarządzaniu nimi, możesz traktować jednostkę żądania (RU) jako pojedynczą miarę dla zasobów wymaganych do wykonywania różnych operacji bazy danych i obsługi żądania aplikacji.
Przepływność jest aprowizowana na podstawie liczby jednostek żądań ustawionych dla każdego kontenera. Użycie jednostek żądania jest oceniane jako szybkość na sekundę. Aplikacje, które przekraczają aprowizowaną liczbę jednostek żądań dla kontenera, są ograniczone do momentu spadku szybkości poniżej aprowizowanego poziomu dla kontenera. Jeśli aplikacja wymaga wyższego poziomu przepływności, możesz zwiększyć przepływność, aprowizując dodatkowe jednostki żądań.
Złożoność zapytania ma wpływ na liczbę jednostek żądania używanych dla operacji. Liczba predykatów, charakter predykatów, liczba funkcji zdefiniowanych przez użytkownika i rozmiar zestawu danych źródłowych wpływają na koszt operacji zapytań.
Aby zmierzyć obciążenie dowolnej operacji (tworzenie, aktualizowanie lub usuwanie), sprawdź nagłówek x-ms-request-charge , aby zmierzyć liczbę jednostek żądań używanych przez te operacje.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
Opłata za żądanie zwrócona w tym nagłówku jest ułamkiem aprowizowanej przepływności. Jeśli na przykład masz aprowizowaną wartość 2000 RU/s, a poprzednie zapytanie zwróci 1000 1 KB dokumentów, koszt operacji wynosi 1000. W związku z tym w ciągu jednej sekundy serwer honoruje tylko dwa takie żądania przed ograniczeniem liczby kolejnych żądań. Aby uzyskać więcej informacji, zobacz Request units and the request unit calculator (Jednostki żądań i kalkulator jednostek żądania).
- Obsługa ograniczania szybkości/szybkości żądań jest zbyt duża
Gdy klient próbuje przekroczyć zarezerwowaną przepływność dla konta, nie ma spadku wydajności na serwerze i nie ma użycia pojemności przepływności poza poziomem zarezerwowanym. Serwer z preemptively zakończy żądanie requestRateTooLarge (kod stanu HTTP 429) i zwróci nagłówek x-ms-retry-after-ms wskazujący ilość czasu w milisekundach, że użytkownik musi czekać przed ponownego przypisania żądania.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Zestawy SDK przechwytują tę odpowiedź niejawnie, przestrzegają określonego przez serwer nagłówka ponawiania próby i ponów próbę żądania. Jeśli twoje konto nie jest używane współbieżnie przez wielu klientów, następne ponowienie próby powiedzie się.
Jeśli masz więcej niż jednego klienta, który stale działa powyżej szybkości żądań, domyślna liczba ponownych prób jest obecnie ustawiona na 9 wewnętrznie przez klienta może nie być wystarczająca; w tym przypadku klient zgłasza błąd CosmosHttpResponseError z kodem stanu 429 do aplikacji. Domyślną liczbę ponownych prób można zmienić, przekazując retry_total konfigurację do klienta. Domyślnie błąd CosmosHttpResponseError z kodem stanu 429 jest zwracany po skumulowanym czasie oczekiwania wynoszącym 30 sekund, jeśli żądanie nadal działa powyżej szybkości żądania. Dzieje się tak nawet wtedy, gdy bieżąca liczba ponownych prób jest mniejsza niż maksymalna liczba ponownych prób, może to być wartość domyślna 9 lub wartość zdefiniowana przez użytkownika.
Chociaż automatyczne zachowanie ponawiania prób pomaga zwiększyć odporność i użyteczność dla większości aplikacji, może to być sprzeczne podczas wykonywania testów porównawczych wydajności, zwłaszcza podczas mierzenia opóźnienia. Obserwowane przez klienta opóźnienie wzrośnie, jeśli eksperyment osiągnie ograniczenie przepustowości serwera i spowoduje, że zestaw SDK klienta ponawia próbę w trybie dyskretnym. Aby uniknąć skoków opóźnień podczas eksperymentów wydajności, zmierz opłatę zwróconą przez każdą operację i upewnij się, że żądania działają poniżej zarezerwowanej stawki żądań. Aby uzyskać więcej informacji, zobacz Request units (Jednostki żądań).
- Projektowanie pod kątem mniejszych dokumentów pod kątem większej przepływności
Opłata za żądanie (koszt przetwarzania żądań) danej operacji jest bezpośrednio skorelowana z rozmiarem dokumentu. Operacje na dużych dokumentach kosztują więcej niż operacje dla małych dokumentów. Najlepiej jest utworzyć architekturę aplikacji i przepływów pracy, aby rozmiar elementu miał rozmiar ok. 1 KB lub podobny porządek lub wielkość. W przypadku aplikacji wrażliwych na opóźnienia należy unikać dużych elementów — dokumenty z wieloma MB spowalniają aplikację.
Następne kroki
Aby dowiedzieć się więcej na temat projektowania aplikacji pod kątem skalowania i wysokiej wydajności, zobacz Partycjonowanie i skalowanie w usłudze Azure Cosmos DB.
Próbujesz zaplanować pojemność migracji do usługi Azure Cosmos DB? Informacje o istniejącym klastrze bazy danych można użyć do planowania pojemności.
- Jeśli wszystko, co wiesz, to liczba rdzeni wirtualnych i serwerów w istniejącym klastrze bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu rdzeni wirtualnych lub procesorów wirtualnych
- Jeśli znasz typowe stawki żądań dla bieżącego obciążenia bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu planisty pojemności usługi Azure Cosmos DB